-
使用数据挖掘提取软件静态缺陷模型(大数据专业毕业设计外文翻译及原文)
译文及原稿
译文题目: 使用数据挖掘提取软件静态缺陷模型
原稿题目: Extracting software static defect models using data mining
原稿出处: Ahmed H. Yousef.Extracting software static defect models
using data mining[J].A in Shams Engineering Journal.2015,
6(1):133-144.目录
使用数据挖掘提取软件静态缺陷模型 1
3. 方法论 1
3.1 软件度量 1
3.2 数据收集 2
3.3 数据挖掘模型 3
3.4 解决方案架构 4
4. 结果与讨论 4
4.1 单关联 4
4.2 贝叶斯分类器的结果 5
4.3 神经网络分类器的结果 6
4.4 关联规则分类器的结果 7
4.5 决策树分类器的结果 9
4.6 模型的准确性 9
3. Methodology 11
3.1. Software metrics 11
3.2. Data collection 11
3.3. Data mining models 13
3.4. Solution architecture 14
4. Results and discussion 14
4.1. Simple correlation 15
4.2. Results of Naı¨ve Bayes classifier 15
4.5. Results of decision tree classifier 19
(figure.9) 20
4.6. Accuracy of models 20使用数据挖掘提取软件静态缺陷模型
3. 方法论
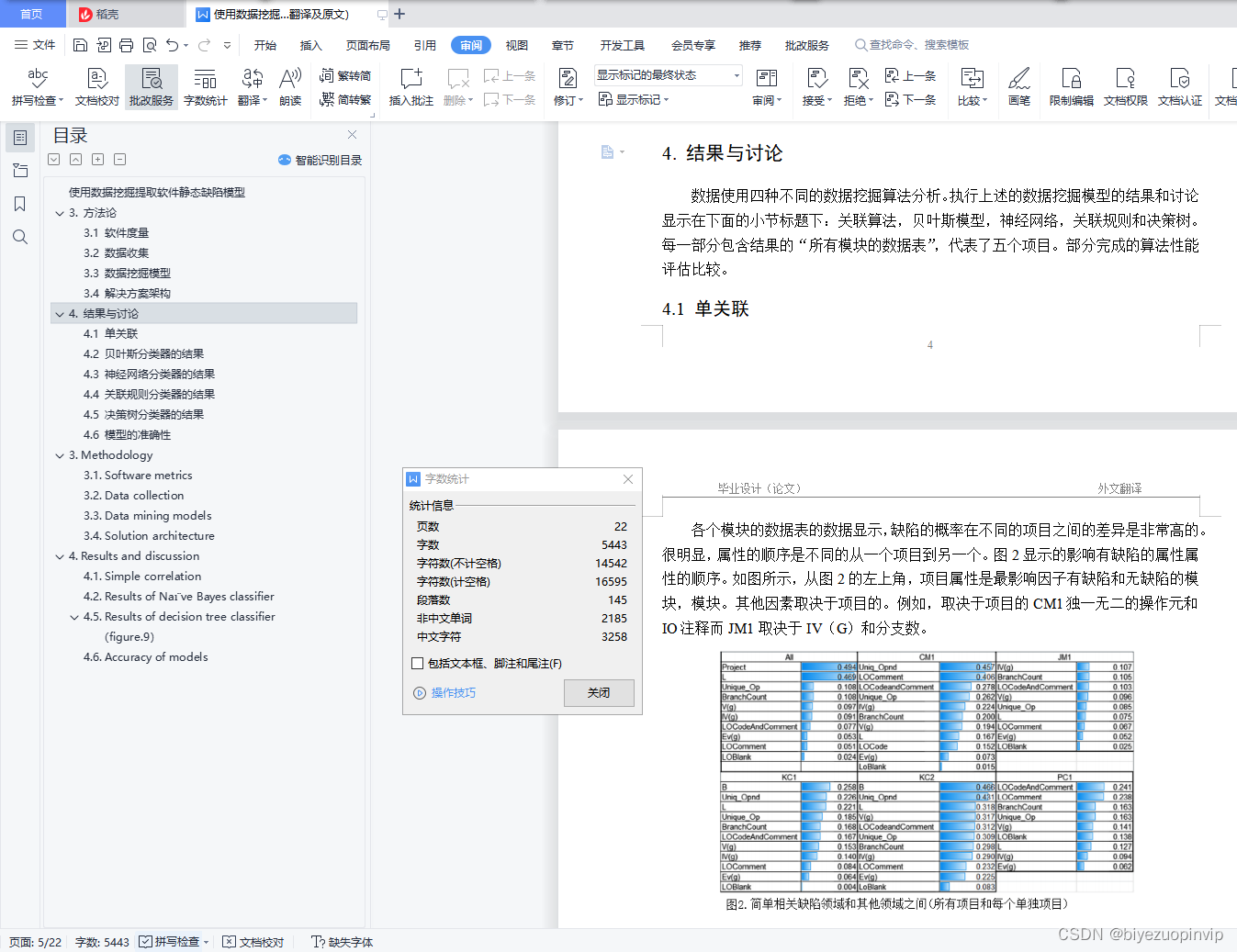
本文的方法将在下一个小节提出。这部分包括用于软件度量,数据采集程序,数据挖掘模型,解决方案的体系结构和使用性能标准。
3.1 软件度量
所使用的软件度量包括McCabe(麦凯布)度量,Halstead(霍尔斯特德)度量,分支数和五个不同措施代表行代码。麦凯布度量是四个软件度量的集合:圈复杂度,必要的复杂性,设计复杂性和行代码。圈复杂度,或是“V(G)(麦凯布圈复杂度)”, “线性独立的路径”措施的数量。根本复杂性,或是“eV(G)(麦凯布“必要的复杂性”)”上是一个流程图可以被“降低”。设计的复杂性,或是“'iv(G)(麦凯布“设计复杂性”)”,是一个模块的圈复杂度的降低流图。此流程图或是“G” 的模块是减少消除任意复杂性而不影响设计模块之间的相互关系。行代码测量根据麦凯布的行数约定。
霍尔斯特德指标分为三类:基础措施,派生的措施,和编码措施线。基础措施包括独特的运营商数量,独特的操作数,运算符和操作数的总总出现次数。派生的措施包括体积,困难,智力,努力写它的程序和时间。代码测量线包括空行,代码行,代码和注释行。
-
相关阅读:
闪烁霓虹灯文字动画
实战演练 | Navicat 常用功能之转储与运行 SQL 文件
HTML 表单笔记/练习
diskgenius数据恢复软件,亲测可用!
钟汉良日记:小白做副业的基本功:阅读
一次Python本地cache不当使用导致的内存泄露
完美解决回车事件使用window.open()打开新窗口行为被浏览器拦截的问题【亲测有效】
C语言暑假学习刷题——Day9
elment表格组件a-table属性formatter
ROS2与turtlebot4仿真入门教程-安装ROS2
- 原文地址:https://blog.csdn.net/newlw/article/details/126686109