-
【PAT(甲级)】1053 Path of Equal Weight
Given a non-empty tree with root R, and with weight Wi assigned to each tree node Ti. The weight of a path from R to L is defined to be the sum of the weights of all the nodes along the path from R to any leaf node L.
Now given any weighted tree, you are supposed to find all the paths with their weights equal to a given number. For example, let's consider the tree showed in the following figure: for each node, the upper number is the node ID which is a two-digit number, and the lower number is the weight of that node. Suppose that the given number is 24, then there exists 4 different paths which have the same given weight: {10 5 2 7}, {10 4 10}, {10 3 3 6 2} and {10 3 3 6 2}, which correspond to the red edges in the figure.
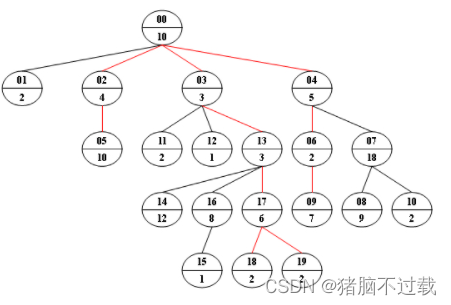
Input Specification:
Each input file contains one test case. Each case starts with a line containing 0
ID K ID[1] ID[2] ... ID[K]
where
IDis a two-digit number representing a given non-leaf node,Kis the number of its children, followed by a sequence of two-digitID's of its children. For the sake of simplicity, let us fix the root ID to be00.Output Specification:
For each test case, print all the paths with weight S in non-increasing order. Each path occupies a line with printed weights from the root to the leaf in order. All the numbers must be separated by a space with no extra space at the end of the line.
Note: sequence {A1,A2,⋯,An} is said to be greater than sequence {B1,B2,⋯,Bm} if there exists 1≤k
Sample Input:
20 9 24
10 2 4 3 5 10 2 18 9 7 2 2 1 3 12 1 8 6 2 2
00 4 01 02 03 04
02 1 05
04 2 06 07
03 3 11 12 13
06 1 09
07 2 08 10
16 1 15
13 3 14 16 17
17 2 18 19Sample Output:
10 5 2 7
10 4 10
10 3 3 6 2
10 3 3 6 2解题思路:
从树的根开始,走到底部,如果路径上所有节点的权重加起来刚好等于S,则输出这条路径。
题目意思很清晰,所以只要dfs()这颗树,把节点的权重加一下就可以解决这道题的大部分测试点了。主要的问题在于要求输出的顺序是先输出节点权重大的,再输出节点权重小的。我利用了vector
来存储路径,所以直接用了sort和自己写的cmp来对结果进行重新排序。 最后直接输出节点权重即可。
易错点:
1. 最后一个测试点是输出的顺序不符合题意。如果你对路径的排序是一层一层的排序的话(就是直接对节点进行sort),最后输出的结果就会有错,一定要把所有可行的路径都存储进一个结构中,在对他们一起排序才行。
例如下面这颗树:

如果只是对层来排序的话,输出就是
10 7 2 8
10 7 8 2
实际上我们需要的输出是
10 7 8 2
10 7 2 8
代码:
- #include
- using namespace std;
- int N;//树的节点数
- int M;//非叶子节点的个数
- int S;//总权重
- int T[101];//节点对应的权重
- vector<int> tree[101];//存储树的孩子,下标为根节点,里面为孩子
- vector<int> tpath;//存储路径
- vector
- void dfs(int a,int sum){
- if(sum>S) return;
- if(sum == S){
- if(tree[a].size()!=0){
- return;
- }
- path.push_back(tpath);
- return;
- }
- if(tree[a].size()==0) return;//走到树底部时返回
- for(int i=0;i
- tpath.push_back(T[tree[a][i]]);
- dfs(tree[a][i],sum+T[tree[a][i]]);
- tpath.pop_back();
- }
- }
- bool cmp(vector<int> a,vector<int> b){//比较权重大小
- return a>b;
- }
- int main(){
- cin>>N>>M>>S;
- for(int i=0;icin>>T[i];}for(int i=0;iint t,link;cin>>t>>link;for(int j=0;jint num;cin>>num;tree[t].push_back(num);}}tpath.push_back(T[0]);//将根节点先放入路径中dfs(0,T[0]);sort(path.begin(),path.end(),cmp);// sort(path.begin(), path.end(), greaterfor(int i=0;icout<for(int j=1;jcout<<" "<}cout<}return 0;}
- 相关阅读:
使用python绘制三维曲线图
一款带数字传输信号的OVP芯片
代码随想录 | Day 60(完结) - LeetCode 84. 柱状图中最大的矩形
Ansible
1021 Deepest Root
使用人工智能聊天机器人时要注意这些!(配提问技巧)
idrac管理界面报错:RAC0508: 发生意外错误。
AWS SAA-C03 #50
微信小程序:图片秒加水印制作生成
vue3 tsx语法
- 原文地址:https://blog.csdn.net/weixin_55202895/article/details/126610233
