-
【Q-Learning】TD算法的一种
强化学习相关的Q-Learning算法的介绍。此处笔记根据B站课程,王树森老师的强化学习记录而来。8.Q-Learning算法 (TD Learning 2_3)(Av374239425,P8)_哔哩哔哩_bilibili
1.Q-Learning
Q-Learning也是TD算法的一种,也是训练价值网络,但是和Saras不同。


Sarsa 近似QΠ,学习动作价值函数 Q-Learning 近似Q*,学习最优动作价值函数,学习DQN 2.推导TD Target
已知QΠ的期望表达式,推导最优的QΠ*。最优价值函数。其期望表达式形式为:



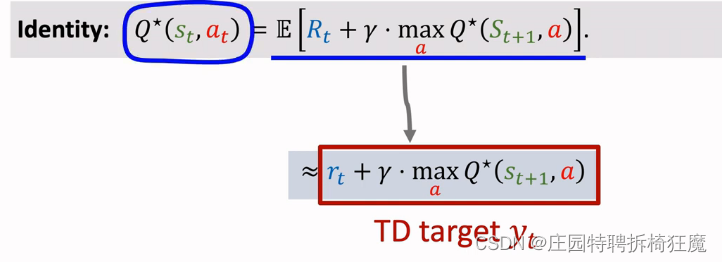
则A(t+1)=argmax Q*(s(t+1),a),是最优动作。Q*替换为最大化形式,近似Q*Π的期望形式,对a求蒙特卡洛近似。Q*的表达式为:
3.表格形式的Q-Learning:Tabular Version
观测到(s(t),a(t),r(t),s(t+1))——>计算yt,最大化的求解过程即在对那个的s(t+1)的行里找到价值最高的动作a(t)。


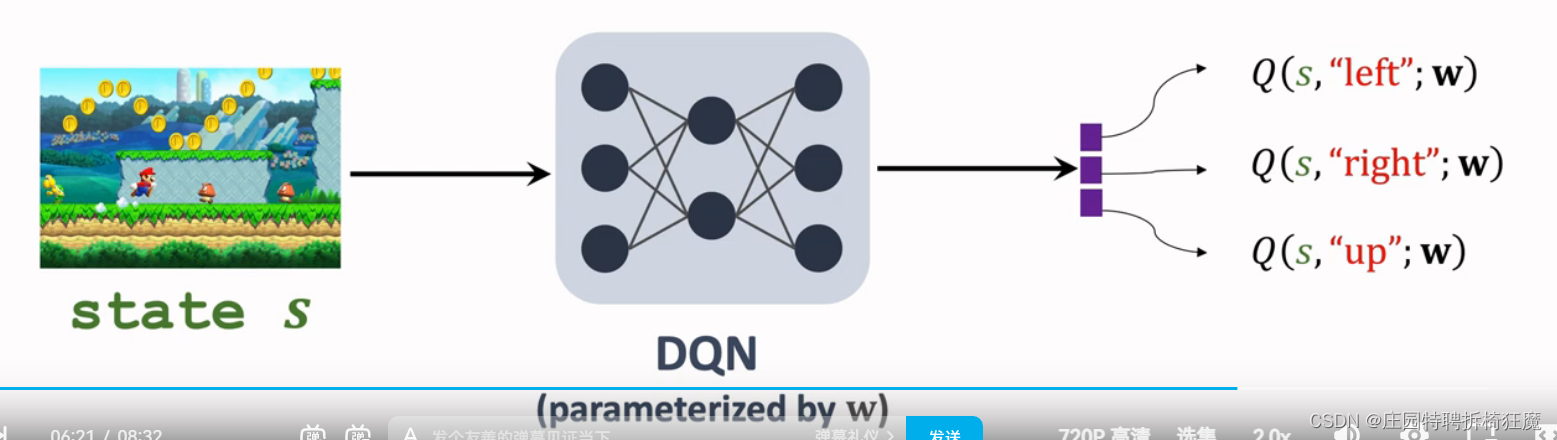
4.神经网络形式的Q-Learning
训练一个QDN网络近似Q*,为所有的动作打分。


Summary:

-
相关阅读:
MS2358:96KHz、24bit 音频 ADC
开源现场总线协议栈
老板叫我把几十万条Excel数据录入系统
Linux文件系统
Linux(八)——解压缩
李宏毅 2022机器学习 HW3 boss baseline 上分记录
[2022/6/29]考试总结
了解操作符的那些事(二)
Git引起的 gitlab-runner 报错
spring-cloud-dubbo基本使用
- 原文地址:https://blog.csdn.net/lt_BeiMo/article/details/126648466