-
ESMM论文精读
本文是对原文的翻译,弄懂原文每一句话的意思。
声明:鉴于本人英文一般,有翻译不对的地方望指正,谢谢!
论文地址:https://dl.acm.org/doi/epdf/10.1145/3209978.3210104题目
全空间多任务模型:一个评估点击后转化率的有效方法
摘要
在工业应用如推荐或广告的排序系统中,精确地评估点击后转化率(CVR)是非常重要的。传统的CVR主要是用深度学习模型建模,并且取得非常好的效果。然而,在实际应用中遇到了一些特定任务的问题,使得CVR建模遇到了挑战。例如:传统CVR模型只用曝光被点击过的样本训练,却被应用于整个曝光样本空间进行预测。这会导致样本选择偏差的问题。此外,还存在数据极端稀疏的问题,使得模型拟合很困难。本文使用一个全新的视角建模CVR,充分利用用户行为的序列模式(曝光 --> 点击 --> 消费)。这个被提出的全空间多任务模型(Entire Space Multi-task Model,ESMM)能同时解决以上两个问题,通过1)直接使用整个曝光样本空间建模CVR,2)采用一个特征表示迁移学习策略。实验使用的数据来自于淘宝推荐系统的流量日志,实验证明了ESMM模型相比对照模型取得了较大的提升。我们还发布了该数据集的采样版本,以供未来的研究。据我们所知,这是第一个公开数据集,服务于CVR建模的依赖点击和转换标签的序列样本。
关键词:点击转化率,多目标学习,样本选择偏差,数据稀疏,全空间建模1 引言
CVR预测对于工业应用中的排序系统是一个必要的任务,如在线广告、推荐等。比如CVR预测被用于广告的OCPC(优化每次点击成本),以调整每次点击竞价达到平台和广告主双赢。同时它在推荐系统中也是平衡用户点击偏好和购买偏好的重要因素。
本文我们主要关注CVR评估任务。为了简化讨论,我们以电子商务网站推荐系统中的CVR建模为例。被推荐的items,用户可能会点击他们感兴趣的items,甚至购买它们。用户行为将形成下面的形式:曝光–>点击–> 购买。用这种方法,CVR建模涉及到了点击后转化率评估的任务,即 p C V R = p ( c o n v e r s i o n ∣ c l i c k , i m p r e s s i o n ) pCVR=p(conversion|click,impression) pCVR=p(conversion∣click,impression)。
一般地,传统的CVR建模方法运用和CTR预测任务相似的技术,例如,最近流行的深度网络。然而存在一些特定任务的问题,使得CVR建模遇到了挑战。这些问题之中,我们介绍两个在实践过程中遇到的关键问题:1)样本选择偏差(SSB)问题。如图1所示,传统CVR建模使用曝光后被点击的数据进行训练,却被用于预测全空间所有曝光的样本。SSB问题导致被训练模型的泛化性能。2)数据稀疏(DS)问题。实际应用中,用于CVR建模的数据通常要少于CTR任务,训练数据的稀疏性使得CVR模型拟合更加困难。
有一些研究尝试解决这些挑战,在[5]中,构建不同特征的分层评估器并结合逻辑回归模型解决DS问题。然而,它依赖先验知识构建分层结构,这在千万用户和物料级别的推荐系统中应用起来很困难。过采样[11]复制稀少类别样本,以帮助减轻数据稀疏的问题,但依赖于采样率。All Missing As Negative(AMAN)利用随机采样策略选择没有点击的样本作为负样本[6]。它能通过引进未观察样本的方式一定程度解决SSB问题,但会产出一个持续被低估的预测结果。无偏方法[10]解决CTR建模中的SSB问题,通过拟合拒绝抽样观察的真正潜在分布。然而,当以拒绝概率的除数对样本进行加权时,它可能出现数值不稳定。总的来说,SSB和DS问题在CVR建模场景中都没有得到很好的解决,并且上述方法中没有一个可以应用于序列行为信息中。
本文中,通过充分利用用户行为序列模式数据,提出可以同时消除SSB和DS问题的ESMM模型。在ESMM模型中,涉及到两个辅助任务:CTR和CTCVR。为了替代直接用点击样本训练CVR模型,ESMM模型把 p C V R pCVR pCVR作为中间变量,通过乘以 p C T R pCTR pCTR得到 p C T C V R pCTCVR pCTCVR。 p C T R pCTR pCTR和 p C T C V R pCTCVR pCTCVR使用全空间的所有曝光样本评估,因此,得到的 p C V R pCVR pCVR也可以被应用于全空间样本。这表明了SSB问题得到了解决。此外,CVR网络的特征表示参数在CTR网络共享,后者被更多的样本训练,这种参数迁移学习可以帮助解决DS问题。
本文的工作,我们收集了来自淘宝推荐系统的流量日志,数据包含89亿点击到转化的序列标签样本。构建严谨的实验,ESMM模型的性能优于对照模型,证明了被提出模型的有效性。我们还发布了我们的数据集供本领域的未来研究。
2 本文方法
2.1 概念
我们假设被观察的数据集是 S = ( x i , y i → z i ) ∣ i = 1 N S={(\mathbf{x}_i,y_i \to z_i)}|^N_{i=1} S=(xi,yi→zi)∣i=1N,整个样本 ( x , y → z ) (\mathbf{x},y \to z) (x,y→z)来自于域 X × Y × Z X \times Y \times Z X×Y×Z的分布 D D D,其中 X X X是特征空间, Y Y Y和 Z Z Z是标签空间, N N N表示曝光的样本数。 x \mathbf{x} x表示观察样本的特征向量,通常是多领域的高维稀疏向量[8],比如用户侧、内容侧等。 y y y和 z z z是二分类标签, y = 1 y=1 y=1或 z = 1 z=1 z=1分别表示点击或转化时间发生。 y → z y \to z y→z表示依赖点击和转化标签的序,转化事件的发生之前总是有一次点击。
CVR模型用于评估 p C V R = p ( z = 1 ∣ y = 1 , x ) pCVR=p(z=1|y=1,\mathbf{x}) pCVR=p(z=1∣y=1,x)的概率,两个概率关联:点击率 p C T R = p ( y = 1 ∣ x ) ‾ \underline{pCTR=p(y=1|\mathbf{x})} pCTR=p(y=1∣x)和点击转化率 p C T C V R = p ( y = 1 , z = 1 ∣ x ) pCTCVR=p(y=1,z=1|\mathbf{x}) pCTCVR=p(y=1,z=1∣x)。给定曝光样本 x \mathbf{x} x,CTCVR的概率如下: p ( y = 1 , z = 1 ∣ x ) = p ( y = 1 ∣ x ) × p ( z = 1 ∣ y = 1 , x ) ; ( 公式 1 ) p(y=1,z=1|\mathbf{x}) = p(y=1|\mathbf{x}) \times p(z=1|y=1, \mathbf{x}) ;(公式1) p(y=1,z=1∣x)=p(y=1∣x)×p(z=1∣y=1,x);(公式1)
注:原文中上面有下划线的部分是:post-view click-through rate (CTR) with p C T R = p ( z = 1 ∣ x ) pCTR = p(z = 1|\mathbf{x}) pCTR=p(z=1∣x),公式中 p ( z = 1 ∣ x ) p(z=1|\mathbf{x}) p(z=1∣x)的 z = 1 z=1 z=1应该是 y = 1 y=1 y=1,因为 y y y是点击标签,而 z z z是点击后的转化标签,并且公式(1)中的 p C T R pCTR pCTR就是 p ( y = 1 ∣ x ) p(y=1|\mathbf{x}) p(y=1∣x)。所以我上文中写的是 p ( y = 1 ∣ x ) p(y=1|\mathbf{x}) p(y=1∣x),大家可以看原文中对比一下。
2.2 CVR建模和挑战
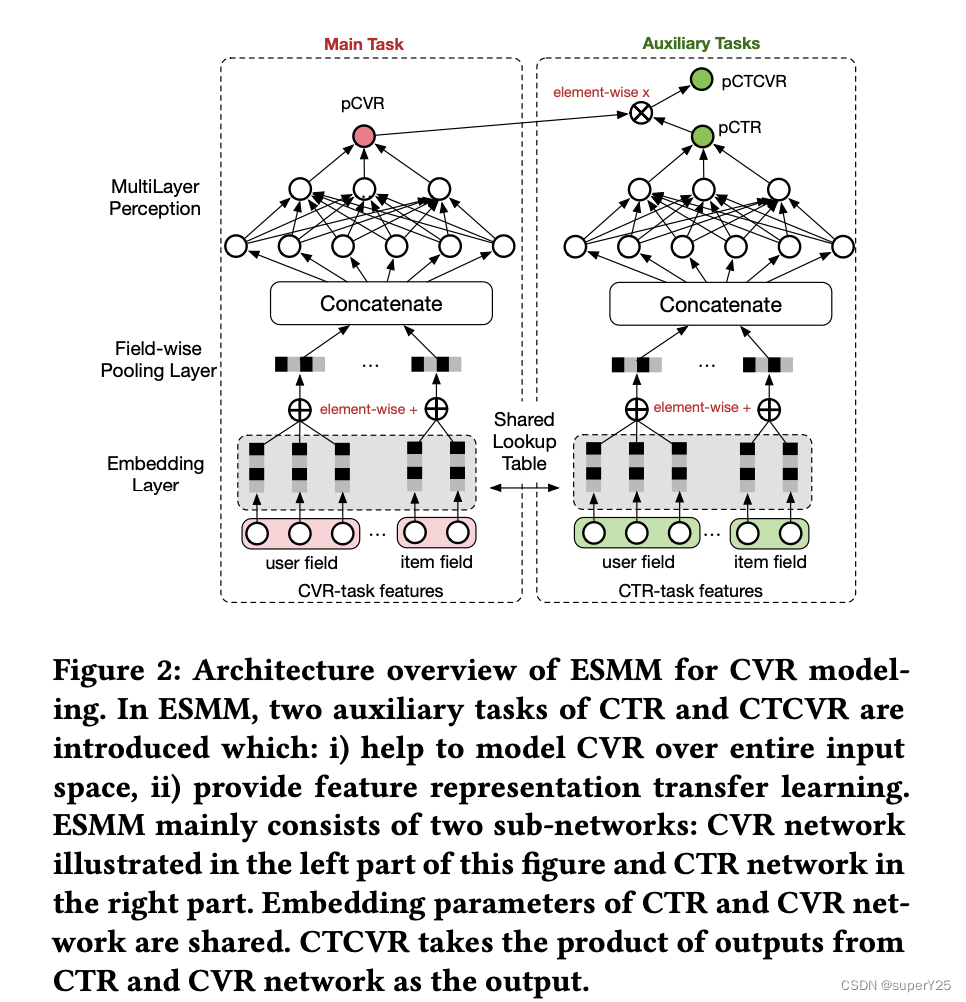
近年来,基于深度学习的方法被建议用于CVR建模,并获得了最有的效果,他们大部分遵从有一个相似的表示层和多层感知机网络架构,如[3]中所介绍的。图2的左边部分展示了这种架构,为了方面,我们将这种模型作为baseline模型。
简单地说,传统的CVR模型直接评估点击转化率 p ( z = 1 ∣ y = 1 , x ) p(z=1|y=1,\mathbf{x}) p(z=1∣y=1,x),训练模型的数据为被点击的曝光数据,即 S c = ( x j , z j ) ∣ y j = 1 ∣ j = 1 M S_c={(\mathbf{x}_j, z_j)|y_j=1}|^M_{j=1} Sc=(xj,zj)∣yj=1∣j=1M,其中 M M M是所有曝光样本中被点击样本的数量。很显然, S c S_c Sc是 S S S的一个子集,在 S c S_c Sc中没有转化( z = 0 z=0 z=0)的样本为负样本,转化( z = 1 z=1 z=1)的样本为正样本。在实际应用中,CVR建模会遇到一些特定任务场景的问题,使之遇到一些挑战。
样本选择偏差(SSB)[12]。实际应用中,传统CVR模型将 p ( z = 1 ∣ y = 1 , x ) p(z=1|y=1,\mathbf{x}) p(z=1∣y=1,x)近似等价 q ( z = 1 ∣ x c ) q(z=1|\mathbf{x}_c) q(z=1∣xc),通过引进辅助特征空间 X c X_c Xc, X c X_c Xc是和 S c S_c Sc关联的有限制的特征表示。 ∀ x c ∈ X c \forall \mathbf{x}_c \in X_c ∀xc∈Xc存在 ( x = x c , y x = 1 ) (\mathbf{x} = \mathbf{x}_c,y_{\mathbf{x}}=1) (x=xc,yx=1),其中 x ∈ X \mathbf{x} \in X x∈X并且 y x y_{\mathbf{x}} yx是 x \mathbf{x} x的点击标签。用这种方法, q ( z = 1 ∣ x c ) q(z=1|\mathbf{x}_c) q(z=1∣xc)使用 S c S_c Sc的点击样本 X c X_c Xc进行训练。在推理阶段,对于整个样本空间 X X X的 p ( z = 1 ∣ y = 1 , x ) p(z=1|y=1,\mathbf{x}) p(z=1∣y=1,x)的预测,通过计算假设条件 ( x , y x = 1 ) (\mathbf{x},y_x=1) (x,yx=1)下的 q ( z = 1 ∣ ( x ) ) q(z=1|\mathbf(x)) q(z=1∣(x))。其中 x ∈ X \mathbf{x} \in X x∈X, x \mathbf{x} x属于 X c X_c Xc。这个假设有很大可能不成立,因为 X c X_c Xc只是 X X X的一部分。它将被很少出现点击事件的随机性所影响,它的概率受到 X X X域的变化而变化。然而,在没有足够的观察样本时,来自 X X X的 X c X_c Xc可能十分不同。这将导致训练样本的分布偏离真正的样本分布,并且影响CVR建模的泛化性能。
注:特征空间 X c X_c Xc等价 X X X的条件: ∀ X ∈ X , p ( y = 1 ∣ x ) > 0 \forall X \in X,p(y=1|\mathbf{x}) > 0 ∀X∈X,p(y=1∣x)>0 并且被观察的样本足够大。否则, X c X_c Xc就是 X X X的一部分。
数据稀疏(DS)。传统方法训练CVR模型使用被点击样本 S c S_c Sc。点击事件极少出现导致CVR建模的训练数据极度稀疏。直观地,它将少1-3个数量级,比使用所有曝光数据训练的的CTR任务。表1展示了我们实验数据的统计量,CVR任务的样本数量仅仅是CTR任务的4%。
CVR建模还遇到一个挑战值得被提到,延迟反馈[1]。这项工作不是本文所关注的,其中一个原因是在我们的系统中转化延迟的量级是可以接受的。另一个原因是我们的方法可以结合之前的工作[1]处理它。
2.3 全域空间的多任务模型
ESMM模型如图2所示,充分使用了用户行为的序列模式。这个想法来自于多目标学习[9],ESMM引进了两个辅助任务CTR和CTCVR,并且同时解决了之前CVR建模的问题。
整体来看,ESMM同时输出 p C T R , p C V R 以及 p C T C V R pCTR,pCVR以及pCTCVR pCTR,pCVR以及pCTCVR。它主要由两个子网络组成:图二左边展示的CVR网络和右边展示的CTR网络,且他们都采用了和基础网络(表示层和多层感知机)相同的结构。CTCVR的输出来自CVR网络和CTR网络输出的按元素乘积(element-wise)。在ESMM模型中有几处亮点,它们对CVR建模有显著的影响,并且将ESMM模型和传统方法区别开来。
全空间建模,公式(1)给我们提示,可以转换成如下公式(2): p ( z = 1 ∣ y = 1 , x ) = p ( y = 1 , z = 1 ∣ x ) p ( y = 1 ∣ x ) ; ( 公式 2 ) p(z=1|y=1,\mathbf{x})=\frac{p(y=1,z=1|\mathbf{x})}{p(y=1|\mathbf{x})} ;(公式2) p(z=1∣y=1,x)=p(y=1∣x)p(y=1,z=1∣x);(公式2)其中 p ( y = 1 , z = 1 ∣ x ) p(y=1,z=1|\mathbf{x}) p(y=1,z=1∣x)和 p ( y = 1 ∣ x ) p(y=1|\mathbf{x}) p(y=1∣x)是利用所有曝光数据集 S S S建模。公式2向我们展示了 p C T C V R pCTCVR pCTCVR, p C T R pCTR pCTR和 p C V R pCVR pCVR的评估可以将全空间 X X X作为输入,以此直接解决SSB问题。这似乎很简单通过分别建模训练评估 p C T R pCTR pCTR和 p C T C V R pCTCVR pCTCVR,并根据公式2获得 p C V R pCVR pCVR,为了后续书写简单称之为除法。然而,实际上 p C T R pCTR pCTR是非常小的数,将其作为除数会导致结果不稳定。为了解决这个问题,ESMM模型采用了乘法的形式。在ESMM模型中, p C V R pCVR pCVR仅仅只是一个中间变量通过公式1被约束。 p C T R pCTR pCTR和 p C T C V R pCTCVR pCTCVR才是ESMM通过全空间 X X X评估的主要因式。乘法形式使得这三个相关联并且一同训练的评估器挖掘数据的序列模式,同时在训练期间各自交互信息。除此之外,它保证了 p C V R pCVR pCVR的值在[0,1]。而在上述的除法中可能会超过1。
ESMM模型的损失函数被定为: L ( θ c v r , θ c t r ) = ∑ i = 1 N l ( y i , f ( x i ; θ c t r ) ) + ∑ i = 1 N l ( y i & z i , f ( x i ; θ c t r ) × f ( x i ; θ c v r ) ) ; ( 公式 3 ) L(\theta_{cvr},\theta_{ctr})=\sum_{i=1}^Nl(y_i,f(\mathbf{x}_i;\theta_{ctr}))+\sum_{i=1}^Nl(y_i\&z_i,f(\mathbf{x}_i;\theta_{ctr})\times f(\mathbf{x}_i;\theta_{cvr}));(公式3) L(θcvr,θctr)=i=1∑Nl(yi,f(xi;θctr))+i=1∑Nl(yi&zi,f(xi;θctr)×f(xi;θcvr));(公式3)其中 θ c t r \theta_{ctr} θctr和 θ c v r \theta_{cvr} θcvr是CTR和CVR网络的参数, l ( ⋅ ) l(·) l(⋅)是交叉熵损失函数。数学上,公式3将 y → z y \to z y→z分成两部分: y y y和 y & z y \& z y&z,在实践中利用点击和转化标签序列依赖。
注:上述所说的两部分是对应CTR和CTCVR任务分别使用数据集训练如下:1)全空间所有曝光组成的样本;2)对CTR任务,被点击标签 y = 1 y=1 y=1,否则 y = 0 y=0 y=0,对CTCVR任务,点击和转化事件同时发生标签 y & z = 1 y\& z=1 y&z=1,否则 y & z = 0 y\& z=0 y&z=0。
特征表示迁移。如章节2.2所述,表示层将大规模稀疏的输入数据映射成低维表示向量。它贡献了深度网络的大部分参数和需要学习的大量训练样本。在ESMM模型中,CVR网络的表示字典和CTR网络共享。它遵循特征表示学习迁移范式。CTR任务的训练样本相对CVR任务更多。参数共享机制使得ESMM中的CVR网络也能学习没有点击样本的信息,这对解决数据稀疏问题提供了很大的帮助。
ESMM模型中的子网络可以被最近提出的模型[2,3]取代,它们可能取得更好的结果,由于篇幅的限制,我们暂时忽略它,只关注解决现在CVR建模所遇到的实际挑战。
3 实验
3.1 实验配置
数据集。我们研究过程中,在CVR建模领域,没有点击和转化序列标签的公开数据集。为了评估ESMM模型,我们收集了淘宝推荐系统的流量日志,并且发布了整个数据集的1%随机采样版本(在没有压缩的情况下仍然有38G)。本文的剩余部分,我们涉及到发布的数据集,称之为公开数据集,和整个数据集,称之为生产数据集。表1概括了两个数据的统计结果。详细的描述可以在公开数据网站中找到。

对照组。我们利用几个CVR模型作为对照组进行实验。(1)BASE是一个在章节2.2中描述的基准模型。(2)AMAN[6]采用负采样策略,采样率在10%,20%,50%,100%中取得了最好结果。(3)OVERSAMPLING[11]复制正样本来缓解数据稀疏的问题,采样率在{2,3,5,10}。(4)UNBIAS 遵从[10]拟合真是数据分布,通过观察样本拒绝采样。 p C T R pCTR pCTR被视为拒接概率。(5)DIVISION分别训练CTR和CTCVR网络评估 p C T R pCTR pCTR和 p C T C V R pCTCVR pCTCVR,并且通过公式2计算出 p C V R pCVR pCVR。(6)ESMM-NS是一个轻量级的ESMM模型,没有表示层的参数共享。
前四个模型是CVR建模的不同变种,都直接基于最优的深度网络模型。DIVISION,ESMM-NS和ESMM来自同一个想法,全空间CVR建模,涉及到CTR,CTCVR以及CVR三个网络。ESMM-NS和ESMM同时训练三个模型,为了模型对比输出CVR网络结果。为了公平,所有模型包括ESMM使用和BASE模型相同的网络结构,以及超参数。1)使用RELU函数,2)表示向量的维度设置为18。3)多层感知机的网络结构设置成 360 × 200 × 80 × 2 360 \times 200 \times 80 \times 2 360×200×80×2。4)使用adam优化器,且参数为 β 1 = 0.9 , β 2 = 0.999 , ϵ = 1 0 − 8 \beta_1=0.9,\beta_2=0.999,\epsilon=10^{-8} β1=0.9,β2=0.999,ϵ=10−8。
评估标准。两个不同的任务作对比:(1)传统的CVR预测任务,在被点击数据集上评估 p C V R pCVR pCVR。(2)CTCVR预测任务,在全样本数据集上评估 p C T C V R pCTCVR pCTCVR。任务2主要是对比全空间样本作为输入的不同CVR模型效果,它反映了针对SSB问题各模型的性能。在CTCVR任务中,所有模型计算 P C T C V R PCTCVR PCTCVR都通过 p C T R × p C V R pCTR \times pCVR pCTR×pCVR,其中1) p C V R pCVR pCVR使用各自模型分别评估。2) p C T R pCTR pCTR使用相同的独立的CTR网络评估(相同的网络结构和超参数,如BASE模型)。两个任务都以时间序列划分前50%作为训练集,剩下的作为测试集。AUC作为模型性能评估指标,所有的模型重复10次然后算平均结果。
3.2 公开数据集上的结果
表2展示了公开数据上不同模型的实验结果。(1)BASE模型的三个变体中,只有AMAN的CVR任务表现的差一点,这可能是随机采样的敏感性导致的。OVERSAMPLING和UNBIAS在CVR和CTCVR任务上都比BASE模型好。(2)DIVISION和ESMM-NS模型在全空间上评估 p C V R pCVR pCVR,并且比BASE模型取得了显著的提升。由于避免了数据的不稳定问题,ESMM-NS的效果比DIVISION模型好。(3)ESMM模型比ESMM-NS模型效果好。通过挖掘用户行为的序列模式和未点击数据的迁移学习机制,ESMM模型提供了一个优美解决方法为CVR建模,并解决了SSB和DS问题,击败了所有的对照模型。对比BASE模型,ESMM在CVR任务中的AUC提高了2.56%,这表明即使对于有偏样本也能有较好的泛化性能。在全样本下的CTCVR任务,它带来了3.25%的AUC收益。这些结果验证了我们模型的有效性。
3.3生产数据集上的结果
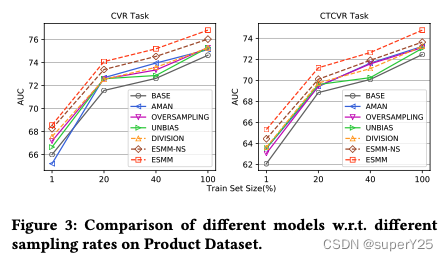
我还在生产数据集上评估了ESMM模型,生产数据包含89亿的样本,比公开数据集大了两个量级。为了验证大量训练集带来的影响,我们在大规模数据集上做了详细的对照实验,不同的采样率,如图3所示。首先,随着训练增加,所有模型的效果都提升了。这表明了数据稀疏的影响。所有的案例中除了AMAN的1%采样的CVR任务,BASE模型效果最差。第二,ESMM-NS和ESMM在所有采样率上都取得最优的效果。尤其是ESMM模型,在CVR和CTCVR任务上AUC相对其他模型维持较大的优势。BASE模型是最新版本并在我们现实系统中服务于主要流量。使用整个数据集训练,ESMM模型较BASE模型在CVR任务获得了绝对AUC2.18%的提升,CTCVR任务2.32%的提升。这对于0.1%收益都显著的工业应用来说无疑是重大的提升。

总结和展望
本文中,我们为CVR建模任务提出一个新颖的方法ESMM模型。ESMM模型充分利用了用户行为序列模式。通过CTR和CTCVR两个辅助任务,ESMM很好的解决了现实应用中CVR建模遇到的SSB和DS问题。运用实际数据集的实验展示了ESMM模型非常好的性能。本方法可以简单的被应用到序列依赖场景的用户行为预测。在未来,我们计划设计全局的优化模型应用于多阶段行为场景,如请求–> 展示–>点击 --> 转化。
参考文献
[1] Olivier Chapelle. 2014. Modeling delayed feedback in display advertising. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 1097–1105.
[2] Heng-Tze Cheng and Levent Koc. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 7–10.
[3] Zhou G., Song C., et al. 2017. Deep Interest Network for Click-Through Rate Prediction. arXiv preprint arXiv:1706.06978 (2017).
[4] Zhu H., Jin J., et al. 2017. Optimized cost per click in taobao display advertising.In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2191–2200.
[5] Lee K., Orten B., et al. 2012. Estimating conversion rate in display advertising from past erformance data. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM.
[6] RongPan,YunhongZhou,BinCao,NathanNLiu,RajanLukose,MartinScholz, and Qiang Yang. 2008. One-class collaborative filtering. In Data Mining, 2008.ICDM’08. Eighth IEEE International Conference on. IEEE, 502–511.
[7] Sinno Jialin Pan and Q. Yang. 2010. A Survey on Transfer Learning. In IEEE Transactions on Knowledge and Data Engineering. 1345–1359.
[8] Steffen Rendle. 2010. Factorization machines. In Data Mining (ICDM), 2010 IEEE 10th International Conference on. IEEE, 995–1000.
[9] Sebastian Ruder. 2017. An overview of multi-task learning in deep neural net-works. arXiv preprint arXiv:1706.05098 (2017).
[10] Zhang W., Zhou T., et al. 2016. Bid-aware gradient descent for unbiased learning with censored data in display advertising. In Proceedings of the 22nd International Conference on Knowledge Discovery and Data Mining. ACM.
[11] Gary M Weiss. 2004. Mining with rarity: a unifying framework. ACM Sigkdd Explorations Newsletter 6, 1 (2004), 7–19.
[12] BiancaZadrozny.2004.Learningandevaluatingclassifiersundersampleselection bias. In Proceedings of the 21th international conference on Machine learning. ACM.
提几个问题:
1、本文模型提出的背景是什么?为什么要提出ESMM模型。
2、出现SSB问题的原因?
3、ESMM模型为什么不使用公式2而使用将 p C V R pCVR pCVR作为中间变量的公式1?
4、如何解决数据稀疏(DS)问题?
5、可以研究一下参考文献中的[2,3],替换ESMM模型的子网络,验证一下是否如论文中猜想的一下,能提高效果?
-
相关阅读:
仙人掌之歌——权力的游戏(2)
o.s.b.d.LoggingFailureAnalysisReporter 错误解决方法
二、PHP序列化与反序列化
docker命令整理
C++的explicit是什么?
一种数字全息自动聚焦技术研究及实例分析
async...await在tcp通讯中的正确用法
初步了解ES7-ES12
【servelt原理_9_servlet应用___】
互融云商业保理系统开发|产品成熟,已服务上千家保理企业
- 原文地址:https://blog.csdn.net/superY_26/article/details/126498913