-
深度学习(PyTorch)——DataLoader的使用方法
B站UP主“我是土堆”视频内容
batch_size是每次给网络的数据多少,比如我们去抓牌,当batch_size=2时,每次抓牌就抓2张。
shuffle是否要打乱数据,当设置为True时,前一次epoch的数据与当前次epoch的数据顺序是不一样的。
num_workers是表示进程数量,在window下可能出现bug
drop_last是每次从数据集取数据,可能最后存在余数,是否要把余数舍去,例如batch_size=2,整个数据的数量为99,此时会出现余数1。
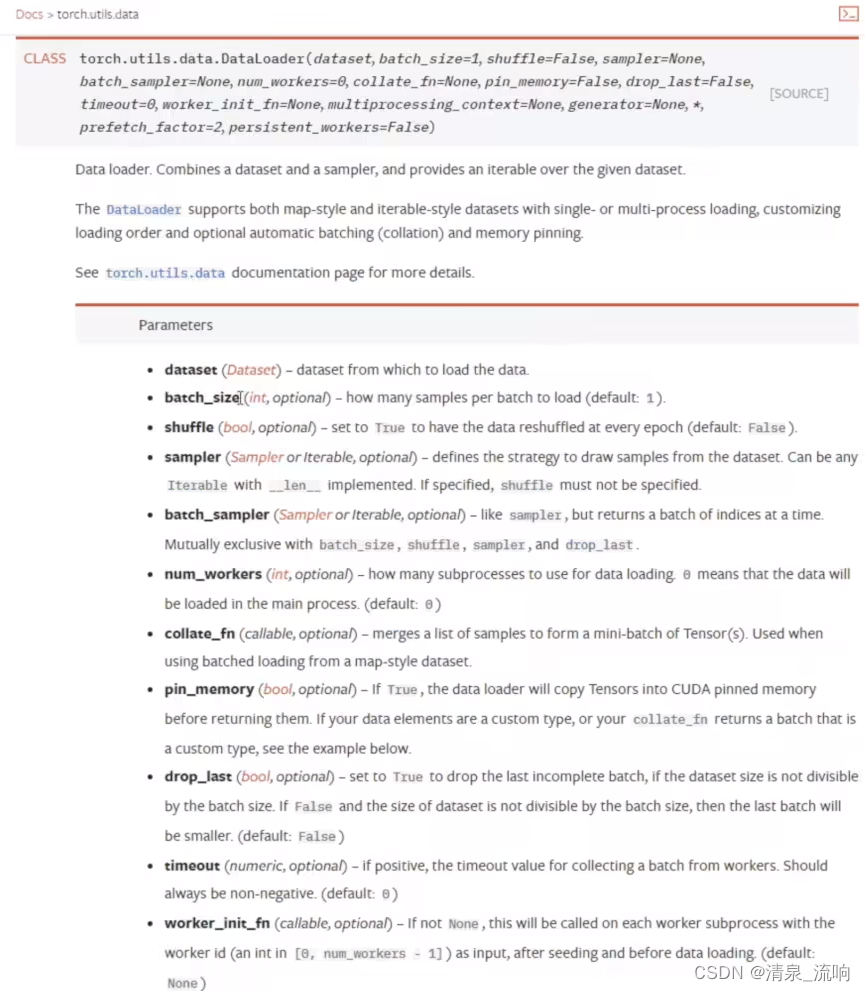
torch.Size([3,32,32])中的3表示3通道(RGB),图片尺寸大小为32*32
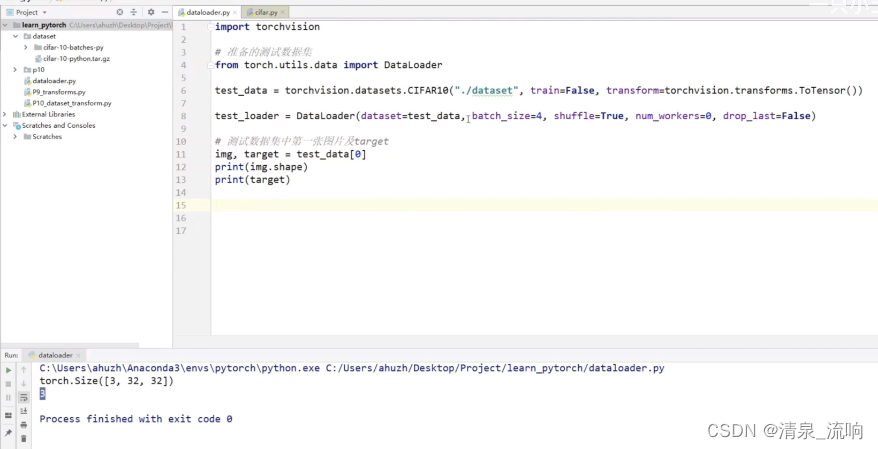
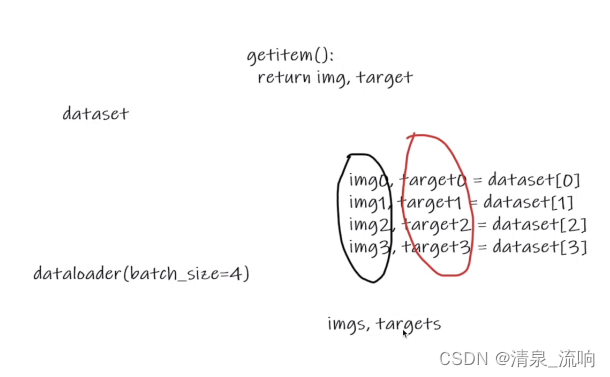
batch_size=4表示从数据集当中取 test_data[0], test_data[1], test_data[2], test_data[3],把它们对应的img进行打包成imgs,把它们对应的target进行打包成targets
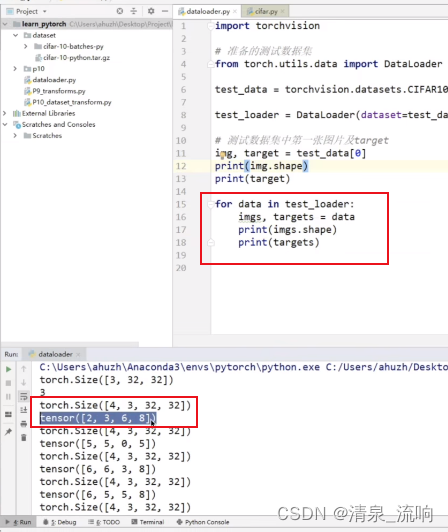
torch.Size([4,,3,32,32])当中的4表示4张图片,也就是batch_size
tensor([2,3,6,8])是把四张图片的target进行打包,每张图片对应的target分别是2,3,6,8
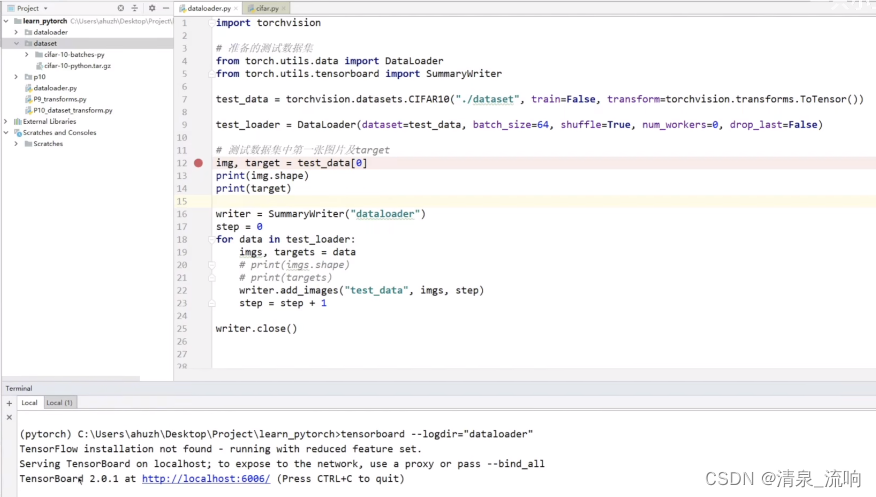
从tensorboard 中可以看到,每次取数据都是64张图片

最后一次取数据是16张图片
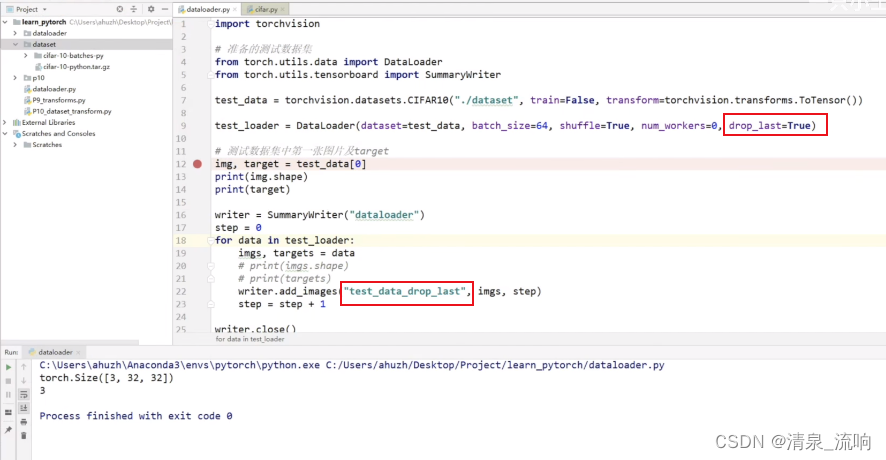
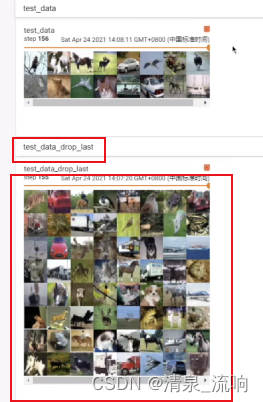
把drop_last设置为True,在tensorboard中观察最后一次数据,发现最后的16张图片舍弃了
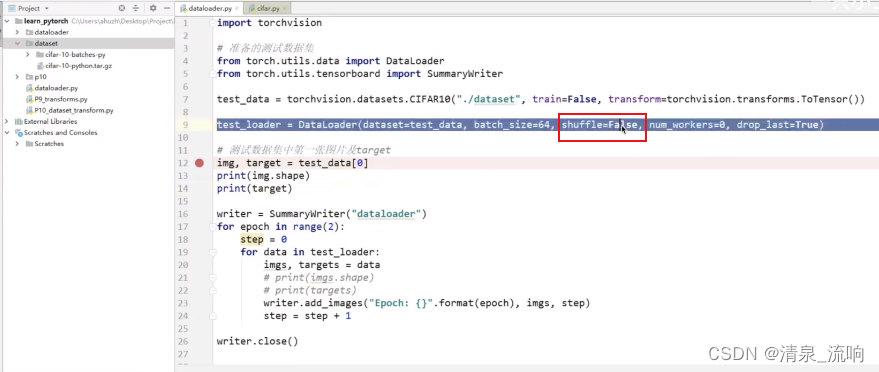
epoch=2表示把所有数据训练2遍,当shuffle=False时,第一次数据和第二次数据的排列顺序是一模一样的。
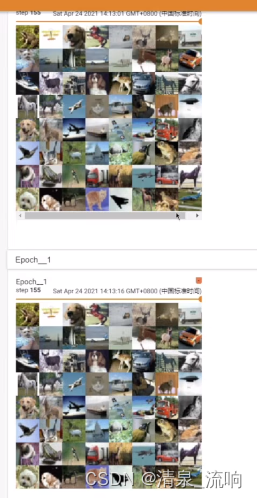
当shuffle=TRUE时,结果如下,一般情况下shuffle设置为TRUE
程序如下:
- import torchvision
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
- test_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",train=False,transform=torchvision.transforms.ToTensor())
- test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
- img,target = test_data[0]
- print(img.shape)
- print(target)
- writer = SummaryWriter("dataloader")
- for epoch in range(2):
- step = 0
- for data in test_loader:
- imgs, targets = data
- # print(imgs.shape)
- # print(targets)
- writer.add_images("Epoch: {}".format(epoch),imgs,step)
- step=step+1
- writer.close()
-
相关阅读:
Spring Boot Maven Plugin -- repackage目标;spring-boot-maven-plugin的executable配置
学生用白炽灯好还是led灯好?2022最专业学生护眼灯推荐
Linux | 性能问题排查
IDEA+MapReduce+Hive综合实践——搜狗日志查询分析
关于c++源文件与头文件的编译规则总结
HTML5期末作业:明星网站设计与实现——明星薛之谦介绍网页设计7个页面HTML+CSS+JavaScript
数据分析与应用:微信-情人节红包流向探索分析
TypeScript在React中的优雅写法
前端性能优化
【超详细~】手把手带你推导傅里叶级数~
- 原文地址:https://blog.csdn.net/qq_42233059/article/details/126641942
