-
java应用提速(速度与激情)

一、
速度与效率与激情什么是速度?速度就是快,快有很多种。
有小李飞刀的快,也有闪电侠的快,当然还有周星星的快:(船家)"我是出了名够快"。(周星星)“这船好像在下沉?” (船家)“是呀!沉得快嘛”。
并不是任何事情越快越好,而是那些有价值有意义的事才越快越好。对于这些越快越好的事来说,快的表现是速度,而实质上是提效。今天我们要讲的java应用的研发效率,即如何加快我们的java研发速度,提高我们的研发效率。
提效的方式也有很多种。但可以分成二大类。
我们使用一些工具与平台进行应用研发与交付。当一小部分低效应用的用户找工具与平台负责人时,负责人建议提效的方案是:你看看其他应用都这么快,说明我们平台没问题。可能是你们的应用架构的问题,也可能是你们的应用中祖传代码太多了,要自己好好重构下。这是大家最常见的第一类提效方式。
而今天我们要讲的是第二类,是从工具与平台方面进行升级。即通过基础研发设施与工具的微创新改进,实现研发提效,而用户要做的可能就是换个工具的版本号。
买了一辆再好的车,带来的只是速度。而自己不断研究与改造发动机,让车子越来越快,在带来不断突破的“速度”的同时还带来了“激情”。因为这是一个不断用自己双手创造奇迹的过程。
所以我们今天要讲的不是买一辆好车,而是讲如何改造“发动机”。
在阿里集团,有上万多个应用,大部分应用都是java应用,95%应用的构建编译时间是5分钟以上,镜像构建时间是2分钟以上,启动时间是8分钟以上,这样意味着研发同学的一次改动,大部分需要等待15分钟左右,才能进行业务验证。而且随着业务迭代和时间的推移,应用的整体编译构建、启动速度也越来越慢,发布、扩容、混部拉起等等一系列动作都被拖慢,极大的影响了研发和运维整体效能,应用提速刻不容缓。
我们将阐述通过基础设施与工具的改进,实现从构建到启动全方面大幅提速的实践和理论,相信能帮助大家。
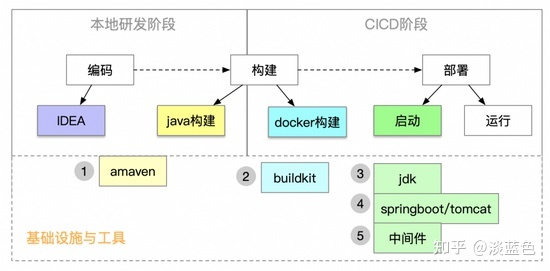
二、
maven构建提速2.1 现状
maven其实并不是拖拉机。
相对于ant时代来说,maven是一辆大奔。但随着业务越来越复杂,我们为业务提供服务的软件也越来越复杂。虽然我们在提倡要降低软件复杂度,但对于复杂的业务来说,降低了复杂度的软件还是复杂的。而maven却还是几年的版本。在2012年推出maven3.0.0以来,直到现在的2022年,正好十年,但maven最新版本还是3系列3.8.6。所以在十年后的今天,站在复杂软件面前,maven变成了一辆拖拉机。
2.2 解决方案
在这十年,虽然maven还是停留在主版本号是3,但当今业界也不断出现了优秀的构建工具,如gradle,bazel。但因各工具的生态不同,同时工具间迁移有成本与风险,所以目前在java服务端应用仍是以maven构建为主。所以我们在apache-maven的基础上,参照gradle,bazel等其它工具的思路,进行了优化,并以“amaven”命名。
因为amaven完全兼容apache-maven,所支持的命令与参数都兼容,所以对我们研发同学来说,只要修改一个maven的版本号。
2.3 效果
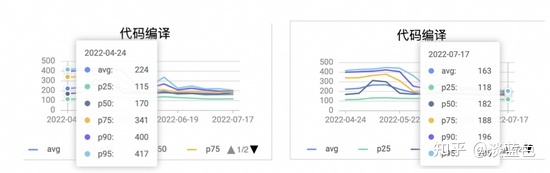
从目前试验来看,对于mvn build耗时在3分钟以上的应用有效果。对于典型应用从2325秒降到188秒,提升了10倍多。
我们再来看持续了一个时间段后的总体效果,典型应用使用amaven后,构建耗时p95的时间有较明显下降,对比使用前后二个月的构建耗时降了50%左右。
2.4 原理
如果说发动机是一辆车的灵魂,那依赖管理就是maven的灵魂。
因为maven就是为了系统化的管理依赖而产生的工具。使用过maven的同学都清楚,我们将依赖写在pom.xml中,而这依赖又定义了自己的依赖在自己的pom.xml。通过pom文件的层次化来管理依赖的确让我们方便很多。
一次典型的maven构建过程,会是这样:
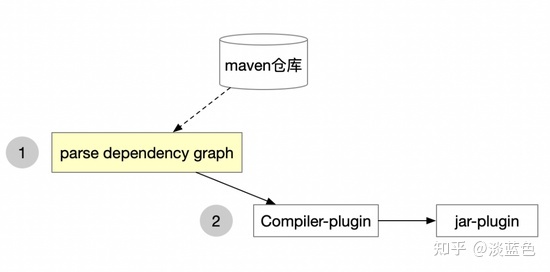
从上图可以看出,maven构建主要有二个阶段,而第一阶段是第二阶段的基础,基本上大部分的插件都会使用第一阶段产生的依赖树:
1.解析应用的pom及依赖的pom,生成依赖树;在解析过程中,一般还会从maven仓库下载新增的依赖或更新了的SNAPSHOT包。
2.执行各maven插件。
我们也通过分析实际的构建日志,发现大于3分钟的maven构建,瓶颈都在“生成依赖树”阶段。而“生成依赖树”阶段慢的根本原因是一个module配置的依赖太多太复杂,它表现为:依赖太多,则要从maven仓库下载的可能性越大。依赖太复杂,则依赖树解析过程中递归次数越多。
在amaven中通过优化依赖分析算法,与提升下载依赖速度来提升依赖分析的性能。除此之外,性能优化的经典思想是缓存增量,与分布式并发,我们也遵循这个思想作了优化。
在不断优化过程中,amaven也不断地C/S化了,即amaven不再是一个client,而有了server端,同时将部分复杂的计算从client端移到了server端。而当client越做越薄,server端的功能越来越强大时,server的计算所需要的资源也会越来越多,将这些资源用弹性伸缩来解决,慢慢地amaven云化了。
从单个client到C/S化再到云化,这也是一个工具不断进化的趋势所在。
2.4.1 依赖树
2.4.1.1 依赖树缓存
既然依赖树生成慢,那我们就将这依赖树缓存起来。缓存后,这依赖树可以不用重复生成,而且可以不同人,不同的机器的编译进行共享。使用依赖树缓存后,一次典型的mvn构建的过程如下:
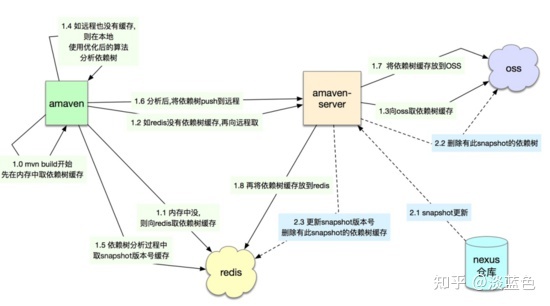
从上图中可以看到amaven-server,它主要负责依赖树缓存的读写性能,保障存储可靠性,及保证缓存的正确性等。
2.4.1.2 依赖树生成算法优化
虽在日常研发过程中,修改pom文件的概率较修改应用java低,但还是有一定概率;同时当pom中依赖了较多SNAPSHOT且SNAPSHOT有更新时,依赖树缓存会失效掉。所以还是会有不少的依赖树重新生成的场景。所以还是有必要来优化依赖树生成算法。
在maven2,及maven3版本中,包括最新的maven3.8.5中,maven是以深度优先遍历(DF)来生成依赖树的(在社区版本中,目前master上已经支持BF,但还未发release版本[1] 。在遍历过程中通过debug与打日志发现有很多相同的gav或相同的ga会被重复分析很多次,甚至数万次。
树的经典遍历算法主要有二种:深度优先算法(DF)及 广度优先算法(BF),BF与DF的效率其实差不多的,但当结合maven的版本仲裁机制考虑会发现有些差异。
我们来看看maven的仲裁机制,无论是maven2还是maven3,最主要的仲裁原则就是depth。相同ga或相同gav,谁更deeper,谁就skip,当然仲裁的因素还有scope,profile等。结合depth的仲裁机制,按层遍历(BF)会更优,也更好理解。如下图,如按层来遍历,则红色的二个D1,D2就会skip掉,不会重复解析。(注意,实际场景是C的D1还是会被解析,因为它更左)。
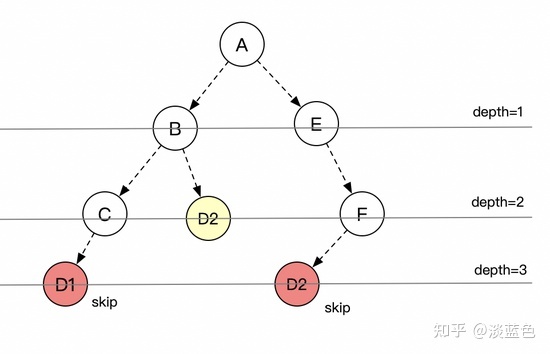
算法优化的思路是:“提前修枝”。之前maven3的逻辑是先生成依赖树再版本仲裁,而优化后是边生成依赖树边仲裁。就好比一个树苗,要边生长边修枝,而如果等它长成了参天大树后则修枝成本更大。
2.4.1.3 依赖下载优化
maven在编译过程中,会解析pom,然后不断下载直接依赖与间接依赖到本地。一般本地目录是.m2。对一线研发来说,本地的.m2不太会去删除,所以除非有大的重构,每次编译只有少量的依赖会下载。
但对于CICD平台来说,因为编译机一般不是独占的,而是多应用间共享的,所以为了应用间不相互影响,每次编译后可能会删除掉.m2目录。这样,在CICD平台要考虑.m2的隔离,及当.m2清理后要下载大量依赖包的场景。
而依赖包的下载,是需要经过网络,所以当一次编译,如要下载上千个依赖,那构建耗时大部分是在下载包,即瓶颈是下载。
1) 增大下载并发数
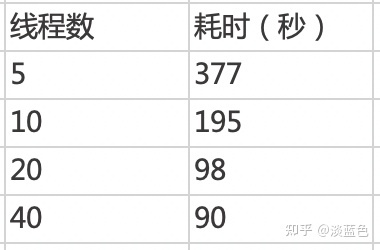
依赖包是从maven仓库下载。maven3.5.0在编译时默认是启了5个线程下载。我们可以通过aether.connector.basic.threads来设置更多的线程如20个来下载,但这要求maven仓库要能撑得住翻倍的并发流量。所以我们对maven仓库进行了架构升级,根据包不同的文件大小区间使用了本地硬盘缓存,redis缓存等包文件多级存储来加快包的下载。
下表是对热点应用A用不同的下载线程数来下载5000多个依赖得到的下载耗时结果比较:
在amaven中我们加了对下载耗时的统计报告,包括下载多少个依赖,下载线程是多少,下载耗时是多少,方便大家进行性能分析。如下图:

同时为了减少网络开销,我们还采用了在编译机本地建立了mirror机制。
2) 本地mirror
有些应用有些复杂,它会在maven构建的仓库配置文件settings.xml(或pom文件)中指定下载多个仓库。因为这应用的要下载的依赖的确来自多个仓库.当指定多个仓库时,下载一个依赖包,会依次从这多个仓库查找并下载。
虽然maven的settings.xml语法支持多个仓库,但localRepository却只能指定一个。所以要看下docker是否支持将多个目录volume到同一个容器中的目录,但初步看了docker官网文档,并不支持。
为解决按仓库隔离.m2,且应用依赖多个仓库时的问题,我们现在通过对amaven的优化来解决。
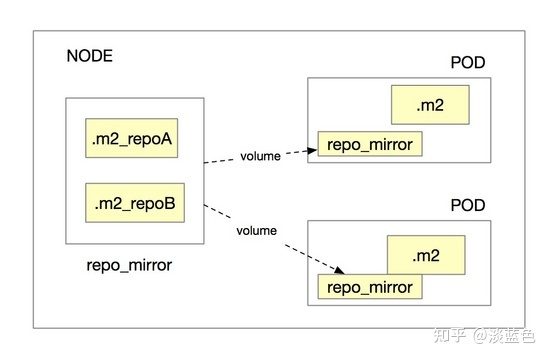
(架构5.0:repo_mirror)
当amaven执行mvn build时,当一个依赖包不在本地.m2目录,而要下载时,会先到repo_mirror中对应的仓库中找,如找到,则从repo_mirror中对应的仓库中将包直接复制到.m2,否则就只能到远程仓库下载,下载到.m2后,会同时将包复制到repo_mirror中对应的仓库中。
通过repo_mirror可以实现同一个构建
-
相关阅读:
WordPress 6.1 “Misha“
Maxwell 一款简单易上手的实时抓取Mysql数据的软件
window便捷使用技巧(LTS)
HTTP/2和HTTP/3特性介绍
2018年亚太杯APMCM数学建模大赛B题人才与城市发展求解全过程文档及程序
计算机毕业设计——网络游戏虚拟交易平台的设计与实现
Flask框架——项目可安装化
入门JavaWeb之 Response 下载文件
Python学习小组课程P4-Python办公(1)Excel保存
Android Studio导入,删除第三方库
- 原文地址:https://blog.csdn.net/AS011x/article/details/126656470