-
深度前馈网络(一)、神经网络学习XOR
参考 深度前馈网络(一)、神经网络学习XOR - 云+社区 - 腾讯云
XOR函数("异或"逻辑)是两个二进制值
x 1 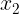 的运算。当这些二进制值中恰好有一个为1时,XOR函数提供了我们想要学习的目标函数
的运算。当这些二进制值中恰好有一个为1时,XOR函数提供了我们想要学习的目标函数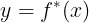 。我们的模型给出了一个函数
。我们的模型给出了一个函数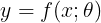 ,并且我们的学习算法会不断调整参数
,并且我们的学习算法会不断调整参数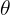 来使得f尽可能接近
来使得f尽可能接近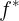 。
。在这个简单的例子中,我们不会关心统计泛化。我们希望网络在这4个点
上表现正确。我们会影全部这4个点来训练我们的网络,唯一的挑战时拟合训练集。我们可以把这个问题当作回归问题,并使用均方误差损失函数。选择这个损失函数是为了尽可能地简化本例中用到的数学知识。在应用领域,对于二进制数据建模时,MSE通常并不是一个合适的代价函数。评估整个训练集上表现的MSE代价函数为
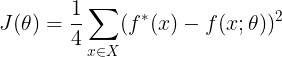 (1)
(1)我们现在必须要选择模型
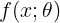 的形式。假设选择一个线性模型,包含w和b,那么模型被定义成
的形式。假设选择一个线性模型,包含w和b,那么模型被定义成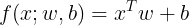 (2)
(2)我们可以使用正规方程关于w和b最小化
J ( θ ) 解正规方程以后,我们得到w=0以及b=1/2。线性模型仅仅是在任意一点都输出0.5。解决这个问题的其中一种方法是使用一个模型来学习一个不同的特征空间,在这个特征空间上线性模型能够表示这个解。
具体来说,我们这里引入了一个非常简单的前馈神经网络,它有一层隐藏层并且隐藏层包含两个单元,见下图中对该模型的解释。这个前馈神经网络有一个通过函数
f ( 1 ) ( x ; W , c ) h = f ( 1 ) ( x ; W , c ) 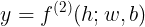 ,完整的模型是
,完整的模型是f ( x ; W , c , w , b ) = f ( 2 ) ( f ( 1 ) ( x ) ) 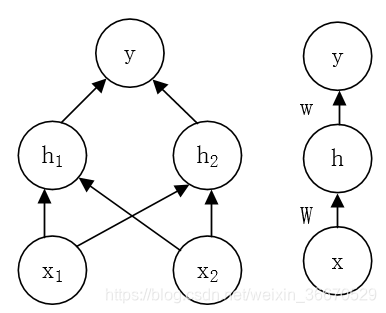
f ( 1 ) f ( 1 ) f ( 1 ) f ( 1 ) ( x ) = W T x f ( 2 ) ( x ) = h T w f ( x ) = w T W T x f ( x ) = x T w ′ w ′ = W w 显然,我们必须用非线性函数来描述这些特征。大多数神经网络通过放射变换之后紧跟着一个被称为激活函数的固定非线性函数来实现这个目标,其中放射变换由学得的参数控制。我们这里使用这种策略,定义
h = g ( W T x + c ) h i = g ( x T W : , i + c i ) g ( z ) = m a x { 0 , z } 现在可以指明我们的整个网络是
f ( x ; W , c , w , b ) = w T m a x { 0 , W T x + c } + b 我们现在可以给出XOR问题的一个解。令
W = [ 1 1 1 1 ] c = [ 0 − 1 ] w = [ 1 − 2 ] 以及b=0。
我们现在可以了解这个模型如何处理一批输入。令X表示设计矩阵,它包含二进制输入空间中全部的四个点,每个样本占一行,那么矩阵表示为
X = [ 0 0 0 1 1 0 1 1 ] 神经网络的第一步是将输入矩阵乘以第一层的权重矩阵:
X W = [ 0 0 1 1 1 1 2 2 ] 然后,我们加上偏置向量c,得到
[ 0 − 1 1 0 1 0 2 1 ] 在这个空间中,所有的样本都处在一条斜率为1的直线上。当我们沿着这条线移动时,输出需要从0升到1,然后再将回0。线性模型不能实现这样的一种函数。为了用h对每个样本求值,我们使用整流线性变换:
[ 0 0 1 0 1 0 2 1 ] 这个变换改变了样本间的关系,它们不再处于同一条直线上。
我们最后乘以一个权重向量w:
[ 0 1 1 0 ] 神经网络对这一批次中的每个样本都给出了正确的结果。
在这个例子中,我们简单地指定了解决方案,然后说明它得到的误差为零。在实际情况中,可能会有数十亿的模型参数以及数十亿的训练样本,所以不能像我们这里做的那样进行简单的猜解。与之相对的,基于梯度的优化算法可以找到一些参数使得产生的误差非常小。这里给出的XOR问题的解处在损失函数的全局最小点,所以梯度下降算法可以收敛到这一点。梯度下降算法还可以找到XOR问题一些其他的等价解。梯度下降算法的收敛点取决于参数的初始值。在实践中,梯度下降通常不会找到像我们这里给出的那种干净的、容易理解的、整数值的解。
-
相关阅读:
【linux 0.11 学习记录】一、环境配置,用Bochs输出hello world
极空间Docker安装Alist套件整合阿里云盘、百度云盘等网盘资源并挂载到本地供极影视刮削播放完整教程
Mac 上fiddler与charles 抓包https 小程序请求 内容
python 上下文管理器
给网站套上Cloudflare(以腾讯云为例)
C++八股记录
银河麒麟SP2服务器系统安装docker-engine-18.09版本
flex的用法 代码6
后台管理系统中,实现修改功能时,数据回显导致table-column数据消失。罪魁祸首竟是浅拷贝
CompletableFuture 异常与事务【无标题】
- 原文地址:https://blog.csdn.net/weixin_36670529/article/details/100689846