-
离线数仓(9):ODS层实现之导入业务数据
目录
4.2. ods_fmys_goods_ext_dt_start节点说明
4.3. ods_fmys_goods_ext_dt_CDM任务节点说明
4.4. ods_fmys_goods_ext_dt_DLI任务节点说明
4.5. ods_fmys_goods_ext_视图创建节点说明
5.2. ods_fmys_goods_ext_record_dt_start节点
5.3. ods_fmys_goods_ext_record_dt_跑数脚本
0. 相关文章链接
1. ODS层概述
1.1. 数仓分层图

1.2. 数仓数据走向图
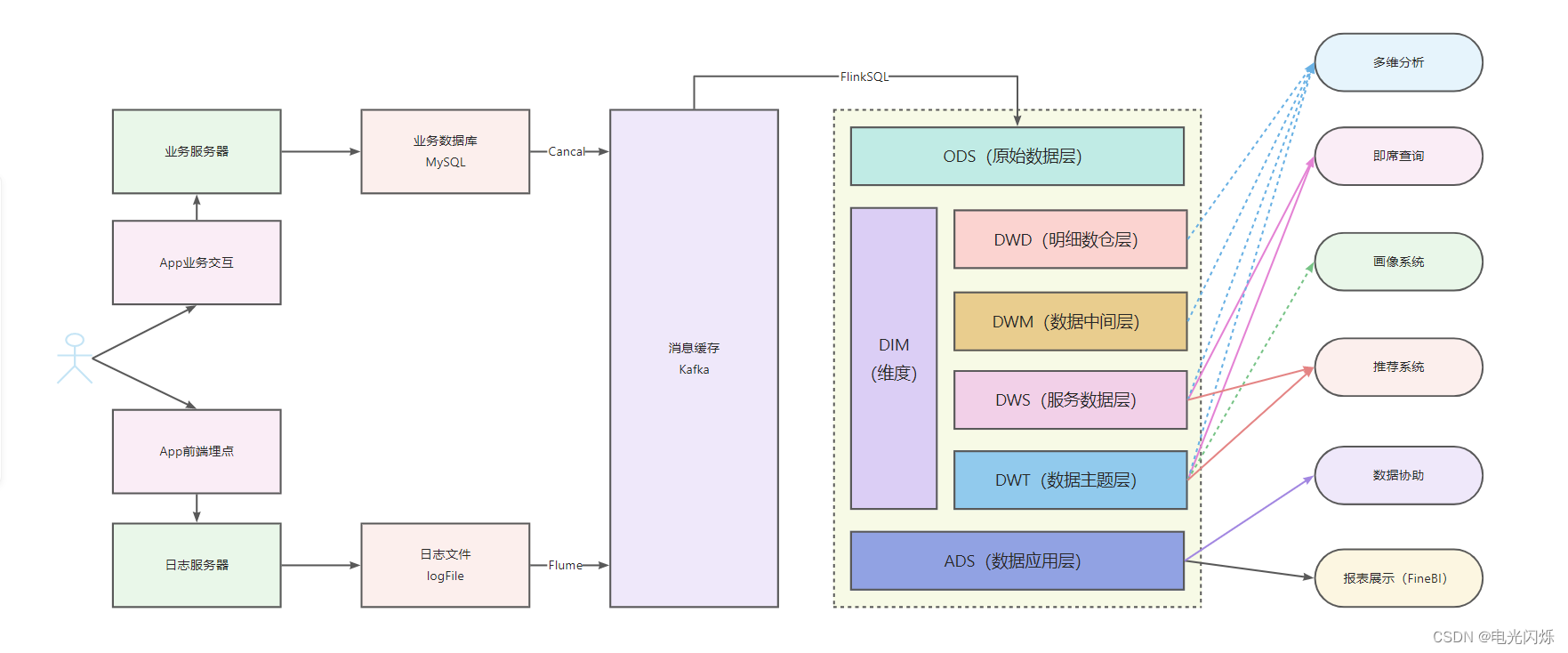
1.3. 实现目标
根据如上数仓分层图和数仓数据走向图,可以看出ods层的主要目的有如下3点:
- 保持数据原貌不做任何修改,起到备份数据的作用
- 数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右)
- 创建分区表,防止后续的全表扫描
所以在此次的数仓分层重构中,ods层分别实现了上述3点:
- 将业务数据写入到数仓中,并每天进行一个全量快照备份(其实可以只备份新增和变化的数据,但我们根据实际业务情况和其他各方面等考虑,进行了全量快照备份,并且如果进行全量快照备份的话,保留180天数据完全足够)
- 除binlog数据通过FlinkSQL写入到文件系统使用了parquet格式外,其他的分区表均使用了orc格式压缩(之所以使用orc压缩,是因为在华为云平台中,有个GaussDBForDWS数据库的服务,用于数据分析的,该数据库底层是PG库,可以支持ORC格式的外部表)
- 在建表时创建了分区表(除了每天一个全量快照备份,还将binlog中各个表的修改记录进行了保存,在后续如果使用拉链表时可以用到)
2. 数据准实时进入文件系统
根据上述数仓数据走向图,使用Cancal、FlinkCDC或者华为云的数据复制服务DRS将binlog数据采集写入到kafka中就不详细介绍了,只介绍数据到达kafka后的后续流向。
跟流量日志数据类似,博主这里还是使用了华为云DLI服务中的FlinkSQL将kafka中的数据进行获取,并将数据写入到OBS文件系统中,具体实现代码如下(需要现在OBS并行文件系统中创建对应目录):
- -- kafka的 bigdata_mysql_binlog_avro 主题中示例数据如下
- -- 注意:其中的nanoTime是使用Java中的System.nanoTime()函数生成的,也就是说,如果程序失败,需要将分区数据删除,然后在flink作业中设置拉取时间重跑
- -- 具体字段描述如下:
- -- db: 在MySQL中对应的数据库
- -- tb: 在MySQL中对应的表
- -- columns: 一个JSONArray,表示所有的字段,如下示例,一个JSONArray中存在该表中所有字段,存储的json的key为字段名,在该json中又有value这个属性,表示该字段对应的值
- -- event: event对应操作类型和数值: insert = 0 ; delete = 1 ; update = 2 ; alter = 3 ;
- -- sql: 触发该更改或删除等操作的sql语句
- -- primary_key: 该更改的主键
- -- create_time: 该数据从binlog中获取出来的时间(分区就用此时间)
- -- sendTime: 该数据进入到kafka的时间(该时间不用)
- -- nano_time: 纳秒级时间戳,用了区分数据的前后,使用此时间可以保证数据唯一
- -- {
- -- "columns": {
- -- "admin_note": {
- -- "key": false,
- -- "mysqlType": "varchar(255)",
- -- "name": "admin_note",
- -- "null_val": false,
- -- "update": false,
- -- "value": ""
- -- },
- -- "allot_num": {
- -- "key": false,
- -- "mysqlType": "smallint(5) unsigned",
- -- "name": "allot_num",
- -- "null_val": false,
- -- "update": false,
- -- "value": "0"
- -- }
- -- },
- -- "createTime": 1649213973044,
- -- "db": "yishou",
- -- "event": 2,
- -- "nanoTime": 23494049498709146,
- -- "primaryKey": "157128418",
- -- "sendTime": 1649213973045,
- -- "sql": "",
- -- "tb": "fmys_order_infos"
- -- }
- -- 命名规范
- -- 流类型_数据源_主题(表)
- -- 例: source_kafka_bigdata_mysql_binlog_avro
- -- 自定义日期格式化方法
- CREATE FUNCTION date_formatted AS 'com.yishou.cdc.udf.DateFormattedUDF';
- -- ==================================================================================
- -- 将数据写入到obs中,通过DLI中的外部表关联
- -- source端,对接kafka,从kafka中获取数据
- CREATE SOURCE STREAM source_kafka_bigdata_mysql_binlog_avro (
- db STRING,
- tb STRING,
- `columns` STRING,
- event INT,
- `sql` STRING,
- `primary_key` STRING,
- create_time bigint,
- send_time bigint,
- nano_time bigint
- ) WITH (
- type = "kafka",
- kafka_bootstrap_servers = "xxx1:9092,xxx2:9092,xxx3:9092",
- kafka_group_id = "business_data_to_obs",
- kafka_topic = "bigdata_mysql_binlog_avro",
- encode = "user_defined",
- encode_class_name = "com.yishou.cdc.source.YishouAvroDerializationSchema",
- encode_class_parameter = ""
- );
- -- sink端,对接obs,将数据写入到obs中
- CREATE SINK STREAM sink_obs_ods_binlog_data (
- db STRING,
- tb STRING,
- `columns` STRING,
- event bigint,
- `sql` STRING,
- `primary_key` STRING,
- create_time bigint,
- send_time bigint,
- nano_time bigint,
- dt STRING
- ) PARTITIONED BY(dt,tb) WITH (
- type = "filesystem",
- file.path = "obs://yishou-test/yishou_data_qa_test.db/ods_binlog_data",
- encode = "parquet",
- ak = "akxxx",
- sk = "skxxx"
- );
- -- 从source表获取数据,写出到sink表中
- INSERT INTO
- sink_obs_ods_binlog_data
- SELECT
- db,
- tb,
- `columns`,
- cast(event as bigint) event,
- `sql`,
- `primary_key`,
- create_time,
- send_time,
- nano_time,
- date_formatted(
- cast(coalesce(create_time, UNIX_TIMESTAMP_MS()) / 1000 - 25200 as VARCHAR(10)),
- 'yyyyMMdd'
- ) as dt
- FROM
- source_kafka_bigdata_mysql_binlog_avro;
- -- ==================================================================================
注意:
- 上述是使用华为云的FlinkSQL实现的,跟开源的FlinkSQL有些不同,但大体类似,可以根据实际情况来进行开发;
- 上述的FlinkSQL是将所有的业务数据变更的binlog均写入了OBS文件系统中,在文件系统中使用了双重分区(日期和表名),可以获取每一天每张表的更新修改删除的binlog数据;
- 上述使用了一个自定义函数,将10位时间戳转换成了8位的年月日格式,在开源的FlinkSQL中已有类似函数,不过华为云的FlinkSQL这个版本中还没有,所以添加了自定义函数,具体情况具体开发即可;
- 另外博主在将数据写入到kafka中时,还使用了avro压缩格式,所以在拉取数据时,还需要进行了解压,其实在kafka中只存储近7天数据,在使用时不进行压缩也可以;
- 博主这里因为业务原因,所以在写入时将数据减去了7个小时(即25200秒),统计的不是0点到第二天0点的数据,而是7点到第二天7点的数据;
在华为云的DLI服务中,运行界面如下所示:
- FlinkSQL作业详情配置图

- FlinkSQL任务列表图:

- OBS文件系统(正常运行后每分钟每张表生成一个新的文件【该表在这分钟要有数据变化】):

3. 创建外部表
3.1. ods_binlog_data建表语句
- drop table if exists ${yishou_data_dbname}.ods_binlog_data;
- CREATE TABLE if not exists ${yishou_data_dbname}.ods_binlog_data (
- `db` STRING COMMENT '数据库名',
- `columns` STRING COMMENT '列数据',
- `event` BIGINT COMMENT '操作类型',
- `sql` STRING COMMENT '执行的SQL',
- `primary_key` STRING COMMENT '主键的值',
- `create_time` BIGINT COMMENT '从MySQL中获取binlog的13位时间戳',
- `send_time` BIGINT COMMENT '发送binlog到kafka的13位时间戳',
- `nano_time` BIGINT COMMENT '纳秒级更新时间戳',
- `dt` BIGINT COMMENT '日期分区',
- `tb` STRING COMMENT '表名'
- ) USING parquet PARTITIONED BY (dt, tb) COMMENT 'ods层binlog表(所有通过binlog进入数仓的数据均在此表中)'
- LOCATION 'obs://yishou-test/yishou_data_qa_test.db/ods_binlog_data'
- ;
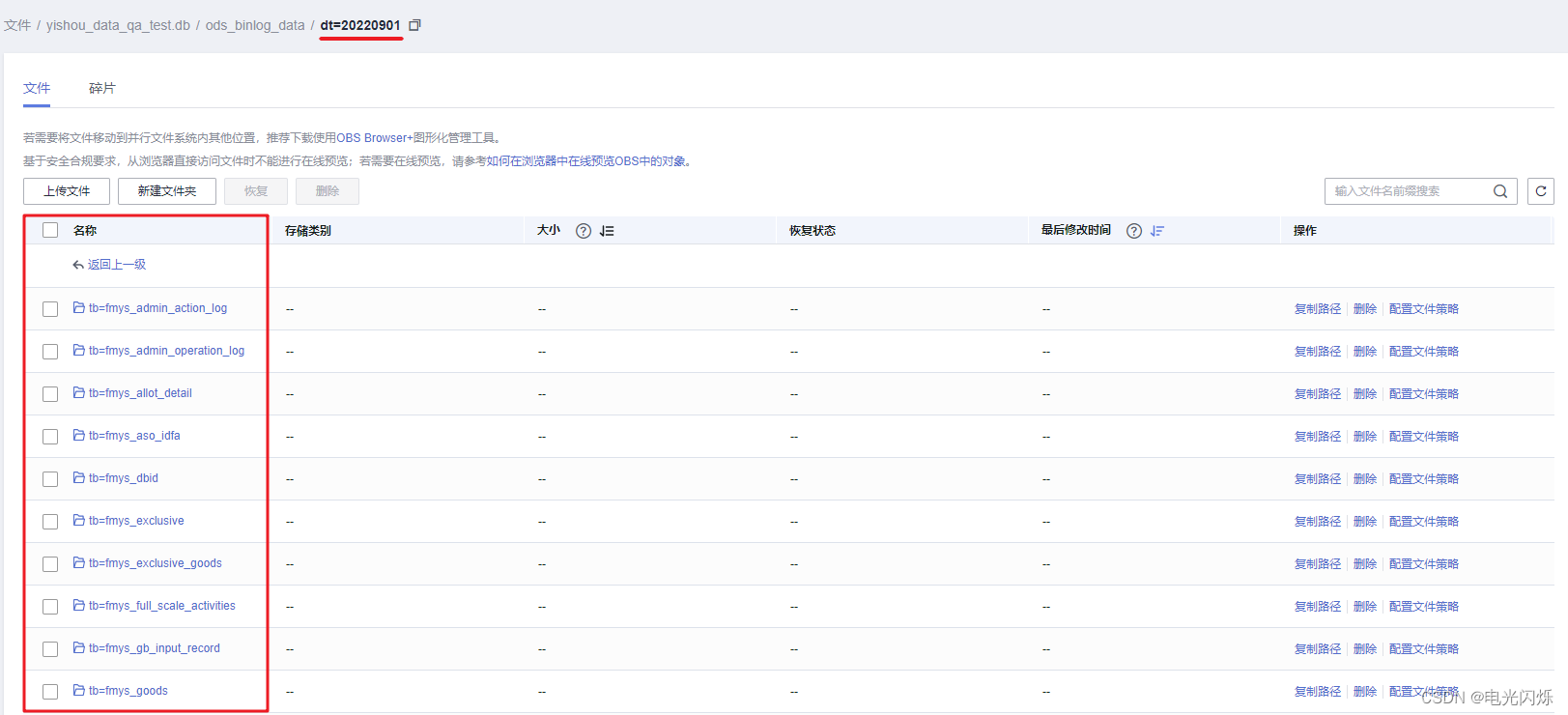
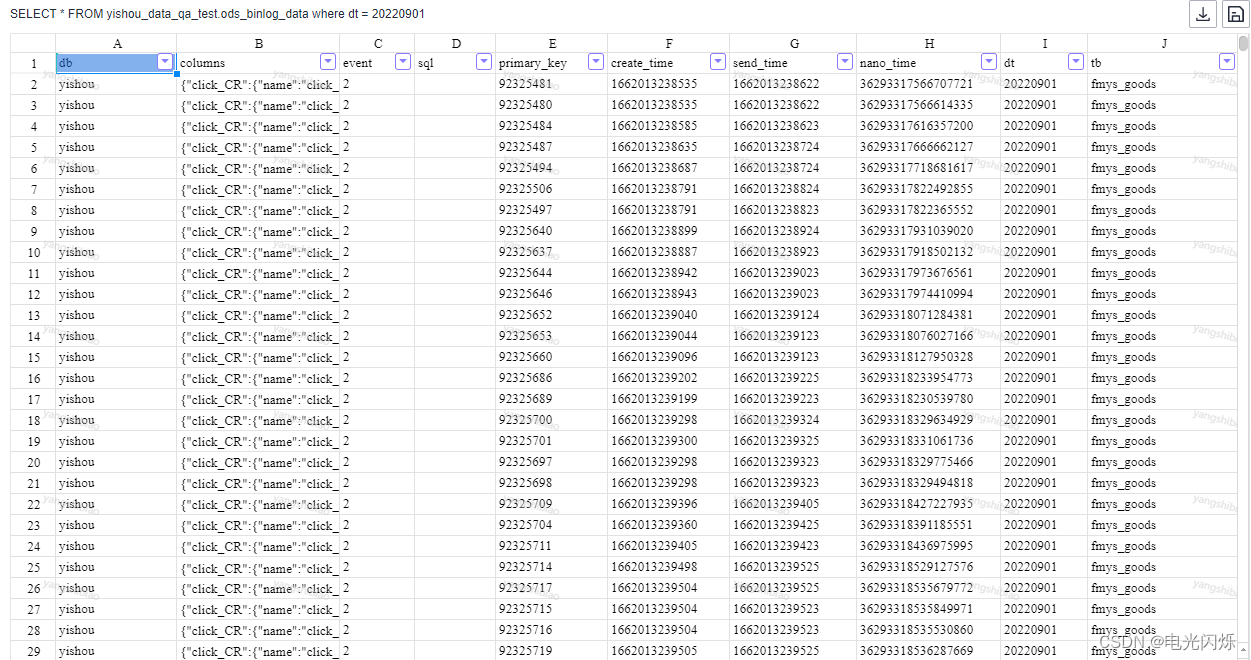
以上述通过FlinkSQL写入到OBS文件系统中的目录为数据目录,创建对应的外部表,查询数据结果如下所示:
3.2. 业务库对应ods层快照表建表语句
- drop table if exists ${yishou_data_dbname}.ods_fmys_goods_ext_dt;
- CREATE EXTERNAL TABLE ${yishou_data_dbname}.ods_fmys_goods_ext_dt (
- `goods_id` BIGINT COMMENT '*',
- `limit_day` BIGINT COMMENT '*',
- `auto_time` STRING COMMENT '*',
- `is_new` BIGINT COMMENT '-1 无效(下架) 0 旧款(有效/上架) 1 新款',
- `grade` BIGINT COMMENT '商品档次',
- `season` BIGINT COMMENT '季节',
- `goods_type` BIGINT COMMENT '商品类型{1:特价,}'
- ) COMMENT '商品拓展信息表(ods层快照分区表)'
- PARTITIONED BY (`dt` BIGINT COMMENT '日期分区(yyyymmdd)')
- STORED AS orc LOCATION 'obs://yishou-test/yishou_data_qa_test.db/ods_fmys_goods_ext_dt'
- ;
上述建表语句和后端业务库的字段需要一一对应,并将对应的数据类型转换成数仓中数据类型。
3.3. 业务库对应ods层历史变更记录表建表语句
- drop table if exists ${yishou_data_dbname}.ods_fmys_goods_ext_record_dt;
- CREATE EXTERNAL TABLE ${yishou_data_dbname}.ods_fmys_goods_ext_record_dt(
- `goods_id` BIGINT COMMENT '*',
- `limit_day` BIGINT COMMENT '*',
- `auto_time` STRING COMMENT '*',
- `is_new` BIGINT COMMENT '-1 无效(下架) 0 旧款(有效/上架) 1 新款',
- `grade` BIGINT COMMENT '商品档次',
- `season` BIGINT COMMENT '季节',
- `goods_type` BIGINT COMMENT '商品类型{1:特价}',
- `event` BIGINT COMMENT '数据操作类型(0:插入;1:删除;2:修改)',
- `record_time` BIGINT COMMENT '从MySQL中获取binlog的13位时间戳',
- `nano_time` BIGINT COMMENT '纳秒级更新时间戳(当record_time相同时,使用此时间戳来判断先后)'
- ) COMMENT '商品拓展信息历史更改记录表(一个分区内保存该业务表历史所有的变更记录)'
- PARTITIONED BY (`dt` BIGINT COMMENT '日期分区')
- STORED AS orc LOCATION 'obs://yishou-test/yishou_data_qa_test.db/ods_fmys_goods_ext_record_dt'
- ;
上述建表语句和后端业务库的字段需要一一对应,并且其中添加了数据操作类型、记录时间戳和纳秒级更新时间戳这3个字段,用了记录这条数据历史上什么时候做了什么变更。
4. ods层快照表调度任务创建
4.1. 概述
架构图:

说明:
- 该作业为每天早晨7点零5分调度(因业务原因,统计的是昨天7点到今天7点的数据,并且给数据归档和传输的时间,所以7点零5分开始调度执行);
- 该作业有2条分支,1条为通过CDM任务(即通过Sqoop拉取全量业务库的数据),1条为DLI任务(即通过昨天的全量数据和昨天的binlog数据进行汇总聚合得出最新的业务库的表数据);
- 通过华为云的EL表达式来判断执行哪条分支(CDM的EL表达式:#{DateUtil.format(Job.planTime,"HHmmss") != '070500' ? 'true' : 'false'} ; DLI的EL表达式:#{DateUtil.format(Job.planTime,"HHmmss") == '070500' ? 'true' : 'false'});正常调度时(早晨7点零5分运行)会执行DLI任务,运行速度很快,一般2分钟内执行完成;当感觉数据异常时,使用补数据的方法执行作业时(不是7点零5分运行),会执行CDM任务,执行速度慢,会全量拉取数据;
- 会将全量结果数据输出到业务库表对应的ods表中,并生成一个以昨天日期的分区,这就是按天全量快照备份;
- 最后会创建一个视图,该视图为分钟级更新,会和业务库中对应表的数据一模一样(下述具体介绍);
4.2. ods_fmys_goods_ext_dt_start节点说明
该节点为SQL节点,具体代码如下:
- -- 在ods_binlog_data表中增加对应日期和表名的分区
- ALTER TABLE ${yishou_data_dbname}.ods_binlog_data ADD if not exists PARTITION (dt=${today}, tb = 'fmys_goods_ext');
主要目的是新增ods_binlog_data表对应日期和业务表的分区,后续使用ods_binlog_data表可以直接使用对应的双重分区。
4.3. ods_fmys_goods_ext_dt_CDM任务节点说明
此节点为CMD(即Sqoop)作业,会将业务库中的全量数据拉取到数仓的ods表中(通过overwrite的方式,将数据写入到昨天的分区中),当手动调度时才执行此节点,主要目的是当感觉数据有误时,可以使用此作业来更新替换最新最全最正确的数据。
CDM任务配置如下:
4.4. ods_fmys_goods_ext_dt_DLI任务节点说明
当正常调度时,会执行此节点,会使用ods前天的分区然后和昨天以及之后的binlog数据合并,再将数据插入到ods的昨天的分区中;因为是跑的SQL作业,不需要拉取数据,所以会执行的较快,正常调度时就使用此种方法运行。
代码如下所示:
- -- DLI sql
- -- ******************************************************************** --
- -- author: yangshibiao
- -- create time: 2022/09/01 10:15:46 GMT+08:00
- -- ******************************************************************** --
- -- 从ods_fmys_goods_ext_dt表中获取出前天分区的数据(即相当于昨天7点之前的所有数据)
- -- 从ods_binlog_data表中获取出昨天分区以及之后分区的数据(即昨天7点之后的增量更新的binlog数据)
- -- 然后2份数据对主键开窗,获取最新的,并且不是被删除的数据,然后将数据插入到ods_fmys_goods_ext_dt昨天的分区中(T-1,即今天7点之前的所有历史数据)
- -- 注意:从ods_fmys_goods_ext_dt表中获取出前天分区的数据时,因为在这张表里没有 nano_time 和 event 字段,所以需要手动设置,设置nano_time为一个很小的值,设置event为0,即插入的数据即可
- insert overwrite table ${yishou_data_dbname}.ods_fmys_goods_ext_dt partition(dt)
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , ${one_day_ago} as dt
- from (
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , nano_time
- , event
- , row_number() over(partition by goods_id order by nano_time desc) as row_number
- from (
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , -987654321012345 as nano_time
- , 0 as event
- from ${yishou_data_dbname}.ods_fmys_goods_ext_dt
- where dt = ${two_day_ago}
- union all
- select
- get_json_object(columns ,'$.goods_id.value') as goods_id
- , get_json_object(columns ,'$.limit_day.value') as limit_day
- , get_json_object(columns ,'$.auto_time.value') as auto_time
- , get_json_object(columns ,'$.is_new.value') as is_new
- , get_json_object(columns ,'$.grade.value') as grade
- , get_json_object(columns ,'$.season.value') as season
- , get_json_object(columns ,'$.goods_type.value') as goods_type
- , nano_time as nano_time
- , event as event
- from ${yishou_data_dbname}.ods_binlog_data
- where
- dt >= ${one_day_ago}
- and tb = 'fmys_goods_ext'
- )
- )
- -- event为1就是删除的数据,当最后一次记录为删除数据的时候,就不用这个主键了,因为已经删除了
- where row_number = 1 and event != 1
- DISTRIBUTE BY floor(rand()*10)
- ;
4.5. ods_fmys_goods_ext_视图创建节点说明
此节点的目的是使用ods昨天的分区和binlog今天以及之后的分区生成一张ods的视图,因为binlog的数据是实时更新的,所以这个ods的视图每次查询的都是最新的,跟业务库可以做到准实时。
代码如下所示:
- -- DLI sql
- -- ******************************************************************** --
- -- author: yangshibiao
- -- create time: 2022/09/01 10:25:56 GMT+08:00
- -- ******************************************************************** --
- -- 目的:
- -- 创建业务库对应的ods层视图,主要目的是按照分钟级别,将业务库的数据同步到数据仓库中,即每分钟在数仓中查询这个视图会和业务库中对应表的数据一模一样
- -- 实现思路:
- -- 1、从ods_fmys_goods_ext_dt表中获取出昨天分区的数据(即相当于今天7点之前的所有数据)
- -- 2、从ods_binlog_data表中获取出今天分区以及之后分区的数据(即今天7点开始该表增量更新的binlog数据)
- -- 3、然后2份数据对主键开窗,获取最新的,并且不是被删除的数据,因为binlog数据每分钟更新一次,所以可以实现业务表数据分钟级进入数据仓库
- drop view if exists ${yishou_data_dbname}.ods_fmys_goods_ext;
- create view if not exists ${yishou_data_dbname}.ods_fmys_goods_ext(
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- ) comment 'fmys_goods_ext在ods层视图(根据业务库数据,分钟级别更新)'
- as
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- from (
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , nano_time
- , event
- , row_number() over(partition by goods_id order by nano_time desc) as row_number
- from (
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , -987654321012345 as nano_time
- , 0 as event
- from ${yishou_data_dbname}.ods_fmys_goods_ext_dt
- where dt = ${one_day_ago}
- union all
- select
- get_json_object(columns ,'$.goods_id.value') as goods_id
- , get_json_object(columns ,'$.limit_day.value') as limit_day
- , get_json_object(columns ,'$.auto_time.value') as auto_time
- , get_json_object(columns ,'$.is_new.value') as is_new
- , get_json_object(columns ,'$.grade.value') as grade
- , get_json_object(columns ,'$.season.value') as season
- , get_json_object(columns ,'$.goods_type.value') as goods_type
- , nano_time as nano_time
- , event as event
- from ${yishou_data_dbname}.ods_binlog_data
- where
- dt >= ${today}
- and tb = 'fmys_goods_ext'
- )
- )
- where row_number = 1 and event != 1
- ;
注意:ods_binlog_data表中对应数据格式如下所示,上述DLI节点和视图节点均使用get_json_object函数进行了数据解析
- {
- "columns": {
- "admin_note": {
- "key": false,
- "mysqlType": "varchar(255)",
- "name": "admin_note",
- "null_val": false,
- "update": false,
- "value": ""
- },
- "allot_num": {
- "key": false,
- "mysqlType": "smallint(5) unsigned",
- "name": "allot_num",
- "null_val": false,
- "update": false,
- "value": "0"
- }
- },
- "createTime": 1649213973044,
- "db": "yishou",
- "event": 2,
- "nanoTime": 23494049498709146,
- "primaryKey": "157128418",
- "sendTime": 1649213973045,
- "sql": "",
- "tb": "fmys_order_infos"
- }
5. ods层历史变更记录表调度任务创建
5.1. 概述
架构图如下:

说明:
- 该作业为每天早晨7点零5分调度(因业务原因,统计的是昨天7点到今天7点的数据,并且给数据归档和传输的时间,所以7点零5分开始调度执行);
- 该作业用记录表前天的分区和binlog昨天的分区汇总,即是记录表昨天分区的数据;
5.2. ods_fmys_goods_ext_record_dt_start节点
该节点为SQL节点,具体代码如下:
- -- 在ods_binlog_data表中增加对应日期和表名的分区
- ALTER TABLE ${yishou_data_dbname}.ods_binlog_data ADD if not exists PARTITION (dt=${today}, tb = 'fmys_goods_ext');
主要目的是新增ods_binlog_data表对应日期和业务表的分区,后续使用ods_binlog_data表可以直接使用对应的双重分区。在上述的ods层快照表调度任务中已有该脚本执行,但在实际跑数时,不确定这2个哪个先行执行,而如果添加依赖也不符合常理,所以添加一段这样的脚本即可,其中使用 if not exists语法。
5.3. ods_fmys_goods_ext_record_dt_跑数脚本
此节点会输出最新的业务表对应的历史记录表分区,脚本如下:
- -- DLI sql
- -- ******************************************************************** --
- -- author: yangshibiao
- -- create time: 2022/08/15 11:45:36 GMT+08:00
- -- ******************************************************************** --
- -- 执行脚本(记录表前天分区的数据和binlog昨天分区的数据 union all 再写入昨天的分区即可)
- insert overwrite table ${yishou_data_dbname}.ods_fmys_goods_ext_record_dt partition(dt)
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , event
- , record_time
- , nano_time
- , ${one_day_ago} as dt
- from (
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , event
- , record_time
- , nano_time
- from ${yishou_data_dbname}.ods_fmys_goods_ext_record_dt
- where dt = ${two_day_ago}
- union all
- select
- get_json_object(columns ,'$.goods_id.value') as goods_id
- , get_json_object(columns ,'$.limit_day.value') as limit_day
- , get_json_object(columns ,'$.auto_time.value') as auto_time
- , get_json_object(columns ,'$.is_new.value') as is_new
- , get_json_object(columns ,'$.grade.value') as grade
- , get_json_object(columns ,'$.season.value') as season
- , get_json_object(columns ,'$.goods_type.value') as goods_type
- , event
- , create_time as record_time
- , nano_time as nano_time
- from ${yishou_data_dbname}.ods_binlog_data
- where
- dt = ${one_day_ago}
- and tb = 'fmys_goods_ext'
- )
- DISTRIBUTE BY floor(rand()*10)
- ;
- -- 初始化脚本(任务调度之前手动执行初始化脚本)(将昨天的分区快照表数据写入到记录表昨天的分区,并设置event为0,设置record_time为0,设置nano_time为一个很小的数)
- -- 注意:执行初始化脚本时,需要注意昨天的分区快照表数据是否有,一般为前置表上线第二天进行初始化,然后就可以启动作业调度,自动调度执行
- -- insert overwrite table ${yishou_data_dbname}.ods_fmys_goods_ext_record_dt partition(dt)
- -- select
- -- goods_id
- -- , limit_day
- -- , auto_time
- -- , is_new
- -- , grade
- -- , season
- -- , goods_type
- -- , 0 as event
- -- , 0 as record_time
- -- , -987654321012345 as nano_time
- -- , ${one_day_ago}
- -- from ${yishou_data_dbname}.ods_fmys_goods_ext_dt
- -- where dt = ${one_day_ago}
- -- ;
- -- 创建记录表视图(该记录表昨天的分区 union all 今天以及之后的binlog的数据,准实时更新)
- drop view if exists ${yishou_data_dbname}.ods_fmys_goods_ext_record;
- create view if not exists ${yishou_data_dbname}.ods_fmys_goods_ext_record(
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , event
- , record_time
- , nano_time
- ) comment 'ods_fmys_goods_ext_record在ods层视图(根据业务库数据,分钟级别更新)'
- as
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , event
- , record_time
- , nano_time
- from (
- select
- goods_id
- , limit_day
- , auto_time
- , is_new
- , grade
- , season
- , goods_type
- , event
- , record_time
- , nano_time
- from ${yishou_data_dbname}.ods_fmys_goods_ext_record_dt
- where dt = ${one_day_ago}
- union all
- select
- get_json_object(columns ,'$.goods_id.value') as goods_id
- , get_json_object(columns ,'$.limit_day.value') as limit_day
- , get_json_object(columns ,'$.auto_time.value') as auto_time
- , get_json_object(columns ,'$.is_new.value') as is_new
- , get_json_object(columns ,'$.grade.value') as grade
- , get_json_object(columns ,'$.season.value') as season
- , get_json_object(columns ,'$.goods_type.value') as goods_type
- , event
- , create_time as record_time
- , nano_time as nano_time
- from ${yishou_data_dbname}.ods_binlog_data
- where
- dt >= ${today}
- and tb = 'fmys_goods_ext'
- )
- ;
注意:在调度之前需要执行初始化脚本(脚本在上述代码中),并且执行初始化脚本之前需要注意昨天的分区快照表数据是否有,一般为前置表上线第二天进行初始化,然后就可以启动作业调度,自动调度执行。并且跟ods层快照表一样,同样的生成了一个视图,用于分钟级更新数据。
6. 总结
在ODS层业务数据类型表中,业务库一张表对应数仓中4张表或者视图:
- ods层快照分区表:ods_xxx_dt,每天一个分区,用来存储全量快照;
- ods层快照视图:ods_xxx,一个视图,分钟级更新业务库的数据;
- ods层历史变更记录表:ods_xxx_record_dt,每天一个分区,用来存储业务表的历史变更记录,可以只保留近1个月的数据;
- ods层历史变更记录视图:ods_xxx_record,一个视图,分钟级更新业务库的变更记录;
注意:
- 上述示例是已一张业务表为例进行编写,其他的业务表同样操作即可,在ods中全部业务表没有其他区别,都是使用同样的策略。
- 在上述的2个作业调度中(快照表作业和历史变更记录表作业)都需要进行自依赖,即必须得前一天的作业正常运行完成,才能进行今天的作业;因为这2个作业都是需要依赖之前的分区,当之前分区因为运行失败没有数据或者数据错误时,不能跑新的作业;不过在代码中都有重跑措施,当运行失败时,直接点击重跑或者点击测试运行然后将作业置成功即可。
数据具体走向图:

注:其他 离线数仓 相关文章链接由此进 -> 离线数仓文章汇总
-
相关阅读:
计算机毕业设计ssm+vue基本微信小程序的执法助手平台
精工书院2022级-C语言编程机考模拟练习课堂
Spring5学习笔记之整合MyBatis
Redis中zSet类型的操作
python 把函数的值赋给变量
QT QDockWidget
JDK的安装与环境配置
ArcGIS导入xyz序列并绘制地形图(含等高线、面体积、点距离的计算)
红外相机和RGB相机标定:实现两种模态数据融合
人工智能统计学:GPT4、混合效应模型、贝叶斯、Copula、SEM、极值统计学、文献计量学、分位数回归、网络爬虫、近红外光谱
- 原文地址:https://blog.csdn.net/yang_shibiao/article/details/126628674
