-
C++ 哈希桶模拟实现(补充)
目录
迭代器实现与UnorderedMap.h和UnorderedSet.h的封装
定义基本的存储结构
- #pragma once
- #include
- #include
- using namespace std;
- namespace OpenHash
- {
- template<class K,class V>
- struct HashNode
- {
- HashNode
- pair
- //构造函数
- HashNode(const pair
- :_next(nullptr)
- ,_kv(kv)
- {}
- };
- template<class K,class V>
- class HashTable
- {
- typedef HashNode
- public:
- //待写
- private:
- vector
- size_t _n = 0; //有效数据的个数
- };
- }
Insert()和Find()
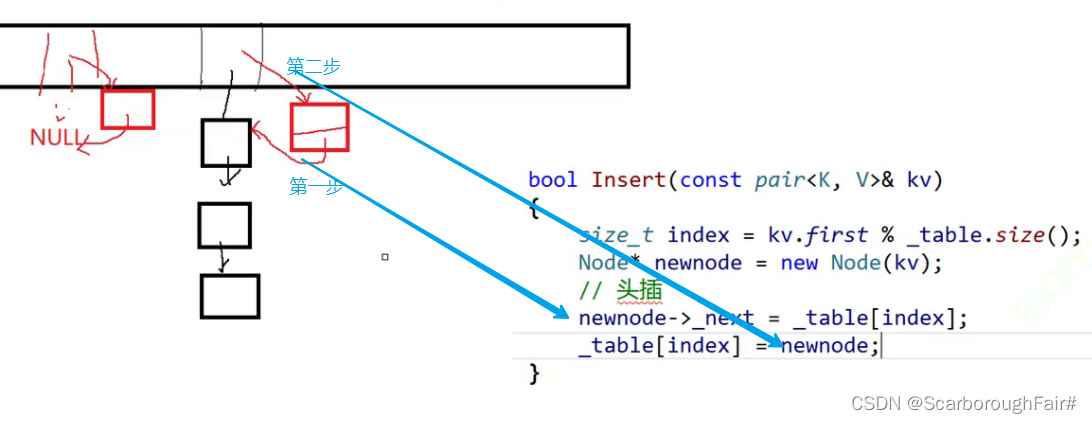
- bool Insert(const pair
- {
- //Find()函数防止冗余
- if (Find(kv.first))
- return false;
- size_t index = kv.first % _table.size();
- //采用头插法,尾插法还需要找尾,麻烦
- Node* newnode = new Node(kv);
- newnode->_next = _table[index];
- _table[index] = newnode;
- ++_n;
- return true;
- }
- Node* Find(const K& key)
- {
- size_t index = kv.first % _table.size();
- Node* cur = _table[index];
- while (cur)
- {
- if (cur->_kv.first == key)
- {
- return cur;
- }
- else
- {
- cur = cur->_next;
- }
- }
- return nullptr;
- }
Erase()
思考:如果单链表不给头结点,如何删除指定节点?采用替换法删除
将下一个节点的值赋给指定节点,再删除下一个节点
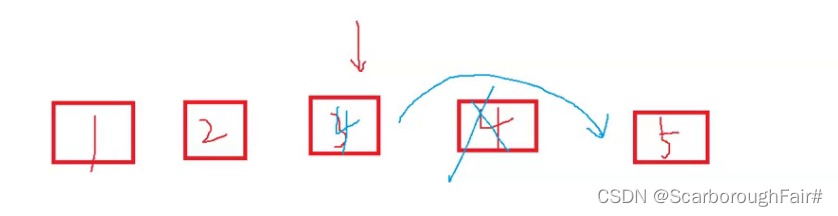
思考:采用替换法如何删除尾节点?以下图为例,删除104节点
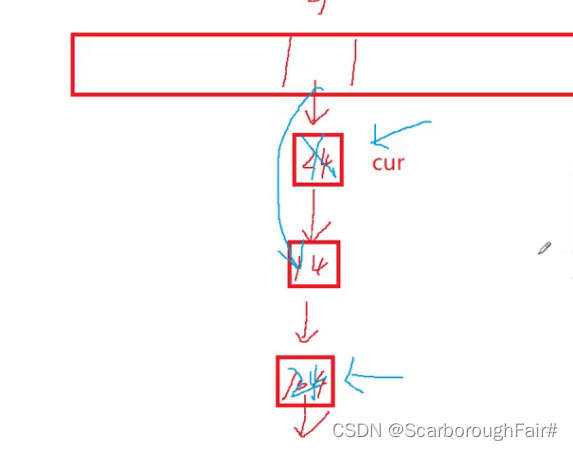
- bool Erase(const K& key)
- {
- size_t index = kv.first % _table.size();
- Node* prev = nullptr;
- Node* cur = _table[index];
- while (cur)
- {
- if (cur->_kv.first == key)
- {
- if (_table[index] == cur)
- {
- _table[index] = cur->_next;
- }
- else
- {
- prev->_next = cur->_next;
- }
- --_n;
- delete cur;
- return true;
- }
- prev = cur;
- cur = cur->_next;
- }
- return false;
- }
如何控制哈希冲突?
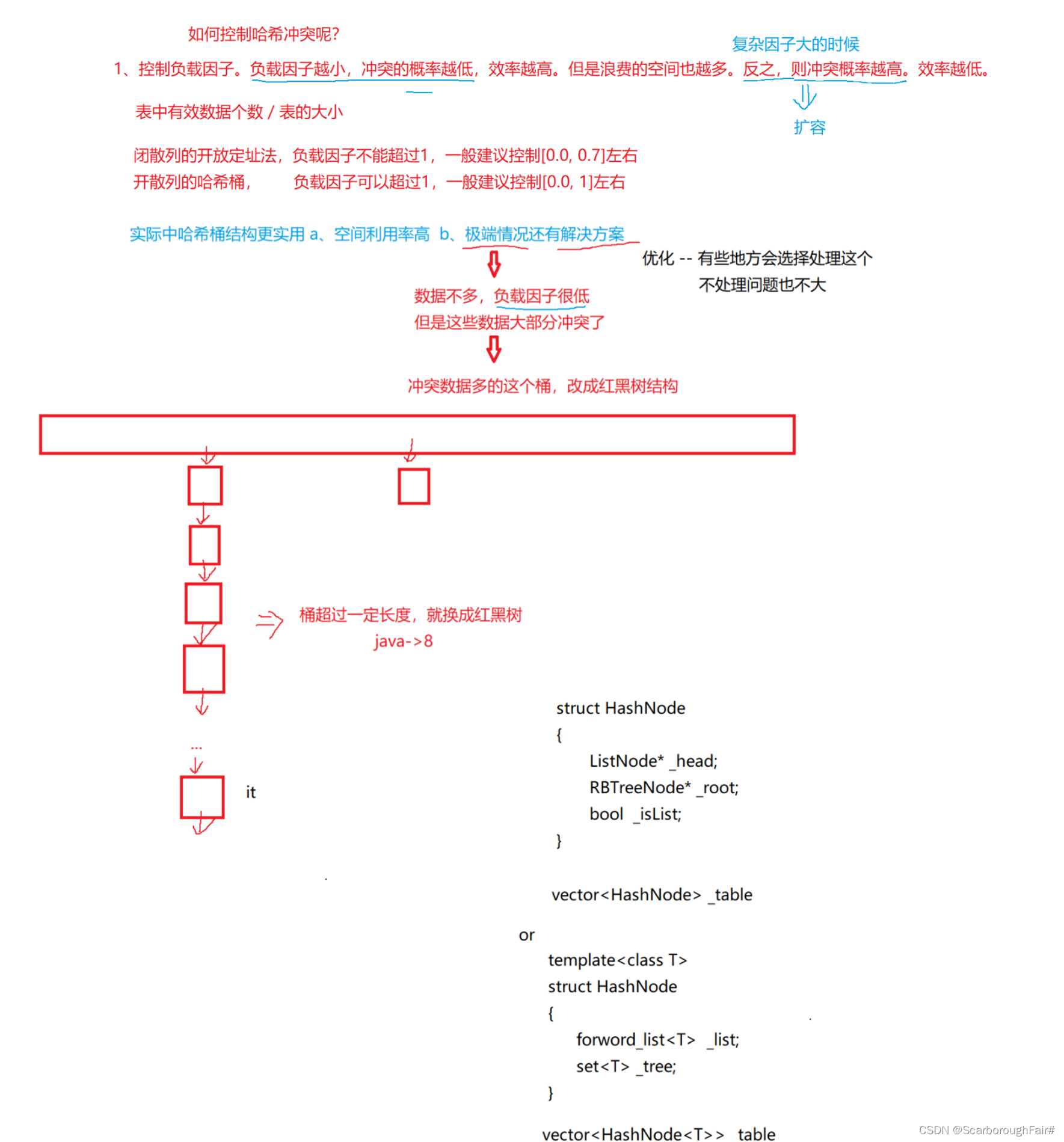
Insert()中添加扩容操作

- bool Insert(const pair
- {
- //Find()函数防止冗余
- if (Find(kv.first))
- return false;
- //负载因子到1的时候增容
- //负载因子为0的时候要防止除零错误
- if (_n == _table.size())
- {
- vector
- size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
- newtable.resize(newSize, nullptr);
- //遍历取旧表中节点,重新算映射到新表中的位置,挂到新表中
- for (size_t i = 0; i < _table.size(); ++i)
- {
- if (_table[i])//operator[]会检查给的下标是否在0到size这个范围之内
- {
- Node* cur = _table[i];
- while (cur)//若不为空,则把该桶取完,计算其在新表中的位置
- {
- Node* next = cur->_next;//保存cur的下一个节点
- size_t index = cur->_kv.first % newtable.size();
- //头插
- cur->_next = newtable[index];
- _table[index] = cur;
- cur = next;
- }
- _table[i] = nullptr;//都处理完后旧表的当前位置可置空
- }
- }
- _table.swap(newtable); //交换新旧表
- }
- size_t index = kv.first % _table.size();
- //采用头插法,尾插法还需要找尾,麻烦
- Node* newnode = new Node(kv);
- newnode->_next = _table[index];
- _table[index] = newnode;
- ++_n;
- return true;
- }
其他问题的解决
1.K不支持取模的情况?提供一个默认返回的仿函数,再提供一个特化的仿函数。后续需要取模的地方使用仿函数即可(详细见全部代码)
- template<class K>
- struct Hash
- {
- size_t operator()(const K& key)
- {
- return key;
- }
- };
- // 特化
- template<>
- struct Hash
- {
- // "int" "insert"
- // 字符串转成对应一个整形值,因为整形才能取模算映射位置
- // 期望->字符串不同,转出的整形值尽量不同
- // "abcd" "bcad"
- // "abbb" "abca"
- size_t operator()(const string& s)
- {
- // BKDR Hash
- size_t value = 0;
- for (auto ch : s)
- {
- value += ch;
- value *= 131;
- }
- return value;
- }
- };
2.除了控制负载因子,尽量让表的大小为素数也可以控制哈希冲突。但是此时对于增容的挑战很大:要保证增容二倍后还是表的大小还是素数。->通过素数表解决
- //提供一个素数表(来自STL源码)
- size_t GetNextPrime(size_t prime)
- {
- const int PRIMECOUNT = 28;
- static const size_t primeList[PRIMECOUNT] = //定义成静态的,不用每次重新创建数组
- {
- 53ul, 97ul, 193ul, 389ul, 769ul,
- 1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
- 49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
- 1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
- 50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
- 1610612741ul, 3221225473ul, 4294967291ul
- };
- size_t i = 0;
- for (; i < PRIMECOUNT; ++i)
- {
- //获取一个比当前素数要大的数
- if (primeList[i] > prime)
- return primeList[i];
- }
- return primeList[i];
- }
此时增容函数就可进行修改

- bool Insert(const pair
- {
- //Find()函数防止冗余
- if (Find(kv.first))
- return false;
- HashFunc hf;
- //负载因子到1的时候增容
- //负载因子为0的时候要防止除零错误
- if (_n == _table.size())
- {
- vector
- //size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
- //newtable.resize(newSize, nullptr);
- newtable.resize(GetNextPrime(_table.size()));//通过素数表可重新写增容函数
- //遍历取旧表中节点,重新算映射到新表中的位置,挂到新表中
- for (size_t i = 0; i < _table.size(); ++i)
- {
- if (_table[i])//operator[]会检查给的下标是否在0到size这个范围之内
- {
- Node* cur = _table[i];
- while (cur)//若不为空,则把该桶取完,计算其在新表中的位置
- {
- Node* next = cur->_next;//保存cur的下一个节点
- size_t index = hf(cur->_kv.first) % newtable.size();
- //头插
- cur->_next = newtable[index];
- _table[index] = cur;
- cur = next;
- }
- _table[i] = nullptr;//都处理完后旧表的当前位置可置空
- }
- }
- _table.swap(newtable); //交换新旧表
- }
- size_t index = hf(kv.first) % _table.size();
- //采用头插法,尾插法还需要找尾,麻烦
- Node* newnode = new Node(kv);
- newnode->_next = _table[index];
- _table[index] = newnode;
- ++_n;
- return true;
- }
UnorderedMap.h和UnorderedSet.h
- #pragma once
- #include"HashTable.h"
- namespace bit
- {
- template<class K, class V>
- class unordered_map
- {
- public:
- struct MapKeyOfT
- {
- const K& operator()(const pair
- {
- return kv.first;
- }
- };
- bool Insert(const pair
- {
- _ht.Insert(kv);
- return true;
- }
- private:
- OpenHash::HashTable
- };
- }
- #pragma once
- #include"HashTable.h"
- namespace bit
- {
- template<class K, class V>
- class unordered_set
- {
- public:
- struct SetKeyOfT
- {
- const K& operator()(const K& k)
- {
- return k;
- }
- };
- bool Insert(const K k)
- {
- _ht.Insert(k);
- return true;
- }
- private:
- OpenHash::HashTable
- };
- }
迭代器实现与UnorderedMap.h和UnorderedSet.h的封装
各个部分的改动和添加看注释即可,最终整体代码如下
- #pragma once
- #include
- #include
- using namespace std;
- namespace OpenHash
- {
- template<class K>
- struct Hash
- {
- size_t operator()(const K& key)
- {
- return key;
- }
- };
- // 特化
- template<>
- struct Hash
- {
- // "int" "insert"
- // 字符串转成对应一个整形值,因为整形才能取模算映射位置
- // 期望->字符串不同,转出的整形值尽量不同
- // "abcd" "bcad"
- // "abbb" "abca"
- size_t operator()(const string& s)
- {
- // BKDR Hash
- size_t value = 0;
- for (auto ch : s)
- {
- value += ch;
- value *= 131;
- }
- return value;
- }
- };
- template<class T>
- struct HashNode
- {
- HashNode
* _next; - T _data;
- HashNode(const T& data)
- :_next(nullptr)
- ,_data(data)
- {}
- };
- //前置声明
- //前置声明不需要给默认参数
- template<class K, class T, class KeyOfT, class HashFunc>
- class HashTable;
- //哈希桶迭代器
- template<class K, class T, class KeyOfT, class HashFunc = Hash
> - struct _HTIterator
- {
- typedef HashNode
Node; - typedef _HTIterator
- typedef HashTable
- Node* _node;
- HT* _pht;//传哈希表的指针
- _HTIterator(Node* node,HT* pht)
- :_node(node)
- ,_pht(pht)
- {}
- Self& operator++()
- {
- //1.当前桶中还有数据,那么就在当前桶往后走
- //2.当前桶走完了,需要往下一个桶去走
- if (_node->_next)
- {
- _node = _node->_next;
- }
- else
- {
- //迭代器走到当前桶的最后一个位置的时候如何进入下一个桶?
- _pht->_table.size();
- KeyOfT kot;
- HashFunc hf;
- size_t index = hf(kot(_node->_data)) % _pht->_table.size();//算出当前桶的位置
- //通过keyoft的仿函数取出data里面的k取出,k再通过HashFunc的仿函数转换成可以取模的整型
- ++index;
- while (index < _pht->_table.size())
- {
- if (_pht->_table[index])//找到下一个桶了
- {
- _node = _pht->_table[index];//指向桶里面的第一个节点
- return *this;
- }
- else
- {
- ++index;
- }
- }
- //return iterator(nullptr, _pht);//后面没有桶了,返回空的迭代器
- _node = nullptr;
- }
- return *this;
- }
- T& operator*()
- {
- return _node->_data;
- }
- T* operator->()
- {
- return &_node->_data;
- }
- bool operator != (const Self& s)const
- {
- return _node != s._node;
- }
- bool operator == (const Self& s)const
- {
- return _node == s._node;
- }
- };
- template<class K,class T, class KeyOfT,class HashFunc = Hash
> - class HashTable
- {
- typedef HashNode
Node; - //设计类模板的友元
- template<class K, class T, class KeyOfT, class HashFunc>//需要添加模板参数
- friend struct _HTIterator;
- public:
- typedef _HTIterator
- //默认的构造
- HashTable() = default; //C++11关键词:显示指定生成默认构造
- //拷贝构造赋值
- HashTable(const HashTable& ht)
- {
- //深拷贝
- _n = ht._n;
- _table.resize(ht._table.size());
- for (size_t i = 0; i < ht._table.size(); i++)
- {
- Node* cur = ht._table[i];
- while (cur)
- {
- Node* copy = new Node(cur->_data);
- //头插到新表
- copy->_next = table[i];
- _table[i] = copy;
- cur = cur->_next;
- }
- }
- }
- //赋值
- HashTable& operator=(const HashTable ht)
- {
- _table.swap(ht._table);
- swap(_n,ht._n);
- return *this;
- }
- //析构
- ~HashTable()
- {
- for (size_t i = 0; i < _table.size();i++)
- {
- Node* cur = _table[i];
- while (cur)
- {
- Node* next = cur->_next;//保存当前节点
- delete cur; //释放当前节点
- cur = next;
- }
- _table[i] = nullptr;
- }
- }
- iterator begin()
- {
- //返回第一个桶里面的第一个节点
- size_t i = 0;
- while (i<_table.size())
- {
- if (_table[i])//不为空就找到第一个桶
- {
- return iterator(_table[i],this);//迭代器需要一个节点的指针,_table[i]就是节点的指针
- //成员函数this就是自己对象的地址,即this就是哈希表的地址
- }
- ++i;
- }
- return end();
- }
- iterator end()
- {
- return iterator(nullptr, this);
- }
- //提供一个素数表(来自STL源码)
- size_t GetNextPrime(size_t prime)
- {
- const int PRIMECOUNT = 28;
- static const size_t primeList[PRIMECOUNT] = //定义成静态的,不用每次重新创建数组
- {
- 53ul, 97ul, 193ul, 389ul, 769ul,
- 1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
- 49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
- 1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
- 50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
- 1610612741ul, 3221225473ul, 4294967291ul
- };
- size_t i = 0;
- for (; i < PRIMECOUNT; ++i)
- {
- //获取一个比当前素数要大的数
- if (primeList[i] > prime)
- return primeList[i];
- }
- return primeList[i];
- }
- pair
- {
- KeyOfT kot;
- //找到了
- auto ret = Find(kot(data));
- if(ret != end())
- return make_pair(ret,false);
- HashFunc hf;
- //负载因子到1的时候增容
- //负载因子为0的时候要防止除零错误
- if (_n == _table.size())
- {
- vector
- //size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
- //newtable.resize(newSize, nullptr);
- newtable.resize(GetNextPrime(_table.size()));//通过素数表可重新写增容函数
- //遍历取旧表中节点,重新算映射到新表中的位置,挂到新表中
- for (size_t i = 0; i < _table.size(); ++i)
- {
- if (_table[i])//operator[]会检查给的下标是否在0到size这个范围之内
- {
- Node* cur = _table[i];
- while (cur)//若不为空,则把该桶取完,计算其在新表中的位置
- {
- Node* next = cur->_next;//保存cur的下一个节点
- size_t index = hf(kot(cur->_data)) % newtable.size();
- //头插
- cur->_next = newtable[index];
- _table[index] = cur;
- cur = next;
- }
- _table[i] = nullptr;//都处理完后旧表的当前位置可置空
- }
- }
- _table.swap(newtable); //交换新旧表
- }
- size_t index = hf(kot(data)) % _table.size();
- //采用头插法,尾插法还需要找尾,麻烦
- Node* newnode = new Node(data);
- newnode->_next = _table[index];
- _table[index] = newnode;
- ++_n;
- return make_pair(iterator(newnode, this), true);
- }
- iterator Find(const K& key)
- {
- if (_table.size() == 0)
- {
- return end();
- }
- KeyOfT kot;
- HashFunc hf;
- size_t index = hf(key) % _table.size();
- Node* cur = _table[index];
- while (cur)
- {
- if (kot(cur->_data) == key)
- {
- return iterator(cur,this);//Find的返回值为迭代器
- }
- else
- {
- cur = cur->_next;
- }
- }
- return end();
- }
- bool Erase(const K& key)
- {
- size_t index = hf(kot(key)) % _table.size();
- Node* prev = nullptr;
- Node* cur = _table[index];
- while (cur)
- {
- if (kot(cur->data) == key)
- {
- if (_table[index] == cur)
- {
- _table[index] = cur->_next;
- }
- else
- {
- prev->_next = cur->_next;
- }
- --_n;
- delete cur;
- return true;
- }
- prev = cur;
- cur = cur->_next;
- }
- return false;
- }
- void TestHashTable1()
- {
- int a[] = { 1,5,30,100000,100,18,15,7,40,44 };
- HashTable<int, int>ht;
- for (auto e : a)
- {
- ht.Insert(make_pair(e.e));
- }
- ht.Insert(make_pair(25, 25));
- }
- private:
- vector
- size_t _n = 0; //有效数据的个数
- };
- }
- #pragma once
- #include "HashTable.h"
- namespace bit
- {
- template<class K>
- class unordered_set
- {
- struct SetKeyOfT
- {
- const K& operator()(const K& k)
- {
- return k;
- }
- };
- public:
- typedef typename OpenHash::HashTable
- iterator begin()
- {
- return _ht.begin();
- }
- iterator end()
- {
- return _ht.end();
- }
- pair
- {
- return _ht.Insert(k);
- }
- private:
- OpenHash::HashTable
- };
- void test_unordered_set1()
- {
- unordered_set<int> us;
- us.insert(200);
- us.insert(1);
- us.insert(2);
- us.insert(33);
- us.insert(50);
- us.insert(60);
- us.insert(243);
- us.insert(6);
- unordered_set<int>::iterator it = us.begin();
- while (it != us.end())
- {
- cout << *it << " ";
- ++it;
- }
- }
- }
- #pragma once
- #include "HashTable.h"
- namespace bit
- {
- template<class K, class V>
- class unordered_map
- {
- struct MapKeyOfT
- {
- const K& operator()(const pair
- {
- return kv.first;
- }
- };
- public:
- typedef typename OpenHash::HashTable
- iterator begin()
- {
- return _ht.begin();
- }
- iterator end()
- {
- return _ht.end();
- }
- pair
- {
- return _ht.Insert(kv);
- }
- V& operator[](const K& key)
- {
- pair
- return ret.first->second;
- }
- private:
- OpenHash::HashTable
- };
- void test_unordered_map1()
- {
- unordered_map
- dict.insert(make_pair("sort", "排序"));
- dict["left"] = "左边";
- dict["left"] = "剩余";
- dict["map"] = "映射";
- dict["string"] = "字符串ַ";
- dict["set"] = "集合";
- unordered_map
- while (it != dict.end())
- {
- cout << it->first << ":" << it->second << endl;
- ++it;
- }
- cout << endl;
- }
- }
-
相关阅读:
视觉SLAM十四讲笔记-8-1
Qt5开发从入门到精通——第五篇三节( 文本编辑器 Easy Word 开发 V1.2详解 )
关于错误javax.net.ssl.SSLException: Received close_notify during handshake
QT+OSG/osgEarth编译之二十八:cairo+Qt编译(一套代码、一套框架,跨平台编译,版本:cairo-1.16.0)
vue3-puzzle-vcode接入后端验证
毅速引领模具3D打印材料创新之路
AR人脸美颜特效解决方案,打造全方位美颜美妆新时代
使用小程序制作一个飞机大战小游戏
Knife4j_接口概述、常用注解详解、搭建swagger项目、功能概述
Day 60 | 动态规划 647. 回文子串 、 516.最长回文子序列 、动态规划总结篇
- 原文地址:https://blog.csdn.net/m0_61548909/article/details/126600355
