-
面试官:你说你用过Dubbo,那你说说看Dubbo的SPI
啥是SPI
SPI,全称为 Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API,它可以用于很多框架的扩展,常见的如Java JDBC、Spring、SpringBoot、Dubbo等
Java SPI
Java SPI由Java核心库提供,它定义了一个接口,具体的实现由第三方来实现。以Java JDBC Driver为例,常用的关系型数据有Mysql、Oracle、SQLServer、DB2等,这些不同类型的数据库使用的驱动程序各不相同,那JDK不可能把所有厂商的驱动都实现,只能制定一个标准接口,各个数据库厂商根据标准来实现自己的驱动,这就是SPI机制
写个例子
Java SPI实现起来比较简单,都是约定俗成的事,按他的标准来就行,在实现Java SPI需要满足以下条件
- 写一个接口,并且提供对应的具体的实现
- 在META-INF/service/目录下新建一个以接口的全限定名命名的文件,如jdbc.sql.Driver
- 使用ServiceLoader.load()方法进行加载
下面开始撸代码
1、定义一个接口

2、实现接口
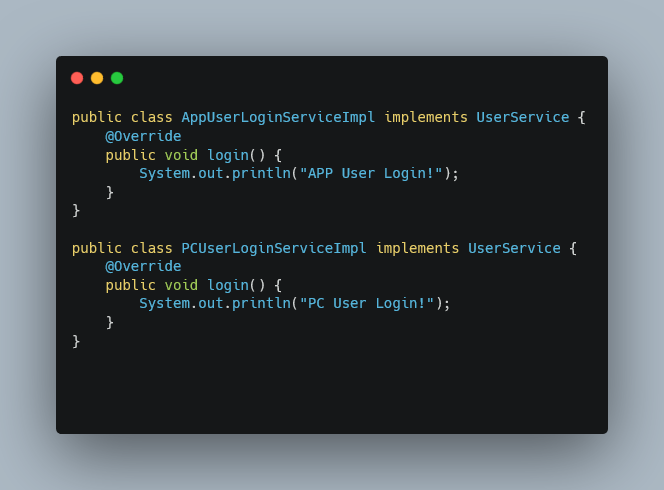
3、加配置
在META-INF/service/目录下新建文件org.kxg.spi.UserService,内容如下:
org.kxg.spi.PCUserLoginServiceImpl org.kxg.spi.AppUserLoginServiceImpl- 1
- 2
4、使用ServiceLoader加载
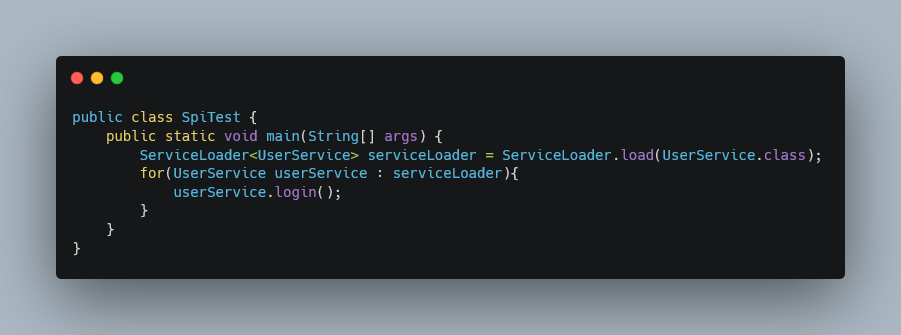
运行代码,结果如下:
PC User Login! APP User Login!- 1
- 2
可以看到Java SPI实现起来还是挺简单的,下面看看Java SPI具体是如何工作的
Java SPI工作原理
1、从ServiceLoader入手
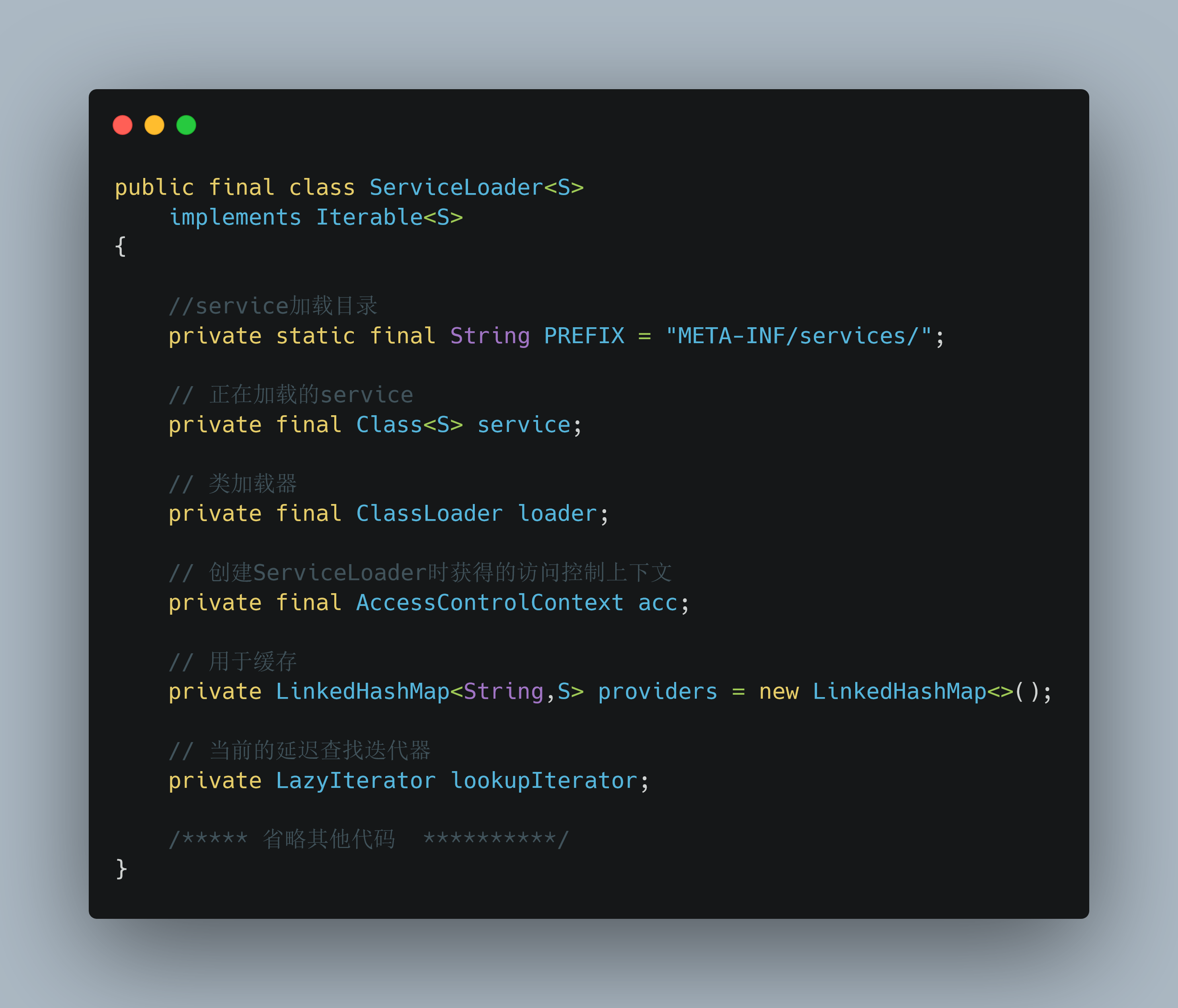
主要是load()方法进行类的加载
代码也挺简单的,最终创建了一个LazyIterator对象,可能看到这里还是没有明白到底ServiceLoader是如何进行加载的,别急我们继续看
从上面的代码我们可以看到ServiceLoader是实现了Iterable接口的,这也是ServiceLoader可以被循环迭代的原因
public final class ServiceLoaderimplements Iterable- 1
实现Iterable接口的类在循环迭代时会调用iterator()方法,也就是说ServiceLoader在循环迭代的时候会调用自身的iterator()方法,下面看一下代码

可以看到iterator()方法中的主要两个方法hasNext()和next()调用的是lookupIterator的hasNext()和next()方法,这样就跟前面的对上了,前面我们创建了一个LazyIterator对象
下面看一下lookupIterator的hasNext()和next()方法
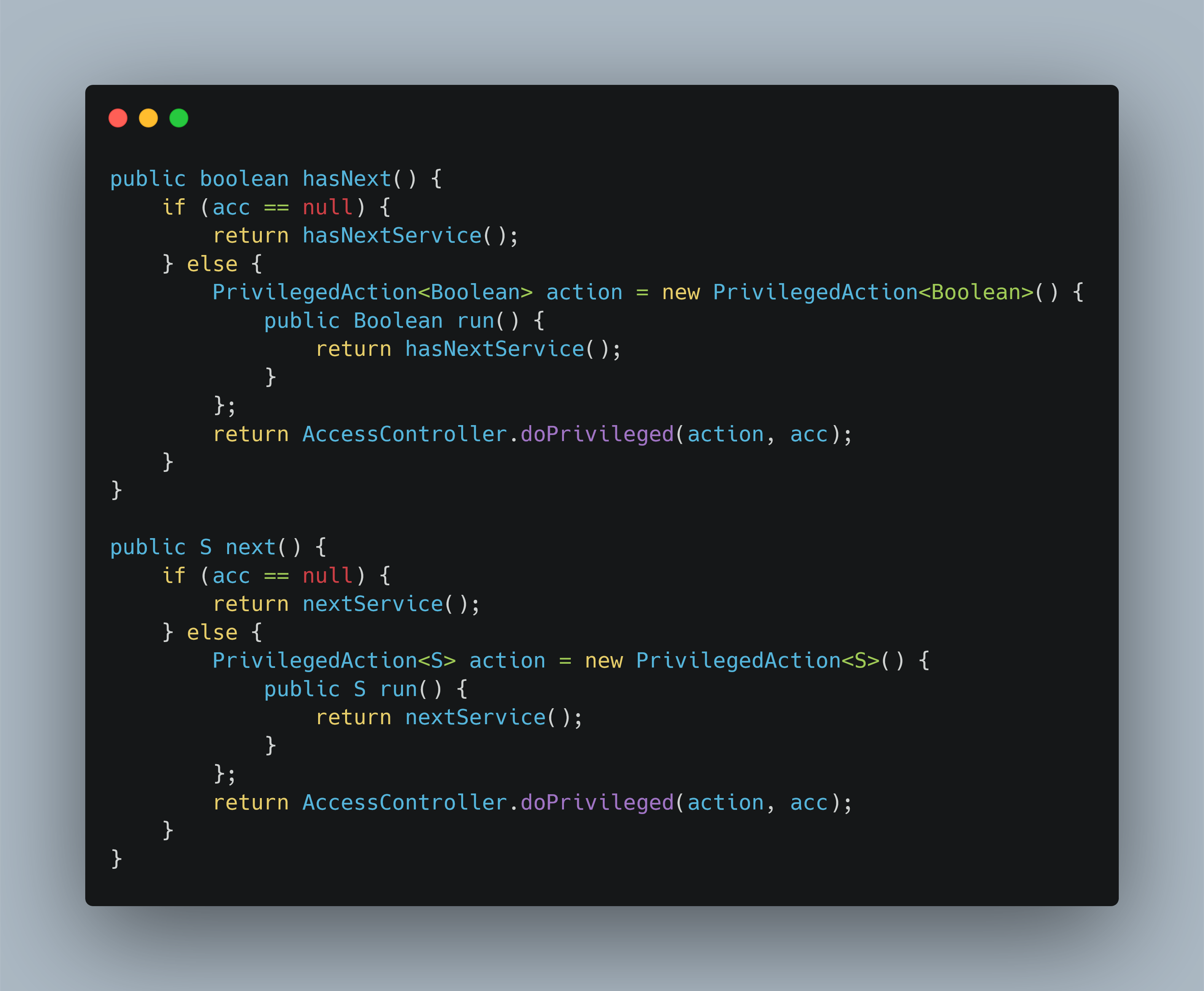
这里可以看到主要是hasNextService()、nextService()这两个方法

代码跟到这里,逻辑基本上已经清楚了,hasNextService()主要完成目录下文件内容的加载,nextService()方法主要作用是用于类的实例化
Dubbo SPI
既然Java已经提供了SPI,为啥Dubbo还要自己实现一套SPI,难道是为了炫技?No,阿里的大神们没这么无聊,从上面的例子可以看出来,Java SPI有个缺点:扫描META-INF/service/目录,加载目录下所有的service,不管你有没有使用到,假如遇到一个加载时间很长的service,会影响整体的加载效率,而加载了可能又不使用,纯粹是浪费资源
Dubbo在Java SPI的基础上对其进行加强,使用Key-Value的形式来标识各个Service,并且增加了对扩展点的IOC和AOP支持
首先我们来看一下dubbo SPI的配置
以Protocol为例
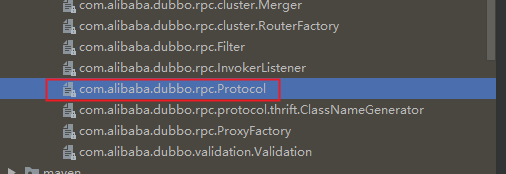
可以看到dubbo同样以全限定名来命名文件,跟Java SPI保持一致,文件内容与Java SPI不一致,它是以Key=Value的形式来配置的,每个实现都指定了一个名称
registry=com.alibaba.dubbo.registry.integration.RegistryProtocol dubbo=com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol filter=com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper listener=com.alibaba.dubbo.rpc.protocol.ProtocolListenerWrapper mock=com.alibaba.dubbo.rpc.support.MockProtocol injvm=com.alibaba.dubbo.rpc.protocol.injvm.InjvmProtocol rmi=com.alibaba.dubbo.rpc.protocol.rmi.RmiProtocol hessian=com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol com.alibaba.dubbo.rpc.protocol.http.HttpProtocol com.alibaba.dubbo.rpc.protocol.webservice.WebServiceProtocol thrift=com.alibaba.dubbo.rpc.protocol.thrift.ThriftProtocol memcached=com.alibaba.dubbo.rpc.protocol.memcached.MemcachedProtocol redis=com.alibaba.dubbo.rpc.protocol.redis.RedisProtocol rest=com.alibaba.dubbo.rpc.protocol.rest.RestProtocol- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
下面我们通过一个例子来自定义实现一个Protocol

在META-INF/dubbo/目录下新增com.alibaba.dubbo.rpc.Protocol文件,内容为:
myProtocol=org.kxg.dubbo.MyProtocol ## 此路径为MyProtocol的包名+类名- 1
写个main方法测试一下
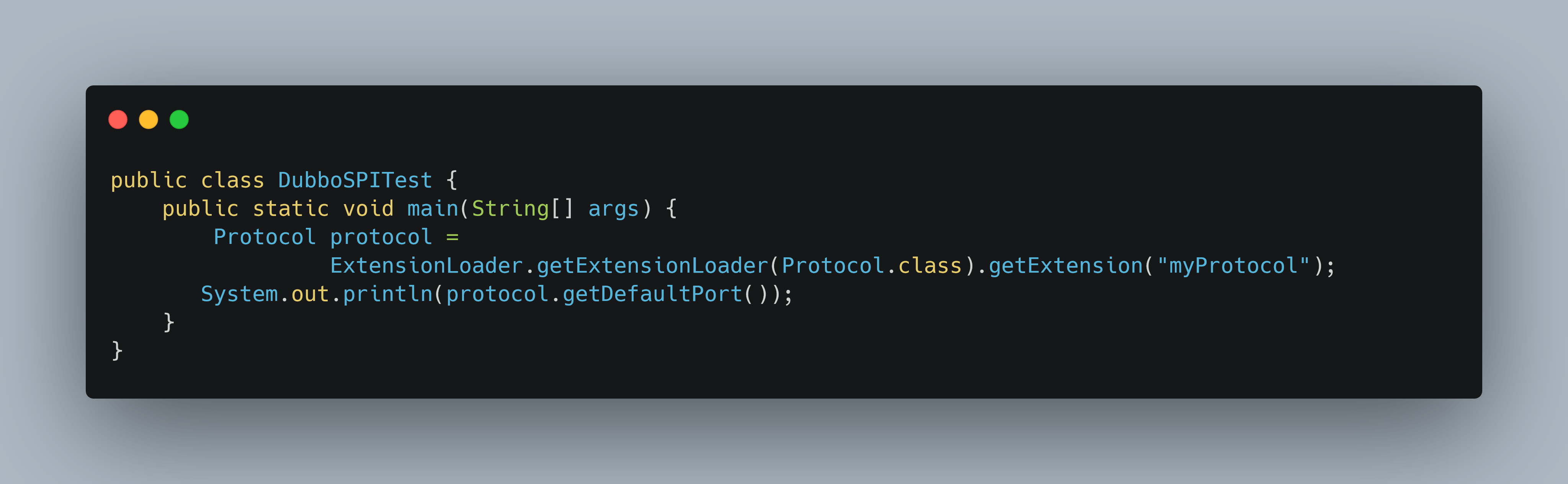
输出结果
9999- 1
可以看到Dubbo的SPI其实也挺简单的,下面我们从源码的角度看看Dubbo的SPI是如何实现的
Dubbo SPI源码分析
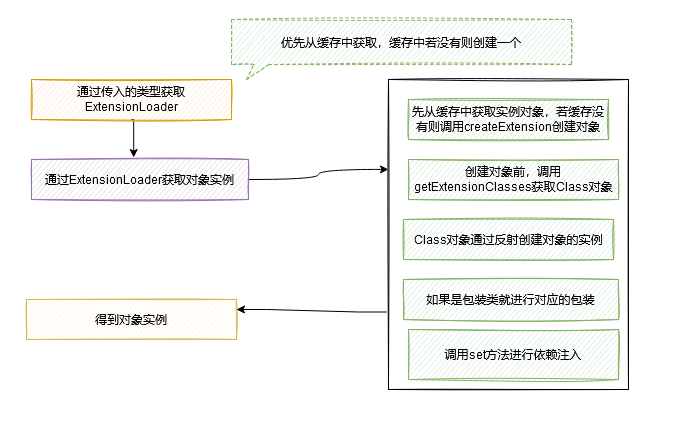
从上面的例子可以看出来,Dubbo主要是通过ExtensionLoader来进行加载的,具体是通过getExtensionLoader方法获取ExtensionLoader,再通过ExtensionLoader调用getExtension来获取具体的对象的,下面我们一步步来看

下面来看一下getExtension方法

以上整个SPI的大致流程,还是挺清晰的,简单画个图描述一下
getExtensionClasses
在上面获取对应的class时,有一个重要的方法getExtensionClasses,它主要是在固定的几个目录下去加载配置文件,读取相应的扩展类
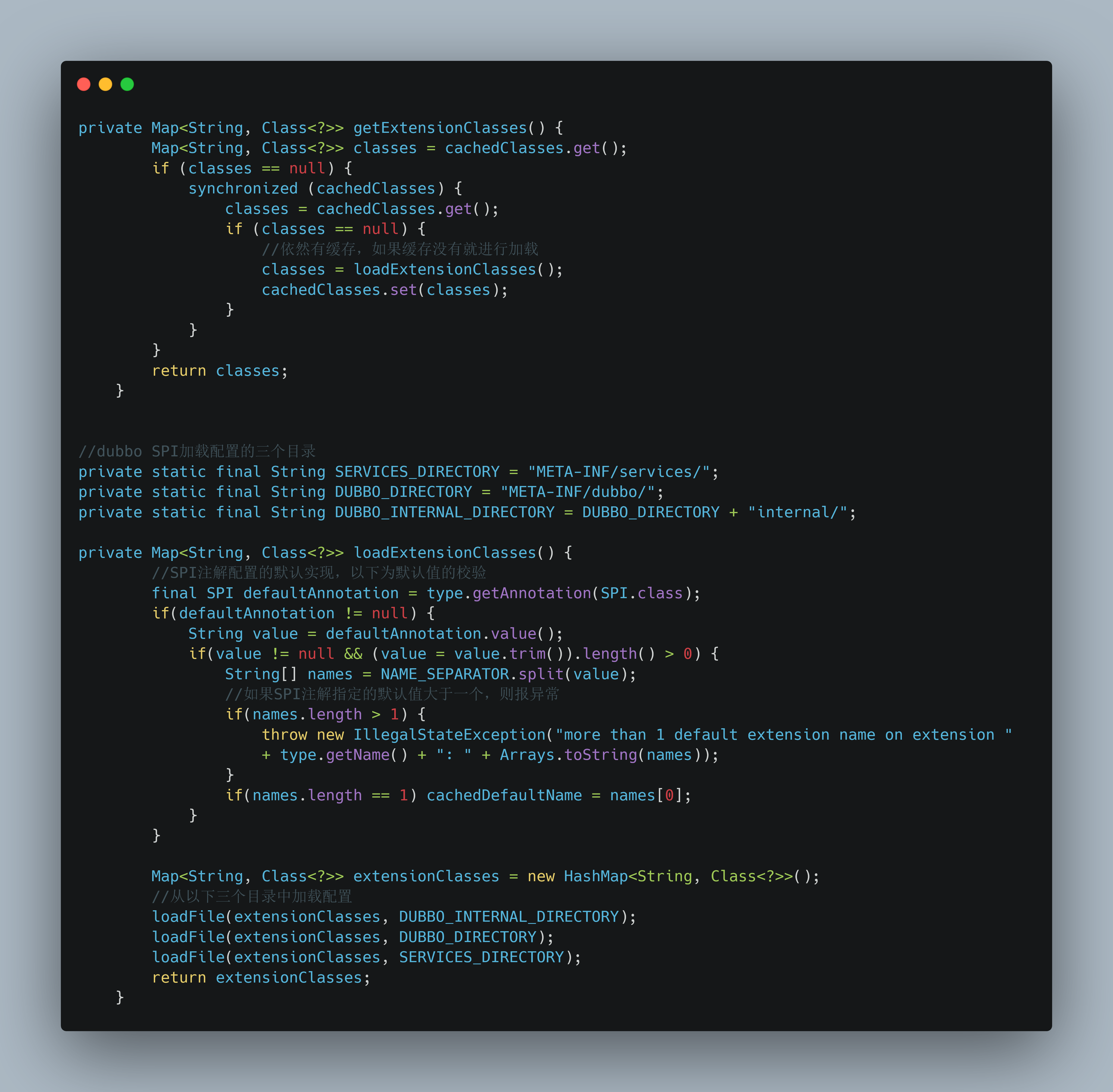
loadFile的代码还是挺简单的,从指定的目录中读取配置,因为配置是键值对的形式,所以中间会有对应的处理,有兴趣可以自己读一下源码
Adaptive自适应扩展点
到底啥是Dubbo的自适应扩展点呢?就是我们会根据配置进行加载扩展点,但有时候我们不希望它自动加载,我们希望通过自己传入的参数来进行动态的加载,这就是Dubbo的自适应扩展点,下面我们看一个例子
运行结果:
class com.alibaba.dubbo.common.compiler.support.AdaptiveCompiler- 1
我们查看AdaptiveCompiler类的源码,可以看到它上面标记了@Adaptive注解,这就是Dubbo的自适应扩展点注解
@Adaptive注解
@Adaptive注解可以标注在类和方法上,两者的区别是:标注在类上说明这个类是自适应扩展点的类,标注在方法上需要动态生成字节码,然后动态生成类
@Adaptive注解在类上
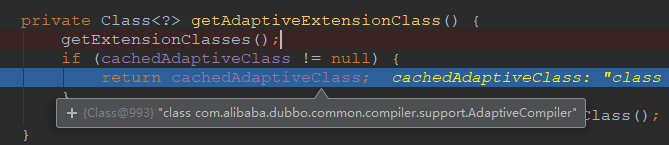
还是上面的Complie例子,我们跟一下源码

我们Debug一下,可以看到Complier对应的自适应扩展类是AdaptiveCompiler
@Adaptive注解在方法上
我们以Protocol为例:

我们看到Protocol接口有两个方法标注了@Adaptive注解,另外两个方法没有标注,我们上面说过@Adaptive标记在方法上时会动态生成字节码,下面来看一下源码,我们就从getAdaptiveExtensionClass()方法开始跟

Debug跟一下,看看动态生成的类文件长什么样

格式化一下

从图中标记的位置可以看出来,动态生成的类名称为Protocol$Adpative,被@Adpative标记的方法,传入url参数,根据传入不同的url参数来自定义扩展点,这就是自适应机制
@Activate注解
@Activate注解有点类似Spring的条件注解,根据条件进行扩展点的激活,在这里@Activate注解表示扩展类被加载到的条件,有两个重要的属性
- group 根据group过滤,包含则返回扩展
- value key过滤条件,URL参数中的key包含此value值则返回扩展
详细的源码,可以去读一下getActivateExtension()方法
总结一下
- SPI,全称为 Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API
- Java SPI由Java核心库提供,它定义了一个接口,具体的实现由第三方来实现
- Java SPI实现起来比较简单,都是约定俗成的事,按他的标准来就行,在实现Java SPI需要满足以下条件
- 写一个接口,并且提供对应的具体的实现
- 在META-INF/service/目录下新建一个以接口的全限定名命名的文件,如jdbc.sql.Driver
- 使用ServiceLoader.load()方法进行加载
- Java SPI工作原理主要是通过ServiceLoader来加载指定目录下的类实现
- Java SPI的缺点:扫描META-INF/service/目录,加载目录下所有的service,不管你有没有使用到
- Dubbo SPI 在Java SPI的基础上对其进行加强,使用Key-Value的形式来标识各个Service,并且增加了对扩展点的IOC和AOP支持
- Dubbo主要是通过ExtensionLoader来进行进行扩展点的加载
- Dubbo的自适应扩展点就是我们通过自己传入的参数来进行动态的加载扩展点
- @Adaptive注解可以标注在类和方法上,两者的区别是:标注在类上说明这个类是自适应扩展点的类,标注在方法上需要动态生成字节码,然后动态生成类
- @Activate注解有点类似Spring的条件注解,根据条件进行扩展点的激活

-
相关阅读:
22/6/27
手写生产者消费者模型
2024年经典【自动化面试题】附答案
在Unity中挂载C#脚本的三种方法
【数据结构】二叉搜索树
Unsatisfied dependency expressed through bean property ‘sqlSessionTemplate‘;
基本正则表达式
如何使用 JavaScript 读取文件
计算机毕业设计Hadoop+Hive地震预测系统 地震数据分析可视化 地震爬虫 大数据毕业设计 Spark 机器学习 深度学习 Flink 大数据
关于SqlSugar的多对多的级联插入的问题(无法获取集合属性的id,导致无法维护中间表)
- 原文地址:https://blog.csdn.net/m0_67266585/article/details/126619995