-
继续刷刷--《十大经典排序算法》
前言
如前所述,下面接着刷刷排序算法,自然就得看看目前经典的十大排序算法。打算都过一遍,理解一下思路,再用代码实现一下,加深印象,仅作为自己的学习积累,写在这里也做自己备份,偶尔也可以上来看看~~
网上关于这十大经典排序算法的资料、说明很多,我就不重复说明了,这里仅放一些自己的理解。有些资料也来源网络,毕竟没必要重复造轮子,如有侵权,请告知我删除~
十大经典排序算法说明
所谓排序,就是将一组序列,按照数的大小,递增地或递减地排列起来的操作。距今为止,出现了10种经典的排序算法,也就是接下来要逐一介绍的。如下图(图片来源网络):
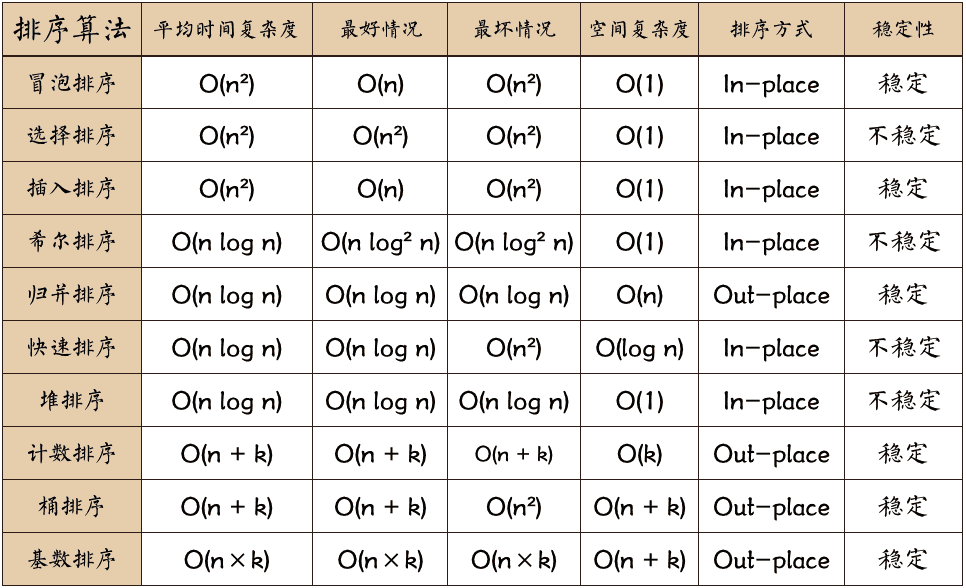
名词解释:- 时间复杂度:定性描述一个算法执行所耗费的时间;(重要性>空间复杂度,优先考虑)
- 空间复杂度:定性描述一个算法执行所需内存的大小;
- n:数据规模/个数;
- k:“桶”的个数;
- In-place:占用常数内存,不占用额外内存;
- Out-place:占用额外内存
- 稳定:排序后,不改变相同元素的先后位置;
- 不稳定:排序后,会改变相同元素的先后位置。
十大经典排序算法分类
目前看到的分类,主要有三种分类:
- 一是按是否占用额外内存分类,分为内部排序和外部排序;
- 二是按是否稳定分类,分为稳定排序和非稳定排序;
- 最后一种就是按是否进行数与数之间的比较分类,分为比较类排序和非比较类排序。
个人觉得最后一种是比较正确的分类方式,方便理解和记忆。
前两种分类,在上图已有介绍。下面放上最后一种分类方式(图片来源网络):

下面开始逐一过一下各个排序算法,学习一下前人的思想有多伟大,一个排序都能想到这么多种方法、思路。
说明:以下排序算法均以升序进行介绍。
——————————分割线:2022,0901——————————————————————
1. 冒泡排序
1.1 算法介绍
经典排序算法,循环比较两个数大小,如果前者大于后者,则进行交换,否则不变(升序)。算法名字的由来也是因为越小的元素会经由交换逐渐“冒泡”到序列前面。
冒泡排序还有一种优化算法,就是定一个flag记录在一次遍历比较中,是否发生元素交换,若未发生交换,则说明该序列已经有序,可提前终止遍历,提升性能。
个人最常用的一种排序,实现简单,很好记忆,几行代码就能搞定。
记忆的话,就记住核心是不停交换就行了,不停冒泡,交换次数:(leng - 1)^2。为什么是减一,因为比如2个数,只用交换1次就排序好了,这样来理解;为什么是平方,因为长序列,不可能通过一次遍历交换就可以排序好,所以是平方。
1.2 算法步骤
- 比较相邻两个元素,如果前者大于后者,则进行交换;
- 重复步骤1,至多n^2次,则可完全排序完。
1.3 算法性能指标
平均复杂度: O(n^2) 空间复杂度: O(1) 稳定性: 稳定 1.4 代码实现
main.cpp
#include#include "../include/bubble_sort.h" using namespace std; /* function description: printf a array before or after sort parameter: @is_before_sort : array type, true for array before sort, false for array after sort @array : data after bubble sort @size : size of data_before_sort return Value: void */ void printf_sort_array(bool is_array_before_sort, const int* array, ssize_t size) { if(NULL == array || size <= 0) return; if(true == is_array_before_sort) cout << "array_before_sort: "<< endl; else cout << "array_after_sort: "<< endl; ssize_t i; for( i = 0; i < size; i++ ) { cout << " " << array[i]; if(i == size - 1) cout << endl << endl; } } int main(void) { /* 排序前的序列 */ int array[] = { 3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48 }; ssize_t len_of_array = sizeof(array) / sizeof(int); /* printf array before sort */ printf_sort_array(true, array, len_of_array); /* sorting */ bubble_sort(array, len_of_array); /* printf array after sort */ printf_sort_array(false, array, len_of_array); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
bubble_sort.cpp
#include "../include/bubble_sort.h" using namespace std; /* function description: bubble sort parameter: @array : data need to be sorted @size : size of data_before_sort return Value: void */ void bubble_sort(int* array, ssize_t size) { if(NULL == array || size <= 0) return; ssize_t i,j; ssize_t cycle_num = 0; int temp; bool flag_to_terminate = true; //flag to optimize bubble sort cout<< "Bubble sorting(optimized)..." << endl << endl; //冒泡算法核心:逐个交换 for(i = 0; i < size - 1; i++) { flag_to_terminate = true; for(j = 0; j < size - 1; j++) { if(array[j] > array[j + 1]) { temp = array[j]; array[j] = array[j + 1]; array[j + 1] = temp; flag_to_terminate = false; } cycle_num++; } if(flag_to_terminate) break; } cout << "cycle_num: " << cycle_num << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
bubble_sort.h
#ifndef __BUBBLE_SORT_H #define __BUBBLE_SORT_H #includevoid bubble_sort(int* array, ssize_t size); #endif // __BUBBLE_SORT_H - 1
- 2
- 3
- 4
- 5
- 6
- 7
1.5 代码运行结果:

——————————分割线:2022,0904——————————————————————
2. 选择排序
2.1 算法介绍
经典排序算法,在未排序序列中找到最小数,放在序列的起始位置(升序),然后再从剩余未排序序列中继续找最小数放在已排序序列的下一位置,重复当前步骤,直至所有序列已排序完毕。
核心是每次在未排序序列中找到最小数,然后放到已排序序列,然后再从剩余未排序序列中找到最小数,注意是剩余的序列,不然会遍历重复元素,徒增算法消耗。
记忆的话,算法核心就是不停在未排序序列中选择一个最小数放在已排序序列中,组成已排序序列,所以叫做选择排序。
2.2 算法步骤
- 在未排序序列找到最小数,放在已排序序列起始位置;
- 在剩余未排序序列找到最小数,放在已排序序列的下一位置;
- 重复步骤2,直至元素排序完。
2.3 算法性能指标
平均复杂度: O(n^2) 空间复杂度: O(1) 稳定性: 不稳定 不稳定体现在取未排序序列的最小数时,并不知道哪个与其相等,所以有可能会改变相同元素的位置。
2.4 代码实现
select_sort.cpp
#include "../include/bubble_sort.h" using namespace std; /* function description: select sort parameter: @array : data need to be sorted @size : size of data_before_sort return Value: void */ void select_sort(int* array, ssize_t size) { if(NULL == array || size <= 0) return; int temp, min_index; ssize_t i,j; cout<< "Select sorting..." << endl << endl; for(i = 0; i < size - 1; i++) { min_index = i; //find min in the unsorted array for(j = i + 1; j < size;j++){ if(array[j] < array[min_index]) min_index = j; } //exchange the min in the unsorted array to the sorted array if(min_index > i) { temp = array[i]; array[i] = array[min_index]; array[min_index] = temp; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
main.cpp同前,只是换了调用的函数,改为select_sort(array, len_of_array)即可,此处不重复添加代码。
2.5 代码运行结果:

——————————分割线:2022,0906——————————————————————
3. 插入排序
3.1 算法介绍
经典排序算法,代码实现没有冒泡排序和选择排序那样简单粗暴,但原理是最好理解的。打过扑克牌的,都能理解,在整理牌的时候,会把牌按从小到大整理,再来下一张牌的时候,就插入在已整理的牌中。
把待排序序列的第一个元素看做一个有序序列,把第二个到最后一个元素作为一个未排序序列,从头到尾依次扫描未排序序列,把扫描到的每个元素插入到有序序列的适当位置。
记忆的话,算法核心就是不停在未排序序列中取出一个数插入到已排序序列中,组成已排序序列,所以叫做插入排序。
3.2 算法步骤
- 把待排序序列的第一个元素看做一个有序序列,把第二个到最后一个元素作为一个未排序序列;;
- 依次遍历未排序序列的每个元素,逐一插入到有序序列中;
- 重复步骤2,直至元素排序完。
3.3 算法性能指标
平均复杂度: O(n^2) 空间复杂度: O(1) 稳定性: 稳定 稳定性体现在在插入的时候,可以选择在遇到相同元素的时候,可以不动其位置,直接放在元素后面就可以了。
3.4 代码实现
insert_sort.cpp
#include "../include/insert_sort.h" using namespace std; /* function description: bubble sort parameter: @array : data need to be sorted @size : size of data_before_sort return Value: void */ void insert_sort(int* array, ssize_t size) { if(NULL == array || size <= 0) return; int temp; ssize_t i, j, k; ssize_t cycle_num = 0; cout<< "Insert sorting..." << endl << endl; //unsorted array for(j = 1; j < size; j++) { // sorted array for(i = 0; i < j; i++) { cycle_num++; // 1,5,7,8, ←3 //插入排序为 1,3,5,7,8 说明 5,7,8需要分别向右移一个位置 //然后再放入3在5前面 if(array[j] < array[i]) { temp = array[j]; //保存3的值 //右移i到j之间数字到下一个位置(包含i,不含j) for(k = j - 1; k >= i; k--) { array[k + 1] = array[k]; } array[i] = temp; //3的插入 break;//插入完成后,则停止继续查找插入位置 } //遍历到最后一个,说明是最大的,直接添加到序列最后的位置 //1,5,7,8, ←9 //1,5,7,8,9 if(i == j - 1){ array[i + 1] = array[j]; } } } cout << "cycle_num: " << cycle_num << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
3.5 代码运行结果:

——————————分割线:2022,0910——————————————————————
今天中秋,节日快乐!一个人在外面,也没啥过节氛围,只有刷刷题啦=。=4. 希尔排序
4.1 算法介绍
1959年由shell发明,就是下图中这个哥们,有点帅啊,第一个复杂度突破O(n^2)的排序算法,NB!也是插入排序的改进版,改进之处在于它可以优先比较距离较远的元素。
首先通过一个初始增量(我理解为间距),将数组分为多组,然后分别对每个组进行插入排序,然后不断缩小增量、排序,重复这个过程,最后当增量为1,再进行一次普通的插入排序,排序完成了。所以也称为缩小增量排序。

它比插入排序更高效,主要基于上图中的两点:- 插入排序对已经排序好的数据操作效率高,可以达到线性排序的效率;(所以先使用增量对每组进行排序)
- 插入排序低效在于每次只能对一个数据进行排序。(所以使用增量,对每组进行排序)
增量的取值,上图也有说明,一般可取值为待排序数的个数的一半,然后逐次减半,直至为1。
算法如下图(图片来源网络),就比较直观了:

记忆的话,算法核心就是缩小增量排序/改进版的插入排序,希尔发明,所以叫希尔排序。
4.2 算法步骤
- 选择一个增量序列,gap1,gap2,gap3,…,1。增量序列为降序,即gap1 > gap2等;
- 对每个gap下的序列,进行gap次插入排序(因为分为了gap个数组);
- 重复步骤2,即可排序完成。
4.3 算法性能指标
平均复杂度: O(nlogn) 空间复杂度: O(1) 稳定性: 不稳定 不稳定体现在多个增量排序下,不能保证相同元素的位置保持不变。
4.4 代码实现
shell_sort.cpp
/* function description: shell sort parameter: @array : data need to be sorted @size : size of data_before_sort return Value: void */ void shell_sort(int* array, ssize_t size) { if(NULL == array || size <= 0) return; int temp; ssize_t i, j, k, m, n; short gap; ssize_t cycle_num = 0; cout<< "Shell sorting..." << endl << endl; //gap值取的规则为size的一半向下取整 for(gap = size >> 1; gap > 0; gap >>= 1) { //每个gap下,每个array的排序 for(m = 0; m < gap; m++) { //插入排序,i为未排序序列,j为已排序序列 for(i = m + gap; i < size; i += gap) { for(j = m; j < i; j += gap) { if(array[i] < array[j]) { temp = array[i]; for(k = i - gap; k >= j; k -= gap) { array[k + gap] = array[k]; } array[j] = temp; break;//插入完成后,则停止继续查找插入位置 } cycle_num++; } } } } cout << "cycle_num: " << cycle_num << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
4.5 代码运行结果:

——————————分割线:2022,0913——————————————————————5. 归并排序
5.1 算法介绍
从算法名字就可以看出,该排序算法的核心在于归并。
既然要归并的话,则开始肯定是需要先分离的,怎么分离呢,就是很直接地不停二二分组,不停分成两组,直到最后两组各只有一个元素,然后比较两组的元素大小,再将该两组归并到一组,再逐一不停归并,一直归并到一个组,此时就完成了归并排序。
两个数组的归并的详细过程是这样的,申请一块内存,内存大小为待归并的两个已排序的数组,两个指针分别指向两个已排序的数组的起始位置,先比较大小,小的放进那块内存,并把指向小的指针移向下一个位置,再进行比较,重复前面的过程,直至两个指针的其中一个已经移到了数组末尾,此时再把那个未到达数组末尾的指针所在的数组剩余的数拷贝至内存末尾。
这样就完成了两个有序数组的归并,注意前提是两个数组必须有序。因为从前面“最后的拷贝至末尾”的操作可以看出,如果不是有序,则会出问题。
5.2 算法步骤
- 数组的不停二二拆分;
- 拆至分别只剩1个元素后,然后比较大小,再进行2个数组归并;
- 重复步骤2,即可排序完成。
5.3 算法性能指标
平均复杂度: O(nlogn) 空间复杂度: O(n) 稳定性: 稳定 从算法可以看出,归并排序需要先申请一块内存,所以空间复杂度为O(n)。
5.4 代码实现
merge_sort.cpp
#include "../include/merge_sort.h" using namespace std; /* function description: sorted merge two sorted arrays parameter: @array1 : sorted array1 need to be merge @size1 : size1 of array1 @array2 : sorted array2 need to be merge @size2 : size of array2 return Value: @int* : sorted merge array, size = size1 + size2 */ int* merge_two_arrays(int* array1, ssize_t size1, int* array2, ssize_t size2) { /* parameters check */ if(NULL == array1 && NULL != array2) return array2; if(NULL == array2 && NULL != array1) return array1; if(NULL == array1 && NULL == array2) return NULL; // index_1 → array1,index_2 → array2, ssize_t index_1 = 0, index_2 = 0, index_t = 0; int* temp_array = (int *)malloc((size1 + size2)*sizeof(int)); //归并两个已排序序列 while(index_1 < size1 && index_2 < size2){ temp_array[index_t++] = array1[index_1] < array2[index_2] ? array1[index_1++] : array2[index_2++]; } //复制剩余元素至已排序序列 while (index_1 < size1){ temp_array[index_t++] = array1[index_1++]; } while (index_2 < size2){ temp_array[index_t++] = array2[index_2++]; } return temp_array; } /* function description: merge sort parameter: @array : data need to be sorted @size : size of data_before_sort return Value: @int* : sorted merge array, size = input array size */ int* merge_sort(int* array, ssize_t size) { if(NULL == array || size <= 1) return array; ssize_t middle_index = size >> 1; ssize_t f = 0 , l = 0, temp = 0; int temp_first[middle_index]; int temp_last[size - middle_index]; while (f < middle_index){ temp_first[f++] = array[temp++]; } while (l < size - middle_index){ temp_last[l++] = array[temp++]; } // First, merge sort the first half and the last half. // Then, merge the two halves. return merge_two_arrays(merge_sort(temp_first, middle_index), middle_index, merge_sort(temp_last, size - middle_index), size - middle_index); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
代码使用的是递归方式进行实现,部分代码参考【https://www.cnblogs.com/guyouyin123/p/14622770.html】,只有TA的代码逻辑我看得很清晰。
5.5 代码运行结果:

6. 快速排序
6.1 算法介绍
快速排序突出一个“快”,“沉也沉的快嘛”,= =。
快速排序是由东尼·霍尔所提出的一种排序算法,名字很直接,排序就是快,而且效率高!据说它是处理大数据最快的排序算法之一了,虽然最坏情况的时间复杂度为O(n^2),平均时间复杂度为O(nlogn),但在大多数情况下,都比平均时间复杂度的排序算法表现要好。
快速排序通过多次比较和交换来完成排序,和冒泡很像,所以经常会拿过来一起比较,但快速排序多了一个和基准值的比较,然后再“分而治之”,比基准值小的放前面,比基准值大的放后面,然后再迭代比较两个区间,最后,就排序好了。
6.2 算法步骤
- 从数列中挑出一个基准数据(一般是第一个元素);
- 排序数列,挑出比基准数小的放基准前面,比基准数大的放后面;
- 递归地对基准前的数据和基准后的数据进行重复步骤2,即可排序完成。
6.3 算法性能指标
平均复杂度: O(nlogn) 空间复杂度: O(logn) 稳定性: 不稳定 6.4 代码实现
//快速排序 //递归地调用单趟排序 void quick_sort(int* a, int left, int right) { //如果区间只剩一个数或没有数,就不进行操作 if(NULL == a || left >= right) return; int key = single_sort(a, left, right); quick_sort(a, left, key-1); quick_sort(a, key+1, right); } //单趟排序,hoare方法 //1.任意取左边第一个数作为基准数,然后分别从最左边向右边遍历和从最右边向左边遍历(注意需要先要最右边向左边遍历) //2.最右边向左边遍历寻找比基准数小的数,最左边向右边遍历寻找比基准数大的数 //3.各找到一个后,交换,继续遍历,直至两个位置重合 //4.最后,交换重合位置的数和基准数 static int single_sort(int* a, int left, int right) { int key = left; while (left < right) { while(right > left && a[right] >= a[key]) right--; while(left < right && a[left] <= a[key]) left++; //交换基准数两边的数 swap(&a[left], &a[right]); } //交换基准数,使其前面为小于它的数,后面为大于它的数 swap(&a[key], &a[left]); key = left; return key; } static void swap(int* a, int* b) { int temp; temp = *a; *a = *b; *b = temp; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
参考:
https://blog.csdn.net/LiangXiay/article/details/121421920(代码实现)
https://blog.csdn.net/weixin_43586713/article/details/119820797(快速排序的排序过程理解)6.5 代码运行结果:

-
相关阅读:
Android核心组件:Activity
ssm基于微信小程序的医学健康管理系统--(ssm+uinapp+Mysql)
Complete the MST 题解
第二部分:DDD 设计中的基本元素
vue3 快速入门系列 —— vue3 路由
【Android进阶】7、Android各SDK版本的区别与兼容
数字图像处理——引言
树上启发式合并小结
06 tp6 的数据更新(改)及删除 《ThinkPHP6 入门到电商实战》
MySQL数据库干货_20——MySQL中的索引【附有详细代码】
- 原文地址:https://blog.csdn.net/To_be_a_fisher/article/details/126652629
