-
vector底层实现及应用注意事项
前言
STL 众多容器中,vector 是最常用的容器之一,其底层所采用的数据结构非常简单,就只是一段连续的线性内存空间(泛型的动态类型顺序表)。
vector的实现原理
vector的数据安排及操作方式与array非常相似。两者的唯一差别在于空间运用的灵活性。
array是静态空间,一旦配置好了就不能改变了,如果程序需要一个更大的array,只能自己再申请一个更大的array,然后将以前的array中的内容全部拷贝到新的array中。
vector是动态空间,随着元素的加入,它的内部机制会自动扩充空间以容纳新的元素。vector的关键技术在于对大小的控制以及重新分配时的数据移动效率。
vector采用的数据结构是线性的连续空间(泛型的动态类型顺序表),他以两个迭代器start和finish分别指向配置得来的连续空间中目前已将被使用的空间。迭代器end_of_storage指向整个连续的尾部。
vector在增加元素时,如果超过自身最大的容量,vector则将自身的容量扩充为原来的两倍。扩充空间需要经过的步骤:重新配置空间,元素移动,释放旧的内存空间。一旦vector空间重新配置,则指向原来vector的所有迭代器都失效了,因为vector的地址改变了。
vector的使用
vector支持随机访问
vector底层是连续空间,并且vector重载了[]下标运算符,用户可以向使用数组的方式访问vector中的每一个元素,即支持随机访问,但vector不适宜做任意位置的插入和删除操作,因为要进行大量元素的搬移,比如插入:
reference operator[](size_type n) { return *(begin() + n); } const_reference operator[](size_type n) const { return *(begin() + n); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
vector不适合做任意位置插入以及删除操作
vector不适宜做任意位置插入与删除操作,因为插入和删除时需要搬移大量元素:
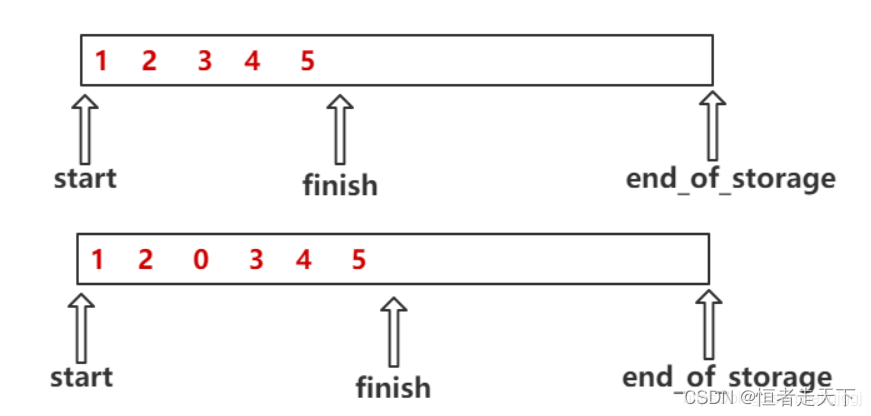 在元素3的位置插入0时,需要将3 4 5 整体向后搬移一个位置,才可以插入数据0,最差情况下时间复杂度为O(N);
在元素3的位置插入0时,需要将3 4 5 整体向后搬移一个位置,才可以插入数据0,最差情况下时间复杂度为O(N);template <class T, class Alloc> void vector<T, Alloc>::insert_aux(iterator position, const T& x) { // 检测是否需要扩容:如果finish和end_of_storage不在同一个位置,即还有空间 // 则不需要库容 if (finish != end_of_storage) { construct(finish, *(finish - 1)); ++finish; T x_copy = x; // 将position之后的元素整体向后搬移一个位置 copy_backward(position, finish - 2, finish - 1); *position = x_copy; } else { // finish与end_of_storage在同一个位置:需要进行扩容 const size_type old_size = size(); // 此处可以看到SGI-STL vector是按照2倍方式扩容的 const size_type len = old_size != 0 ? 2 * old_size : 1; // 开辟新空间 iterator new_start = data_allocator::allocate(len); iterator new_finish = new_start; __STL_TRY { // 将[start, position)区间中元素搬移到新空间,返回拷贝完成后新空间尾即原position相同位置 new_finish = uninitialized_copy(start, position, new_start); // 在原position位置构造新对象 construct(new_finish, x); ++new_finish; // 将原position位置元素搬移到新空间 new_finish = uninitialized_copy(position, finish, new_finish); } # ifdef __STL_USE_EXCEPTIONS catch(...) { destroy(new_start, new_finish); data_allocator::deallocate(new_start, len); throw; } # endif /* __STL_USE_EXCEPTIONS */ destroy(begin(), end()); deallocate(); start = new_start; finish = new_finish; end_of_storage = new_start + len; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
vector使用时注意事项
- 在不确定的情况下使用at而不是operator[]
实际上at函数就是调用的operator[]函数,只是多了一个检查是否越界的动作,而operator[]函数是直接跳转位置访问元素,所以速度是很快的,从时间复杂度看,是O(1)。
const_reference operator[](size_type __n) const _GLIBCXX_NOEXCEPT { __glibcxx_requires_subscript(__n); return *(this->_M_impl._M_start + __n); } const_reference at(size_type __n) const { _M_range_check(__n); return (*this)[__n]; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 什么类型不可以作为vector的模板类型
对于vector模板特化类型,因为在vector的实现过程中,变量会经常被拷贝或者赋值,所以vector的模板类型应该具有公有的拷贝构造函数和重载的赋值操作符函数。 - 什么情况下vector的迭代器会失效
第一是在vector容器中间根据指定迭代器删除元素,也就是调用erase函数,此时因为当前位置会被后面的元素覆盖,所以该指定迭代器会失效,不过此时可以通过erase的返回值重新得到当前位置的正确迭代器;
第二是在vector需重新申请内存的时候,比如扩容,比如释放未使用的内存等等这些过程中都会发生迭代器失效的问题,因为内存有了变动,此时就需要重新获得迭代器;
有人说往vector中间插入数据也会使迭代器失效,实际上根据源码是不会的,看上面的insert实现可以得知,再插入完成以后给当前迭代器重新赋值了的。 - vector怎么迅速的释放内存
有人说是不是可以调用reserve(0)来进行释放,毕竟reserve函数会根据我们指定的大小重新申请的内存,那是行不通的哈,这个函数只有在传入大小比原有内存大时才会有动作,否则不进行任何动作。
至于通过resize或者clear等都是行不通的,这些函数都只会对当前已保存在容器中的所有元素进行析构,但对容器本身所在的内存空间是不会进行释放的。
4.1 通过swap函数
这时我们可以想想,什么情况下vector大小为0呢,就是作为一个空容器的时候,所以要想快速的释放内存,我们可以参考swap函数机制,用一个空的vector与当前vector进行交换,使用形如vector().swap(v)这样的代码,将v这个vector变量所代表的内存空间与一个空vector进行交换,这样v的内存空间等于被释放掉了,而这个空vector因为是一个临时变量,它在这行代码结束以后,会自动调用vector的析构函数释放动态内存空间,这样,一个vector的动态内存就被迅速的释放掉了。
4.2使用shrink_to_fit函数
在c++11以后增加了这个函数,它的作用是释放掉未使用的内存,假设我们先调用clear函数把所有元素清掉,这样是不是整块容器都变成未使用了,然后再调用shrink_to_fit函数把未使用的部分内存释放掉,那不就把这个vector内存释放掉了吗。
vector扩容
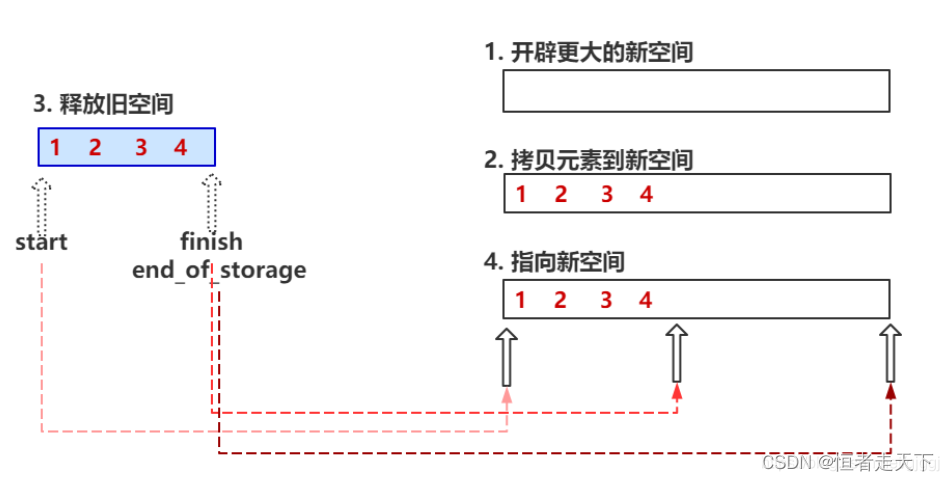
vector扩大容量的本质:当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容。vector 容器扩容的过程需要经历以下 4 步:
1.完全弃用现有的内存空间,重新申请更大的内存空间;
2.将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
3.将旧的内存空间释放。
4.使用新开辟的空间
下面从源码下,看下vector的扩容机制:// SGI-STL扩容机制 void reserve(size_type n) { // 当n大于当前vector的容量时才会扩容,小于等于当前容量则忽略本次操作 if (capacity() < n) { const size_type old_size = size(); // 使用空间配置器开辟n个新空间,并将旧空间元素拷贝到新空间 iterator tmp = allocate_and_copy(n, start, finish); // 释放旧空间 // a. 先调用析构函数,将[start, finish)区间总所有的对象析构完整 destroy(start, finish); // b. 将空间规划给空间配置器 deallocate(); // 3. 接收新空间并更新其成员 start = tmp; finish = tmp + old_size; end_of_storage = start + n; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
注意:扩容的实际为,在插入时,当finish与start在同一个位置,或者调用reserve操作,或者resize操作等都可能引起扩容。
由上扩容机制也就解释了,为什么 vector 容器在进行扩容后,与其相关的指针、引用以及迭代器可能会失效的原因。并且vector 扩容是非常耗时的。为了降低再次分配内存空间时的成本,每次扩容时 vector 都会申请比用户需求量更多的内存空间(这也就是 vector 容量的由来,即 capacity>=size),以便后期使用。
根据以上,其实如果我们能确定vector必定会被使用且有数据时,我们应该在声明的时候指定元素个数,避免最开始的时候多次申请动态内存消耗资源,进而影响性能。
由上我们知道了,vector扩容的本质,但是vector扩容的倍数是怎么选择的啊,以及内存是如何释放的需要我们思考。
vector扩容的倍数选择
要解释为什么要两倍扩容(gcc)我们可以分两步理解?
- 为什么选择成倍扩容,而不是成等差扩容?
(1)我们假设我们使用m扩容,一共有n个元素,那么我们需要扩展多少次才能装下这n个元素,通过计算我们可以得到: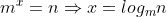
那么我们需要拷贝多少个元素呢?
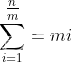
这个式子可以看出来总的时间复杂度为n,当平均分摊到每个元素上,时间复杂度为常数。
(2)我们假设使用每次增加一个固定的常数m来扩容,总的元素个数是n,那么我们需要扩展多少次才能装下这n个元素,通过计算我们可以得到:
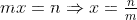
那么我们需要拷贝多少个元素呢?
这个式子可以看出总的时间复杂度为n^{2},当平均分摊到每个元素上,时间复杂度为n。
综上所述,我们可以知道我们应该选择的是成倍扩容,而不是成一个固定数扩容。
- 为什么我们要选择2倍扩容(gcc)或者1.5倍扩容?
首先我们可以明确的是,我们的扩容倍数一定是大于1的,因为装不下才需要扩容。
那么它的上限是多少呢?
我们通过排列的知识可以知道,当扩容 的倍数为2的时候,那么这个扩容容量总是大于之前所有的扩容总和:
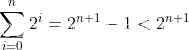
这样的话,之前扩容的空间不能使用,这样对缓存并不友好。因此选定的倍数应该是1到2
中间,选择1.5的原因应该是:不至于太浪费内存空间,同时也不需要太多次的赋值数组内容。
如何释放内存
vector的内存空间只增不减,vector内存的回收只能靠vector调用析构函数的时候才被系统收回,当然也可以使用swap来帮你释放内存,具体方法:
vec.swap(vec);其他常用接口与底层结构关系
为了能使算法操作容器中的元素,每个容器都提供了begin()和end()的迭代器,[begin, end)区间中包含了容器中的所有元素,vector也是如此。
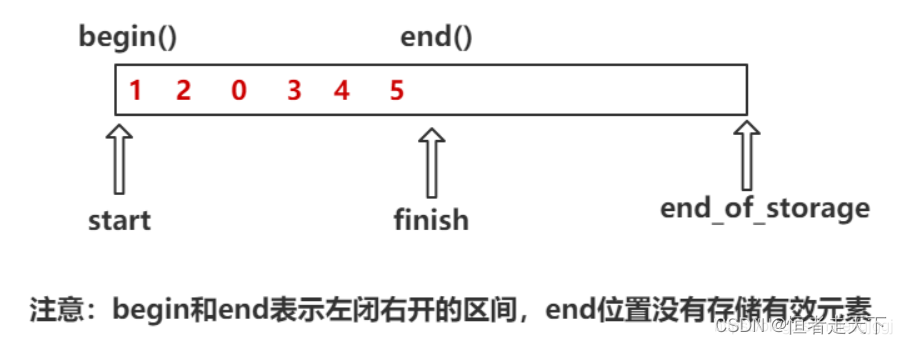
iterator begin() { return start; } iterator end() { return finish; }- 1
- 2
size()和capacity()分别表示vector中的元素个数以及底层的空间大小。
size_type size() const { return size_type(end() - begin()); // finish - start } size_type capacity() const { return size_type(end_of_storage - begin()); // end_of_storage - start }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
学习了上面vector的原理,但是在实际工程中,用vector存储数据时,切忌,vector不是存储bool类型元素的vector容器!
不推荐使用 vector 的原因有以下 2 个:
1.严格意义上讲,vector 并不是一个 STL 容器;
2.vector 底层存储的并不是 bool 类型值。vector不是容器
对于是否为 STL 容器,C++ 标准库中有明确的判断条件,其中一个条件是:如果 cont 是包含对象 T 的 STL 容器,且该容器中重载了 [ ] 运算符(即支持 operator[]),则以下代码必须能够被编译:
T *p = &cont[0];- 1
此行代码的含义是,借助 operator[ ] 获取一个 cont 容器中存储的 T 对象,同时将这个对象的地址赋予给一个 T 类型的指针。
这就意味着,如果 vector 是一个 STL 容器,则下面这段代码是可以通过编译的:
//创建一个 vector容器 vector<bool>cont{0,1}; //试图将指针 p 指向 cont 容器中第一个元素 bool *p = &cont[0];- 1
- 2
- 3
- 4
但此段代码不能通过编译。原因在于 vector 底层采用了独特的存储机制。
实际上,为了节省空间,vector 底层在存储各个 bool 类型值时,每个 bool 值都只使用一个比特位(二进制位)来存储。 也就是说在 vector 底层,一个字节可以存储 8 个 bool 类型值。在这种存储机制的影响下,operator[ ] 势必就需要返回一个指向单个比特位的引用,但显然这样的引用是不存在的。同样对于指针来说,其指向的最小单位是字节,无法另其指向单个比特位。综上所述可以得出一个结论,即上面第 2 行代码中,用 = 赋值号连接 bool *p 和 &cont[0] 是矛盾的。
如何避免使用vector
那么,如果在实际场景中需要使用 vector 这样的存储结构,该怎么办呢?很简单,可以选择使用 deque 或者 bitset 来替代 vector
deque 容器几乎具有 vecotr 容器全部的功能(拥有的成员方法也仅差 reserve() 和 capacity()),而且更重要的是,deque 容器可以正常存储 bool 类型元素。
还可以考虑用 bitset 代替 vector,其本质是一个模板类,可以看做是一种类似数组的存储结构。和后者一样,bitset 只能用来存储 bool 类型值,且底层存储机制也采用的是用一个比特位来存储一个 bool 值。
和 vector 容器不同的是,bitset 的大小在一开始就确定了,因此不支持插入和删除元素;另外 bitset 不是容器,所以不支持使用迭代器。
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,
分享给大家:[Linux,Nginx,ZeroMQ,MySQL,Redis,
fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,
TCP/IP,协程,DPDK等技术内容,点击立即学习:服务器课程 -
相关阅读:
Gin 笔记(06)— 设置不同启动模式、优雅启动和关闭、运行多个不同端口的服务进程
面试题 02.07. 链表相交-双指针法
React报错之No duplicate props allowed
matplotlib设置y轴刻度范围【已解决】
Vue2.js使用 Axios
Linux卷组管理
c++模板
AIGC , 超级热点 or 程序员创富新起点?
前端开发攻略---合并表格单元格,表格内嵌套表格实现手风琴效果。
Iris for mac 好用的录屏软件
- 原文地址:https://blog.csdn.net/weixin_52259848/article/details/126634343
