-
MIPI CSI-2笔记(12) -- Low Level Protocol(数据加扰,扰码,Data Scrambling)
数据加扰(Data Scrambling)的目的是减轻EMI和RF自干扰做造成的影响,加扰是通过将链路的信息传输能量扩展到一个尽可能大的频带上,使用了一种数据随机化技术(data randomization technique)。本节介绍的扰码是可选项:如果CSI-2实现方案包含了对加扰的支持,那么加扰特性的实现上要按照本小节的描述来。使用数据加扰的好处是总所周知的,强烈推荐在系统中实现数据加扰能力来减少辐射干扰。

如上图所示,数据加扰应用在每Lane上。Lane Distribution Function的输出到每Lane的数据,通过一个专门为这个Lane设计的的加扰功能去加扰,这个过程发生在Lane的数据通过Tx PPI接口发送到PHY之前。
D-PHY物理层CSI-2扰码

使用D-PHY物理层的2-Lane数据Burst示例
上图展示了使用D-PHY物理层的2-Lane上的一次两个包burst传输例子。在SoT之后,HS-ZERO和HS-SYNC会被发送,包头和数据载荷被分发到了两条Lane上。
如果使用了D-PHY物理层,那么每条Lane里的加扰器的线性反馈移位寄存器LFSR(Linear Feedback Shift Register)都要进行初始化,使用Lane seed的值,这个值的产生要满足如下任意条件之一:
1. 在burst的起始点位置,紧跟HS-Sync的第一个要发送的字节之前,由D-PHY立即生成(可用于D-PHY EPD Option 1和D-PHY EPD Option 2)。
2. 紧跟HS-Sync的第一个要发送的字节之前,每当D-PHY EPD Option 1 HS-Idle被发送的时候生成。(这里纯属个人理解,各位有疑问请参考规范原文)
当使用D-PHY EPD Option 2时,CSI-2包之间扰码器不会重新初始化。
当加扰器被初始化,每条Lane的LFSR要用16-bit的seed值初始化。
C-PHY物理层CSI-2扰码
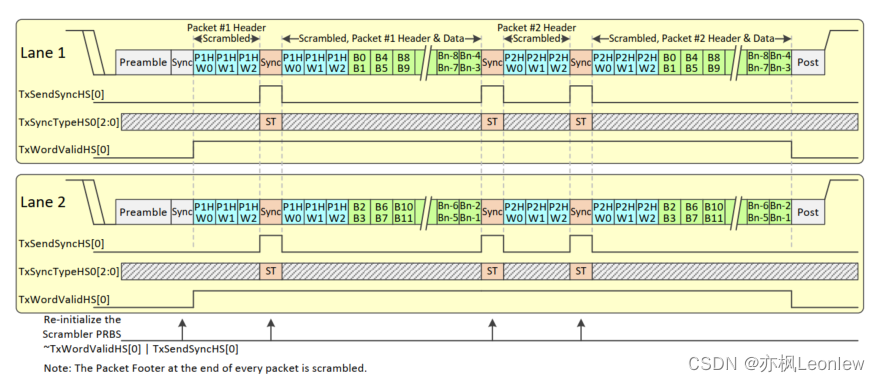
使用C-PHY物理层的2-Lane数据Burst示例
上图展示了使用C-PHY物理层的2-Lane上的一次两个包burst传输例子。在SoT之后,Preamble和Sync被发送,包头在每条Lane上复制了两份,每个包的数据载荷被分发到两条Lane上。如果使用C-PHY物理层,那么加每条Lane的扰器LFSR要在每个长包包头或短包开始的时间点进行初始化,每条Lane上分配的是多个16-bit seed值中的一个。初始化发生在每次Sync Word被发送的时候。
在某些场景中,图像可能会导致重复传输带有相同或高度相似的长包包头和相同的像素数据的长包(例如:全黑的像素或全白的像素)。如果加扰器在每个包的开始时,被初始化为相同seed值,和每行像素数据的起始值相同,那么加扰后的伪随机序列会按照相同的图像数据行传输的速率重复出现。这会导致信号随机性减少,并且出现和图像数据行传输的速率一样的峰值频率。
为了减轻这个问题,发送器每次发送包头时,会选择一个不同的seed值。Sync Word(规范原文中是说包头中的Sync Word,个人对这个in the Packet Header存疑,包头和Sync Word个人理解为两个概念,因此没有加“包头中”这几个字,可能我的理解有误,大家自行判断)编码了少量数据,因此发送器能够通知接收器使用了哪个starting seed作为包的加扰seed。这些Sync Word中的少量数据通过发送一个CSI-2发送器所选择的Sync Type来发出去。Sync Type的值也被用来选择加扰器(scrambler)和去扰器(descrambler)所使用的的starting seed。

每种Sync Type的符号序列值(Symbol Sequence Value)表
上表展示了五种C-PHY支持的五种可能的Sync Type。Sync Word值在C-PHY规范中被正式规定,并且为了方便,直接复制了这张表中的值。CSI-2协议只会使用这五种可能的Sync Type中的前四种,这样会简化实现方案。
按照Seed Index产生Tx Sync Type(单Lane视角)
上图展示了单Lane中的扰码器架构。由PRBS(Pseudo-Random Binary Sequence)所产生的伪随机数被用作seed index来从seed列表中选择初始seed值,这个过程发生在发送包之前。这个seed index也要通过PPI接口信号TxSyncTypeHS0[1:0]发送到C-PHY上。TxSyncTypeHS0[2]始终为0.TxSyncTypeHS1[2:0]被用做类似功能,使用在32-bit数据路径上。C-PHY会确保在一次burst传输开始的第一个包会使用Sync Type 3的Sync Word。
Seel列表可能包含1个或四个初始seed值。发送器和接收器要能够从seed列表中只选出一个seed值。当只使用一个单独的seed值时,这个seed要和Seed 3相同,发送器始终要发送Sync Type 3。发送器和接收器也要能够从四个seed值的列表中选出一个seed值,如上图所示。当使用了四个seed值的列表时,Sync Type 0到Sync Type 3被用来传输从发送器到接收器的seed index值。
当使用四个seed的列表时,2-bit seed index的值在发送器的伪随机生成器(例如PRBS)中生成。
PRBS生成器的实现方案上如果和标准的PRBS生成器存在细微差异,并不会影响发送器和接收器的互操作性,因为接收器还是会响应发送器中选择并发送到接收器的seed index,通过使用Sync Type来实现。

使用C-PHY物理层生成Tx Sync Type
对于接收器来说,C-PHY会解码Sync Word,并且传递2-bit Sync Type值到CSI-2协议逻辑中。CSI-2协议逻辑将这个2-bit值作为索引,从四个seed值中选出一个值去初始化去扰器。由于seed的选择字段是通过Sync Word来发送的,因此不需要任何其他的机制来协调接收器端来选择特定的去扰器初始seed值。
扰码细节
长包包头(Long Packet Header)、数据载荷(Data Playload)、长包包尾(Long Packe Footer,包尾可能包含Filler字节),以及短包都要加扰。由PHY产生的特殊数据字段超出了CSI-2协议的控制,不会被加扰。下面这张表列举了所有不会加扰的字段。

不被加扰的字段列表
数据加扰器和去扰器伪随机二进制序列PRBS,其生成过程所使用的伽罗瓦(Galois)LFSR生成多项式如下:
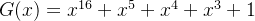 (我看的规范上这里缺少了G,自己补上的)
(我看的规范上这里缺少了G,自己补上的)
D-PHY Lane 1到Lane 8的加扰器PRBS初始种子值

C-PHY Lane 1到Lane 8的加扰器PRBS初始种子值
(每Lane有四种可能的Sync Type值,如果只使用一种Sync Type,默认是Sync Type 3)
对于超过8 Lane的D-PHY和C-PHY系统,Lane 9 到32的扰码器PRBS寄存器值初始种子值参考下面这张表:
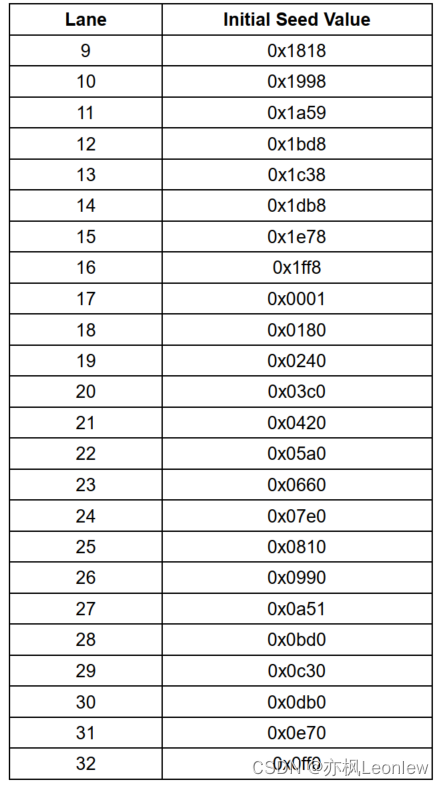
对于超过32 Lane的链路,Lane 33以及之后的Lane,加扰器PRBS寄存器使用的值是通过Lane的编号模去32得到的Lane编号对应的初始种子值。
例如:
- Lane 33 和Lane 1使用相同的初始种子值
- Lane 34 和Lane 2使用相同的初始种子值
- Lane 64 和Lane 32使用相同的初始种子值
- Lane 65 和Lane 1使用相同的初始种子值
仔细观察C-PHY所使用的两张表(Lane 1到Lane 8, Lane 9到Lane 32),基本上所有值从正向看和反向看都是对称的(比如0x0810,反向把每个bit输出组成的值也是0x0810),这句话也可以说成是对于每个种子值,加扰器PRBS寄存器的LSB bit Q0和其MSB的bit Q15是相同的。但Lane 11,17,27是例外。
LFSR要用G(x)对每个要加扰的载荷数据字节生成一个8-bit序列,从他的初始seed值开始。LFSR对每个载荷数据字节,会生成一个G(x)的新的bit序列,通过增加8 bit时钟周期实现。
加扰的过程,通过让一个8位G(x)值的每bit和CSI-2载荷数据进行模2加法(XOR)的方式来实现。
实现方案贴士: 每隔8个bit时钟,PRBS里的8-bit值是PRBS LFSR寄存器的Q15:Q8 bits的翻转值。设计者可以选择并行形式实现PRBS LFSR,在一个单独的字节时钟内移位8个位置的等价值;设计者甚至可以让PRBS LFSR可被配置为在一个单独的word时钟内移位8个位置的整数倍。

PRBS LFSR串行实现方案示例
上图的例子中,Q[15:8]被捕获到了一个临时寄存器中,随后在Q[15:8]被再次捕获前,PRBS LFSR被移位了8次。加扰通过以下方式执行:
• TxD[7] = PktD[7] ⊕ Q’[8];
• TxD[6] = PktD[6] ⊕ Q’[9];
• TxD[5] = PktD[5] ⊕ Q’[10];
• TxD[4] = PktD[4] ⊕ Q’[11];• TxD[3] = PktD[3] ⊕ Q’[12];
• TxD[2] = PktD[2] ⊕ Q’[13];
• TxD[1] = PktD[1] ⊕ Q’[14];
• TxD[0] = PktD[0] ⊕ Q’[15];
PRBS Bit-at-a-Time Shift Sequence
上表按照一次一个bit的方式展示了PRBS寄存器的序列,从Lane 2的初始seed值开始。数据加扰序列是输出G(x)。从加扰器输出的第一个bit是当寄存器包含初始seed值的时候,来自G(x)的输出值。

D-PHY物理层的PRBS LFSR Byte Sequence示例

C-PHY物理层的PRBS LFSR Byte Sequence示例
-
相关阅读:
酒水商城|基于Springboot实现酒水商城系统
5、Nacos服务注册与发现
Spring 中毒太深!离开 Spring 我居然连最基本的接口都不会写了。。。
【STM32】TIM2的PWM:脉冲宽度调制
【定向征文活动】2023年深圳1024开发者城市聚会活动参会感想征文
yolov5检测cs2中的目标
Python名片管理系统
基于Linux的智能家居(工厂模式)
第十七节 huggingface的trainner的断点续训的Demo(resume)
基于Springboot美食推荐小程序的设计与实现(源码+数据库+文档)
- 原文地址:https://blog.csdn.net/vivo01/article/details/126609451