-
【博客478】prometheus-----存储目录结构以及格式,作用分析
prometheus-----存储目录结构
存储原理:
prometheus按照block块的方式来存储数据,每2小时为一个时间单位,首先会存储到内存中,当到达2小时后,会自动写入磁盘中。为防止程序异常而导致数据丢失,采用了WAL机制,即2小时内记录的数据存储在内存中的同时,还会记录一份日志,存储在block下的wal目录中。当程序再次启动时,会将wal目录中的数据写入对应的block中,从而达到恢复数据的效果。
当删除数据时,删除条目会记录在tombstones 中,而不是立刻删除。每个block都是一个独立的数据库:
prometheus采用的存储方式称为“时间分片”,每个block都是一个独立的数据库。优势是可以提高查询效率,查哪个时间段的数据,只需要打开对应的block即可,无需打开多余数据。
数据备份与恢复
数据备份:
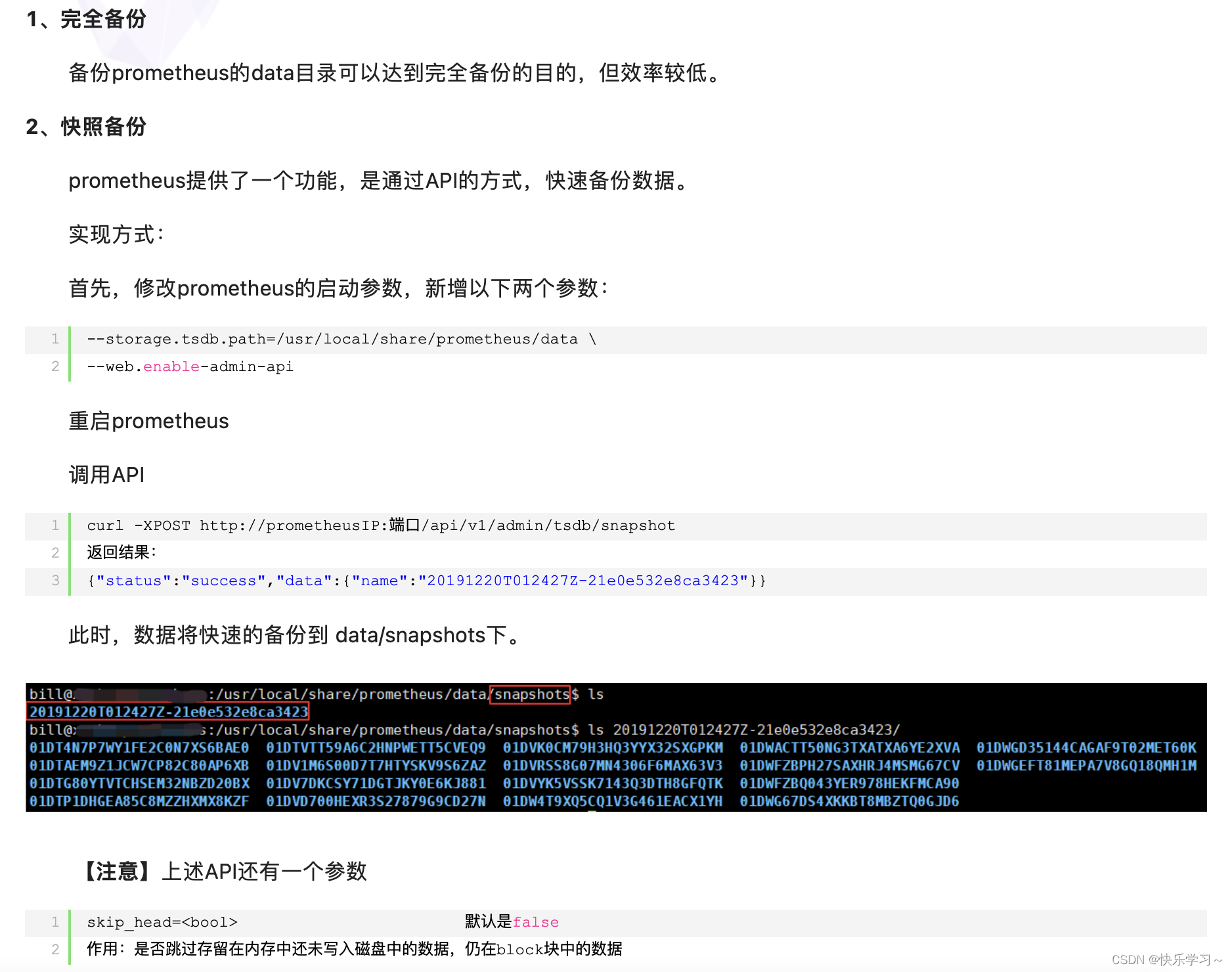
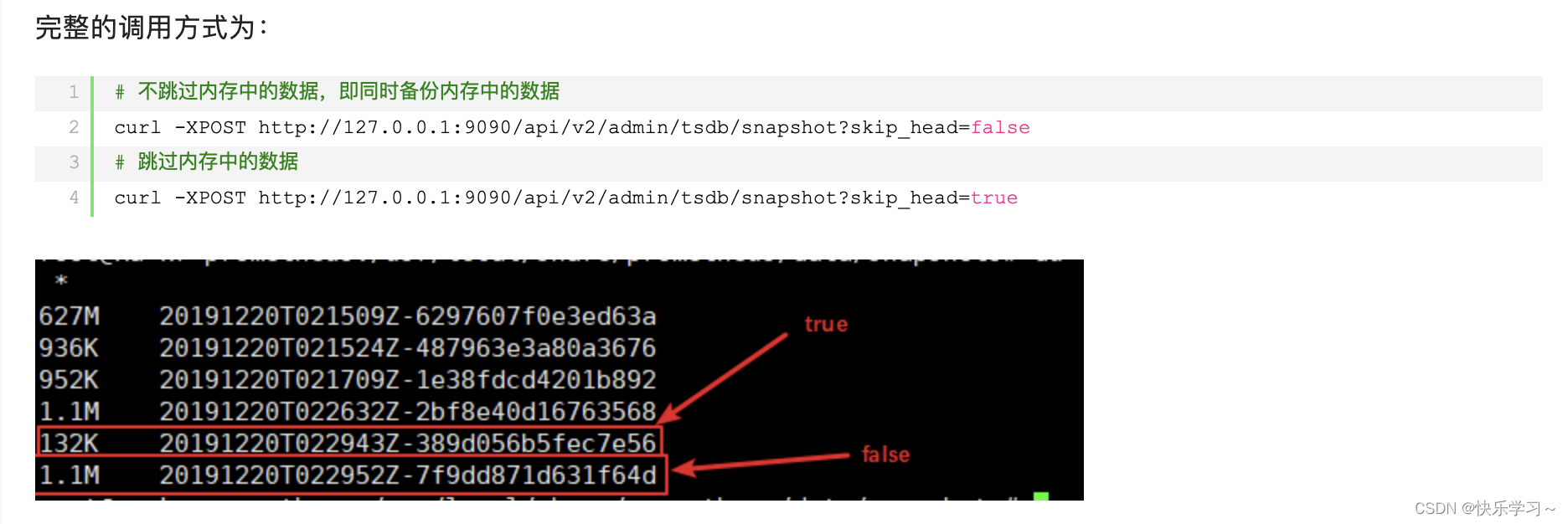
数据恢复:

prometheus数据存储目录
example:
./data ├── 01BKGV7JBM69T2G1BGBGM6KB12 │ └── meta.json ├── 01BKGTZQ1SYQJTR4PB43C8PD98 │ ├── chunks │ │ └── 000001 │ ├── tombstones │ ├── index │ └── meta.json ├── chunks_head │ └── 000001 └── wal # 预写日志 ├── 000000002 └── checkpoint.00000001 └── 00000000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
每种文件作用解析:
01BKGV7JBM69T2G1BGBGM6KB12:block ID,这类命名的目录是一个完整的block meta.json:是这个block的元信息 chunks:目录下存储每一个Block中的所有的Chunk,目录下每个文件都是一个chunk数据单元 Index:文件是该Chunk的索引文件 tombstones:数据删除记录文件,记录的是删除信息 wal:保存了内存里最近2小时的数据,用于重启后恢复最近两小时里内存的数据 chunks_head:磁盘内存映射头块 checkpoint:checkpoint机制会将wal 清理过后的数据做过滤写成新的段, 然后checkpoint文件被命名为创建 checkpoint的最后一个段号checkpoint.X- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
每种文件格式解析
meta.json:
// example { "ulid": "01EM6Q6A1YPX4G9TEB20J22B2R", "minTime": 1602237600000, "maxTime": 1602244800000, "stats": { "numSamples": 553673232, "numSeries": 1346066, "numChunks": 4440437 }, "compaction": { "level": 1, "sources": [ "01EM65SHSX4VARXBBHBF0M0FDS", "01EM6GAJSYWSQQRDY782EA5ZPN" ] }, "version": 1 } // 内容解析 version:告诉我们如何解析元文件。 minTime,maxTime:是块中存在的所有块中的绝对最小和最大时间戳。 stats:告诉块中存在的Series、Samples和Chunks的数量。 compaction:讲述区块的历史。 * level:告诉这个块已经到了多少代。 * sources:告诉这个块是从哪些块创建的(即合并形成这个块的块)。如果它是从 Head 块创建的, 则sources设置为自身(01EM6Q6A1YPX4G9TEB20J22B2R在这种情况下)。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
chunks_head文件夹中的chunks:文件的最大大小保持在 128MiB
// example ┌──────────────────────────────┐ │ magic(0x0130BC91) <4 byte> │ ├──────────────────────────────┤ │ version(1) <1 byte> │ ├──────────────────────────────┤ │ padding(0) <3 byte> │ ├──────────────────────────────┤ │ ┌──────────────────────────┐ │ │ │ Chunk 1 │ │ │ ├──────────────────────────┤ │ │ │ ... │ │ │ ├──────────────────────────┤ │ │ │ Chunk N │ │ │ └──────────────────────────┘ │ └──────────────────────────────┘ // 内容解析 magic:将此文件标识为块文件 version:告诉我们如何解析这个文件 padding:适用于任何未来的标题 Chunk 1 - Chunk N:是块列表。 // 单个块的格式: ┌─────────────────────┬───────────────────────┬───────────────────────┬───────────────────┬───────────────┬──────────────┬────────────────┐ | series ref <8 byte> | mint <8 byte, uint64> | maxt <8 byte, uint64> | encoding <1 byte> | len| data │ CRC32 <4 byte> │ └─────────────────────┴───────────────────────┴───────────────────────┴───────────────────┴───────────────┴──────────────┴────────────────┘ series ref:它是用于访问内存中series的series ID mint和maxt:块的样本中看到的最小和最大时间戳 encoding:是用于压缩块的编码 len:是从这里开始的字节数data,是压缩块的实际字节数。 CRC32:是上述chunk内容的校验和,用于校验数据的完整性。 // 块如何被读取 series ref 为 8 个字节。前4个字节告诉文件块所在的文件号,最后4个字节告诉文件中块开始的偏移量 如果块在文件中00093并且series ref从文件中的字节偏移开始1234: 那么该块的引用将是(93 << 32) | 1234(左移位,然后按位或)。 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
block文件夹中的chunks:该chunks目录包含一系列编号的文件,每个文件的上限为 512MiB。接下来分析此目录中单个文件的格式
单个 chunk 的时间跨度默认是 2 小时,Prometheus 后台会有合并操作,把时间相邻的 block 合到一起
// example ┌──────────────────────────────┐ │ magic(0x85BD40DD) <4 byte> │ ├──────────────────────────────┤ │ version(1) <1 byte> │ ├──────────────────────────────┤ │ padding(0) <3 byte> │ ├──────────────────────────────┤ │ ┌──────────────────────────┐ │ │ │ Chunk 1 │ │ │ ├──────────────────────────┤ │ │ │ ... │ │ │ ├──────────────────────────┤ │ │ │ Chunk N │ │ │ └──────────────────────────┘ │ └──────────────────────────────┘ // 内容解析 magic:将此文件标识为块文件 version:告诉我们如何解析这个文件 padding:适用于任何未来的标题 Chunk 1 - Chunk N:是块列表。 // 单个块的格式: ┌───────────────┬───────────────────┬──────────────┬────────────────┐ │ len│ encoding <1 byte> │ data │ CRC32 <4 byte> │ └───────────────┴───────────────────┴──────────────┴────────────────┘ // 作用:这里面存的是时序数据,文件中的块由 uint64 从index文件中引用, // uint64 由文件内偏移量(低 4 个字节)和段序列号(高 4 个字节)组成 // 即:index中的数据条目有一个64bit的引用记录,其中四个字节存数据在哪个文件(段文件序列号), // 另外四个字节存文件内偏移量,这样就能找到每个记录对应的chunk数据在哪个文件的哪个位置 // 这里的chunk和上面的head chuank相比,少了series ref, mint和maxt,为什么不需要呢 // 因为series ref, mint和maxt的信息在index文件里面有,我们就是根据index文件里的 // series ref, mint和maxt来查找chunk里的数据的,因此这里不需要存 // 原因解析: // https://ganeshvernekar.com/blog/prometheus-tsdb-persistent-block-and-its-index/ - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
index:
┌────────────────────────────┬─────────────────────┐ │ magic(0xBAAAD700) <4b> │ version(1) <1 byte> │ ├────────────────────────────┴─────────────────────┤ │ ┌──────────────────────────────────────────────┐ │ │ │ Symbol Table │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Series │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Label Index 1 │ │ │ ├──────────────────────────────────────────────┤ │ │ │ ... │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Label Index N │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Postings 1 │ │ │ ├──────────────────────────────────────────────┤ │ │ │ ... │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Postings N │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Label Offset Table │ │ │ ├──────────────────────────────────────────────┤ │ │ │ Postings Offset Table │ │ │ ├──────────────────────────────────────────────┤ │ │ │ TOC │ │ │ └──────────────────────────────────────────────┘ │ └──────────────────────────────────────────────────┘ // 内容解析 magic:编号将该文件标识为索引文件 version:告诉我们如何解析这个文件 TOC:该索引的入口点,它代表索引目录。 // TOC ┌─────────────────────────────────────────┐ │ ref(symbols) <8b> │ -> Symbol Table ├─────────────────────────────────────────┤ │ ref(series) <8b> │ -> Series ├─────────────────────────────────────────┤ │ ref(label indices start) <8b> │ -> Label Index 1 ├─────────────────────────────────────────┤ │ ref(label offset table) <8b> │ -> Label Offset Table ├─────────────────────────────────────────┤ │ ref(postings start) <8b> │ -> Postings 1 ├─────────────────────────────────────────┤ │ ref(postings offset table) <8b> │ -> Postings Offset Table ├─────────────────────────────────────────┤ │ CRC32 <4b> │ └─────────────────────────────────────────┘ // 作用解析 它告诉我们索引的各个组成部分到底从哪里开始(文件中的字节偏移量)。 我已经在上面的索引格式中标记了每个参考指向的内容。 下一个组件的起点也告诉我们各个组件的终点在哪里。 如果任何参考文献是0,则表明索引中不存在相应的部分,因此应在阅读时跳过。 由于TOC是固定大小,因此文件的最后 52 个字节可以作为TOC. 正如您将在接下来的部分中注意到的那样,每个组件都有自己的校验和,即CRC32检查底层数据的完整性。 // Symbol Table // 此部分包含已删除重复字符串的排序列表,这些字符串可在此块中所有系列的标签对中找到。 // 例如,如果系列是{a="y", x="b"},那么符号就是"a", "b", "x", "y" ┌────────────────────┬─────────────────────┐ │ len <4b> │ #symbols <4b> │ ├────────────────────┴─────────────────────┤ │ ┌──────────────────────┬───────────────┐ │ │ │ len(str_1)│ str_1 │ │ │ ├──────────────────────┴───────────────┤ │ │ │ . . . │ │ │ ├──────────────────────┬───────────────┤ │ │ │ len(str_n) │ str_n │ │ │ └──────────────────────┴───────────────┘ │ ├──────────────────────────────────────────┤ │ CRC32 <4b> │ └──────────────────────────────────────────┘ len:这部分的占用字节数 symbols:这部分存储的符号数 len(str_n) │ str_n :是一个符号的长度和内容 作用: 索引中的其他部分可以为任何字符串引用此符号表,从而显着减小索引大小。 符号在文件中开始的字节偏移量(即 的开头len(str_i))形成了相应符号的引用, 该符号可以在其他地方使用,而不是实际的字符串。 当您需要实际字符串时,可以使用偏移量从该表中获取它。 // Series ┌───────────────────────────────────────┐ │ ┌───────────────────────────────────┐ │ │ │ series_1 │ │ │ ├───────────────────────────────────┤ │ │ │ . . . │ │ │ ├───────────────────────────────────┤ │ │ │ series_n │ │ │ └───────────────────────────────────┘ │ └───────────────────────────────────────┘ 每个系列条目都是 16 字节对齐的,这意味着系列开始的字节偏移量可以被 16 整除。 因此,我们将系列的 ID 设置为offset/16偏移量指向系列条目开始的位置。 此 ID 用于引用该系列,并且每当您想要访问该系列时,您都可以通过执行 获取索引中的位置ID*16。 每个series条目都包含系列的标签集和对属于该系列的所有块的引用: ┌──────────────────────────────────────────────────────┐ │ len │ ├──────────────────────────────────────────────────────┤ │ ┌──────────────────────────────────────────────────┐ │ │ │ labels count │ │ │ ├──────────────────────────────────────────────────┤ │ │ │ ┌────────────────────────────────────────────┐ │ │ │ │ │ ref(l_i.name) │ │ │ │ │ ├────────────────────────────────────────────┤ │ │ │ │ │ ref(l_i.value) │ │ │ │ │ └────────────────────────────────────────────┘ │ │ │ │ ... │ │ │ ├──────────────────────────────────────────────────┤ │ │ │ chunks count │ │ │ ├──────────────────────────────────────────────────┤ │ │ │ ┌────────────────────────────────────────────┐ │ │ │ │ │ c_0.mint │ │ │ │ │ ├────────────────────────────────────────────┤ │ │ │ │ │ c_0.maxt - c_0.mint │ │ │ │ │ ├────────────────────────────────────────────┤ │ │ │ │ │ ref(c_0.data) │ │ │ │ │ └────────────────────────────────────────────┘ │ │ │ │ ┌────────────────────────────────────────────┐ │ │ │ │ │ c_i.mint - c_i-1.maxt │ │ │ │ │ ├────────────────────────────────────────────┤ │ │ │ │ │ c_i.maxt - c_i.mint │ │ │ │ │ ├────────────────────────────────────────────┤ │ │ │ │ │ ref(c_i.data) - ref(c_i-1.data) │ │ │ │ │ └────────────────────────────────────────────┘ │ │ │ │ ... │ │ │ └──────────────────────────────────────────────────┘ │ ├──────────────────────────────────────────────────────┤ │ CRC32 <4b> │ └──────────────────────────────────────────────────────┘ 含义解析: labels count:这个series数据里有多少个label对 ref(l_i.name) 和ref(l_i.value) :我们不存储实际的字符串本身,而是使用符号表中的符号引用, 利用这个引用去查符号表就可以 chunks count:这个series对应的时序数据由多少个chunk块来存放 mint,maxt,ref:这三个就是前面说的chunk相比head chunk少的三个数据就是存放在这里, 在查询series的时候,会根据index中这个series的chunk列表中每个chunk的 mint,maxt,ref,然后到chunk文件去查。这里ref是八个字节,里面四个字节 记录了数据在哪个chunk文件,四个字节记录了文件在那个chunk文件里的偏移量 // 在索引中保存mintandmaxt允许查询跳过查询时间范围不需要的块 // 上面在记录mint,maxt的时候,你可以看到除了第一个mint记录的是完整的时间戳, // 后面的其他mint,maxt记录的全是相对上一个数据的时间增量,以节省记录的空间 // 即第一个mint是varint,后面的全是uvarint,因为增量肯定是正数,使用uvarint, // 可以节省很多前缀0 // Label Offset Table和Label Index i 这两个不再使用了;它们是为向后兼容而编写的,但不会从最新的 Prometheus 版本中读取 // Postings Offset Table和Postings i // Postings 1- N存储了Postings列表,Postings Offset Table记录这些条目的偏移量。 // Postings是一个series ID,在index文件的上下文中,它是series条目在文件中开始的偏移量除16, // 因为它是 16 字节对齐的。 一个Postings的结构 ┌────────────────────┬────────────────────┐ │ len <4b> │ #entries <4b> │ ├────────────────────┴────────────────────┤ │ ┌─────────────────────────────────────┐ │ │ │ ref(series_1) <4b> │ │ │ ├─────────────────────────────────────┤ │ │ │ ... │ │ │ ├─────────────────────────────────────┤ │ │ │ ref(series_n) <4b> │ │ │ └─────────────────────────────────────┘ │ ├─────────────────────────────────────────┤ │ CRC32 <4b> │ └─────────────────────────────────────────┘ entries是下面series列表的数量 ref(series_1) 是series ID,也是series ref,也就是引用 // 具体Postings如何与Postings Offset Table一起配合记录, // 看下面讲完Postings Offset Table后的实例 // Postings Offset Table ┌─────────────────────┬──────────────────────┐ │ len <4b> │ #entries <4b> │ ├─────────────────────┴──────────────────────┤ │ ┌────────────────────────────────────────┐ │ │ │ n = 2 <1b> │ │ │ ├──────────────────────┬─────────────────┤ │ │ │ len(name) │ name │ │ │ ├──────────────────────┼─────────────────┤ │ │ │ len(value) │ value │ │ │ ├──────────────────────┴─────────────────┤ │ │ │ offset │ │ │ └────────────────────────────────────────┘ │ │ . . . │ ├────────────────────────────────────────────┤ │ CRC32 <4b> │ └────────────────────────────────────────────┘ // Postings Offset Table和Postings联合作用 // 举例: series: {a="b", x="y1"} with series ID 120, {a="b", x="y2"} with series ID 145 Postings list a="b" [120,145] x="y1" [120] x="y2" [145] Postings Offset Table: a="b" offset 1 x="y1" offset 2 x="y2" offset 3 查询series: {a="b", x="y1"} 时,查Postings Offset Table,得到a="b", x="y1"分别在 Postings list中的第一和第二,拿出Postings list中第一和第二这两个label-pair对应的series, 然后求合集,就得到这两个label-pair的公共series,也就是哪些series里同时有这两个标签 // Postings Offset Table作用 这里存储了很多的label-pair对的名字和值,以及offset,也就是他们的posting位置, 有了这些就能知道一个label-pari对在哪个posting中,然后posting中记录了label-pari对 对应的series的内容,然后series里面的ref又能找到chunk里面的时序数据,这样就对应起来了 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
-
相关阅读:
6、MySQL——模糊查询、字段控制查询
Prometheus Operator 与 kube-prometheus 之一-简介
教育、卫生和社会服务-省级面板数据数据(1994-2019年)
SwiftUI 中的几种毛玻璃效果
maven与nexus
Git 21 天打卡:day09-day21汇总
软件项目管理 6.3.用例点估算法
vscode常用插件
Linux:firewalled服务常规操作汇总
Java SSM Spring MVC 响应数据和结果视图+文件上传+异常处理+拦截器
- 原文地址:https://blog.csdn.net/qq_43684922/article/details/126686249
