-
【初认Redis】
Redis的作者
Salvatore Sanfilippo (antirez),男,意大利人,出生并居住在西西里 岛,个人网站 http://invece.org/ 。早年为系统管理员,关注计算机安全领域,于 1999 年发明了 idle scan 扫描技术,该技术现在在 nmap 扫描器上也有实现。2004 年~2006 年期间在做嵌入式方面的工作,并 为此写了名为 Jim 的Tcl 解释器 、《Tcl Wise:Guide to the Tcl programming language》一书以及《Tcl the Misunderstood》文档。(Redis 的事件处理器就重写自 Jim 的事件循环,而 Redis 的测试套件也使用 Tcl 语言来写的)。除此之外,他在2006 还写了 Hping —— 一个 TCP/IP 包分析器。之后开始接触 web ,在 2007 年和另一个朋友共同创建了 LLOOGG.com,并因为解决这个网站的负载问题而在 2009 年 2 月 26 日发明了 Redis
antirez的github账号简介
redis是K-V结构内存型数据服务。
官网介绍
Redis 是一个开源的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件.它支持多种类型的数据结构,如
字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets)
与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了
复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU
eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过
Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。中文官网www.redis.cn
应用场景
1、缓存数据
最常用,对经常需要查询且变动不是很频繁的数据 常称作热点数据。
2、消息队列
可以做,但不建议。
3、计数器
比如统计点击率、点赞率,redis具有原子性,可以避免并发问题
4、网站信息
大型电商平台初始化页面数据的缓存。比如去哪儿网购买机票的时候首页的价格和你点进去的价格会有差异。
5、热点数据
比如新闻网站实时热点、微博热搜等,需要频繁更新。总数据量比较大的时候直接从数据库查询会影响性能redis为什么快
- 基于内存实现,不需要和磁盘交互,读写速度快
- 本身是KV结构,类似hashMap,查询速度接近O(1)
- 命令执行是单线程,避免上下文切换
- 使用多路I/O复用模型,非阻塞I/O
- redis自己的底层数据结构支持,如跳表、SDS
Redis 的5中数据类型:
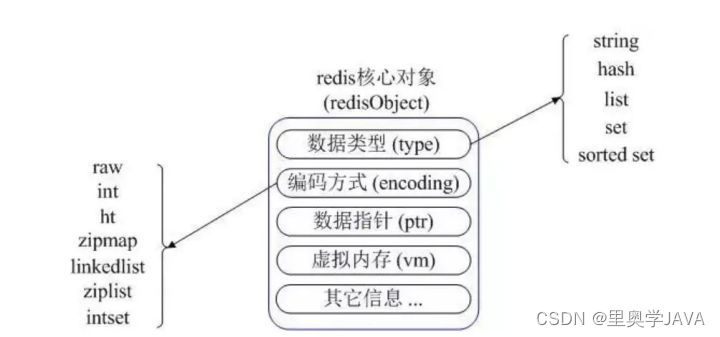
Redis的2中持久化方式
RDB 默认
RDB(Redis DataBase )是默认的持久化方式,会生成dump.rdb文件。不足:可靠性低
触发机制
手动触发
save:主线程去备份,备份期间不会处理其他指令,其他指令必须等待
bgsave:子线程去备份,其他指令正常执行
自动触发
shutdown、flushall指令触发、定时出发(可配置)AOF
AOF(Append Only File)默认关闭的,appendonly no //默认关闭,可以进行开启,开启后会生成appendonly.aof文件
AOF 同步机制- always:每次写入都会执行fsync,性能慢,但是安全
- everysec 默认:每秒执行一次fsync,可能会丢失1s数据
- no:由操作系统保证数据同步到磁盘,速度最快数据只需要交给操作系统
重写机制
由于AOF是追加的会越来越大,所以引入重写机制- 什么时候重写:大于auto-aof-rewrite-min-size 默认64mb触发重写,下次重写条件auto-aof-rewrite-percentage 100 即要达到上次压缩后的2倍。如果第一次重写后是40MB,那么下次到达40*(1+100%)=80MB才会重写
AOF优缺点:
优点:- 性能高,默认最多丢失1s数据
- 磁盘满了,追加失败可以用redischeck-aof 工具来修复
- 格式都是追加的日志,所以可读性更高
缺点
- 数据集一般比RDB大
- 持久化跟数据加载比RDB更慢
- 在7.0之前,重写的时候,因为重写的时候,新的指令会缓存在内存
区,所以会导致大量的内存使用 - 重写期间,会跟磁盘进行2次IO,一个是写入老的AOF文件,一个
是写入新的AOF文件
过期策略
惰性过期
每次访问key,触发expireIfNeeded方法- 1
定时过期
定时方法serverCron
1.扫描所有有过期时间的key
2.根据hash桶的维度扫描,扫到20个为止
3.单个桶不足20,扫描下一个桶,扫到的桶就把桶内扫完,扫描最多不超过400个桶
4.删除扫描到的过期的key
5.如果400个桶没数据,或者扫描的删除跟扫描的key总数超过10%,继续执行2,3,4
6.循环16次后会去检测时间,超过指定时间会跳出淘汰
淘汰策略
1.noeviction 不淘汰 能读不能写 默认
2.LRU (least recently used)最近最少使用
3.LFU (least frequently used)最不常使用
4.Random 随机
5.TTL 即将过期2、3、4分别适用于所有key、有过期时间的所有key
淘汰流程
淘汰池的概念,默认大小16
1.每次指令操作,自旋会判断当前内存是否满足指令所需内存
2.如果不满足,会从淘汰池中的尾部取最适合淘汰的数据
2.1 会取样(配置 maxmemory-samples)从Redis中获取随机获
取到取样的数据 解决一次性读取所有的数据慢的问题
2.2 在取样的数据中,根据淘汰算法 找到最适合淘汰的数据
2.3 将最合适的那个数据跟淘汰池中的数据比较,是否比淘汰池
中的更适合淘汰,如果更适合,放入淘汰池
2.4 按照适合的程度进行排序,最适合淘汰的放入尾部
3.将需要淘汰的数据从Redis删除,并且从淘汰池移除集群
主从数据同步
role:master //角色
connected_slaves:1 //从节点数量
slave0:ip=192.168.0.1,port=6379,state=online,offset=789,lag=1 //从节点的信息 状态 偏移量
master_replid:04f4969ab63ce124e870fa1xxx448e7
//# master启动时生成的40位16进制的随机字符串,用来标识master节点
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:78899 //mater已写入的偏移量
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576 //缓冲区大小
repl_backlog_first_byte_offset:1
repl_backlog_histlen:78899 //缓冲区的数据已有大小(是个环形,跟
RedoLog一样会覆盖)Redis只能主写从读,因为只有slave会从主拿数据,master不会拿slave数据的。
slave数据同步
在slave的serverCron方法调用replicationCron方法,里面会发起跟
master的数据同步,参数(master_replid,偏移量offset)
master接收到消息后
全量同步- master开始执行bgsave,生成一个RDB文件,并且把RDB文件传输
给我们的slave,同时把master的replid以及offerset(master的数
据进度,处理完命令后,都会写入自身的offerset) - slave接收到rdb文件后,清空slave自己内存中的数据,然后用rdb
来加载数据,这样保证了slave拿到的数据是master生成rdb时候的
最新数据。 - 由于master生成RDB文件是用的bgsave生成,所以,在生成文件的
时候,是可以接收新的指令的。那么这些指令,我们需要找一个地
方保存,等到slave加载完RDB文件以后要同步给slave。- . 在master生成rdb文件期间,会接收新的指令,这些新的指令会
保存在一个内存区间,这个内存区间就是replication_buffer。
我们可以通过以下方式设置replication_buffer的大小 - 这个空间不能太小,如果太小,为了数据安全,会关闭跟从库
的网络连接。再次连接得重新全量同步,但是问题还在,会导
致无限的在同步
增量同步
master中有个另外的积压缓存(replication_backlog_buffer)。
如果slave发送的(master_replid,偏移量offset) master_replid在master中存在,且offset之后的数据都在replication_backlog_buffer中,则会发送replication_backlog_buffer中的增量数据到slave。
- . 在master生成rdb文件期间,会接收新的指令,这些新的指令会
主从主要解决备份和负载的问题。
sentinel哨兵机制
master挂了,slave不会自动升级为master,这时就需要使用redis中的哨兵机制了。
哨兵服务可以单独启动。
功能- 监控:能够监控我的Redis各实例是否正常工作
- 通知:如果Redis的实例出现问题,能够通知给其他实例以及sentinel
- 自动故障转移:选举sentinel,来做故障转移
- 选举依据
- 与master的断开连接时间
- 配置的优先级
- 已复制的偏移量
- Run ID
- 发现master故障
- 单个哨兵发现故障做标记SDOWN
- 询问其他sentinel,如果超过Quorum(法定人数)的sentinel都
认为master不可用,那么就会将master标为ODOWN(Objectively Down
condition 客观下线)
- 转移条件
Quorum如果大于一半,必须Quorum的sentinel授权,故障迁移才能启动
- 配置提供
客户端只需要和sentinel连接:
sentinel可以提供Redis的master实例地址,
那么客户端只需要跟sentinel进行连接,master挂了后会提供新的master
缺点:会有脑裂问题存在
cluster
分片思想: 把数据分布到不同的节点。这样如果某些节点异常,其他数据能正常提供服务,跟微服务的思想很相似。
基本逻辑,引入虚拟槽,每个可以对应唯一的虚拟槽,每个节点分配一定区间的虚拟槽,
这样key和节点之前间接通过虚拟槽关联。节点扩容和缩容的时候只需要移动少量虚拟槽点数据就可以了,不需要影响所有的节点。hash slot(虚拟槽):
- Redis cluster中有16384个虚拟槽。
- 会根据key 通过CRC16 取模 16383 得到一个0到16383的值 计算公
式:slot = CRC16(key) & 16383,得到的值,就代表这个key在哪个虚拟
槽。 - key跟虚拟槽是根据key计算的,不会变
- 如果想把相关key放入一个虚拟槽,也就是一个实例节点,我们可以采用{},那
么就只会根据{}里面的内容计算hash槽! - 节点移动、宕机故障转移、扩容缩容
- 每次节点的扩容与缩容,只需要改变节点跟虚拟槽的关系即可,不需
要全部变动。
- 每次节点的扩容与缩容,只需要改变节点跟虚拟槽的关系即可,不需
-
相关阅读:
【ARM裸机】ARM入门
Excel数据分析
CSS基础知识
图像处理初学者导引---OpenCV 方法演示项目
JavaScript:实现Fedwick树算法(附完整源码)
债券数据集:绿色债券数据集、历时新发、发行债券、DCM定价估值四大指标数据
【图像隐写】基于Jsteg算法实现JPEG图像信息隐藏,可设置DCT系数 嵌入率附Matlab代码
洛谷——P1164 小A点菜
使用Vue3和Vite升级你的Vue2+Webpack项目
使用DataSecurity Plus可以快速检测威胁并自动响应事件
- 原文地址:https://blog.csdn.net/loveme888/article/details/126606246