-
Soft Actor-Critic Algorithms and Applications
无模型深度强化学习(RL)算法已成功地应用于一系列具有挑战性的顺序决策和控制任务。然而,这些方法通常面临两大挑战:高样本复杂性和超参数的脆弱性。这两个挑战都限制了这种方法在现实世界领域的适用性。在本文中,我们描述了最近引入的基于最大熵RL框架的非策略行为-批评(SAC)算法。在此框架下,行动者的目标是同时最大化期望收益和熵;也就是说,在完成任务的同时尽可能随机行事。我们对SAC进行了扩展,纳入了一些修改,以加速训练并提高与超参数相关的稳定性,包括一个自动调整温度超参数的约束公式。我们系统地评估SAC的一系列基准任务,以及具有挑战性的现实任务,如四足机器人的运动和机器人灵巧手操作。通过这些改进,SAC实现了最先进的性能,在样本效率和渐近性能方面优于之前的on-policy和off-policy方法。此外,我们证明,与其他非策略算法相比,我们的方法是非常稳定的,在不同的随机种子上实现了类似的性能。这些结果表明,SAC是一个有前途的候选人学习在现实世界的机器人任务。
背景:


原因:
1)on-policy learning: 深度强化学习方法的样本效率较差,因为要求(几乎)每次策略更新都要收集新样本。这很快就会变得非常昂贵,因为随着任务的复杂性,学习有效策略所需的梯度步骤和每个步骤的样本数量会增加
2) Off-policy algorithms :以重复使用过去的经验为目标。这对于传统的策略梯度公式来说是不可行的,但是对于基于q学习的方法来说是相对简单的
3)不幸的是,Off-policy algorithms和神经网络的高维非线性函数逼近的结合对稳定性和收敛性提出了重大挑战
4)引入了基于最大熵框架的软行为批评(SAC)算法
最大熵目标(参见例如(Ziebart, 2010)通过使用熵项对标准目标进行扩充,从而使最优策略额外旨在最大化其在每个访问状态的熵

4 From Soft Policy Iteration to Soft Actor-Critic
我们的off-policy软actor-critic算法可以从策略迭代方法的最大熵变体派生出来。我们将首先提出这一推导,验证相应的算法收敛于其密度类的最优策略,然后基于这一理论提出一个实用的深度强化学习算法。在本节中,我们将温度视为一个常数,稍后在第5节中提出对SAC的扩展,自动调整温度以匹配期望中的熵目标
4.1 Soft Policy Iteration
我们将从推导软策略迭代开始,这是一种用于学习最优最大熵策略的通用算法,在最大熵框架中在策略评估和策略改进之间交替进行。我们的推导是基于表格设置的,以实现理论分析和收敛性保证,在下一节中,我们将该方法扩展到一般的连续设置。我们将表明,软策略迭代收敛于一组策略中的最优策略,这些策略可能对应于一组参数化密度。
在软策略迭代的策略评估阶段,我们希望根据最大熵目标来计算策略π的值。对于固定策略,软Q值可以迭代计算,从任意函数Q: S ×A→R开始,反复应用由给出的修改Bellman备份算子Tπ
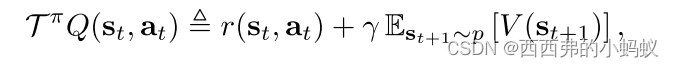

4.2 Soft Actor-Critic
如上所述,大型连续域要求我们推导出软策略迭代的实用近似。为此,我们将对软q函数和策略使用函数逼近器,而不是运行评估和改进来收敛,而是使用随机梯度下降来优化两个网络。我们将考虑一个参数化软q函数Qθ(st, at)和一个可处理策略πφ(at|st)。这些网络的参数分别为θ和φ。例如,软q函数可以建模为表达神经网络,策略可以建模为由神经网络给出的具有均值和协方差的高斯。接下来,我们将推导这些参数向量的更新规则。


其中值函数通过方程3中的软q函数参数隐式参数化,可以用随机梯度进行优化
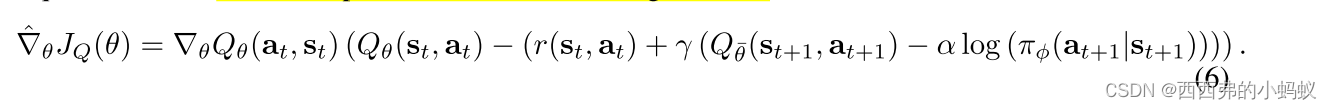



-
相关阅读:
在Bender对偶算法的时候出现bilinear项怎么办?
Spring笔记二:IOC简介及入门案例
ZYNQ使用AXI4-HP接口总线读取DDR中的数据
2023计算机毕业设计SSM最新选题之java中药城药材销售管理系统eah41
开发人员提高开发效率的10个推荐工具
重组模型系统
Kubernetes(K8s)Pod控制器详解-06
数字化转型指南发布,官方明确这样做!
读书笔记3|使用Python,networkx对卡勒德胡赛尼三部曲之——《群山回唱》人物关系图谱绘制
基于深度学习的问答系统
- 原文地址:https://blog.csdn.net/zj_18706809267/article/details/126659014