-
1632. 矩阵转换后的秩 并查集+排序
1632. 矩阵转换后的秩
给你一个
m x n的矩阵matrix,请你返回一个新的矩阵answer,其中answer[row][col]是matrix[row][col]的秩。每个元素的 秩 是一个整数,表示这个元素相对于其他元素的大小关系,它按照如下规则计算:
- 秩是从 1 开始的一个整数。
- 如果两个元素
p和q在 同一行 或者 同一列 ,那么:- 如果
p < q,那么rank(p) < rank(q) - 如果
p == q,那么rank(p) == rank(q) - 如果
p > q,那么rank(p) > rank(q)
- 如果
- 秩 需要越 小 越好。
题目保证按照上面规则
answer数组是唯一的。示例 1:
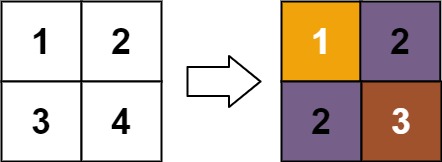
输入:matrix = [[1,2],[3,4]] 输出:[[1,2],[2,3]] 解释: matrix[0][0] 的秩为 1 ,因为它是所在行和列的最小整数。 matrix[0][1] 的秩为 2 ,因为 matrix[0][1] > matrix[0][0] 且 matrix[0][0] 的秩为 1 。 matrix[1][0] 的秩为 2 ,因为 matrix[1][0] > matrix[0][0] 且 matrix[0][0] 的秩为 1 。 matrix[1][1] 的秩为 3 ,因为 matrix[1][1] > matrix[0][1], matrix[1][1] > matrix[1][0] 且 matrix[0][1] 和 matrix[1][0] 的秩都为 2 。
示例 2:
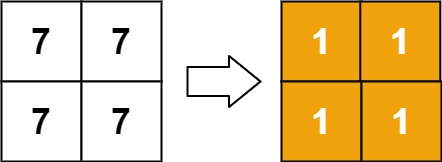
输入:matrix = [[7,7],[7,7]] 输出:[[1,1],[1,1]]
示例 3:
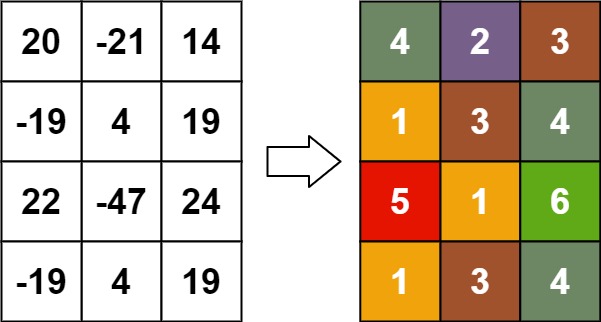
输入:matrix = [[20,-21,14],[-19,4,19],[22,-47,24],[-19,4,19]] 输出:[[4,2,3],[1,3,4],[5,1,6],[1,3,4]]
示例 4:
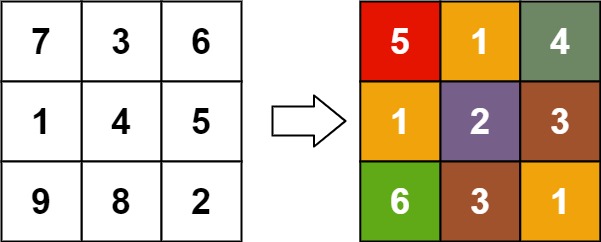
输入:matrix = [[7,3,6],[1,4,5],[9,8,2]] 输出:[[5,1,4],[1,2,3],[6,3,1]]
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 500-1e9 <= matrix[row][col] <= 1e9
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/rank-transform-of-a-matrix
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。做题结果
成功,不过写了好久,好几个小时。开始的做法是 图+拓扑,发现有问题,会不满足同行同列一起变化的条件。更换了思路,变成并查集+排序最终通过
方法:并查集+排序
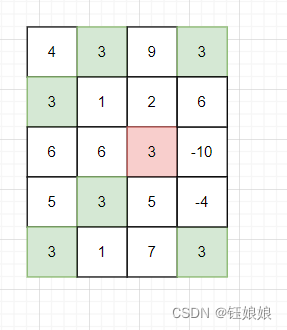
1. 并查集并在哪里?这题用并查集是藏的很好的。它的并在于相同数字的行列值相同,这意味着,他们需要一起改变。数组中完全有可能有多个转角,从而达成间接关系,而一起改变。如图,多个3可以一起改变,但是并不是值相同一定一起改变。红色的3和其他3的行列都不相同,因此,不和其他3一起改变。因此我们需要根据值和位置进行分组,于是就用到了并查集。
- class Solution {
- int[] parent;
- int[] sizes;
- public int[][] matrixRankTransform(int[][] matrix) {
- int m = matrix.length;
- int n = matrix[0].length;
- int[][] ans = new int[m][n];
- parent = new int[m*n];
- sizes = new int[m*n];
- for(int i = 0; i < m*n; i++){
- parent[i] = i;
- sizes[i] = 1;
- }
- //并查集
- for(int i = 0; i < m; i++){
- Map
- for(int j = 0; j < n; j++){
- if(map.containsKey(matrix[i][j])) connect(map.get(matrix[i][j]),i*n+j);
- else map.put(matrix[i][j],i*n+j);
- }
- }
- for(int j = 0; j < n; j++){
- Map
- for(int i = 0; i < m; i++){
- if(map.containsKey(matrix[i][j])) connect(map.get(matrix[i][j]),i*n+j);
- else map.put(matrix[i][j],i*n+j);
- }
- }
- Set
[] cnt = new HashSet[m*n]; - Arrays.setAll(cnt,o->new HashSet<>());
- for(int i = 0; i < m*n; i++){
- int p = root(i);
- cnt[p].add(i);
- }
- List
list = new ArrayList<>(); - for(int i = 0; i < m*n; i++) list.add(i);
- list.sort((a,b)->matrix[a/n][a%n]-matrix[b/n][b%n]);
- int[] mlines = new int[m];
- int[] mcols = new int[n];
- for(int i = 0; i < m*n; i++){
- int id = list.get(i);
- int x = id/n;
- int y = id%n;
- //System.out.println(matrix[x][y]);
- int rid = root(id);
- sizes[rid]--;
- if(sizes[rid]==0){
- int value = 0;
- for(Integer item:cnt[rid]){
- value = Math.max(Math.max(mlines[item/n]+1,mcols[item%n]+1),value);
- }
- for(Integer item:cnt[rid]){
- ans[item/n][item%n]=value;
- mlines[item/n]=value;
- mcols[item%n]=value;
- }
- }
- }
- return ans;
- }
- private void connect(int a, int b){
- int ra = root(a);
- int rb = root(b);
- if(ra==rb) return;
- if(sizes[ra]>=sizes[rb]){
- parent[rb] = ra;
- sizes[ra] += sizes[rb];
- }else{
- parent[ra] = rb;
- sizes[rb] += sizes[ra];
- }
- }
- private int root(int a){
- while(parent[a]!=a){
- parent[a] = parent[parent[a]];
- a = parent[a];
- }
- return a;
- }
- }
2. 分组后的处理。小的数字一定要分配更小的值,大的数字一定分配更大的值,因此,我们完全可以把所有元素的行列索引,按照从小到大排序,依次放入。
3. 相同值是需要一起放入的。所以当一个值完成放置后,需要处理对应并查集位置-1,当所有并查集元素都完成放入操作后,即可填写这一组并查集元素的值。
4. 每次填好id后,更新对应行列的最大id。后续放入的值是并查集的所有元素,行列填入的最大值+1。原因是这些元素必须要填写相同的值,又要保证不同元素值不同。
-
相关阅读:
TCP 连接管理机制(二)——TCP四次挥手的TIME_WAIT、CLOSE_WAIT状态
【Python Odyssey】1-1 | Python初见面
千字文||无聊又数了一下千字文字数
关于WPF template使用FindName查找控件方法问题。
联想小新如果使用蓝牙鼠标在关闭了触摸板的情况下不小心关掉了蓝牙该如何处理?
【PHP框架 | Laravel8 系列6】 - 控制器
Excel VBA | 一键批量生成对账单(功能优化版本)
案例分析
postman的断言、关联、参数化、使用newman生成测试报告
MySQL分页查询的5种方法
- 原文地址:https://blog.csdn.net/yu_duan_hun/article/details/126681940
