-
R-CNN(Regions with CNN features)
论文信息
论文标题:
Rich feature hierarchies for accurate object detection and semantic segmentation
论文作者:
Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik, UC Berkeley
收录期刊/会议及年份:
CVPR, 2014
论文学习
学习目标:
-
了解 Overfeat 模型的移动窗口方法
-
当一张图片中存在多个类别、多个目标时,网络模型的输出结果是不定的;因此需要一些其他方法解决目标检测中多个类别、多个目标的问题,试图将一个检测问题简化成分类问题。
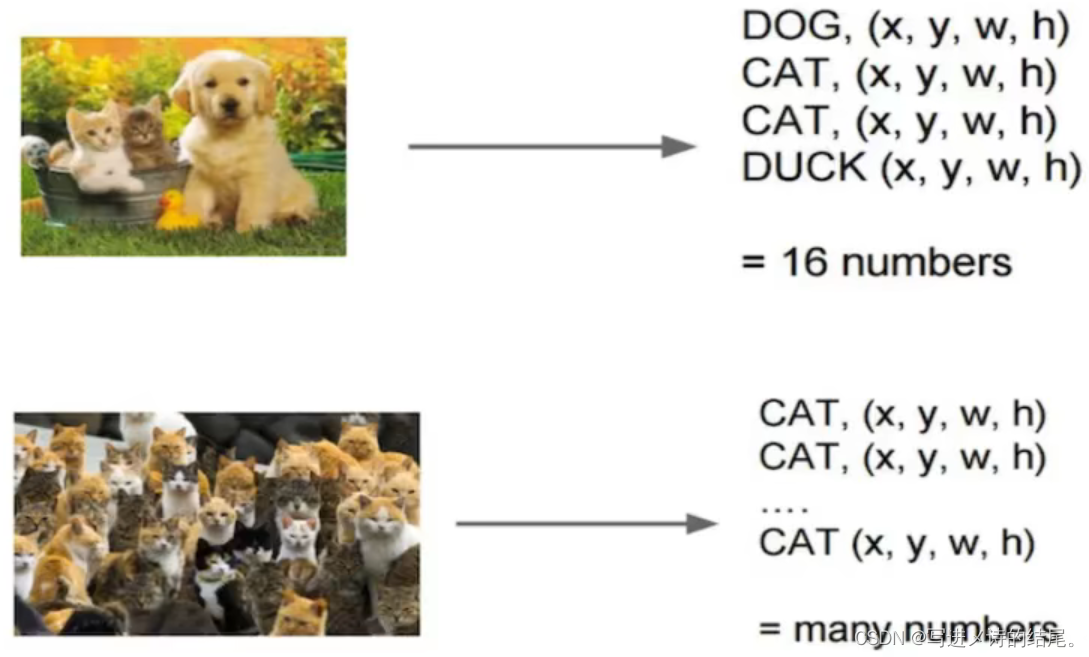
目标检测中的 overfeat 模型就是一个能解决该问题的方法。
-
滑动窗口: 目标检测的暴力方法是从左到右、从上到下的滑动窗口,利用分类来识别目标。
为了能够在不同观察距离处检测到不同的目标类型,我们使用具有不同大小和宽高比的窗口来进行滑动。如下图所示:

使用滑动窗口方法需要初始设定一个固定大小的窗口,但这就会遇到一个问题,不同的物体适应框是不一样的,即一种窗口无法很好的框中图片中所有出现的目标。
因此需要提前设定 K 个具有不同大小的窗口,每个窗口在图片上滑动 M-1 次得到 M 个图像块,总共能得到 K*M 个图像块。 -
通常会把要训练的所有图像进行一定的变形处理转换成统一大小的图像,每一个图像经过滑动窗口后得到的所有图像块被输入进 CNN 分类器中,提取特征后,使用分类器来进行分类识别,使用回归器来进行边框回归。
-
缺点: overfeat 模型使用的滑动窗口是一种暴力穷举的方法,会消耗大量的计算能力;而且有限种不同大小的窗口可能导致效果并不理想。
-
-
说明 R-CNN 的整个流程及完整结构
-
不使用暴力方法,而是采用候选区域(region proposal)方法;R-CNN 是以深度神经网络为基础的目标检测模型,R-CNN 在当时以优异的性能令世人瞩目,以 R-CNN 为基点,后续的 SPPNet、Fast R-CNN、Faster R-CNN 模型都是沿用这个思路。
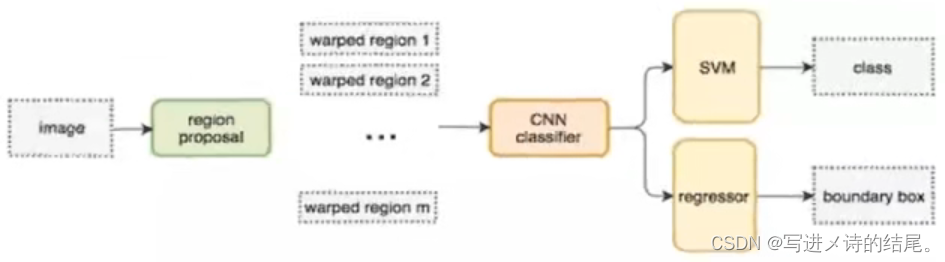
-
R-CNN 算法的具体步骤(以 AlexNet 网络为基准):
- 找出图片中可能存在目标的候选区域(region proposal),默认生成 2000 个候选区域;
- 将候选区域的大小调整为 227*227 以适应 AlexNet 网络的输入,而后将所有候选区域送入 CNN 以提取特征,每个候选区域都会生成 4096 维的特征向量,因此 AlexNet 网络最终会输出一个 2000*4096 维矩阵;
- 将 2000*4096 维特征经过 SVM 分类器(SVM 是二分类器,这里设定 20 种类别,因此有 20 个 SVM 分类器),获得一个 2000*20 的类别得分矩阵;
- 对 2000 个候选区域做非极大值抑制(NMS:Non-Maximum Suppression)处理,以便每个目标物体都能得到最高分的候选区域;
- 修正候选框,对 bounding box 做回归微调。
-
CNN 网络提取特征: 在候选区域的基础上提取出更高级、更抽象的特征,这些高级特征是作为下一步分类和回归的输入数据。

提取的这些特征将会保存在磁盘当中,这些提取的特征才是真正要训练的数据。
-
特征向量训练 SVM 分类器: 一张图片生成约 2000 个候选区域,经过 CNN 后就能得到 2000 个 4096 维的特征向量。
R-CNN 选用 SVM 进行二分类,这里设定有 20 个检测类别,则会提供 20 个不同类别的 SVM 分类器,每个 SVM 分类器都会对 2000 个候选区域的特征向量计算一次,这样就得到一个 2000*20 的类别得分矩阵。如下图所示:

-
-
了解选择性搜索算法
-
选择性搜索(SelectiveSearch,SS)算法: 首先将每个像素作为一组;然后计算每一组的纹理,并将两个最接近的组结合起来。为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。继续合并区域,直到所有区域都结合在一起。下图第一行展示了如何使区域增长,第二行中的蓝色矩形框代表合并过程中所有可能的感兴趣区域(RoI:Region of Interest)。

-
SS 算法在一张图片上提取约 2000 个候选区域,需要注意的是这些候选区域的长宽并不固定;而在使用 CNN 提取候选区域的特征向量时,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
-
-
了解 NMS 的处理过程及作用
-
非极大值抑制(NMS): 筛选候选区域,目的是通过抑制那些冗余的候选框,使得一个目标物体只保留一个最优候选框。
-
迭代过程:
-
假设图片中真实目标物体个数为 2,筛选之后得到 5 个候选框。如下图所示,A、C 候选框对应左边车辆,B、D、E 候选框对应右边车辆。

-
对 2000 个候选区域的类别得分进行概率筛选,概率阈值设定为 0.5(去掉不包含或只包含一小部分目标物体的候选框);
-
对类别得分在 0.5 以上的每一个候选框,都能找到一个对应的所属类别。对于右边车辆,B 是得分最高的候选框,将所有属于右边车辆的候选框与 B 候选框进行 IoU 计算,IoU>0.5 的候选框都删除;对于左边车辆,A 是得分最高的候选框,将所有属于左边车辆的候选框与 A 候选框进行 IoU 计算,IoU>0.5 的候选框都删除。
-
-
-
了解候选区域的修正过程
-
SS 算法得到的候选区域位置都是固定的,但我们通过筛选得到的最优候选框的位置与目标物体的 Ground Truth 相比不一定完全准确,因此需要对最优候选框进行修正(线性回归)。
-
回归用于修正最优候选框位置,使之回归于目标物体的 Ground Truth,默认这两个框之间是线性关系,因为最优候选框已经很接近 Ground Truth 了。

对于最优候选框 A = ( A x , A y , A w , A h ) A = (A_x, A_y, A_w, A_h) A=(Ax,Ay,Aw,Ah) 和真实框 G T = ( G x , G y , G w , G h ) GT = (G_x, G_y, G_w, G_h) GT=(Gx,Gy,Gw,Gh),我们要寻找一种变换 F,使得 F ( A x , A y , A w , A h ) = ( G x ′ , G y ′ , G w ′ , G h ′ ) F(A_x, A_y, A_w, A_h) = (G_x^{'}, G_y^{'}, G_w^{'}, G_h^{'}) F(Ax,Ay,Aw,Ah)=(Gx′,Gy′,Gw′,Gh′),其中 ( G x ′ , G y ′ , G w ′ , G h ′ ) ≈ ( G x , G y , G w , G h ) (G_x^{'}, G_y^{'}, G_w^{'}, G_h^{'}) \approx (G_x, G_y, G_w, G_h) (Gx′,Gy′,Gw′,Gh′)≈(Gx,Gy,Gw,Gh)。
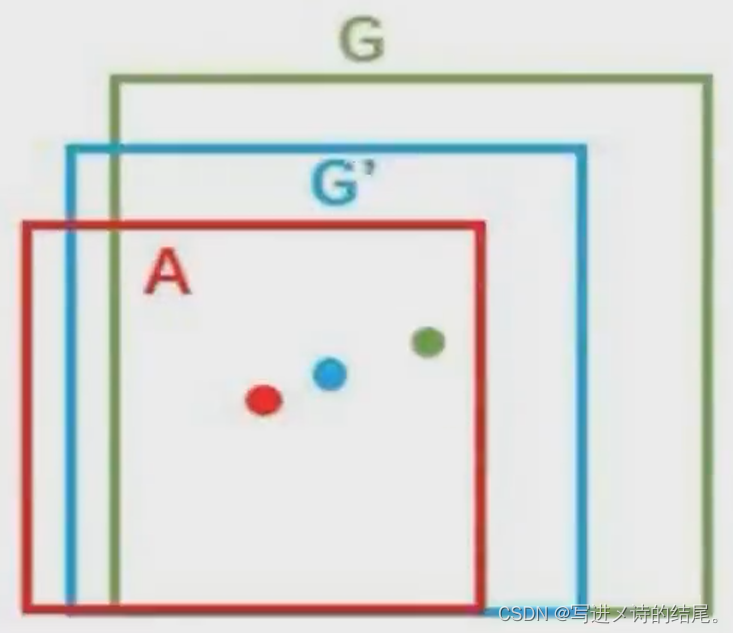
-
-
目标检测的评估指标
- IoU 交并比:

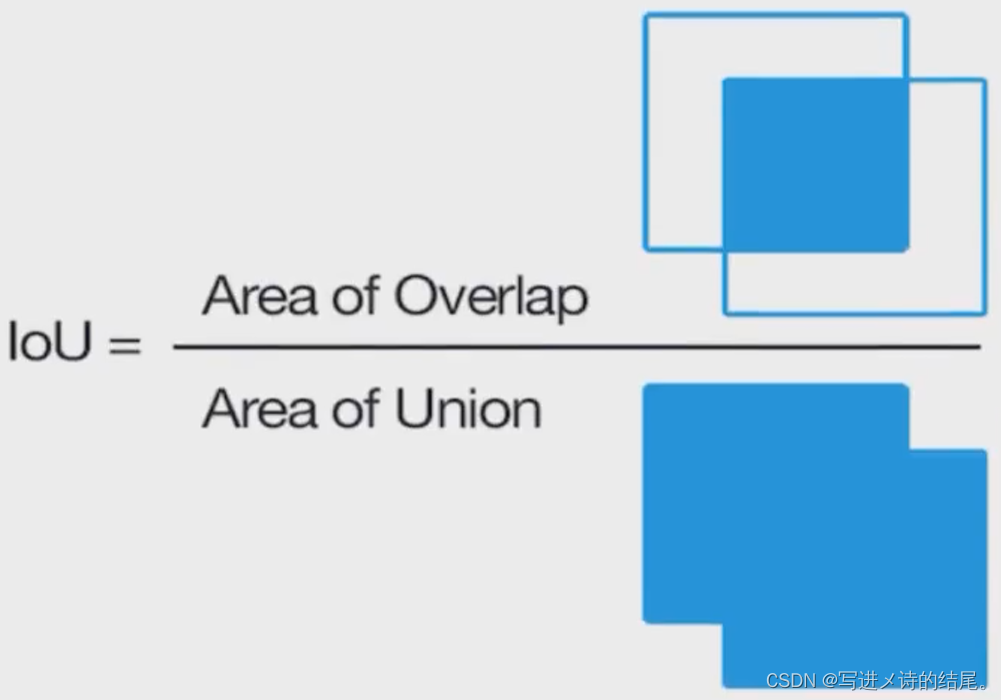
- 平均精确率(map:mean average precision):
定义:多个分类任务的 AP 的平均值。
mAP = 所有类别的 AP 之和 / 总的类别数
精度 precision = true positives / (true positives + false positives)
召回率 recall = true positives / (true positives + false negatives)
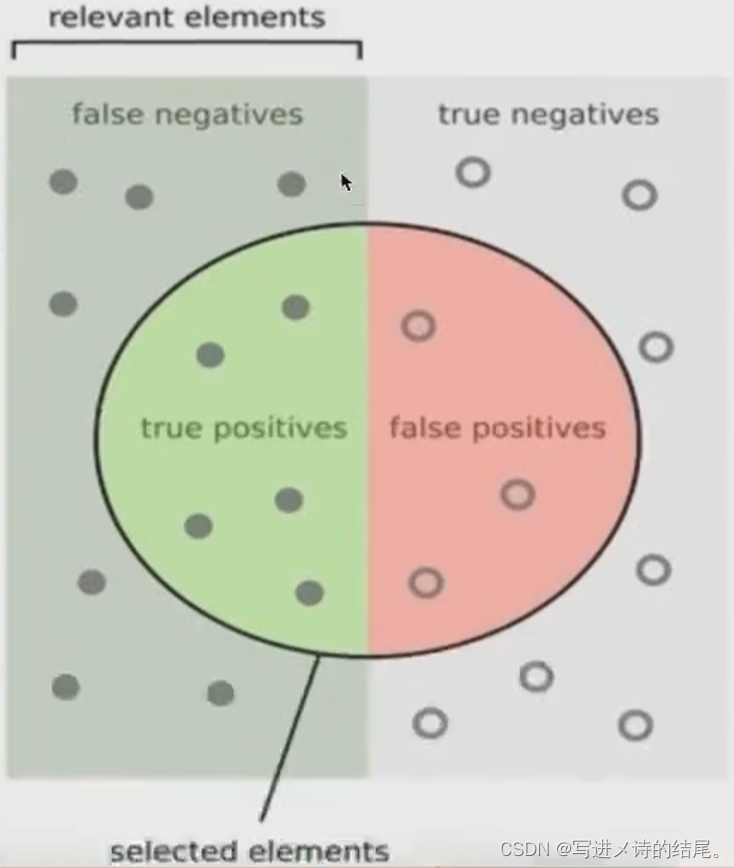

- IoU 交并比:
-
说明 R-CNN 的缺点
- 训练阶段多,微调网络 + 训练 SVM 分类器 + 训练边框回归器;
- 训练耗时严重,占用磁盘空间大。5000 张图像会产生几百G的特征文件;
- 处理速度慢,使用 GPU、VGG16 模型处理一张图像需要 47 s。
论文阅读
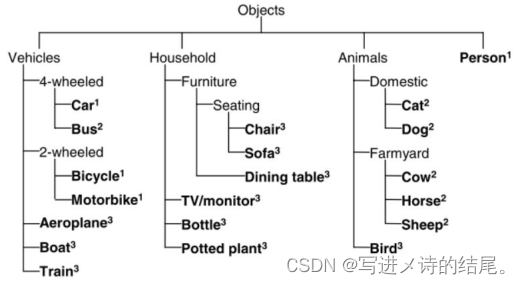
PASCAL VOC 2007 和 2012 数据集总共分 4 个大类:vehicle、household、animal、person,共有 20 个小类(加背景21 类)。
问题/背景:
(1)传统视觉特征 SIFT 和 HOG 用于检测任务,进展缓慢
(2)CNN 用于分类表现良好,能否用来提升检测性能
主要贡献:
(1)使用 SS 算法生成候选区域,替换 overfeat 中的滑动窗口方法(耗费计算资源)
(2)用 CNN 提取的深度特征,替换 SIFT 和 HOG 等传统视觉特征
(3)在大型辅助数据集上进行有监督预训练,在特定任务的小数据集上进行微调,以解决带标注数据稀缺导致难以训练大型 CNN 网络的问题
摘要:
提出了一种简单且可扩展的检测算法,与之前 VOC 2012 的最佳结果相比,mAP 提升了 30% 以上,达到了 53.3%。
当带标签的训练数据不足时,先对辅助任务进行有监督预训练,再对特定任务进行微调,可以产生显著的性能提升。
介绍:
过去十年,各种视觉识别任务的进展很大程度上是基于对 SIFT 和 HOG 的使用。但是从在典型的视觉识别任务 —— PASCAL VOC 目标检测上的表现来看,人们普遍认为在 2010-2012 期间进展缓慢。
可能存在分层的、多阶段的过程,可用于计算对视觉识别来说更富信息量的特征。
LeCun 等人证明了反向传播的随机梯度下降法对训练卷积神经网络是有效的。
CNN 在 20 世纪 90 年代曾得到广泛的应用,但后来随着支持向量机的兴起而退出潮流。2012 年,Krizhevsky 等人提出的算法在 ImageNet 大赛中的图像分类方面表现出了明显更高的准确率,重新点燃了人们对 CNN 的兴趣。Krizhevsky 等人的成功得益于对 120 万张带标签图像进行了大型 CNN 的训练,且在 CNN 中使用了 ReLU 和 Dropout 等技巧。
本文首次表明,与基于更简单的类 HOG 特征的系统相比,CNN 可以在 PASCAL VOC 上实现明显更好的目标检测性能。
为了实现更好的检测性能,重点解决了两个问题:(1)利用深度网络定位目标;(2)仅用少量带标注的检测数据训练大容量模型。在 CNN 中使用滑动窗口这一方法至少有 20 年了,通常用于受约束的目标类别,比如人脸和行人等。
为了保持高的空间分辨率,这些 CNN 通常只有两个卷积层和池化层。
对于输入图像,我们的方法会生成大约 2000 个与类别无关的候选区域,使用 CNN 从每个候选区域中提取固定长度的特征向量,然后使用特定类别的线性 SVM 分类器对每个候选区域进行分类。其中,我们使用一种简单的技术(affine image warping)将每个候选区域调整成固定大小以作为 CNN 的输入。
检测面临的一大挑战,是标签数据稀缺导致可用的数据量不足以训练一个大型 CNN。这个问题的传统解决方案是无监督的预训练+有监督的微调。本文证明了在数据稀缺的情况下,在大型辅助数据集上进行有监督预训练,然后在小数据集上进行特定任务的微调是一种有效的学习大容量 CNN 的方法。
我们的系统也很有效率,唯一特定于类的计算是相当小的矩阵向量乘积和贪婪的非极大值抑制。这种计算特性源于所有类别共享的特征,并且这些特征的维度也比以前使用的区域特征低两个数量级。
我们证明了一种简单的边框回归方法,能显著的减少错误定位。
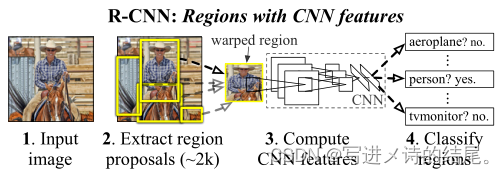
(1)输入一幅图像;(2)生成大约 2000 个自下而上的候选区域;(3)使用大型 CNN 提取每个候选区域的特征向量;(4)使用特定类别的线性 SVM 分类器对每个候选区域进行分类。
基于 R-CNN 的目标检测:
我们的目标检测系统由三个模块组成:第一个模块用于生成独立于类别的候选区域;第二个模块是一个大型卷积神经网络,用于从每个候选区域中提取一个固定长度的特征向量;第三个模块是一组特定类别的线性支持向量机。
模块设计:
候选区域: 最近的各种论文提供了生成独立于类别的候选区域的方法。
特征提取: 使用 AlexNet 网络从每个候选区域中提取 4096 维的特征向量。具体操作是将 227*227 的 RGB 图像块送入网络,并相继通过五个卷积层和两个全连接层,从而计算出特征。
在计算出候选区域的特征之前,必须先将其调整成固定大小以输入进 CNN 中。我们选择了一种最简单的调整方法,无论候选区域的大小和长宽比如何,我们都会将其紧密边界框中的所有像素扭曲环绕至所需大小。在扭曲之前,我们扩大紧密的边界框,以便在原始框周围有 p 个扭曲图像的上下文像素(这里 p = 16)。测试检测:
在测试时,我们在测试图像上运用 SS 算法提取约 2000 个候选区域,将每个候选区域调整成固定大小,并通过前向传播将它们输入进 CNN 中,以便计算出特征。然后,使用特定类别的支持向量机对每个提取到的特征向量进行评分。而后在给定图像中所有得分区域的情况下,运用贪婪的非极大值抑制来拒绝掉每一类别中与最高得分候选框具有较高重叠度的其他候选框。
运行分析: 两个特性使得检测更加高效:(1)CNN 中的所有参数都在所有类别中共享;(2)与其他方法相比,CNN 计算出的特征向量是低维的。
这种共享的结果,使得生成候选区域和计算特征所花费的时间(在 GPU 上为 13 秒/图像,在 CPU 上为 53 秒/图像)在所有类别中分摊。唯一特定于类别的计算是特征与支持向量机权重之间的点积以及非极大值抑制。在实践中,一个图像的所有点积都被批处理成一个矩阵与矩阵的乘积,特征矩阵通常为 2000*4096,支持向量机权重矩阵为 4096*N,N 为类别个数。训练:
有监督预训练: 我们仅使用图像级标注(边界框标签不适用于此数据)在大型辅助数据集上有区别地预训练 CNN。使用开源的 Caffe CNN 库进行预训练。
特定任务的微调: 为了使 CNN 适应检测任务,我们只用经过调整的候选区域继续通过 SGD 算法来训练 CNN 的参数。我们将 ImageNet 中的 1000 个分类层替换为随机初始化的 N+1 个分类层(其中,N 为类别个数,1 作为背景),除此之外,CNN 的架构没有改变。
我们将所有与 Ground Truth 的 IoU>=0.5 的候选框视为正类,其余候选框视为负类。我们以 0.001 的学习率启动 SGD。
在每一次 SGD 迭代中,我们均匀地采样 32 个前景和 96 个背景以构建一个大小为 128 的 mini-batch。目标类别分类器: 一旦提取了特征并应用了训练标签,我们就为每个类优化了一个线性支持向量机。
在微调过程中,我们将 IoU<0.5 的候选框视为负样本;而在训练 SVM 分类器时,我们将 IoU<0.3 的候选框视为负样本(IoU 阈值设定为 0.5,mAP 会降低 5 个点)。可视化、消融和错误模式:
可视化:
第一层的 filters 可以直接可视化,它们可以捕捉 oriented edges 和 opponent colors。
我们提出了一种简单的非参数方法,它能直接显示网络学习的内容。其想法是在网络中挑选出特定的单元(特征),并将其用作目标检测器。也就是说,我们计算神经元在大量候选区域上的激活,从最高激活到最低激活排序,执行非极大值抑制,然后显示得分最高的区域。消融实验:
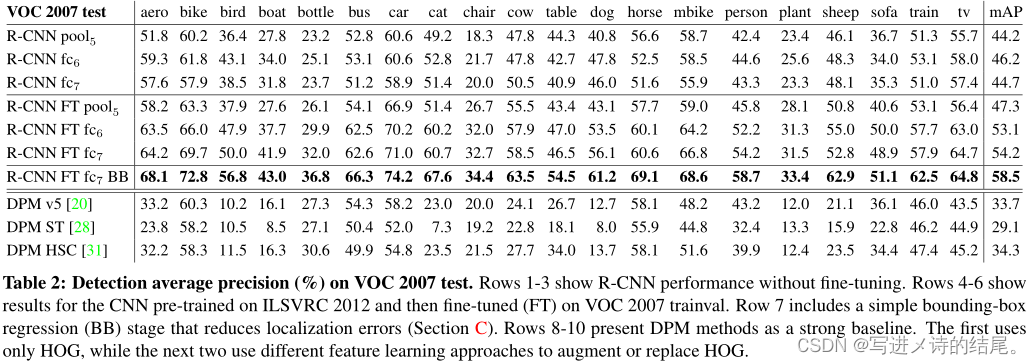
无微调: 所有 CNN 参数仅在大型辅助数据集(ILSVRC 2012)上进行了预训练。逐层分析性能表明, F C 7 FC_7 FC7 中的特征比 F C 6 FC_6 FC6 中的特征泛化能力更差,这意味着在不降低 mAP 的情况下,可以删掉 29%,即约 1680 万个 CNN 参数。更令人惊讶的是,同时去掉 F C 7 FC_7 FC7 和 F C 6 FC_6 FC6 也能得到相当好的结果,即使 P o o l 5 Pool_5 Pool5 的特征只由 CNN 参数的 6% 计算得到。这表明 CNN 的大部分表现力来自其卷积层,而不是连接层。
有微调: 改进是显著的,微调使 mAP 增加了 8 个点,达到了 54.2%。对于 F C 6 FC_6 FC6 和 F C 7 FC_7 FC7,微调的促进作用要比 P o o l 5 Pool_5 Pool5 大得多,这表明从 ImageNet 学习的 P o o l 5 Pool_5 Pool5 特征是通用的,大部分改进是通过在它们之上学习特定任务的非线性分类器来获得的。
网络架构:
本文的大部分结果使用了 Krizhevsky 等人提出的网络结构,但是我们发现结构的选择对 R-CNN 的检测性能有很大影响。采用 O-Net 的 R-CNN 性能显著优于采用 T-Net 的 R-CNN,mAP 从 58.5% 提升到了 66.0%。然而,O-Net 的前向传递花费的时间大约是 T-Net 的 7 倍。

边界框回归:
我们训练了一个线性回归模型来预测一个新的检测边框,该模型接收候选区域的 P o o l 5 Pool_5 Pool5 特征。这个简单的方法修复了大量错误定位的检测,将 mAP 提高了 3-4 个点。
训练数据:
R-CNN 的三个步骤需要用到训练数据:(1)CNN 的微调;(2)SVM 分类器的训练;(3)边界框的回归训练。
-
-
相关阅读:
我用规则引擎实现了消除if语句
Java的I/O框架
SpringBoot+Mybatis-Plus整合Sharding-JDBC5.1.1实现单库分表【全网最新】
22.括号生成
探究平台化设计的核心思想和Lattice(TMF)的设计原则
PICO首届XR开发者挑战赛正式启动,助推行业迈入“VR+MR”新阶段
开源|商品识别推荐系统
vue-cli中总提示组件没有正确注册
iptables学习
PlayWright(十二)- PO模式
- 原文地址:https://blog.csdn.net/weixin_48158964/article/details/126682193