-
通过Docker安装ElasticSearch和Kibana
1、安装ElasticSearch(单节点)
1.1、创建docker网络
因为安装完ElasticSearch后还安装Kibana,为了让ElasticSearch和Kibana互联,因此我们得先创建一个docker网络
docker network create es-net- 1

1.2、加载镜像并运行
因为这里使用ElasticSearch的7.12.1版本的镜像,这个镜像特别大,接近1G,因此不建议直接pull,拉取得很慢。直接通过(load)加载jar包的形式拿到镜像,Kibana也采用同样的方式
下载tar包
连接https://pan.baidu.com/s/1ENeH5nh2-1RStpWs5yihaQ
提取码:1024通过文件传输工具上传到虚拟机中
然后使用命令加载tar包拿到镜像# 导入数据 docker load -i es.tar- 1
- 2
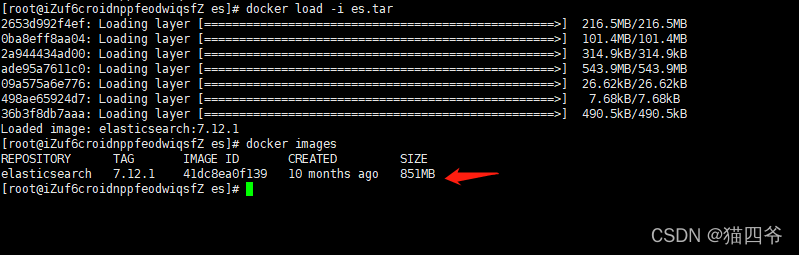
可以看到,已拿到ElasticSearch的镜像然后执行运行命令
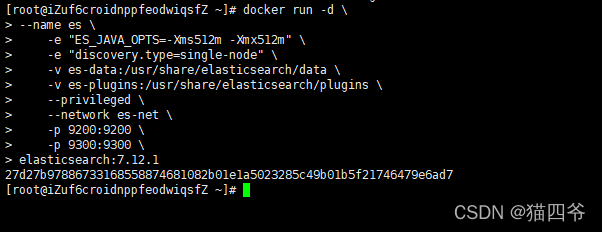
docker run -d --name es -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -e "discovery.type=single-node" -v es-data:/usr/share/elasticsearch/data -v es-plugins:/usr/share/elasticsearch/plugins --privileged --network es-net -p 9200:9200 -p 9300:9300- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
1.3测试
在浏览器中输入连接http://xxx.xxx.xxx.xxxx:9200
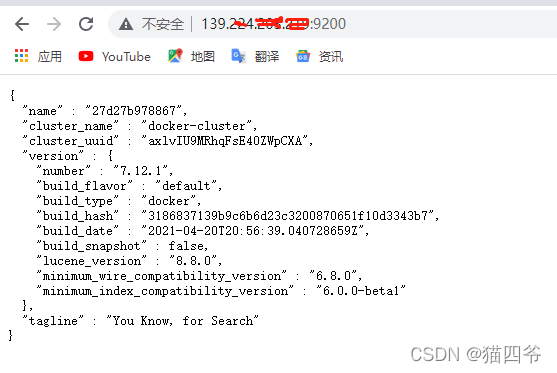
看到以上结果,说明安装成功2、安装Kibana
2.1、加载镜像并运行
和ElasticSearch的步骤一样,我们先拿到Kibana的tar包,然后上传到虚拟机,进行(load)加载后得到镜像
链接:https://pan.baidu.com/s/1RaOTNNdVLSYkMwi_yvTu6g
提取码:1024docker load -i kibana.tar- 1
拿到镜像
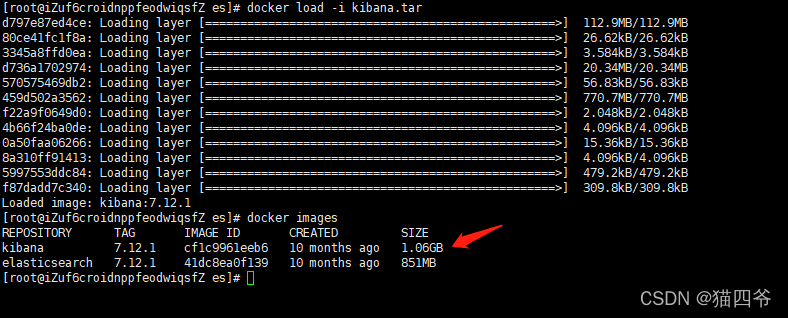
然后执行命令
docker run -d- 1
–name kibana
-e ELASTICSEARCH_HOSTS=http://es:9200
–network=es-net
-p 5601:5601
kibana:7.12.1--network es-net:加入到刚刚创建的名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
kibana启动比较慢,可以通过docker logs -f 容器ID 查看kibana的日志是否启动完成
docker logs -f kibana- 1
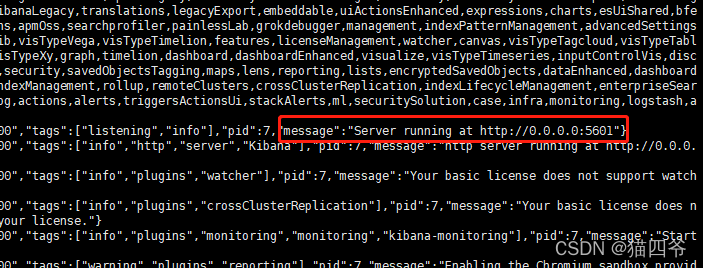
如果显示以上结果说明启动成功,浏览器输入http://xxx.xxx.xxx.xxx:5601
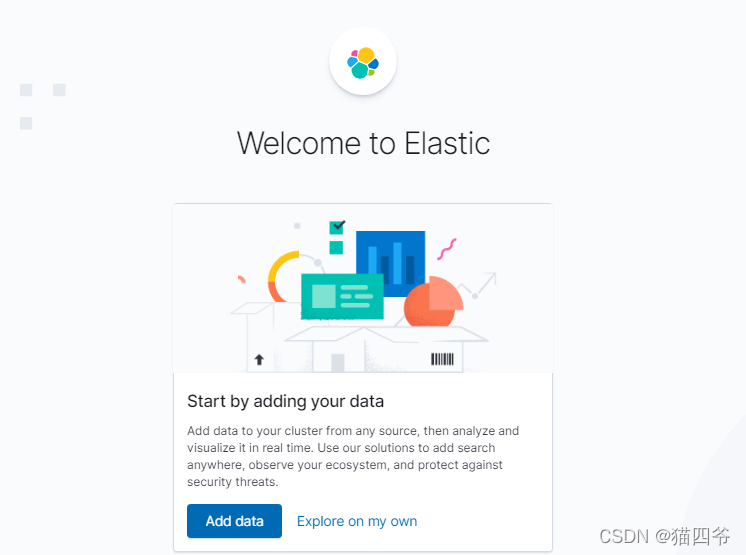
拓展可以看到页面默认是英文的,如果想要汉化也是可以配置的。
执行命令,将kibana.yml文件从容器拷贝到当前文件夹下
docker cp kibana:/usr/share/kibana/config/kibana.yml .- 1

编辑kibana.yml,在文件最后加上下面配置i18n.locale: “zh-CN”
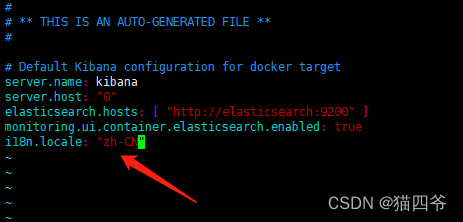
保存退出后执行命令将配置文件拷贝进容器docker cp kibana.yml kibana:/usr/share/kibana/config/kibana.yml- 1
重启Kibana容器
docker restart kibana- 1
重新输入网址访问Kibana
会发现,已经汉化成功!!!3、 安装IK分词器插件
因为ElasticSearch默认(lucene)是不支持中文分词的,比如"努力学习"会被分为"努"、“力”、“学”、“习” 。为了避免这种情况,所以我们需要安装能对中文进行分词的IK分词器插件
IK分词器包含两种模式:-
ik_smart:最少切分 -
ik_max_word:最细切分
3.1、在线安装(很慢,不推荐)
首先进入容器内部
docker exec -it elasticsearch /bin/bash- 1
在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip- 1
退出容器
exit 或 Ctrl+p+q- 1
重启ElasticSearch容器
docker restart elasticsearch- 1
到此,IK分词器插件安装完毕。
3.2、离线安装(很快)
(1) 、解压缩分词器的压缩包
首先下载IK分词器的压缩包
链接:https://pan.baidu.com/s/17ZGMDOkL_Z3TqsoPEM2n3Q
提取码:1024下载到桌面后进行解压,并且重命名为IK
(2)、拿到ElasticSearch数据卷目录
在执行ElasticSearch镜像时我们通过具名挂载 - v将ElasticSearch的插件目录进行了挂载
先执行
docker ps- 1
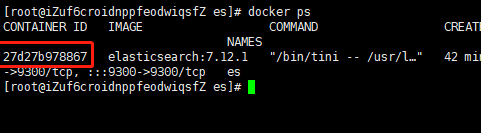
即可拿到ElasticSearch的容器ID,然后执行
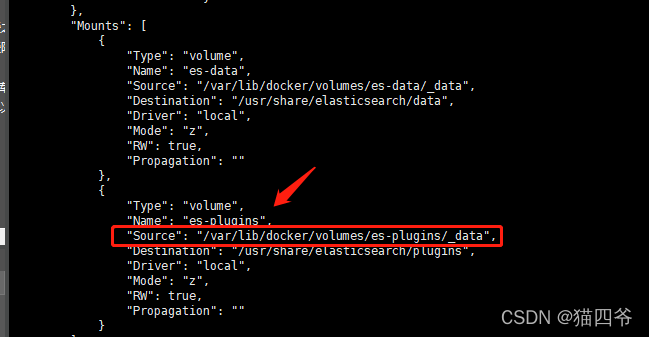
docker inspect 容器ID- 1
即可看到数据卷挂载的目录
(3)、将Ik文件夹上传至ElasticSearch插件的数据卷目录中
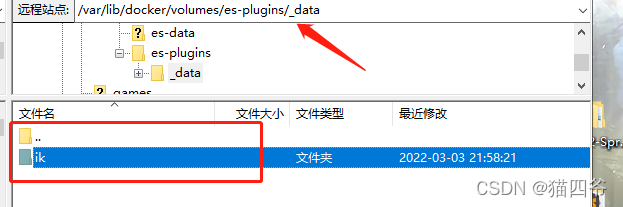
上传完之后重启ElasticSearch容器即可docker restart es- 1
到这里,IK分词器插件就安装完毕啦!
(4)、扩展词词典配置和停用词典配置
随着现在互联网的发展,会出现很多新颖的词汇比如:“蜀黍”、“表酱紫” 这样的词汇 ,那么像这种词汇,搜索时需要作为一个整体,那我们就需要手动进行配置了。但是还有一些词语是不能在网上传播的,比如政治敏感的词语,我们希望能在搜索时忽略掉,IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)打开ik文件夹下的config
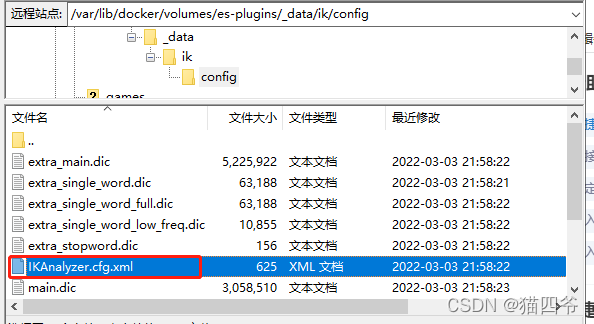
2)在该文件中配置添加IK Analyzer 扩展配置 ext.dic stopword.dic - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3)创建ext.dic文件和stopword.dic文件
ext.dic:

stopword.dic:

然后移动到confiig目录下
4)重启ElasticSearch容器
docker restart es- 1
即配置成功啦!!!
- 测试
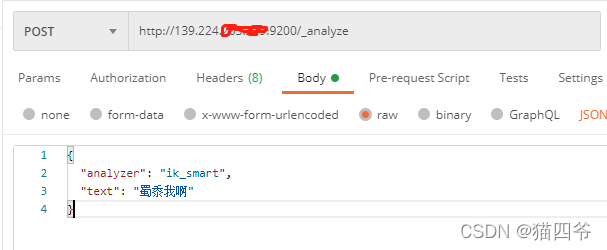
响应
{
“tokens”: [
{
“token”: “蜀黍”,
“start_offset”: 0,
“end_offset”: 2,
“type”: “CN_WORD”,
“position”: 0
},
{
“token”: “我”,
“start_offset”: 2,
“end_offset”: 3,
“type”: “CN_CHAR”,
“position”: 1
},
{
“token”: “啊”,
“start_offset”: 3,
“end_offset”: 4,
“type”: “CN_CHAR”,
“position”: 2
}
]
}会发现 蜀黍会被分词成一个整体,到这里,就全部配置成功啦!!!
后记
愿今后的你,能感谢现在拼命努力的自己。
-
相关阅读:
c++的发展史以及如何学习
Crack:Stimulsoft BI Server 2022.4.5
《java开发高频面经总结大合集》你想要的都在这里了
第十三更---大家都在那里查找资料??
机器学习模型的“可解释性”
Docker启动失败:Failed at step LIMITS spawning /sbin/modprobe
【图像去噪】基于边缘增强扩散 (cEED) 和 Coherence Enhancing Diffusion (cCED) 滤波器实现图像去噪附matlab代码
Eigen中三维位姿表示方式以及相互转换
基于PHP+MySQL的茶叶销售购物网店
SAP PS 第八节 PS 常见问题处理-来源于SAP EPPM分享
- 原文地址:https://blog.csdn.net/m0_67391683/article/details/126618272