-
架构师的 36 项修炼第09讲:系统的安全架构设计
本课时讲解系统的安全架构。

本节课主要讲 Web 的攻击与防护、信息的加解密与反垃圾。其中 Web 攻击方式包括 XSS 跨站点脚本攻击、SQL 注入攻击和 CSRF 跨站点请求伪造攻击;防护手段主要有消毒过滤、SQL 参数绑定、验证码和防火墙;加密手段,主要有单向散列加密、对称加密、非对称加密;信息过滤与反垃圾主要讨论分类算法和布隆过滤器。
Web 攻击与防护
XSS 攻击
先看 XSS 跨站点脚本攻击。XSS 攻击,顾名思义,就是通过构造一个非法的浏览器脚本,让用户跨站点去执行,从而达到攻击的目的。
URL 钓鱼攻击
如下图示例:用户登录了被攻击的服务器,比如微博的服务器,然后他收到了攻击者发送给他的一个含有恶意脚本的 URL,这个 URL 是指向微博服务器的。用户点击恶意 URL 以后,就会把 URL 提交给微博的服务器,同时这段 URL 里面还包含了一段可执行的恶意脚本,这个脚本也会被客户端去执行。在这个恶意脚本里面,会强制用户关注某个特定的微博账号,并发送一条含有恶意脚本的微博,当其他用户浏览点击微博的时候,会再一次执行同样的动作,以此来达到攻击不断扩散的目的。

直接攻击
除了通过上述 URL 钓鱼的方式进行攻击,还有一种攻击方式是,恶意的攻击者直接攻击被攻击的服务器。
如下图所示,攻击者发送一个含有恶意脚本的请求给被攻击的服务器,比如通过发布微博的方式向微博的服务器发送恶意请求,被攻击的服务器将恶意脚本存储到本地的数据库中,其他正常用户通过被攻击的服务器浏览信息的时候,服务器会读取数据库中含有恶意脚本的数据,并将其展现给正常的用户,在正常用户的浏览器上执行,从而达到攻击的目的。

XSS 攻击防御
XSS 攻击防御的主要手段有以下几种。
消毒
检查用户提交的请求中是否含有可执行的脚本,因为大部分的脚本都需要用尖括号等脚本语法,因此大部分的攻击也都包含尖括号这样的脚本语法,所以可以通过 HTML 转义的方式,比如把“>”转义为“>”这样的转义 HTML 字符,HTML 显示的时候还是正常的”>“,但是这样的脚本无法在浏览器上执行,也就无法达到攻击的目的。
HttpOnly
此外,XSS 攻击的目的是想利用客户端浏览器的权限去执行一些特定的动作,而这种权限通常是需要依赖 Cookie 的,所以可以通过限制脚本访问 Cookie,从而达到防止攻击的目的。也就是在 Cookie 上设置 HttpOnly 的属性,使恶意脚本无法获取 Cookie,避免被攻击脚本攻击。
SQL 注入攻击
SQL 注入是另外一种常见的攻击手段。恶意的攻击者在提交的请求参数里面,包含有恶意的 SQL 脚本。
如下图示例,在需要输入的参数 username 里面,注入了另外一条 SQL 语句“drop table users”,这是一条删除 users 表的命令。如果程序根据输入参数进行 SQL 构造,那么构造出来的就是这样两条 SQL:一条是 Select 根据用户名进行查询的 SQL 语句;另一条 SQL 就是删除 users 表。当这样的两条 SQL 被提交到数据库以后,数据库 user 表就会被删除,从而导致系统瘫痪。

SQL 攻击防御
消毒
解决 SQL 注入的手段,一种手段是消毒。通过拦截请求中的数据,对请求数据进行正则表达式匹配,如果请求数据里面包含有某些 SQL 语句,比如“drop table”,那么就对这些语句进行转义和消毒,插入一些特定的不可见字符或者进行编码转换,使其无法在数据库上执行,从而达到防御攻击的目的。
参数绑定
但是在实践中最常用、最有效、最高效的是第二种,通过 SQL 预编译手段,即将 SQL 命令和输入参数绑定,防止将输入参数中的数据当作 SQL 执行。也就是说访问数据库的 SQL,通过预编译的方式已经提交到了数据库,数据库收到请求参数以后,只会按照特定的 SQL 参数,按照已经编译好的执行命令去执行,所有提交的数据都会被当作参数,而不会当作 SQL 语句去执行。目前很多常用的 Web 数据库访问框架,比如 MyBatis、Hibernate 等 ORM 框架,都支持 SQL 预编译和参数绑定,能够避免 SQL 注入攻击。
CSRF 攻击
还有一种常见的攻击是跨站点请求伪造 CSRF,跨站请求伪造的攻击方式如下图所示。

用户先登录受信任的服务器,然后又访问了被攻击的服务器。被攻击了的服务器返回的响应里面包含着用户访问受信任的服务器的请求,用户在不知情的情况下执行了请求,从而达到了攻击者的目的。
CSRF 攻击防御
表单 Token
跨站请求伪造的防御手段,一种是使用表单 Token。要达到 CSRF 跨站请求伪造,用户必须要构造出来受信任站点的完整的请求参数才能够进行请求,那么如果请求参数是必须要在当前浏览器或者是应用中生成的,比如请求中包含必须要在特定场景下生成的 Token 才能够发送的请求,这样攻击者就无法构造这个 Token,也就无法进行攻击。通常这样的 Token 利用时间戳、用户设备指纹、页面内容等多方数据进行计算,服务器在收到请求后,对请求包含的 Token 进行校验,确定是否是合法的 Token,只有包含合法Token 的请求才会被执行。
验证码
另一种手段就是用验证码。CSRF 攻击是在用户不知情的情况下,去请求受信任的服务器,达到自己的攻击目的。对于一些比较敏感的操作,比如关于资金方面的操作,那么可以要求用户输入图片验证码或者手机验证码,才能够完成。这个时候用户就会发现自己被攻击了,避免执行被攻击的请求,从而防御 CSRF 攻击。
Web 应用防火墙
大部分的攻击都可以在请求和响应阶段进行拦截处理,所以不用每个程序自己去独立处理。在应用网关或者在请求接入的时候,可以设置一个统一的 Web 应用防火墙,对所有的请求响应进行拦截处理。
ModSecurity 就是这样一个开源的 Web 应用防火墙,如下图所示。它能够探测攻击并保护应用系统,既可以嵌入到 Web 应用服务器之内,也可以作为一个独立的应用程序启动。ModSecurity 最早是 Apache 服务器的一个模块,现在已经有了 Java、.net 多个版本,并且支持 Nginx。

ModSecurity 本身的架构设计也非常值得借鉴。ModSecurity 采用处理逻辑与规则集合分离的架构模式。处理逻辑负责请求和响应的拦截过滤、规则加载执行等功能。而规则集合则负责对具体的攻击的规则定义、模式识别、防御策略等功能。处理逻辑比较稳定,规则集合需要不断针对漏洞进行升级,这是一种可扩展的架构设计。
信息加解密
再看信息加解密技术。信息加解密技术主要分为三类,单向散列加密、对称加密和非对称加密。
单向散列加密
所谓的单向散列加密是指对一串明文信息进行单向散列加密以后,得到的密文信息是不可以解密的,也就是说给定一个密文,即使是加密者也无法知道它的明文是什么,加密是单向的,不支持解密。
单向散列加密的主要应用场景就是应用到用户密码加密上。我们知道将用户密码的明文直接存储到数据库中是比较危险的,如果数据库被内部员工泄露,或者是被黑客拖库以后,那么用户的密码就会被暴露出去。所以对用户密码进行解密是没有意义的,反而会造成密码不安全,事实上现在一般的应用系统都是对数据库的密码采用单向散列加密的方式进行保护的。
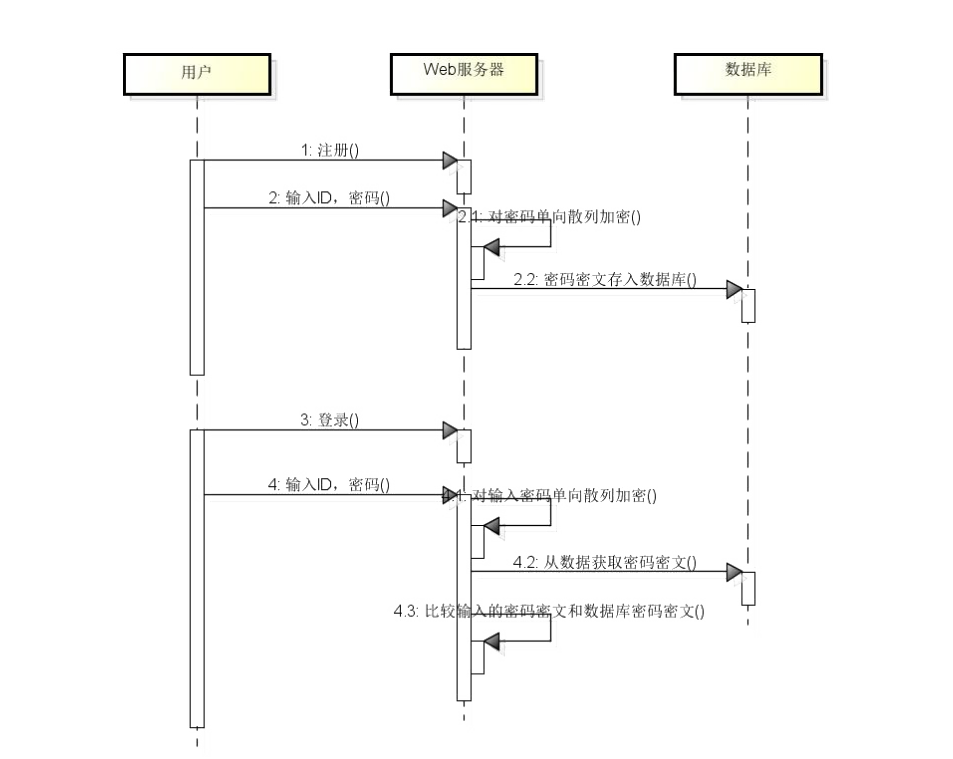
主要过程如下面架构时序图所示。用户在注册的时候需要输入密码,应用服务器得到用户输入的密码以后,调用单向散列加密算法,对密码进行加密,然后将加密后的密文存储到数据库中去。用户下一次登录的时候,用户在客户端依然需要输入密码,用户输入的密码发送到 Web 服务器以后,Web 服务器对输入的密码再进行一次单向散列加密,得到密文,然后和从数据库中取出来的密文进行对比,如果两个密文是相同的,那么用户的登录验证就是成功的。通过这种手段,既可以保证用户密码的安全性,也实现了对用户的身份认证。
因为常用单向散列算法,就这么几种,而用户常用的密码组合,也有一定的重复性,比如根据生日设置密码,根据姓名拼音设置密码等等,所以如果有足够多的密码明文和密文,建立一个明文和密文之间的映射表,虽然通过密文无法解密计算出来明文,但是知道密文以后,可以通过查表的方式去查找出来明文是什么。
所以现在常用的单向散列加密,不但使用算法进行加密,还在算法上加一些盐,其实也是类似于密钥一样性质的东西,如下图。这样不同的加盐参数加出来的密文,即使是有了明文和密文的映射表,也无法通过密文和映射表去查找得到明文了。

对称加密
对称加密,顾名思义,使用一个加密算法和一个密钥,对一段明文进行加密以后得到密文,然后使用相同的密钥和对应的解密算法,对密文进行解密,就可以计算得到明文,如下图所示。对称加密主要用于加密一些敏感信息,对密文进行信息传输和存储,但是在使用的时候,必须要解密得到明文信息的一些场景。

比如说用户的信用卡卡号,很多互联网电商网站支持用户使用信用卡进行支付,把用户的信用卡信息存储在自己的服务器,当用户支付的时候,直接用信用卡信息和银行通信,完成信用卡扣款支付。用户的信用卡卡号等信息需要在交易的时候,跟银行进行支付认证。但是如果直接把信用卡号、有效期、安全码存储在数据库中,是比较危险的,所以必须要对它进行加密。在数据库中存储密文,在使用的时候又必须要对密码进行解密,还原得到明文,才能够正常使用。所以这个时候就要使用对称加密算法,在存储的时候使用加密算法进行加密,在使用的时候使用解密算法进行解密。
非对称加密
所谓的非对称加密是指在加密的时候使用一个加密算法和一个加密密钥进行加密,得到一个密文,在解密的时候,必须要使用解密算法和解密密钥进行解密才能够还原得到明文,加密密钥和解密密钥完全不同,如下图所示。非对称加密的典型应用场景,就是我们常见的 HTTPS。HTTPS 加密就是一种非对称加密,用户在客户端进行网络通讯的时候,对数据使用加密密钥和加密算法进行加密,得到密文。到了数据中心的服务器以后,使用解密密钥和解密算法进行解密,得到明文。

在 HTTPS 这个场景中,由于所有的用户都要获得加密密钥,才能够对自己的明文进行加密,所以加密密钥通常也被叫作公钥,意思就是公开的密钥,谁都可以获得得到。但是解密密钥只有互联网系统后端服务器才能够拥有,只能由数据中心的服务器使用,所以也叫作私钥,也就是说谁都可以加密,但是只有自己才能解密,通过这种方式实现网络的安全传输,因为公钥本身就是公开的,所以也不需要担心密钥泄漏。同时由于公钥是对所有用户公开的,为了保证公钥本身的安全性和权威性,通常 HTTPS 的公钥和私钥使用权威的 CA 认证中心颁发的密钥证书。
使用非对称加密,还可以实现数字签名。用数字签名的时候是反过来的,自己用私钥进行加密,得到一个密文,但是其他人可以用公钥将密文解开,因为私钥只有自己才拥有,所以等同于签名。一段经过自己私钥加密后的文本,文本内容就等于是自己签名认证过的。
信息过滤与反垃圾
接下来看信息过滤与反垃圾,包括分类算法和布隆过滤器黑名单。
分类算法
分类算法,来看常用的贝叶斯分类算法,贝叶斯分类算法可以解决概率论中的一个典型问题。
如果有两个箱子,一号箱子里面放着红色球和白色球各 20 个,二号箱放有白色球 10 个,红色球 30 个。现在随机挑选一个箱子,取出来 1 个球的颜色是红色的,那么请问这只球来自于一号箱子的概率是多少?解决这类问题的方法就是使用条件概率,条件概率公式如下所示。

方程式左边 P(B|A) 表示的是在 A 条件发生的情况下,B 发生的概率是多少?在上图这个例子中,A 就是红色球,B 就是一号箱,P(B|A) 也就是问题中,在取出红色球的情况下,该球来自一号箱的概率是多少?计算公式是 P(A|B) 乘以 P(B) 除以 P(A),P(A|B) 是在一号箱中有红色球的概率,P(B) 是一号箱的概率,P(A) 是红色球的概率。也就是一号箱中有红色球的概率乘以一号箱的概率,再除以红色球的概率,来得到取出红色球的情况下是一号箱的概率。
实践中我们会使用贝叶斯分类算法进行垃圾邮件的识别。比如说我们统计现有的邮件,将邮件分为垃圾邮件和非垃圾邮件两类,然后再统计垃圾邮件中包含的文本特征的概率,以及非垃圾邮件中文本特征的概率。那么当我们收到一份邮件的时候,我们就可以根据这份邮件中的文本特征概率去计算它是垃圾邮件的概率。在这个例子里面,P(A) 是邮件中的文本特征,P(B) 就是垃圾邮件的概率,使用分类算法,根据文本特征计算垃圾邮件的概率。垃圾邮件过滤的整个的流程,如下图所示。

我们先对当前的邮件进行人工分类,分为垃圾邮件和非垃圾邮件两类,然后将这两类邮件输入分类算法进行训练,训练得到 P(A)、P(B) 以及 P(A|B) 这些概率值,然后当一份新邮件到达的时候,也就是待处理邮件到达的时候,我们将待处理邮件带入分类算法进行计算,也就是计算 P(B|A) 的值,然后根据计算出来的值,判断它是垃圾邮件还是正常邮件。
通过分类算法我们可以识别出来一份邮件是垃圾邮件还是非垃圾邮件。如果是垃圾邮件,那么发送垃圾邮件的邮箱地址通常也会被标记为黑名单地址,需要记录下来。对于一个邮箱系统而言,需要管理的黑名单是非常庞大的,如何管理这样庞大的一组黑名单邮箱的地址,最直观的解决手段就是使用哈希表。但是如果数量特别庞大,那么哈希表也会非常庞大,需要占用大量的内存空间。事实上,我们对黑名单里面这些邮件地址并不关心,我们只需要关心,一个邮件到达以后,它的发件人地址是不是在黑名单里就可以了。
布隆过滤器
更简单的办法就是使用布隆过滤器这样一种手段去记录邮箱地址黑名单。
如下图所示,布隆过滤器的算法实现是这样的。首先它开辟一块巨大的连续存储空间,比如说开辟一个 16G 比特的连续存储空间,也就是 2G 大的一个内存空间,并将这个空间所有比特位都设置为 0。然后对每个邮箱地址使用多种哈希算法,比如使用 8 种哈希算法,分别计算 8 个哈希值,并保证每个哈希值是落在这个 16G 的空间里的,也就是,每个 Hash 值对应 16G 空间里的一个地址下标。然后根据计算出来的哈希值将对应的地址空间里的比特值设为 1,这样一个邮箱地址就可以将 8 个比特位设置为 1。当检查一个邮箱地址是否在黑名单里的时候,只需要将邮箱地址重复使用这 8 个哈希算法,计算出 8 个地址下标,然后检查这 8 个地址下标里面的二进制数是否全是 1,如果全是 1,那么表示它就是在黑名单里头。使用布隆过滤器,记录同样大小的邮箱黑名单,可以比使用哈希表节约更多的内存空间。

使用布隆过滤器需要注意的是,该过滤器存在误杀的情况。也就是说,一个非黑名单邮箱地址对应的 8 个比特位的值,正好被其它的黑名单邮箱地址都设为 1 了。那么在检查比特位时,该邮箱地址就会被误认为黑名单邮箱,被错误拦截。
总结回顾
回顾本节课内容如下。
主要的几种攻击方式,XSS 攻击、SQL 注入攻击和 CSRF 攻击。这三种攻击方式占了 Web 攻击 90% 以上的攻击。解决方案有消毒、SQL 预编译参数绑定、验证码等常用手段,而所有这些攻击都可以通过使用统一的 Web 应用防火墙去解决。
加密的几种常用算法:单向散列加密,主要应用场景是用户密码加密、存储;还有对称加密,加密密钥和解密密钥相同,主要是对敏感信息进行加密,比如信用卡;非对称加密的主要应用场景就是 HTTPS,它的加密密钥和解密密钥是不同的。
此外在信息过滤和反垃圾中,我们学习了两个算法,一个是贝叶斯分类算法,一个是布隆过滤器算法,前者通过邮件内容去检查邮件是否为垃圾邮件,后者利用较小的内存空间记录垃圾邮件地址黑名单。
以上就是本节课的内容。在这个越来越重视信息安全的时代,做出更加安全的系统也就显得尤为重要。下一课时主要分享一些架构案例。
精选评论
**1460:
HTTPS我理解也只是传输密钥的时候用到非对称加密算法,传输数据时是对称加密算法
lyy1010:
之前只知道完成任务,从来不会去想这方面的东西然后现在越学就发现自己懂的越少,加油💪
编辑回复:
加油!
**龙:
安全这一块总感觉很重要,但是总是缺少资料来学习。
**辉:
学习了。
-
相关阅读:
光格科技递交科创板上会稿:拟募资6亿 预计年营收3亿
docker上安装的Jenkins但没有vi
网络协议入门 笔记一
区块链 | OpenSea 相关论文:Toward Achieving Anonymous NFT Trading(三)
2021年的一封情书:指针
Mysql的索引
猿如意开发工具|Sublime Text(4126)
搜索排序技术简介
《痞子衡嵌入式半月刊》 第 100 期
java基于SpringBoot的病房信息管理系统
- 原文地址:https://blog.csdn.net/fegus/article/details/126676496