-
Connor学JVM - 执行引擎

Learn && Live
虚度年华浮萍于世,勤学善思至死不渝
前言
Hey,欢迎阅读Connor学JVM系列,这个系列记录了我的JVM基础知识学习、复盘过程,欢迎各位大佬阅读斧正!原创不易,转载请注明出处:http://t.csdn.cn/TMIXT,话不多说我们马上开始!
(1)执行引擎在执行字节码的时候,通常会采用解释执行或编译执行,也可能两者结合,或同时包含多个不同级别即时编译器一起工作
(2)执行引擎的输入、输出都是一致的:输入字节码二进制流,处理过程是字节码解执行的等效过程,最后输出执行的结果
1.栈帧

(1)栈帧与方法相对应,一个方法对应栈中的一个栈桢(2)在活动线程中,只有位于栈顶的方法才是在运行的(当前方法),只有栈顶的栈帧才是生效的(当前栈帧),
(3)栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息
(4)栈帧需要多大的局部变量表、需要多深的操作数栈可以由Class文件中Code属性的max_locals和max_stack数据项指定,也就是说一个栈桢需要分配多少内存,并不会受到程序运行期变量数据的影响,而仅仅取决于程序源码和具体的JVM实现的栈内存布局形式
1.1 局部变量表
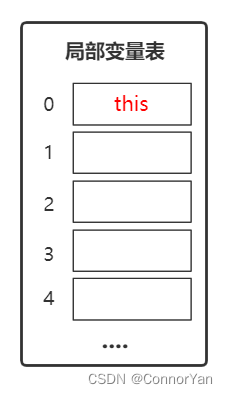
(1)局部变量表的容量以变量槽为最小单位(2)一个变量槽存放一个32位(4B)以内的数据类型,共8种类型,其中6种为基本数据类型,其余两种较特殊:
-
reference类型,表示一个对象的引用,没有明确的长度、结构要求,虚拟机可以利用引用完成以下两件事
- 根据引用直接或间接地查找到对象在堆中的起始地址或索引
- 根据引用直接或间接地查找到对象所属数据类型在方法区中的存储的类型信息
-
returnAddress类型,为字节码指令jsr、jsr_w、ret服务,用于老版本JVM的异常处理跳转,现已改为使用异常表
(3)两个连续的变量槽存放一个64位的类型,因为局部变量表属于线程私有数据,不会引起读写连续区域的数据竞争和线程安全问题
(4)JVM通过索引定位使用局部变量表
- 索引0为this,默认用于传递方法所属对象实例的引用
- 访问32位数据类型变量,索引N代表使用第N个变量槽
- 访问64位数据类型变量,代表使用的是索引N和N+1的变量槽
(5)变量槽是可以复用的,如果当前PC的值已经超出了某个变量的作用域,则这个变量使用的变量槽就可以交给其他变量来重用。注意这样的行为虽可以节省栈帧空间,但会直接影响到系统的GC
public static void main(String[] args) { { byte[] placeholder = new byte[64 * 1024 * 1024]; } // placeholder = null // int a = 0 System.gc(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(1)代码在完成数组的创建,虽然已经离开了placeholder的作用域,但在此之后并没有对局部变量表有任何的读写操作,placeholder仍占用着变量槽,不会进行回收
(2)如果在之后做如注释的操作,可以手动清空其占用的变量槽或者复用其占用的变量槽,使其失去关联关系,此时才会回收这个引用
1.2 操作数栈
(1)32位类型数据所占栈容量为1,64为类型数据所占栈容量为2
(2)操作数栈中元素的数据类型必须与字节码指令的序列严格匹配,即确定类型的指令只能操作对应类型的数据
(3)操作数栈可以重叠,即在概念模型中,两个不同的栈帧是完全相互独立的,但是大多数虚拟机的实现里都会让两个栈帧出现一部分重叠,既节省空间,又可以在方法调用时共用一部分数据。注意重叠部分不一定相同,如操作栈共享区域与局部变量表共享区域实现重叠
1.3 动态连接
(1)每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,用来支持方法调用过程中的动态连接
(2)方法调用指令会以常量池中指向方法的符号引用作为参数
- 一部分符号引用在类加载阶段或第一次使用时转化为直接引用,称为静态解析
- 另一部分符号引用在第一次运行期间转化为直接引用,称为动态连接
1.4 方法返回地址
(1)方法的返回可以分为正常退出和异常退出
-
正常退出,主调方法的PC值作为返回地址,栈帧中很可能保存这个PC值
-
异常退出,返回地址通过异常表来确定,栈帧一般不会保存这部分信息
(2)方法退出的过程等同于栈帧出栈,因此退出时可能执行的操作
- 恢复上层方法的局部变量表和操作数栈
- 如果有返回值,把返回值压入调用者栈帧的操作数栈中
- 调整PC的值以指向方法调用指令后面的一条指令
- ……
1.5 附加信息
如与调试、性能收集相关的信息,这部分信息完全取决于具体的虚拟机实现
2.方法调用
(1)方法调用并不等同于方法内代码的执行,而是确定被调用的方法的版本,即与重载和重写相关
(2)方法调用主要涉及到的字节码指令
- invokestatic:调用静态方法
- invokespecial:调用实例构造器
()方法、私有方法和父类中的方法 - invokevirtual:调用所有的虚方法
- invokeinterface:调用接口方法,会在运行时确定一个实现该接口的对象
- invokedynamic:先在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法
(3)非虚方法:方法调用时会在类加载的时候就可以把符号引用解析为该方法的直接引用,如静态方法、私有方法、实例构造器、父类方法和final方法。反之为虚方法
2.1 解析调用
解析调用一定是一个静态的过程,在编译期间就完全确定,在类加载的解析阶段就会把涉及的符号引用全部转变为明确的直接引用,不必延迟到运行期再去完成
2.2 分派调用
静态类型与实际类型
Human man = new Man();- 1
(1)静态类型:Human,也叫外观类型,是编译期确定并使用的类型
(2)实际类型:Man,也叫运行时类型,运行时才会确定的类型
(3)两种类型都可以在程序中发生变化,区别是
- 静态类型的变化仅在使用时发生(类型转换),变量本身的静态类型不会被改变,并且最终的静态类型是编译期可知的
- 实际类型变化的结果在运行期才确定,编译时并不清楚这个对象的实际类型是什么
静态分派
所有依赖静态类型来决定方法执行版本的分派动作,最典型的应用就是方法重载
动态分派
运行期根据实际类型确定方法执行版本的分派过程,最典型的应用是方法重写
单分派和多分派
(1)宗量:方法的接收者和方法的参数
(2)单分派是根据一个宗量对目标方法进行选择,如动态分派已经确定了方法的参数,仅需要考虑方法的接收者的实际类型这一个宗量
(3)多分派是根据多于一个宗量对目标方法进行选择,如静态分派需要根据方法参数和方法接收者两个宗量来选择方法
2.3 注意
解析与分派这两者之间的关系并不是二选一的,他们是在不同层次上去筛选、确定目标方法的过程。比如静态方法会在编译期确定、在类加载期解析,而静态方法显然也可以有重载版本,选择重载版本是通过静态分派决定的
3.基于栈的字节码解释执行引擎
3.1 解释执行

解释执行的过程中,Javac编译器在JVM之外,完成了词法分析、语法分析到抽象语法树,再遍历语法树生成线性的字节码指令流的过程,后续的解释执行则由JVM内部的解释器完成3.2 基于栈的指令集与基于寄存器的指令集
基于寄存器的指令集
mov eax, 1 add eax, 1- 1
- 2
每个指令都包含两个单独的输入参数,执行过程依赖于寄存器来访问和存储数据
基于栈的指令集
iconst_1 iconst_1 iadd istore_0- 1
- 2
- 3
- 4
(1)指令流中的指令通常不带参数,使用操作数栈中的数据作为指令的运算输入,指令的运算结果也存储在操作栈中
(2)优点
- 可移植,用户程序不会直接用到寄存器,避免了硬件的约束,由虚拟机自行决定把一些访问最频繁的数据(程序计数器、栈顶缓存等)放到寄存器中以获取尽量好的性能,同时实现也更简单
- 代码相对紧凑,字节码中每个字节都对应一条指令
- 编译器实现更简单,所需空间都在栈上操作,不需要考虑空间分配的问题
(3)缺点
- 理论上执行速度稍慢,由于内存数量较多且需要内存访问,但局限于解释执行的状态下,如果经过即时编译器输出成物理机上的汇编指令流,那就与指令集架构无关了
些访问最频繁的数据(程序计数器、栈顶缓存等)放到寄存器中以获取尽量好的性能,同时实现也更简单 - 代码相对紧凑,字节码中每个字节都对应一条指令
- 编译器实现更简单,所需空间都在栈上操作,不需要考虑空间分配的问题
-
-
相关阅读:
怎么把amr格式转换成mp3?
【Android 屏幕适配】屏幕适配通用解决方案 ③ ( 自定义组件解决方案 | 获取设备状态栏高度 | 获取设备屏幕数据 )
AI芯片软件定义硬件架构
如何使用VMware12PRO安装Mac OS
笔记59:序列到序列学习Seq2seq
自动化脚本如何切换环境?Pytest这些功能你必须要掌握
arm架构docker安装mysql5.7
9k+ Star 简洁好用的开源 Linux 运维管理面板
PowerDesigner 设置
Golang入门笔记(10)—— 闭包 closure
- 原文地址:https://blog.csdn.net/scottb/article/details/126617062