-
服务器宕机了,数据会丢失吗
对于Kafka有三个问题:数据丢失、数据重复、数据顺序。
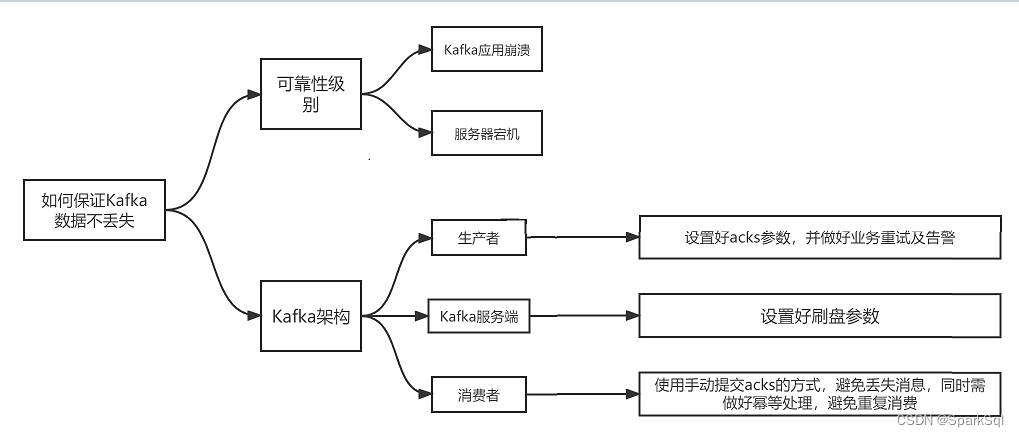
可靠性级别
无法保证Kafka数据不丢失,只能保证某种程度下Kafka数据不丢失。因此,我们根据业务的重要程度,设置合理的可靠性级别,可靠性级别越高,付出的成本越高。
从大局看Kafka
要让 Kafka 消息不丢失,那么我们必须知道 Kafka 可能在哪些地方丢数据,因此弄清楚 Kafka 消息流转的整个过程就非常重要了。对 Kafka 来说,其整体架构可以分为生产者、Kafka 服务器、消费者三大块。
生产者
对生产者来说,其发送消息到 Kafka 服务器的过程可能会发生网络波动,导致消息丢失。对于这一个可能存在的风险,我们可以通过合理设置 Kafka 客户端的
request.required.acks参数来避免消息丢失。该参数表示生产者需要接收来自服务端的 ack 确认,当收不到确认或者超市时,便会抛出异常,从而让生产者可以进一步进行处理。该参数可以设置不同级别的可靠性,从而满足不同业务的需求,其参数设置及含义如下所示:
- request.required.acks = 0 表示 Producer 不等待来自 Leader 的 ACK 确认,直接发送下一条消息。在这种情况下,如果 Leader 分片所在服务器发生宕机,那么这些已经发送的数据会丢失。
- request.required.acks = 1 表示 Producer 等待来自 Leader 的 ACK 确认,当收到确认后才发送下一条消息。在这种情况下,消息一定会被写入到 Leader 服务器,但并不保证 Follow 节点已经同步完成。所以如果在消息已经被写入 Leader 分片,但是还未同步到 Follower 节点,此时Leader 分片所在服务器宕机了,那么这条消息也就丢失了,无法被消费到。
- request.required.acks = -1 表示 Producer 等待来自 Leader 和所有 Follower 的 ACK 确认之后,才发送下一条消息。在这种情况下,除非 Leader 节点和所有 Follower 节点都宕机了,否则不会发生消息的丢失。
如上所示,如果业务对可靠性要求很高,那么可以将
request.required.acks参数设置为 -1,这样就不会在生产者阶段发生消息丢失的问题。kafka服务器
当 Kafka 服务器接收到消息后,其并不直接写入磁盘,而是先写入内存中。随后,Kafka 服务端会根据不同设置参数,选择不同的刷盘过程,这里有两个参数控制着这个刷盘过程:
- # 数据达到多少条就将消息刷到磁盘
- #log.flush.interval.messages=10000
- # 多久将累积的消息刷到磁盘,任何一个达到指定值就触发写入
- #log.flush.interval.ms=1000
如果我们设置 log.flush.interval.messages=1,那么每次来一条消息,就会刷一次磁盘。通过这种方式,就可以降低消息丢失的概率,这种情况我们称之为同步刷盘。 反之,我们称之为异步刷盘。与此同时,Kafka 服务器也会进行副本的复制,该 Partition 的 Follower 会从 Leader 节点拉取数据进行保存。然后将数据存储到 Partition 的 Follower 节点中。
对于 Kafka 服务端来说,其会根据生产者所设置的
request.required.acks参数,选择什么时候回复 ack 给生产者。对于 acks 为 0 的情况,表示不等待 Kafka 服务端 Leader 节点的确认。对于 acks 为 1 的情况,表示等待 Kafka 服务端 Leader 节点的确认。对于 acks 为 1 的情况,表示等待 Kafka 服务端 Leader 节点好 Follow 节点的确认。但要注意的是,Kafka 服务端返回确认之后,仅仅表示该消息已经写入到 Kafka 服务器的 PageCache 中,并不代表其已经写入磁盘了。这时候如果 Kafka 所在服务器断电或宕机,那么消息也是丢失了。而如果只是 Kafka 服务崩溃,那么消息并不会丢失。
因此,对于 Kafka 服务端来说,即使你设置了每次刷 1 条消息,也是有可能发生消息丢失的,只是消息丢失的概率大大降低了。
消费者
对于消费者来说,如果其拉取消息之后自动返回 ack,但消费者服务在处理过程中发生崩溃退出,此时这条消息就相当于丢失了。对于这种情况,一般我们都是采用业务处理完之后,手动提交 ack 的方式来避免消息丢失。
在我们在业务处理完提交 ack 这种情况下,有可能发生消息重复处理的情况,即业务逻辑处理完了,但在提交 ack 的时候发生异常。这要求消费者在处理业务的时候,每一处都需要进行幂等处理,避免重复处理业务。
能不丢失吗?
kafka只能做到应用崩溃这个级别,如果服务器宕机,即使设置了每来一条消息就写入一次磁盘,那么也有可能在写入 PageCache 后、写入磁盘前这个关键点,服务器发生宕机。这时候 PageCache 里面的消息数据就没了,那么消息自然也就丢失了。但如果仅仅是 Kafka 应用崩溃退出,因为其已经写入到 PageCache 中了,那么系统自然会将其写入到磁盘中,因此消息并不会丢失。
-
相关阅读:
快速找到需要包含函数的头文件
DFS与DFT的关系,以及DFT与DCT的关系
获取当周和上周的周一、周日时间
学网络安全可以参考什么方向?该怎么学?
第九篇、线程同步(解决并发问题)
Keepalived+LVS负载均衡
如何查看项目中使用的Qt版本
CADEditorX ActiveX 14.1.X
0029__时钟分频原理 - 时钟分频原理详解
湖北工业大学计算机考研资料汇总
- 原文地址:https://blog.csdn.net/m0_57320261/article/details/126605758