-
pytorch模型的保存与加载
torch.save 与 torch.load
模型保存有两种形式,一种是保存模型的
state_dict(),只是保存模型的参数。那么加载时需要先创建一个模型的实例 model,之后通过torch.load()将保存的模型参数加载进来,得到dict,再通过model.load_state_dict(dict)将模型的参数更新。另一种是将整个模型保存下来,之后加载的时候只需要通过
torch.load()将模型加载,即可返回一个加载好的模型。
具体可参考:PyTorch 模型的保存与加载。torch.save 函数有两种保存方式:一种是保存整个模型,此时模型的 type 应该为继承自 nn.Module 的类;另一种是仅保存模型的参数,此时模型的type应该为有序字典即类 OrderedDict。
保存完整的模型
我在通过两个神经元的极简模型,清晰透视 Pytorch 工作原理中构建了两个神经元的网络。以这个为例,我在模型训练完成后保存成 pt 文件,然后再加载测试。代码如下:
import torch import torch.nn as nn class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(1, 2) self.fc2 = nn.Linear(2, 1) def forward(self, x): x = torch.sigmoid(self.fc1(x)) x = self.fc2(x) return x net = Net() x = torch.linspace(0, 1, 10).reshape(10, 1) y = x*x - 0.5*x + 1.5625 import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr = 0.001) for n in range(0, 100000): optimizer.zero_grad() loss = sum(abs(net(x) - y)) loss.backward() optimizer.step() if n % 1000 == 0: print(n, loss) print('Finished Training!') # 保存模型 torch.save(net, "/home/yeping/mynet.pt") # 加载模型 net2 = torch.load( "/home/yeping/mynet.pt") # 测试加载的模型 import matplotlib.pyplot as plt plt.plot(x, y, "k*") z=[] x = torch.linspace(0,1,100).reshape(100,1) for xx in x: zz = net2(xx) z.append(zz) plt.plot(x, z, "b-")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
最后显示图片:
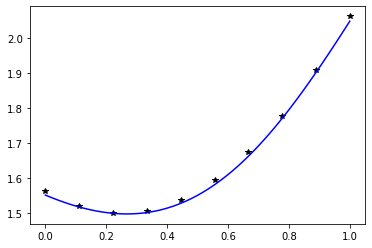
仅依靠 pt 文件加载模型
实际上,仅写测试代码也是可以。这说明 pt 文件包含了模型的结构定义和权重信息。
import torch import torch.nn as nn # 加载模型 net2 = torch.load( "/home/yeping/mynet.pt") # 测试加载的模型 import matplotlib.pyplot as plt x = torch.linspace(0, 1, 10).reshape(10, 1) y = x*x - 0.5*x + 1.5625 plt.plot(x, y, "k*") z=[] x = torch.linspace(0,1,100).reshape(100,1) for xx in x: zz = net2(xx) z.append(zz) plt.plot(x, z, "b-")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行后,结果与上面一样。
仅保存模型的参数
下面的例子中仅仅保存模型参数:
import torch import torch.nn as nn class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(1, 2) self.fc2 = nn.Linear(2, 1) def forward(self, x): x = torch.sigmoid(self.fc1(x)) x = self.fc2(x) return x net = Net() x = torch.linspace(0, 1, 10).reshape(10, 1) y = x*x - 0.5*x + 1.5625 import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr = 0.001) for n in range(0, 100000): optimizer.zero_grad() loss = sum(abs(net(x) - y)) loss.backward() optimizer.step() if n % 1000 == 0: print(n, loss) print('Finished Training!') # 保存模型 torch.save(net.state_dict(), "/home/yeping/mynet-wts.pt") # 加载模型 net2 = Net() net2.load_state_dict(torch.load("/home/yeping/mynet-wts.pt")) # 测试加载的模型 import matplotlib.pyplot as plt plt.plot(x, y, "k*") z=[] x = torch.linspace(0,1,100).reshape(100,1) for xx in x: zz = net2(xx) z.append(zz) plt.plot(x, z, "b-")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
查了看了一下
net.state_dict()的内容,整理如下:OrderedDict ( [ ( 'fc1.weight', tensor ( [ [-3.5805], [-1.4185] ] ) ), ( 'fc1.bias', tensor ( [ 3.4771, -0.8718 ] ) ), ( 'fc2.weight', tensor ( [ [ -1.7204, 1.7042 ] ] ) ), ( 'fc2.bias', tensor( [2.7291] ) ) ] )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
-
相关阅读:
深度学习课后week2 编程(识别猫)
小县城蔬菜配送小程序制作全攻略
【Java】Arrays类、static关键字
ST推出 28nm MCU ,NXP更狠,推出16nm MCU
美国多ip站群vps的五大优势
线程的概念和创建【javaee初阶】
浅谈一下Java锁机制
5 分钟完成 ZooKeeper 数据迁移
BiMPM实战文本匹配【上】
【kali-漏洞利用】(3.2)Metasploit基础(上):基础知识
- 原文地址:https://blog.csdn.net/quicmous/article/details/126679899
