-
【目标检测】37、FreeAnchor: Learning to Match Anchors for Visual Object Detection

论文:FreeAnchor: Learning to Match Anchors for Visual Object Detection
代码:https://github.com/zhangxiaosong18/FreeAnchor
出处:NIPS2019
贡献点:
- 将检测器的训练过程建模成了一个最大似然估计(MLE)的过程,使用学习的方法来实现 anchor assignment,而非手动更新,打破了 IoU 的限制,让目标能够基于最大似然估计来自主的选择其 anchor
- 将检测器的优化定制成了似然形式,并且提出了 end-to-end 的形式来联合优化分类和回归,也就是一个端到端的完整的检测器,而非单独的 anchor 匹配的方法
一、背景
Anchor-based 方法的 label assignment,一般使用 IoU 来实现,大于某个阈值的 anchor 为正样本,小于某个阈值的 anchor 为负样本,每个 anchor 的 assignment 是独立的,但手工选取的参数肯定不是最优的。
原因有两点:
- 离心状的目标,如细长、偏靠的雨伞、香蕉等,最具有区分力的特征并未处于目标中心,空间上较为对其的 anchor 可能并没有包含这些区分特征,扰乱分类和回归的性能
- 当很多目标离得很近或重叠、聚集时,仅仅使用 IoU 难以获得最优的 anchor 分配
本文提出了一种基于学习策略的 label assignment 方法,从 3 个方面来分析:
- 为了实现高 recall,每个 gt 需要至少一个 anchor 和之匹配
- 为了实现高 precision,需要把定位效果差的 anchor 分配到背景类上去
- 需要和 NMS 兼容,即高分类得分的框同时定位也要好,才能保留下来优质的框
基于上述分析,作者将 object-anchor 的匹配问题,构造成了一个最大似然估计 maximum likelihood estimation(MLE)过程,即从一系列 anchor 中选择优质的 anchor 并分配给每个 gt。
MLE 的过程,就是最大化一个似然估计,保证每个 gt 至少有一个 anchor 是同时具有高分类得分和定位得分的。其他很多分类误差大或定位误差大的 anchor 被分为 background。在训练过程中,似然估计也就变成了 loss 函数。
二、方法

2.1 使用极大似然估计的方式来优化检测器
检测器的工作过程如下:
- 给定一个输入图像 I I I,其 g t gt gt 为 B B B
- 在训练的过程中,每个 anchor a i ∈ A a_i \in A ai∈A 都会在经过 sigmoid 函数后,输出一个类别得分,在经过回归后得到一个位置预测
- 在基于 IoU 的手工选取 anchor 的时候,都会使用 IoU 来判定某个 anchor 是否和某个 gt 匹配,匹配 matrix C i j ∈ 0 , 1 C_{ij} \in {0, 1} Cij∈0,1,如果 IoU > 阈值,则给定 C i j = 1 C_{ij}=1 Cij=1,也就是可能和该 gt 匹配,否则 C i j = 0 C_{ij}=0 Cij=0,经过一轮计算后,anchor 选择和它的 IoU 最大的 gt 组队,保证每个 anchor 只和一个 gt 组队,而一个 gt 可以有多个 anchor 围绕。
- loss function 如下,其中
θ
\theta
θ 是网络参数,分类损失为 BCE,回归损失为 smooth L1,背景的分类损失也为 BCE

- 根据极大似然估计,将 loss 函数写为极大似然形式如下,
p
c
l
s
p^{cls}
pcls 为分类得分,
p
l
o
c
p^{loc}
ploc 为定位得分。最小化
L
(
θ
)
L(\theta)
L(θ) 相当于最大化
P
(
θ
)
P(\theta)
P(θ)
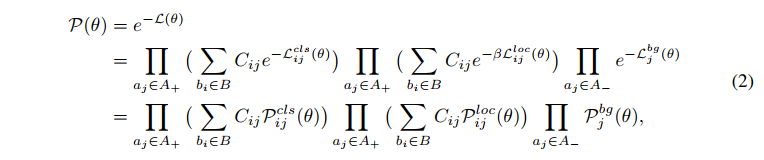
上面的 2 式,其实就从 MLE 的角度,同时考虑的分类和回归,但一般的方法也就缺乏了一点:如何优化 matching matrix C i j C_{ij} Cij,因为一般都是直接使用 IoU 来决定该 matrix 的值。
所以,本文中网络学习的是什么,就是这个 matrix C i j C_{ij} Cij
2.2 detection customized likelihood
为了实现最优的 object-anchor 的配对,作者通过引入 detection customized likelihood 扩展了 CNN-based 检测器的结构。该结构能够在同时保证 recall 和 precision 的同时,适配 NMS。
如何实现:
-
首先,使用 IoU,选出 anchor 集合中的 top-n anchors(也就是缩小了 anchor 的可选择范围,但还是可以选择的,而非直接指定确定的 anchor 来匹配某个 gt)
-
接着,通过最大化 detection customized likelihood 来让网络学习最优的 gt-anchor 匹配
-
其次,为了优化 recall 效果,对每个真值,都至少需要一个 anchor,且该 anchor 对应的分类和回归结果是和该 gt 的真值很相近的(也就是该 anchor 很优质),则该目标函数可以写为:

-
再次,为了优化 precision 效果,分类器要能够把定位差的 anchor 分配到 background 类上去,则该目标函数如下所示,其中, P { a j ∈ A _ } = 1 − max i P { a j → b i } P\{a_j \in A\_\}=1-\text{max}_iP\{a_j \to b_i\} P{aj∈A_}=1−maxiP{aj→bi} ,表示 a i a_i ai 没有和任何 gt 匹配上的概率, P { a j → b i } P\{a_j \to b_i\} P{aj→bi} 表示 anchor a j a_j aj 能够正确预测目标 b i b_i bi 的概率:
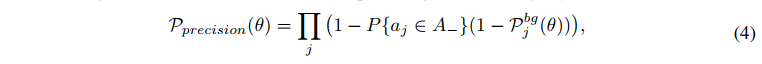
-
然后,为了更好的适配 NMS 过程, P { a j → b i } P\{a_j \to b_i\} P{aj→bi} 需要满足如下三个特性,分段函数如图 2 所示:
- P { a j → b i } P\{a_j \to b_i\} P{aj→bi} 是随着 a j a_j aj 和 b i b_i bi 的 IoU 的增大而单调递增的
- 当上述 IoU 小于某个阈值 t t t 时, P { a j → b i } P\{a_j \to b_i\} P{aj→bi} 趋于 0
- 对一个目标
b
i
b_i
bi 至少存在一个 anchor
a
i
a_i
ai, 满足
P
{
a
j
→
b
i
}
=
1
P\{a_j \to b_i\}=1
P{aj→bi}=1
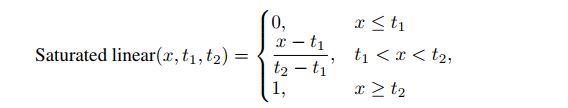
最后,detection customized likelihood 定义如下,通过优化这个似然函数,可以同时最小化 recall 和 precision 的概率,实现在训练过程中无需手动匹配 gt-anchor:
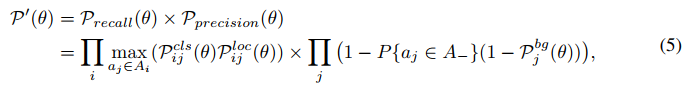

2.3 Anchor matching Mechanism
为了实现 learning-to-match 的方法,公式 5 可以被转换成 detection customized loss function ,公式如下:
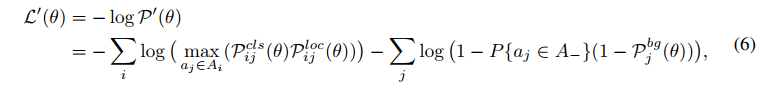
- 其中,max 函数是用来给每个 gt 选择最优 anchor 的
- 在训练的过程中,anchor 序列中的每个 anchor,都会被用来优化模型参数
训练早期,由于所有参数都是随机初始化而来,所以所有 anchor 的置信度都比较低,而得分较高的 anchor 越有利于模型的训练,所以,作者使用了 Mean-max 函数,来选择 anchor。如图 3 所示,Mean-max 函数是近似 mean 函数的,也就是说,几乎所有的 anchor 都会用于训练:

Mean-max 其实可以看做先 mean,最后 max 的情况。刚开始所有的 anchor 其实都不太准,所以取平均,随着训练的进行,一些 anchor 的置信度会逐步增加,最后肯定会有一个最大的 anchor 作为最终的选择。即随着训练,从 mean 过渡到 max,然后会给每个 gt 选择一个最优的 anchor。
使用 Mean-max 函数代替公式 6 中的 max 函数,并添加平衡因子和使用 Focal loss。
FreeAnchor 检测器最终的 detection customized loss 函数公式如下:
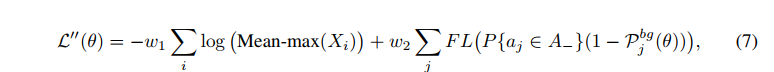

总体过程如下所述:

三、效果
FreeAnchor 是以 RetinaNet 为基础检测器来进行相关实验的,使用上面公式 7 中的 loss 函数来代替 RetinaNet 的 loss 函数。
1、Learning-to-match 效果可视化
如图 4 所示,手工选择的方法有两个问题:细长目标的中心问题和多个目标聚集问题。
FreeAnchor 能够较好的解决这两个问题:
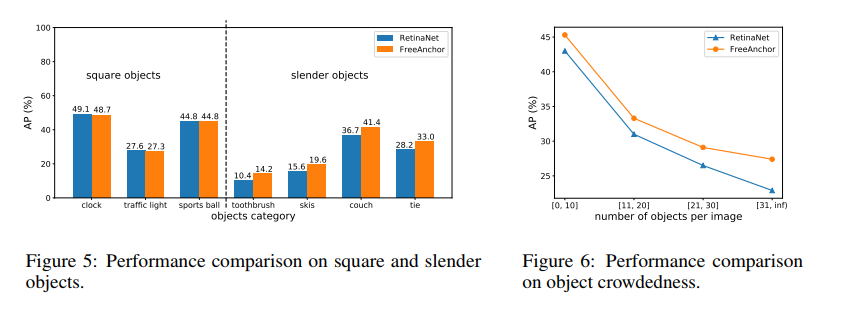
- 对于细长物体,如图 5 所示,超越了 RetinaNet 的效果,对于趋于正方形的物体,和 RetinaNet 效果差不多,这是因为 FreeAnchor 方法会驱动每个 gt 至少有一个和其匹配的 anchor,而和其匹配的 anchor 不需要很强的空间对齐,而是更注重包围那些具有区分能力的区域的 anchor
- 对于拥挤场景,如图 6 所示,随着每个图中目标数量的上升,FreeAnchor 比 RetinaNet 的效果好的程度也在增大,说明这种学习的匹配模式,能够很好的适应拥挤场景的问题。

2、和 NMS 的适配
本文使用 NMS Recall (KaTeX parse error: Undefined control sequence: \tao at position 5: NR_{\̲t̲a̲o̲}) 来作为衡量指标,衡量使用不同 IoU 阈值 KaTeX parse error: Undefined control sequence: \tao at position 1: \̲t̲a̲o̲ 的 NMS 前后的 recall 指标。
KaTeX parse error: Undefined control sequence: \tao at position 1: \̲t̲a̲o̲ 从 0.05 增大到 0.9,interval=0.05,FreeAnchor 一直比 RetinaNet 的效果好。

3、综合对比
- Anchor bag size n n n:设置了 {40, 50, 60, 100},表现最好的是 50
- Background IoU threshold t t t:设置了 {0.5, 0.6, 0.7},表现最好的是 0.6
- β \beta β:0.75
- Focal loss: α = 0.5 , γ = 2 \alpha=0.5, \gamma=2 α=0.5,γ=2
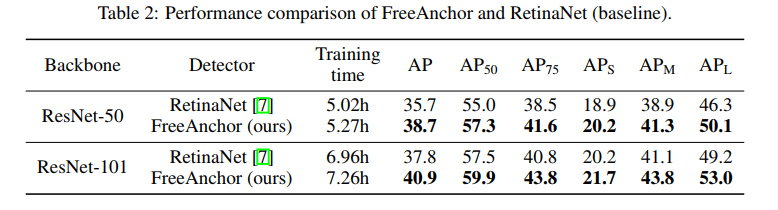
和 RetinaNet 对比,提升了约 3% AP

-
相关阅读:
通用代码生成器应用场景三,遗留项目反向工程
从GPT入门,到R语言基础与作图、回归模型分析、混合效应模型、多元统计分析及结构方程模型、Meta分析、随机森林模型及贝叶斯回归分析综合应用等专题及实战案例
Centos7 rpm 安装 Mysql 8.0.28
LeetCode第203题—移除链表元素
【数字图像处理笔记】Matlab实现离散傅立叶变换 (二)
Python Django 5 Web应用开发实战
24.flink windows 窗口,彻底站起来。
Vue首次使用Element
深度学习在图像识别中的革命性应用
C++支持默认函数参数,而C不支持默认函数参数
- 原文地址:https://blog.csdn.net/jiaoyangwm/article/details/126666550