-
paddlepaddle 实现AlexNet模型,复现原创论文
,AlexNet是与LeNet不同的 一种新的深度学习模型。
论文原文百度云资源链接:链接:https://pan.baidu.com/s/1WdZnD6aVzUXvzs9XxshROQ 提取码:hans第一步:模型实现
- import os
- import cv2
- import numpy as np
- import paddle
- from paddle.io import Dataset
- import paddle.vision.transforms as T
- import matplotlib.pyplot as plt
- from paddle.io import Dataset
- from PIL import Image
- from PIL import ImageFile
- import paddle.nn as nn
- import paddle.nn.functional as F
- # 打印所使用的GPU编号
- print(paddle.device.get_device())
- ImageFile.LOAD_TRUNCATED_IMAGES = True
- # 搭建Alexnet网络
- class alexnet(paddle.nn.Layer):
- def __init__(self, ):
- super(alexnet, self).__init__()
- self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=96, kernel_size=7, stride=2, padding=2)
- self.conv2 = paddle.nn.Conv2D(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
- self.conv3 = paddle.nn.Conv2D(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
- self.conv4 = paddle.nn.Conv2D(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
- self.conv5 = paddle.nn.Conv2D(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
- self.mp1 = paddle.nn.MaxPool2D(kernel_size=3, stride=2)
- self.mp2 = paddle.nn.MaxPool2D(kernel_size=3, stride=2)
- self.L1 = paddle.nn.Linear(in_features=256*3*3, out_features=1024)
- self.L2 = paddle.nn.Linear(in_features=1024, out_features=512)
- self.L3 = paddle.nn.Linear(in_features=512, out_features=10)
- def forward(self, x):
- x = self.conv1(x)
- x = paddle.nn.functional.relu(x)
- x = self.mp1(x)
- x = self.conv2(x)
- x = paddle.nn.functional.relu(x)
- x = self.mp2(x)
- x = self.conv3(x)
- x = paddle.nn.functional.relu(x)
- x = self.conv4(x)
- x = paddle.nn.functional.relu(x)
- x = self.conv5(x)
- x = paddle.nn.functional.relu(x)
- x = paddle.flatten(x, start_axis=1, stop_axis=-1)
- x = self.L1(x)
- x = paddle.nn.functional.relu(x)
- x = self.L2(x)
- x = paddle.nn.functional.relu(x)
- x = self.L3(x)
- return x
第二步:查看一下网络结构;
- # 网络结构 应用paddle.summary检查网络结构是否正确。
- model = alexnet()
- paddle.summary(model, (100,3,32,32))
运行后的输出结果。
- ---------------------------------------------------------------------------
- Layer (type) Input Shape Output Shape Param #
- ===========================================================================
- Conv2D-1 [[100, 3, 32, 32]] [100, 96, 15, 15] 14,208
- MaxPool2D-1 [[100, 96, 15, 15]] [100, 96, 7, 7] 0
- Conv2D-2 [[100, 96, 7, 7]] [100, 256, 7, 7] 614,656
- MaxPool2D-2 [[100, 256, 7, 7]] [100, 256, 3, 3] 0
- Conv2D-3 [[100, 256, 3, 3]] [100, 384, 3, 3] 885,120
- Conv2D-4 [[100, 384, 3, 3]] [100, 384, 3, 3] 1,327,488
- Conv2D-5 [[100, 384, 3, 3]] [100, 256, 3, 3] 884,992
- Linear-1 [[100, 2304]] [100, 1024] 2,360,320
- Linear-2 [[100, 1024]] [100, 512] 524,800
- Linear-3 [[100, 512]] [100, 10] 5,130
- ===========================================================================
- Total params: 6,616,714
- Trainable params: 6,616,714
- Non-trainable params: 0
- ---------------------------------------------------------------------------
- Input size (MB): 1.17
- Forward/backward pass size (MB): 39.61
- Params size (MB): 25.24
- Estimated Total Size (MB): 66.02
- ---------------------------------------------------------------------------
在网络设计过程中,往往会出现结构性差错的地方就在卷积层与全连接层之间出现,在进行Flatten(扁平化)之后,出现数据维度对不上。可以在网络定义的过程中,首先将Flatten之后的全连接层去掉,通过paddle.summary输出结构确认卷积层数出为 256×3×3之后,再将全连接层接上。如果出现差错,可以进行每一层校验。
在上面模型的基础上,进行下面相关操作(加载数据,训练,预测)
第三步,加载Cifar10数据
原文根据AlexNet的结构,结合 The CIFAR-10 dataset 图片的特点(32×32×3),对AlexNet网络结构进行了微调:
- import sys,os,math,time
- import matplotlib.pyplot as plt
- from numpy import *
- import paddle
- from paddle.vision.transforms import Normalize
- normalize = Normalize(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5], data_format='HWC')
- from paddle.vision.datasets import Cifar10
- cifar10_train = Cifar10(mode='train', transform=normalize)
- cifar10_test = Cifar10(mode='test', transform=normalize)
- train_dataset = [cifar10_train.data[id][0].reshape(3,32,32) for id in range(len(cifar10_train.data))]
- train_labels = [cifar10_train.data[id][1] for id in range(len(cifar10_train.data))]
- class Dataset(paddle.io.Dataset):
- def __init__(self, num_samples):
- super(Dataset, self).__init__()
- self.num_samples = num_samples
- def __getitem__(self, index):
- data = train_dataset[index]
- label = train_labels[index]
- return paddle.to_tensor(data,dtype='float32'), paddle.to_tensor(label,dtype='int64')
- def __len__(self):
- return self.num_samples
- _dataset = Dataset(len(cifar10_train.data))
- train_loader = paddle.io.DataLoader(_dataset, batch_size=100, shuffle=True)
第四步 训练网络
- test_dataset = [cifar10_test.data[id][0].reshape(3,32,32) for id in range(len(cifar10_test.data))]
- test_label = [cifar10_test.data[id][1] for id in range(len(cifar10_test.data))]
- test_input = paddle.to_tensor(test_dataset, dtype='float32')
- test_l = paddle.to_tensor(array(test_label)[:,newaxis])
- optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
- def train(model):
- model.train()
- epochs = 2
- accdim = []
- lossdim = []
- testaccdim = []
- for epoch in range(epochs):
- for batch, data in enumerate(train_loader()):
- out = model(data[0])
- loss = paddle.nn.functional.cross_entropy(out, data[1])
- acc = paddle.metric.accuracy(out, data[1])
- loss.backward()
- optimizer.step()
- optimizer.clear_grad()
- accdim.append(acc.numpy())
- lossdim.append(loss.numpy())
- predict = model(test_input)
- testacc = paddle.metric.accuracy(predict, test_l)
- testaccdim.append(testacc.numpy())
- if batch%10 == 0 and batch>0:
- print('Epoch:{}, Batch: {}, Loss:{}, Accuracys:{}{}'.format(epoch, batch, loss.numpy(), acc.numpy(), testacc.numpy()))
- plt.figure(figsize=(10, 6))
- plt.plot(accdim, label='Accuracy')
- plt.plot(testaccdim, label='Test')
- plt.xlabel('Step')
- plt.ylabel('Acc')
- plt.grid(True)
- plt.legend(loc='upper left')
- plt.tight_layout()
- train(model)
训练参数:
BatchSize:100LearningRate:0.001如果BatchSize过小,训练速度变慢。
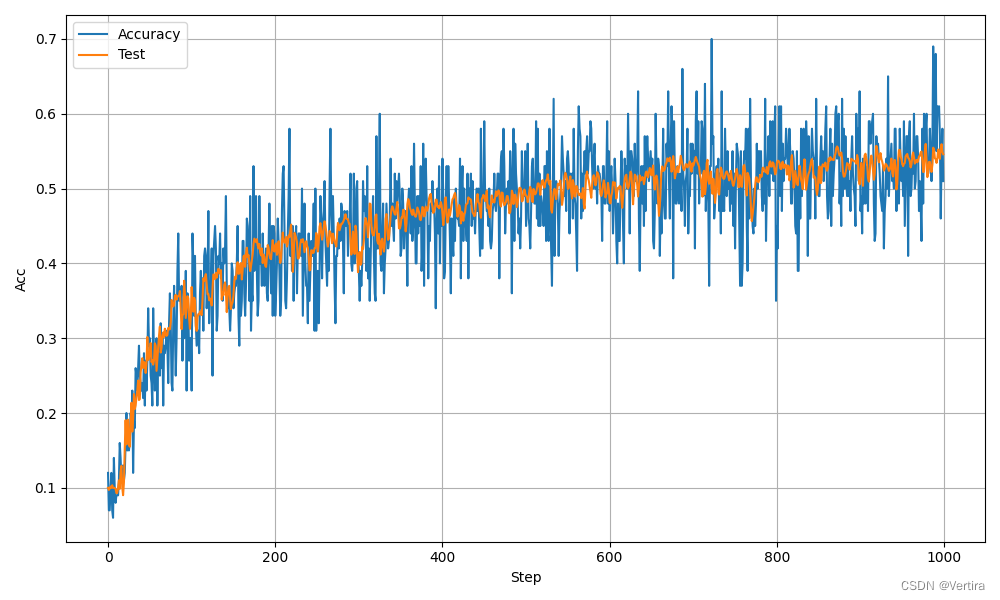
训练参数:
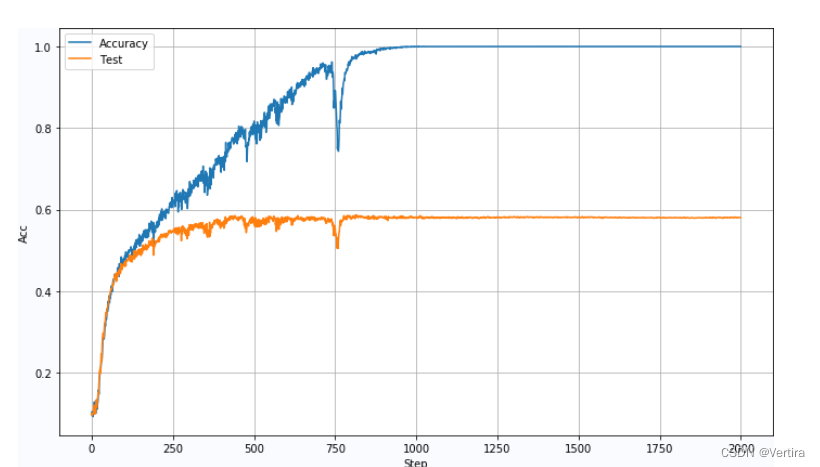
BatchSize:5000LearningRate:0.0005BatchSize:5000,Lr=0.001, DropOut:0.2:

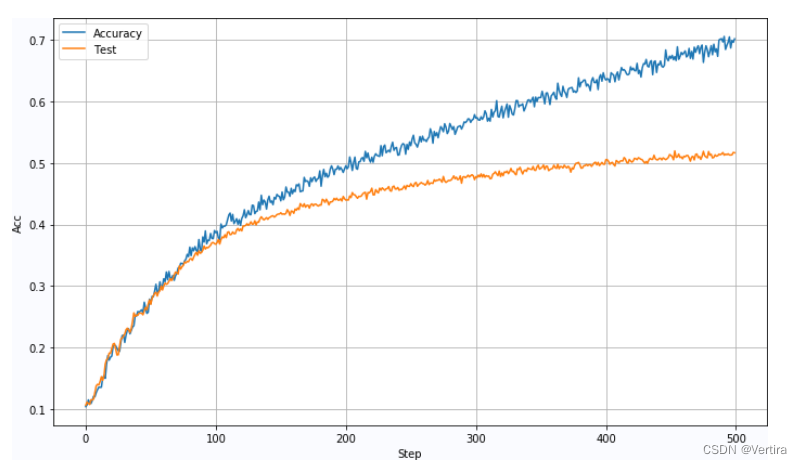
BatchSize:5000,Lr=0.0001, DropOut:0.2:
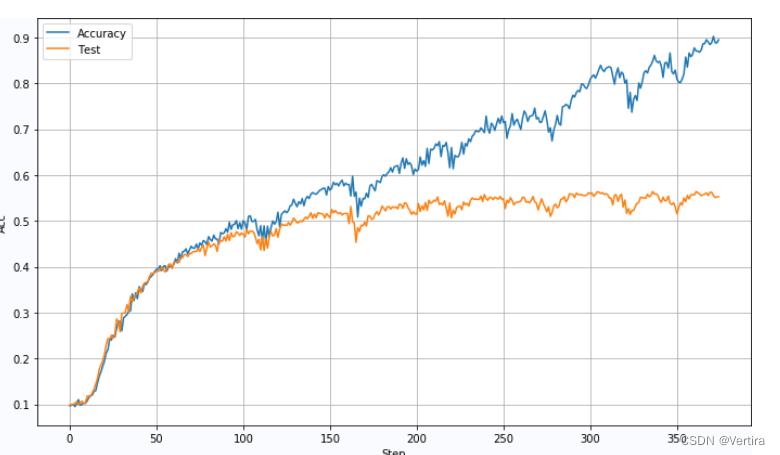
BatchSize:5000,Lr=0.0005, DropOut:0.5:
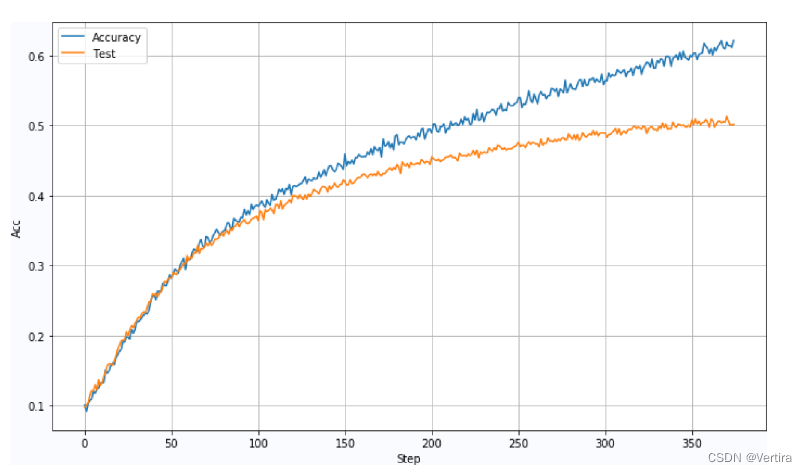
参考链接:
-
相关阅读:
SI,SIS,SIR,SEIRD模型
罗永浩直播首秀带货过亿,“IP+直播”会成为新的商业模式吗?
Docker轻量级可视化监控工具Portainer的使用
SQL语句查询关键字
matlab小车运动轨迹增量式PID控制
构造pop链
基本数据结构
基于javaweb的学生作业管理系统
leetcode1658. 将 x 减到 0 的最小操作数
png转jpg格式图片怎么弄?这几种格式转换方法要知道
- 原文地址:https://blog.csdn.net/Vertira/article/details/126671494