-
【Linux】进程概念
本文演示所用系统为
CentOS 7.61.操作系统
操作系统是不会直接对用户提供服务的。因为这样会暴露自己的底层实现,对系统稳定性造成了威胁

操作系统是通过系统调用层的方式对外提供接口服务的。
这就好比你是通过前端按钮来使用一个网站的功能,而通常你是看不到网页的后端实现的。
Linux系统的底层是用C语言写的,所以这些接口服务本质上就是一些C语言的函数。这些函数用于操作系统的各种管理。
我们学习Linux的系统编程,本质上是在学习这些和系统对接的函数。
1.1 编程语言和系统对接
不同的操作系统,其提供的各种管理硬件的函数是不同的。这时候我们的C/C++等其他语言想和系统对接(如
printf打印到屏幕上)就需要在底层帮用户管理好这些系统接口的调用。当我们使用这些语言的时候,就不需要自己手动去调用1.2 描述进程-PCB
PCB并不是那些绿油油的电路板,这里指的是
process control block进程是有一个担当分配系统资源(CPU时间,内存)的实体
- 进程信息被放在一个叫做
进程控制模块的数据结构中,可以理解为进程属性的集合 - 在Linux中的PCB其实就是一个结构体
task strcut,包含了这个进程的各种信息。
task_struct的内容大家可以上网搜搜,能力强的朋友可直接去看Linux的源码。1.3 组织进程
我们可以在Linux的源码中找到组织进程的方式。所有运行在系统里面的进程都是以
task_struct为成员的链表形式存在内核中。下面是关于这个结构体的一部分解析- 标示符: 描述本进程的唯一标示符,用来区别其他进程
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据
- I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
相关解析可以看看这篇博客【传送门】
1.4 查看进程
1.4.1 ps命令
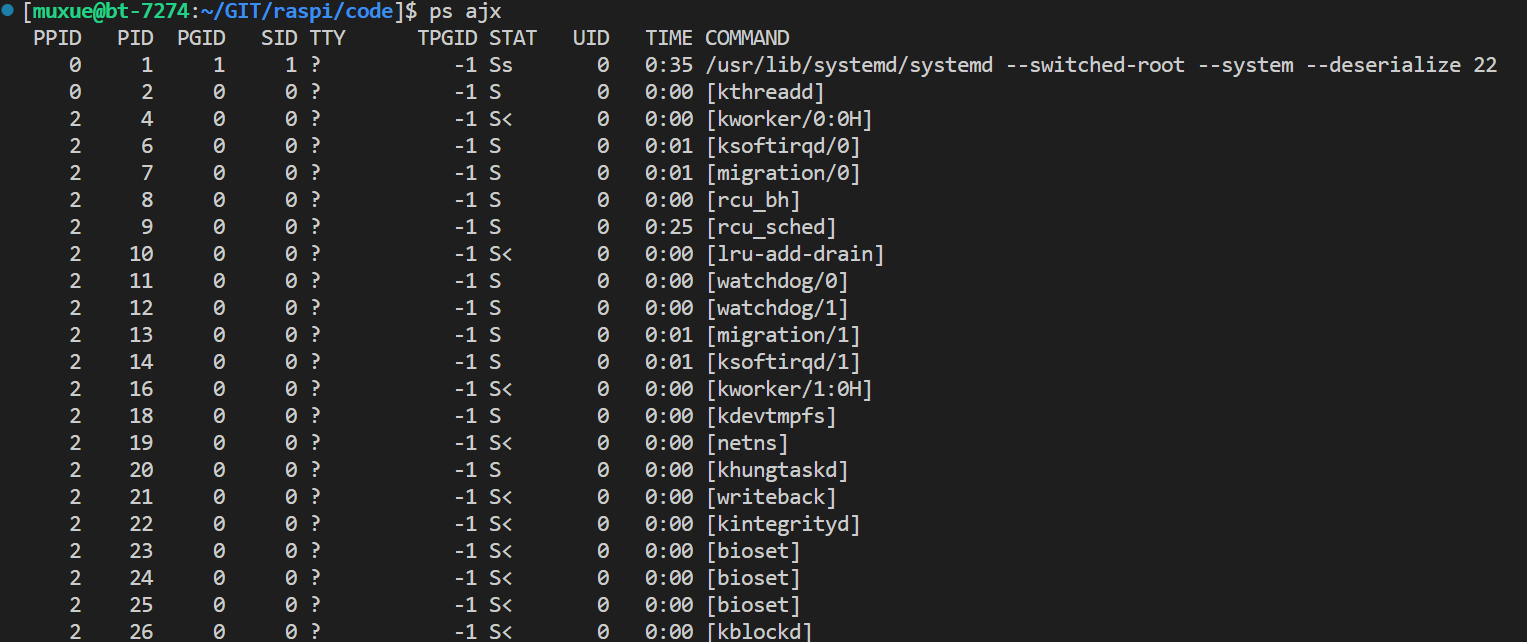
可以用ps命令来查找进程信息。下面这个指令是显示所有的进程
ps axj- 1
系统会打印下面的很多进程信息,这就好比windows下的任务管理器
如果我们使用一个
while(1)的死循环函数,运行的时候就变成了一个进程了。我们可以用下面的命令来查找特定的进程信息ps axj | grep test- 1
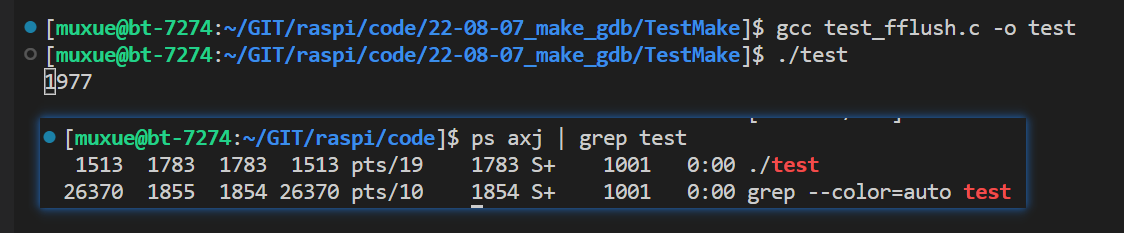
上图中我们搜索test,出现了两个进程。第一个进程很明显是我们运行的可执行程序。那么第二个是什么呢?
实际上,所有的指令都是一个进程。只不过
ls这种类型的命令很快就能执行完毕。这样一来,我们便可以确认,出现的第二个进程实际上是我们执行这条搜索语句出现的。可以用下面的这个指令来屏蔽grep的结果,只显示我们自己的那个程序。
ps axj | grep test | grep -v grep- 1
最后一个指令的意思是忽略掉包含
grep的结果,现在就不会显示第二个grep的进程了
1.4.2 proc目录
还可以通过
/proc系统文件夹来查看系统进程信息。这里面的内容都是一个实时的进程信息
每一个进程都有一个自己的
PID(process id),用来标识唯一的进程可以用下面的这个指令来显示一个提示信息,其中的
&&代表逻辑与,只有第一个命令执行成功,才会执行第二个命令ps ajx | head -1 && ps ajx | grep test | grep -v grep- 1

这里就告诉我们了这个命令的
PID是什么,即第2位数字
如果你需要查看
PID为1的进程,则打开对应进程的文件夹
上面我们搜到的进程
PID为5408,查看对应文件夹可以看到下面的内容
当我们关闭了
./test进程在去查找,会发现没有这个路径了
在每一个进程文件夹中都有一个
cwd和execwd其指向的是进程当前的工作路径exe指向的是进程对应可执行程序的磁盘文件
比如现在我使用
ps命令查找到了下面这个python代码进程
使用
ls -l /proc/19423命令打开对应文件夹,便可以看到cwd和exe的指向
这代表该进程是用
python3.10进行执行的,其工作目录为cwd指向的路径pid、工作路径等等信息都存放在进程的
task_struct中1.4.3 C语言代码获取ppid和pid
除了在命令行中输入命令以外,我们还可以通过C语言代码中和系统通信的库函数来获取当前进程的
ppid和pid#include#include #include int main() { printf("pid: %d\n", getpid()); printf("ppid: %d\n", getppid()); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
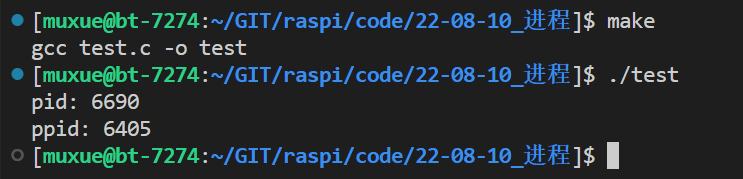
使用一个
while(1)循环,我们就可以看看这个进程是否和我们用ps搜出来的结果相同
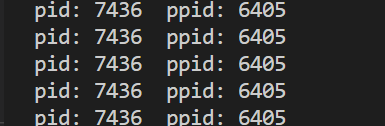
可以看到,搜寻出来的结果和该程序自己打印的结果是一样的
实际上,我们所有在命令行上执行的程序,都是
bash(即当前命令行)的子进程
1.5 fork 通过系统调用创建父子进程
如果你用过gitee或者github,想必对fork并不陌生。在git托管网站上,我们fork别人的仓库,便会在自己的账户中出现一个别人仓库的“子仓库”。我们可以在这个“子仓库”里面修改一部分信息,再创建一个
pull request合并入被fork的仓库而在Linux系统中,fork的作用便是可以创建一个父子进程,这两个进程相互独立,且有很多特殊的地方等着我们的探索
比如:fork具有两个不同的返回值!
下面是一个示例代码
#include#include #include int main() { pid_t id = fork(); //id=0 子进程;>0为父进程 if(id == 0) { //child while(1) { printf("子进程,pid: %d, 父进程是: %d\n", getpid(), getppid()); sleep(1); } } else{ //parent while(1) { printf("父进程,pid: %d, 父进程是: %d\n", getpid(), getppid()); sleep(1); } } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
运行上面的代码,你会发现父子进程竟然交叉运行了!而且这两个进程都有不同的pid。其中子进程的
ppid即为父进程的pid!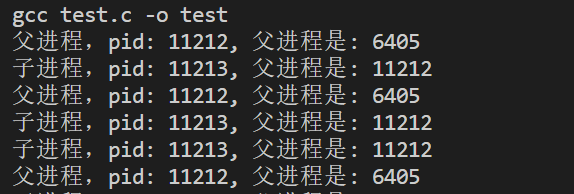
奇怪,我们的while循环明明是写在if里面的啊?为什么else里面的while也被正常执行了呢?
1.5.1 man fork
这便需要我们了解一下
fork到底是何方神圣了。man fork- 1
如果你出现
No manual entry for fork的报错,在CentOS下请尝试执行下面的命令sudo yum install -y man-pages- 1
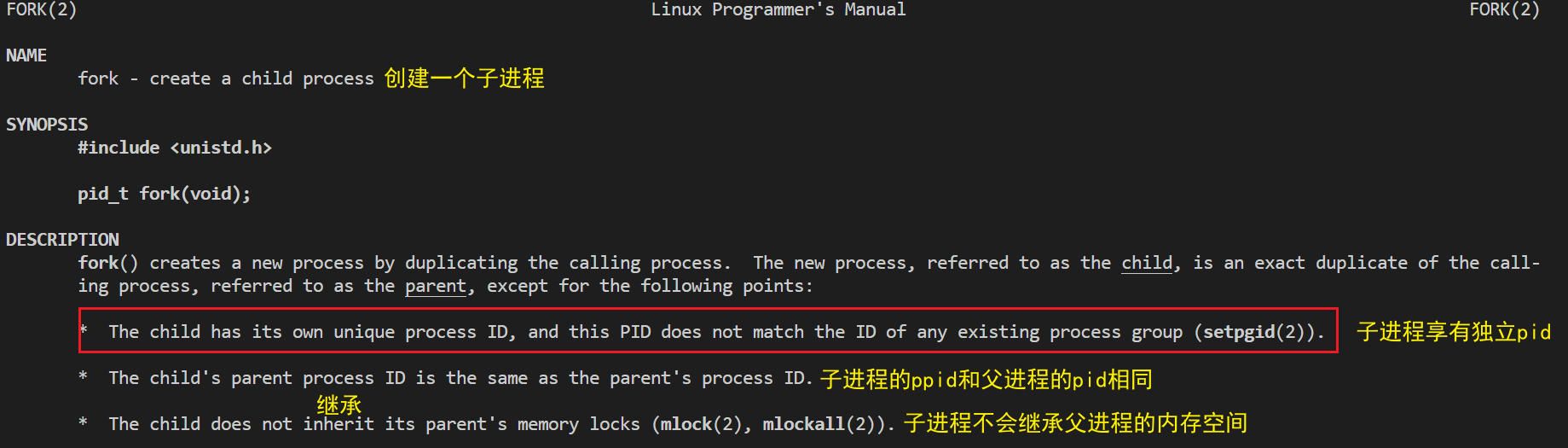
同时可以看到关于fork的返回值的描述

这便能告诉我们,为啥fork下方同一个id值使用打印会返回不同的结果;以及
if else被交叉运行的原因。- fork之后,父子进程共享代码,都会执行后面的
if else语句 - fork之后,父子进程的返回值不相同,所以
if else语句进入的模块也不相同
fork进程给父进程返回
子进程pid,方便父进程管理自己的子进程。这是因为父进程必须要有标识子进程的方法!- 一个父亲可以有多个孩子,需要pid来进行管理
- 一个子进程只能有1个父亲,所以用0来标识子进程创建成功即可。它可以用
ppid方便的找到自己的父进程。
1.5.2 fork做了什么
fork会调用系统的
OS system call,创建一个子进程- task_struct + 父进程代码和数据
- task_struct + 子进程代码和数据
子进程的代码和数据大多数都是从父进程继承下来的,不过pid和ppid肯定不会继承。其内部的
变量/数据和父进程独立(这个后续的博客会涉及)- 当fork创建好子进程并进行
return的时候,它的功能就已经完成了 - 此时还会将子进程放入运行队列
了解了这个之后,再来理解一下进程是如何被运行的👇
2. 如何理解进程被运行
在我们的系统中,每一个CPU都有一个
运行队列这个运行队列之中存放的便是
task_struct,系统会依次运行每一个进程。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tZYhum7e-1663982430474)(https://img-7758-typora.oss-cn-shanghai.aliyuncs.com/img1/202208301124680.png)]
在上面我们的fork创建子进程之后,便会把子进程放入运行队列
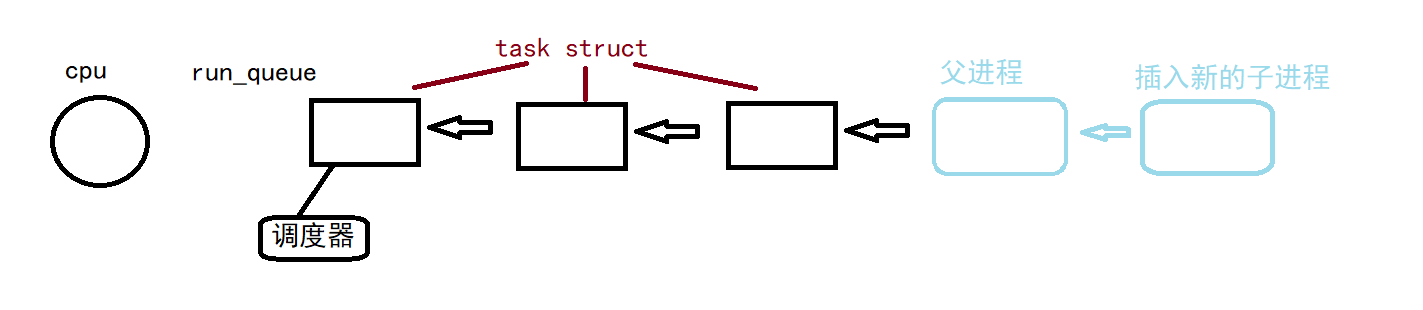
所以实际上,fork并不是有两个返回值,而是在先运行了父进程后,又创建了一个子进程。这两个进程共享代码,而且它们都是挂载在同一个
bash命令行上,才会出现上述交替打印的情况。
结语
下篇博客是有关
进程状态的内容,阿巴阿巴,好久没写博客了
- 进程信息被放在一个叫做
-
相关阅读:
asp.net文档管理系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
【JavaWeb】Http协议及Servlet快速入门
musescore 构建入门
知识注入以对抗大型语言模型(LLM)的幻觉11.6
JDK中的Set和Map解析
Qt绘制椭圆曲线的角度问题(离心角和旋转角)
CSS :has伪类
限流模块再理解
php代码审计
极速系列04—python批量获取word中的表格
- 原文地址:https://blog.csdn.net/muxuen/article/details/126601234
