-
推荐系统-Hive基础
基本概念
功能说明

- 操作接口采用类SQL法,提供快速开发的能力
- 避免了去写MapReduce,减少开发人员的学习成本
- 功能扩展很方便
架构


hive和hadoop
- Hive利用HDFS存储数据,利用MapReduce查询分析数据
- 注:Hive是数据仓库工具,没有集群的概念。只需要在hadoop集群Master节点上装Hive。
数据模型
在创建表时指定数据中的分隔符,Hive就可以映射成功,解析数据
- Hive中包含以下数据模型:
- db:在hdfs中表现为hive.metastore.warehouse.dir目录下的一个文件夹
- table:在hdfs中表现所属db目录下一个文件夹
- external table:数据存放位置可以在HDFS任意指定路径
- partition:在hdfs中表现为table目录下的子目录
- bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
安装部署
安装
#Hive安装前需要安装好JDK和Hadoop并配置好环境变量。 #下载Hive的安装包 http://archive.cloudera.com/cdh5/cdh/5/ 并解压 tar -zxvf hive安装包 -C ~/bigdata/ #进入到解压后的hive目录中,找到conf目录,修改配置文件 cp hive-env.sh.template hive-env.sh vi hive-env.sh #在hive-env.sh中指定hadoop的路径 HADOOP_HOME=/root/bigdata/hadoop 配置环境变量 # 编辑文件 vi ~/.bash_profile # 进行环境变量配置 export HIVE_HOME=/root/bigdata/hive export PATH=$HIVE_HOME/bin:$PATH # 更新配置 source ~/.bash_profile- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
启动
- 启动Hive之前先要开启hive的元数据服务

基本操作
注意:
hive创建数据库时不需要指定charset
hive中创建表时需要指定表字段数据之间的分隔符创建数据库 CREATE DATABASE test; 显示所有数据库 SHOW DATABASES; 创建表 CREATE TABLE student(classNo string, stuNo string, score int) row format delimited fields terminated by ','; 将数据load到表中 load data local inpath '/root/tmp/student.txt' overwrite into table student; 查询表中的数据跟SQL类似 hive>select * from student; 分组查询group by和统计count hive>select classNo,count(score) from student where score>=60 group by classNo;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
对于复杂的hql查询,会被翻译成mapreduce任务执行
hive的内部表和外部表
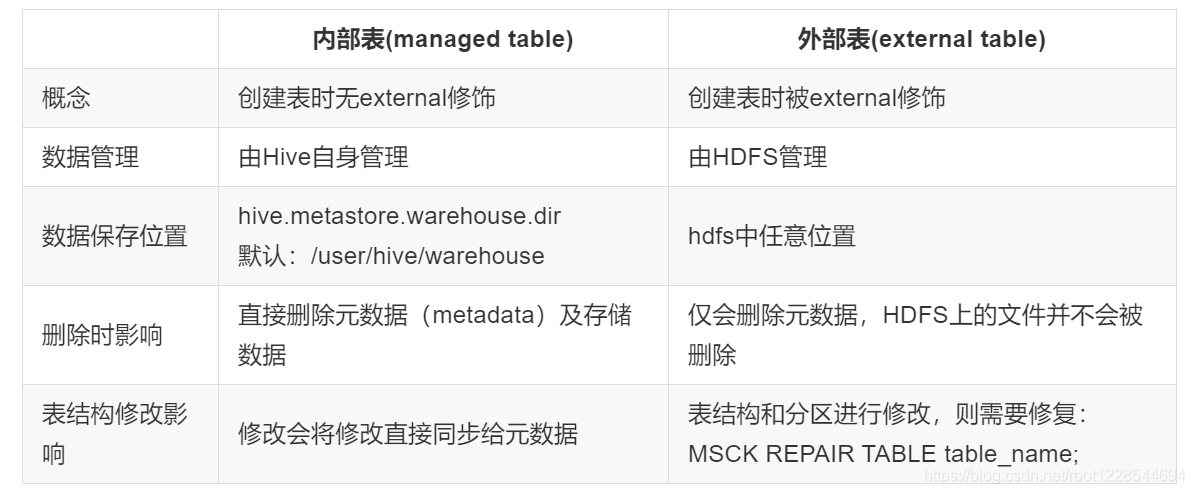
创建一个外部表student2 CREATE EXTERNAL TABLE student2 (classNo string, stuNo string, score int) row format delimited fields terminated by ',' location '/root/tmp/student'; 装载数据 load data local inpath '/root/tmp/student.txt' overwrite into table student2; 显示表信息 desc formatted table_name; 删除表查看结果 drop table student2; 再次创建外部表student2 不插入数据直接查询查看结果 select * from student2;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
分区表
- hive中分区表实际就是对应hdfs文件系统上独立的文件夹,该文件夹内的文件是该分区所有数据文件
- 表现:在hdfs中表现为table目录下的一个子目录。
- 作用:使用分区字段查询时,不会进行全表扫描,查询效率高。
创建分区表 create table employee (name string,salary bigint) partitioned by (date1 string) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile; 查看表的分区 show partitions employee; 添加分区 alter table employee add if not exists partition(date1='2018-12-01'); 加载数据到分区 load data local inpath '/root/tmp/employee.txt' into table employee partition(date1='2018-12-01'); 如果重复加载同名文件,不会报错,会自动创建一个*_copy_1.txt 外部分区表即使有分区的目录结构, 也必须要通过hql添加分区, 才能看到相应的数据 hadoop fs -mkdir /user/hive/warehouse/test.db/employee/date1=2018-12-04 hadoop fs -copyFromLocal /root/tmp/employee.txt /user/hive/warehouse/test.db/employee/date1=2018-12-04/employee.txt 此时查看表中数据发现数据并没有变化, 需要通过hql添加分区 alter table employee add if not exists partition(date1='2018-12-04');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
分区字段不是数据文件中的列数据
分区字段的值仅仅是一个目录名
查看数据时,hive会自动添加分区列
支持多级分区也就是多级子目录动态分区
在写入数据时自动创建分区(包括目录结构) 创建表 create table employee2 (name string,salary bigint) partitioned by (date1 string) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile; 导入数据 insert into table employee2 partition(date1) select name, salary, date1 from employee; 使用动态分区需要设置参数 set hive.exec.dynamic.partition.mode=nonstrict;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Hive函数
Hive内置运算符和内置函数
Hive有四种类型的运算符:
关系运算符
算术运算符
逻辑运算符
复杂运算
Hive内置函数
简单函数: 日期函数、字符串函数、类型转换
统计函数:sum、avg、distinct
集合函数:size、array_contains
show functions:显示所有函数
desc function 函数名;
desc function extended 函数名;Hive自定义函数
UDF:用户自定义函数(user-defined function),相当于mapper,对每一条输入数据,映射为一条输出数据
UDAF:用户自定义聚合函数 (user-defined aggregation function),相当于reducer,做聚合操作,把一组输入数据映射为一条(或多条)输出数据。在hdfs中创建/user/hive/lib目录 hadoop fs -mkdir /user/hive/lib 把hive目录下lib/hive-contrib-2.3.4.jar放到hdfs中 hadoop fs -put hive-contrib-2.3.4.jar /user/hive/lib/ 把集群中jar包的位置添加到hive中 hive> add jar hdfs:///user/hive/lib/hive-contrib-2.3.4.jar; 在hive中创建临时UDF hive> create temporary function row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFRowSequence'; 在之前的案例中使用临时自定义函数(函数功能:添加自增长的行号) select row_sequence(), * from employee; 创建非临时自定义函数 create function row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFRowSequence' using jar 'hdfs:///user/hive/lib/hive-contrib-2.3.4.jar';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Python UDF
#准备案例环境 #创建表 create table users(fname STRING,lname STRING); #向表中插入数据 insert into table users values('George','washington'); insert into table users values('George','bush'); insert into table users values('Bill','clinton'); insert into table users values('Bill','gates'); #编写map风格脚本 import sys for line in sys.stdin: line = line.strip() fname , lname = line.split('\t') l_name = lname.upper() print '\t'.join([fname, str(l_name)]) #通过hdfs向hive中add file #加载文件到hdfs hadoop fs -put udf.py /user/hive/lib/ #hive从hdfs中加载python脚本 add file hdfs:///user/hive/lib/udf.py; # Transform select TRANSFORM(fname, lname) using 'python udf.py' as (fname, l_name) from users;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
综合案例
-
相关阅读:
力扣198. 打家劫舍
342.4的幂
顺序表--C语言版(从0开始,超详细解析 ,小白一听就懂!!!)
java基于springboot房产门户房屋出租销售网站—计算机毕业设计
算法金 | 读者问了个关于深度学习卷积神经网络(CNN)核心概念的问题
LeetCode 2341. 数组能形成多少数对
RichView TRVDocParameters 页面参数设置
网页开发工具VSCode的使用
MySQL面试题——隔离级别相关面试题
华为HCIP Datacom H12-821 卷19
- 原文地址:https://blog.csdn.net/root1228544694/article/details/107769765
