-
mac下 如何简单粗暴 使用Python进行网络爬虫(2)
这次 我们来爬一个图片网站 然后保存到数据库
目标 我们选择 http://www.win4000.com/zt/fengjing.html
先打开网站看一下
我们的目的 就是抓风景桌面的壁纸 但这些都是缩略图 大图 在点击后的详情页里面
我们再次点击 一张素略图 看看
基本上 每一个缩略图都对应8-9张大图
那么 我们的目的很明确了 根据每个缩略图 找到对应的大图 并且下载下来回到 http://www.win4000.com/zt/fengjing.html 检查元素查看网页 源代码
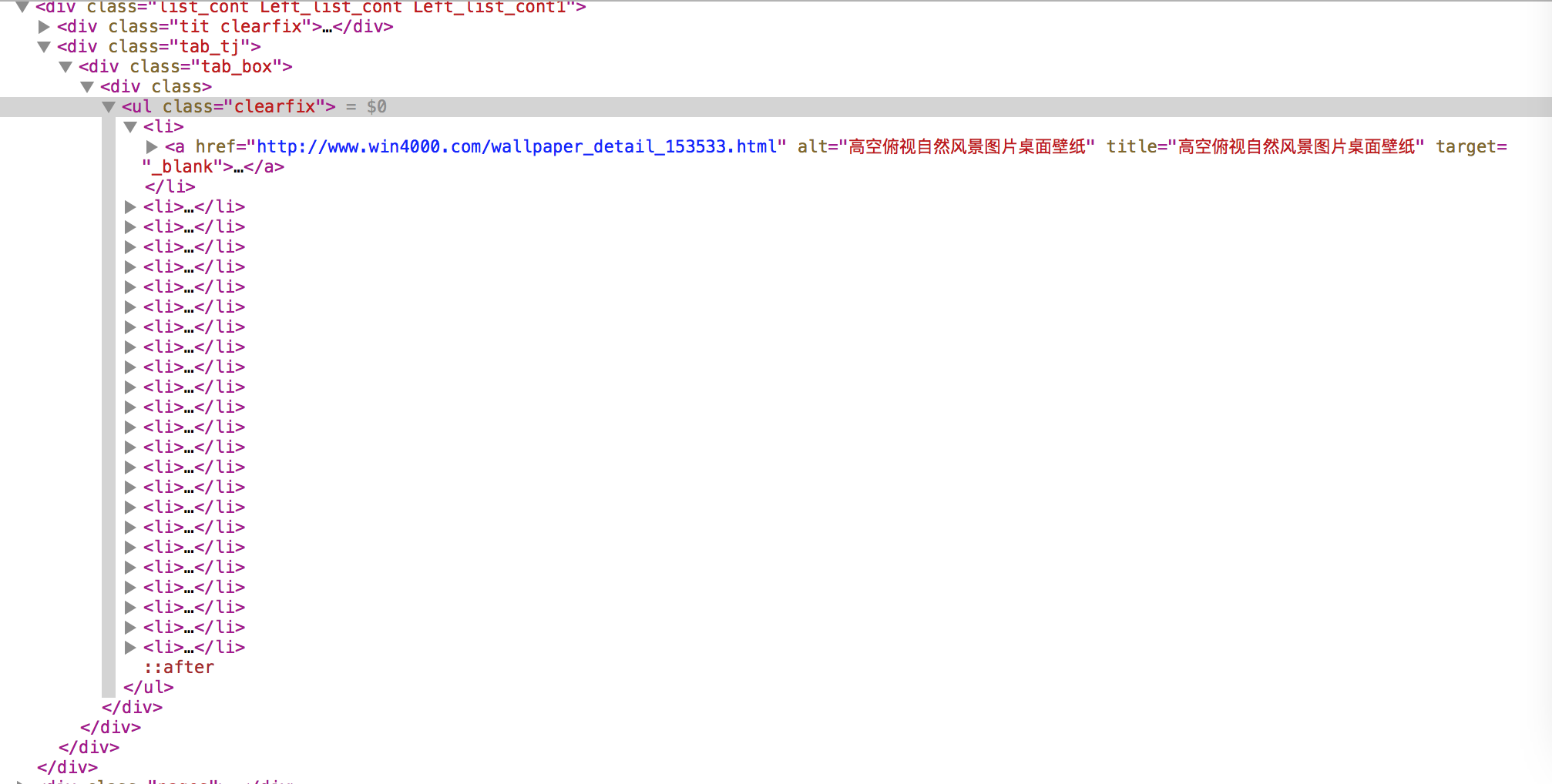
这个简直太简单了 直接用 BeautifulSoup获得每一个缩略图对应的详情
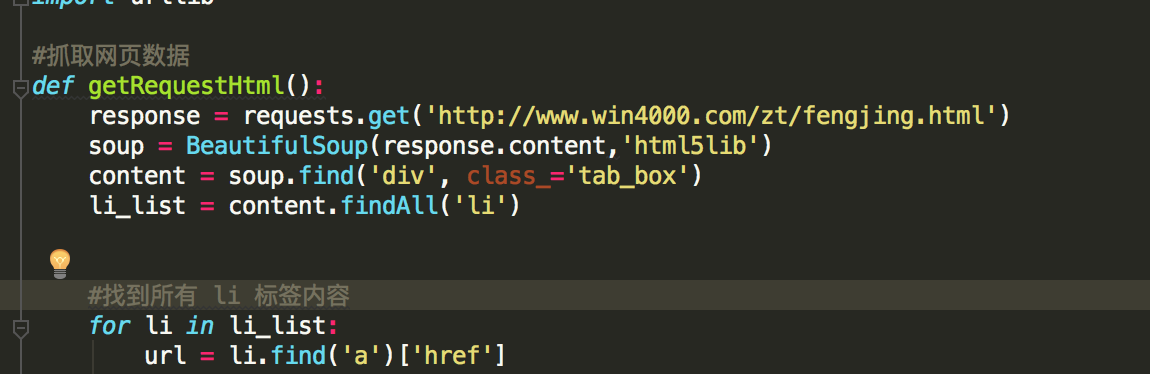
再来查看对应大图的

既然每张大图 大概有8-9张不等 那我们就搞一个循环直接便利
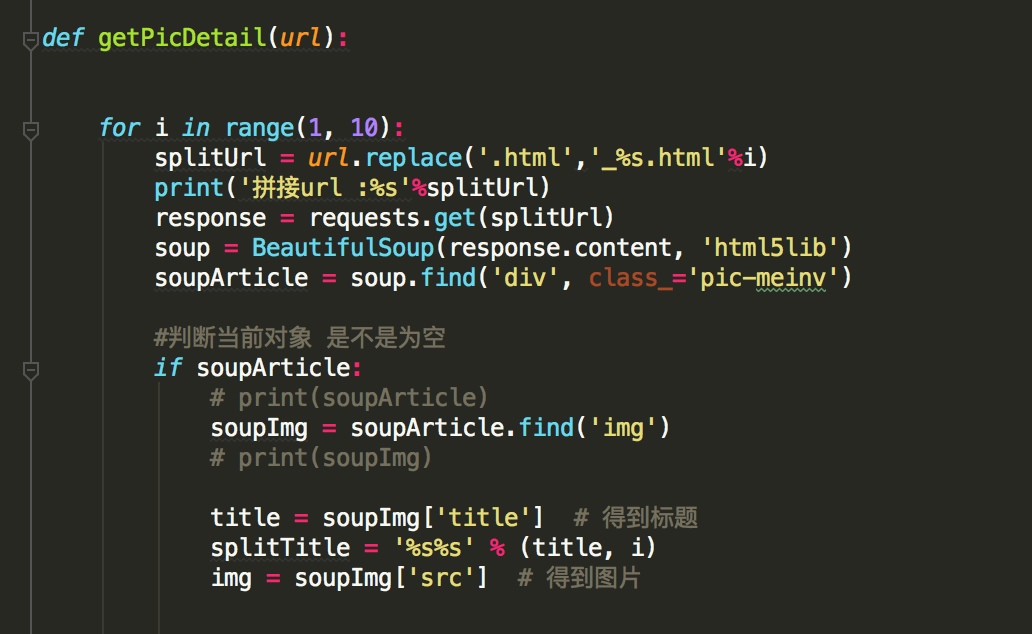
得到图片url后 开始下载
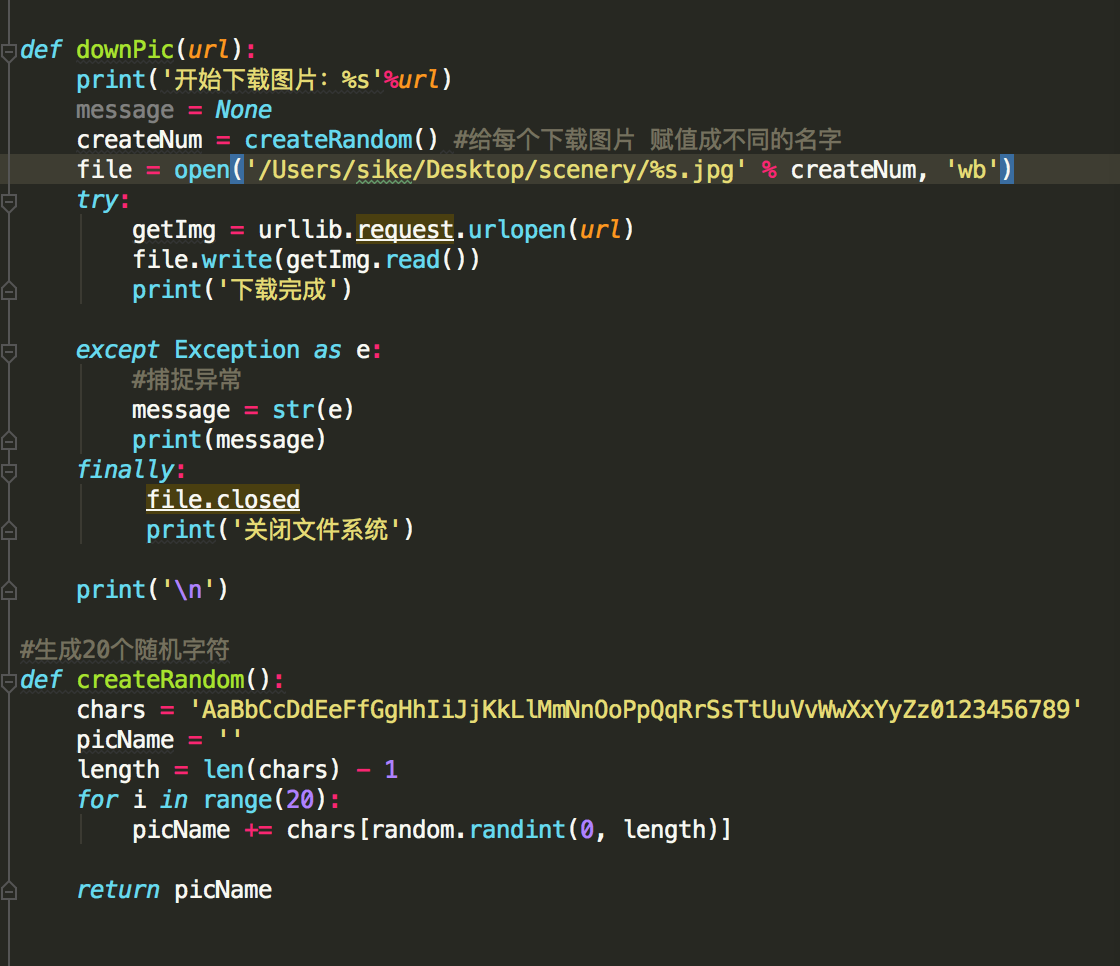
(注 我这里把下载扔到桌面 你也可以根据自己的需求更换地址)
到这一步 我们算是把图片抓取过来了。继续扩展一下 既然捕捉到了图片 那么我们能不能存到数据库里?
当然可以! 看如下操作首先 数据库软件 我使用

mac系统下 有破解版的 破解过程很简单 我就不重复了
打开软件
在127.0.0.1点击右键->新建数据库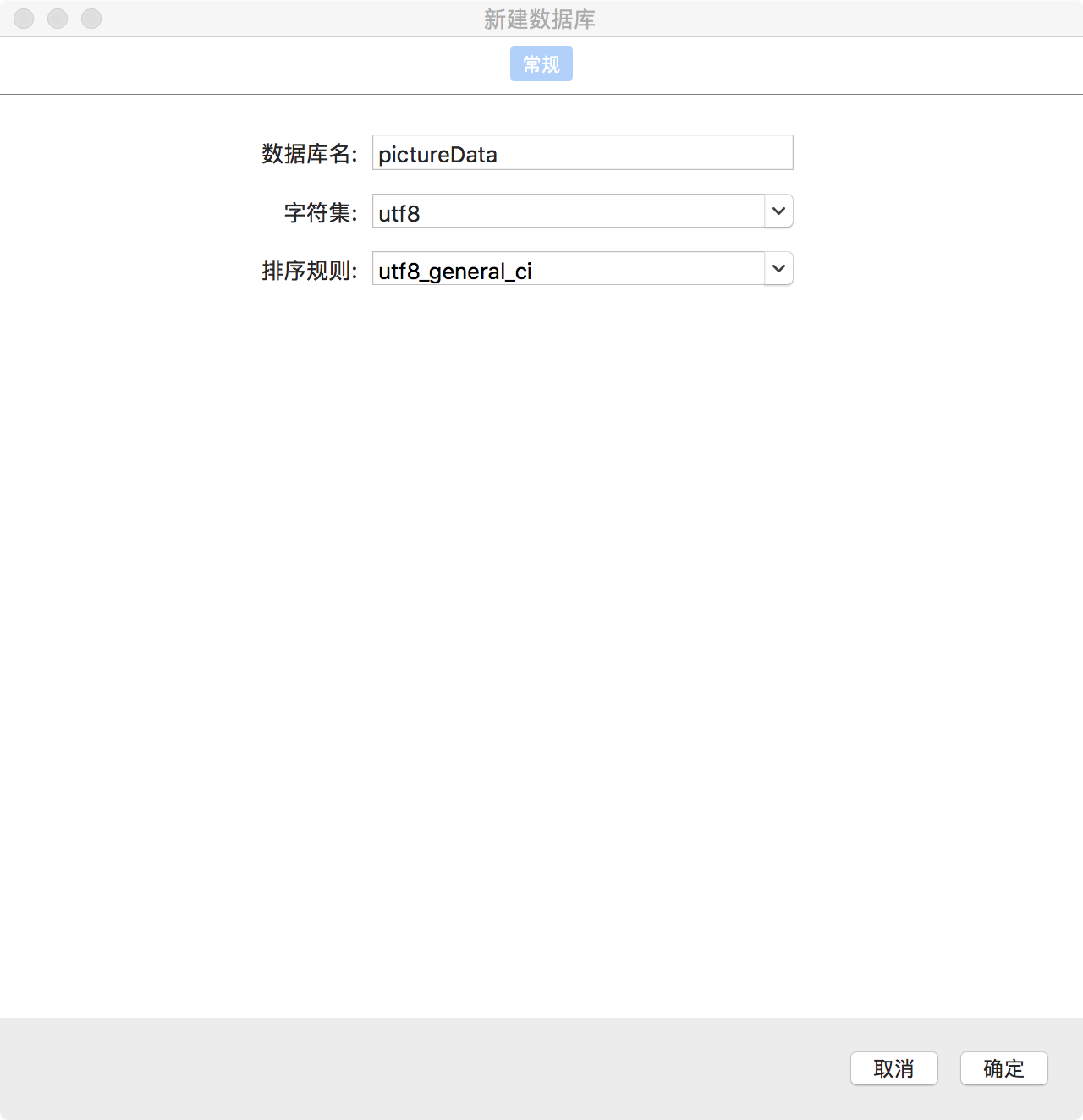
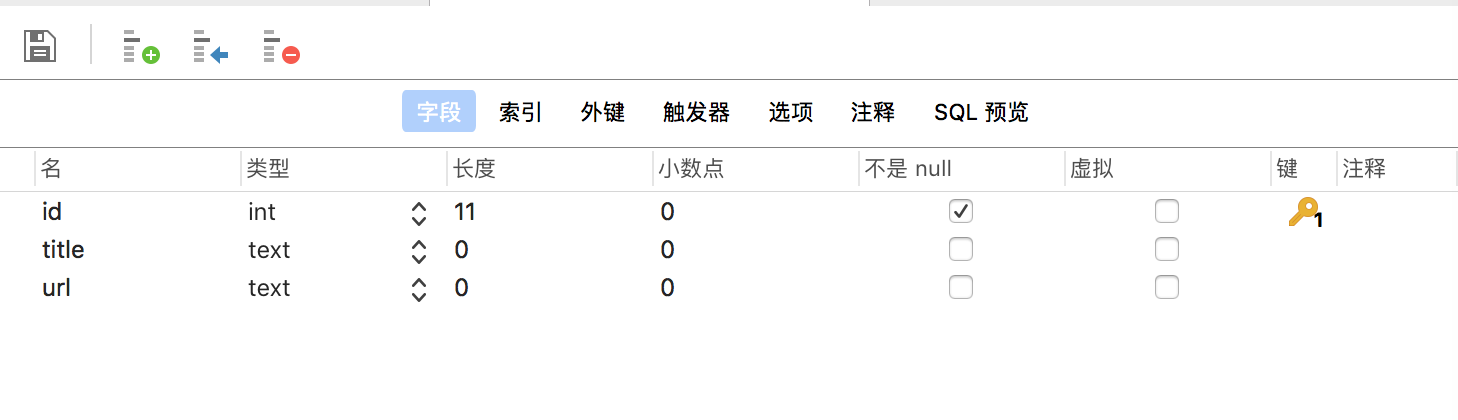
id自增 title url 一共三个字段
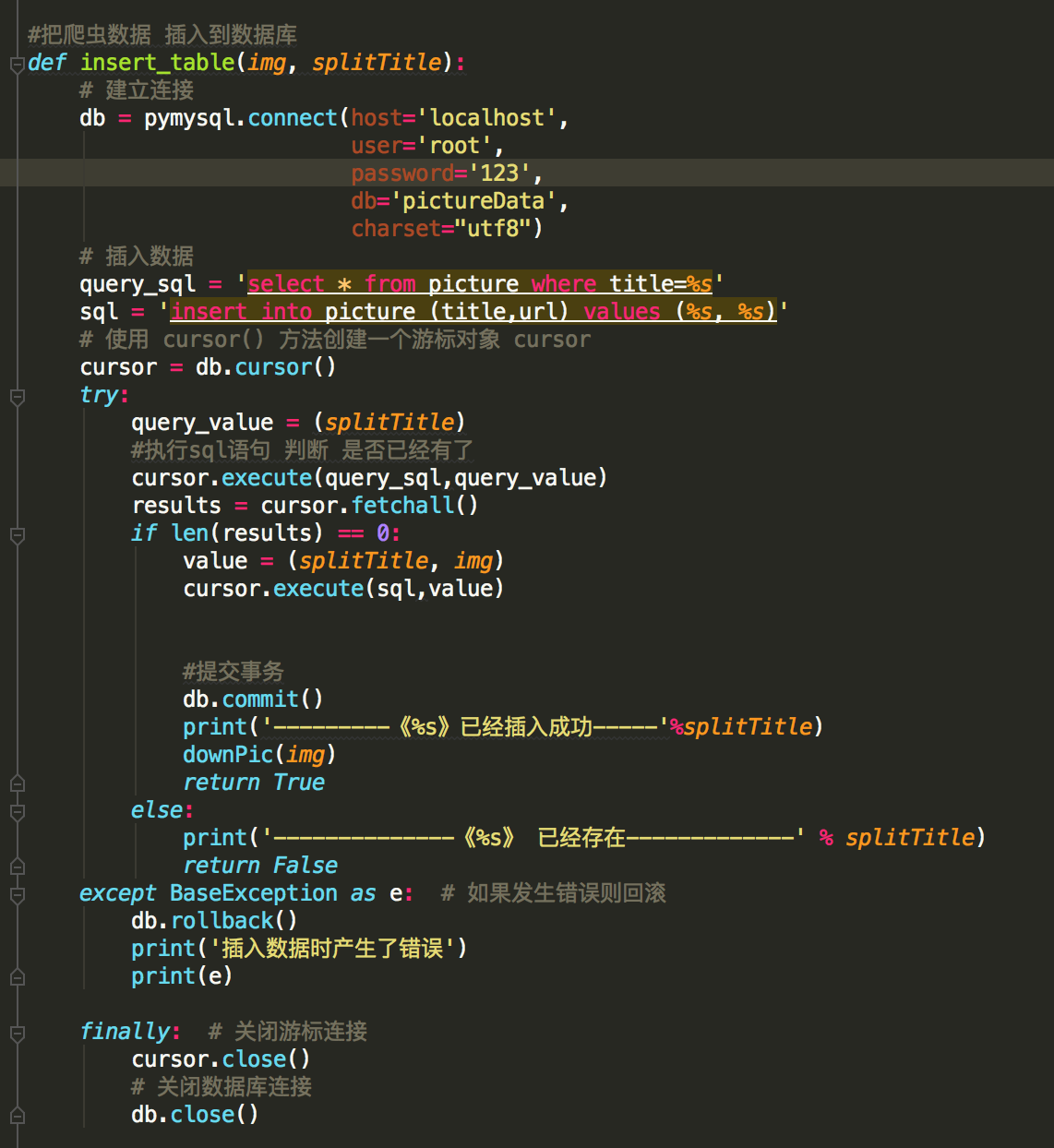
我是根据 标题 来判断 当前的图片 是否下载成功
如果数据库 没有 才可以从网络上下载
downPic(img)这个方法 就是上面下载的函数方法完整代码
- import requests
- from bs4 import BeautifulSoup
- import html5lib
- import time
- import pymysql
- import random
- import urllib
- #抓取网页数据
- def getRequestHtml():
- response = requests.get('http://www.win4000.com/zt/fengjing.html')
- soup = BeautifulSoup(response.content,'html5lib')
- content = soup.find('div', class_='tab_box')
- li_list = content.findAll('li')
- #找到所有 li 标签内容
- for li in li_list:
- url = li.find('a')['href']
- getPicDetail(url)
- def getPicDetail(url):
- for i in range(1, 10):
- splitUrl = url.replace('.html','_%s.html'%i)
- print('拼接url :%s'%splitUrl)
- response = requests.get(splitUrl)
- soup = BeautifulSoup(response.content, 'html5lib')
- soupArticle = soup.find('div', class_='pic-meinv')
- #判断当前对象 是不是为空
- if soupArticle:
- # print(soupArticle)
- soupImg = soupArticle.find('img')
- # print(soupImg)
- title = soupImg['title'] # 得到标题
- splitTitle = '%s%s' % (title, i)
- img = soupImg['src'] # 得到图片
- # 根据数据库里面数据来判断 该图片是否下载
- insert_table(img, splitTitle)
- time.sleep(2) # 休眠2秒
- else:
- print('当前链接为空')
- return
- #把爬虫数据 插入到数据库
- def insert_table(img, splitTitle):
- # 建立连接
- db = pymysql.connect(host='localhost',
- user='root',
- password='123',
- db='pictureData',
- charset="utf8")
- # 插入数据
- query_sql = 'select * from picture where title=%s'
- sql = 'insert into picture (title,url) values (%s, %s)'
- # 使用 cursor() 方法创建一个游标对象 cursor
- cursor = db.cursor()
- try:
- query_value = (splitTitle)
- #执行sql语句 判断 是否已经有了
- cursor.execute(query_sql,query_value)
- results = cursor.fetchall()
- if len(results) == 0:
- value = (splitTitle, img)
- cursor.execute(sql,value)
- #提交事务
- db.commit()
- print('---------《%s》已经插入成功-----'%splitTitle)
- downPic(img)
- return True
- else:
- print('--------------《%s》 已经存在-------------' % splitTitle)
- return False
- except BaseException as e: # 如果发生错误则回滚
- db.rollback()
- print('插入数据时产生了错误')
- print(e)
- finally: # 关闭游标连接
- cursor.close()
- # 关闭数据库连接
- db.close()
- def downPic(url):
- print('开始下载图片:%s'%url)
- message = None
- createNum = createRandom() #给每个下载图片 赋值成不同的名字
- file = open('/Users/sike/Desktop/scenery/%s.jpg' % createNum, 'wb')
- try:
- getImg = urllib.request.urlopen(url)
- file.write(getImg.read())
- print('下载完成')
- except Exception as e:
- #捕捉异常
- message = str(e)
- print(message)
- finally:
- file.closed
- print('关闭文件系统')
- print('\n')
- #生成20个随机字符
- def createRandom():
- chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789'
- picName = ''
- length = len(chars) - 1
- for i in range(20):
- picName += chars[random.randint(0, length)]
- return picName
- if __name__ == '__main__':
- getRequestHtml()
参考资料
Python 爬虫实战(一):使用 requests 和 BeautifulSoup - SegmentFault 思否
Python 爬虫实战(二):使用 requests-html - SegmentFault 思否 -
相关阅读:
js的slice()和splice()
OpenCV-Python学习(2)—— OpenCV 图像的读取和显示
如何在Python爬虫中使用IP代理以避免反爬虫机制
M1/M2 Parallels Desktop 19虚拟机安装Windows11教程(超详细)
使用css reset 还是使用Normalize.css
基于GAMS的电力系统优化分析
关于《web课程设计》网页设计 用html css做一个漂亮的网站 仿新浪微博个人主页
Ikigai: 享受生命的意义
Vue3.x使用vuex进行页面间通信
Spring Boot 文件上传与下载
- 原文地址:https://blog.csdn.net/sike2008/article/details/126675460
