-
日志收集分析平台项目-2-项目原理
目录
ISR -- 集合列表 -- in-sync-replica
零碎概念
怎么实现高可用:
- 硬件层面
- 多块网卡 -- 物理层面两块网卡 -- 逻辑层面一块网卡
- 磁盘 -- 磁盘阵列
- 架构层面
- 引入集群
- 异地多活
目前主流的消息中间件
kafka、ActiveMQ、RocketMQ、RabbitMQ
消息中间件的两种通信方式
- 点对点:生产者消费者一一对应,消费者消费完,消息中间件就没有了
- 发布订阅:类似公众号
kafka消息中间件通常用于
- 日志收集
- 业务解耦
- 流量削峰
版本问题
此次项目使用的kafka版本是2.12版本,此版本的kafka需要依靠zookeeper
kafka3.0版本以后已经脱离了zookeeper,kafka能自己实现zookeeper功能
项目描述
通过前端nginx集群收集的访问日志,解析出日志中ip所属的省份、运营商等信息存入数据库
nginx集群、filebeat
在项目中,配置了三台nginx应用集群,在用户和nginx应用集群中间,加入了两台nginx代理集群
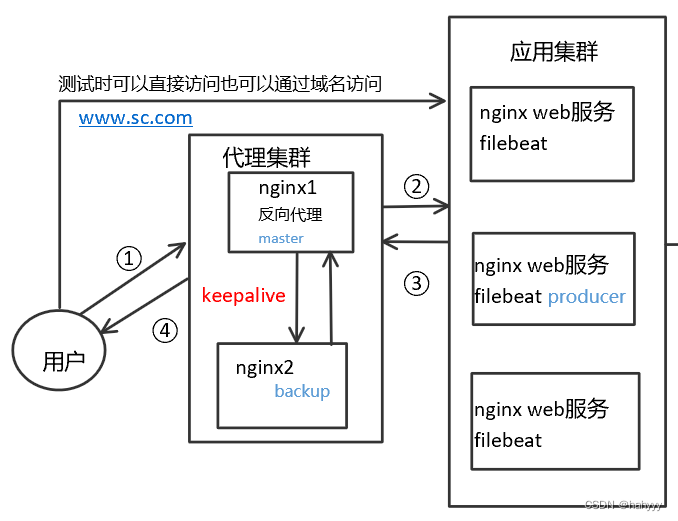
为什么要搭建nginx反向代理集群
例如www.sc.com可以解析成多个IP地址,一般来说会使用轮询的方式去解析成各个IP
但是如果其中一个其中一个服务器挂了,DNS不会立马将这个IP地址去掉,还是会解析成挂掉的IP,可能会造成访问失败,虽然客户端有重试,但还是会影响用户体验
所以在应用web前面加反向代理,安全性也会增加,负载均衡的控制也会容易很多
反向代理和正向代理
反向代理是充当web服务器网关的代理服务器
当请求发送到使用反向代理的web服务器时,会将请求先转到反向代理,由该代理确定是将其路由到web服务器还是将其阻止
有了反向代理,用户永远不会与它使用的web服务器进行直接通信
通过负载均衡和缓存,可以保护web免遭攻击,并提供更好的性能
正向代理:客户端和原始服务器之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标 (原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给服务器
反向代理是代理服务器,正向代理是代理客户机
keepalive原理
keepalive是基于一个vrrp(虚拟路由冗余协议)去做的,用于高可用。
假如给nginx1的虚拟IP是1.5(设为master),nginx2的虚拟IP是1.6(设为backup)
两个机器会同时运行keepalive协议,假如master没挂掉,1.5会在nginx1上,若master挂掉了,1.5会去nginx2上,除非两台都挂掉了,否则IP地址不会掉
如果master在工作的话,backup哪怕在正常状态下也是不会工作的,只有50%的利用率。
为了提高利用率,使用双VIP地址:nginx1的1.5是master,1.6是backup;nginx2的1.6是master,1.5是backup,域名就解析成两个虚拟IP地址,一个1.5一个1.6,避免空闲backup。
若nginx1的master挂掉了,就会飘到nginx2上,nginx2上就有两个IP地址。
优点:两个反向代理机使用keepalive双VIP互为主备做高可用
为什么要使用filebeat
filebeat在这里的作用就是将nginx收集到的用户访问信息统一收集起来交给kafka
kafka集群
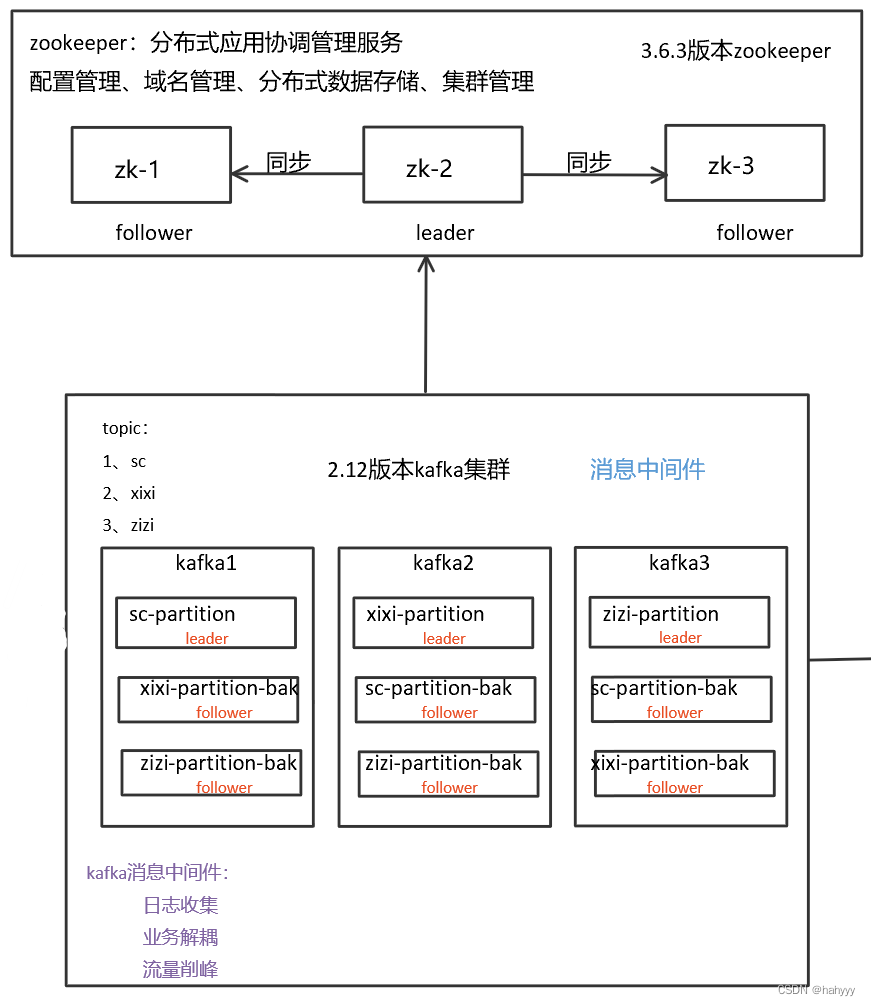
为什么要使用kafka
统一收集的好处:
- 如果出现故障,不用一台台去登录nginx去查找故障,统一收集方便定位问题
- 后续需要日志的程序直接从kafka获取日志即可,尽可能的减少日志处理对nginx的影响
- 减少对数据库的访问
kafka里的一些元素
- broker:kafka节点,每一台机器就是一个broker
- topic:主题,消息的类别,消息的分类
- 比如nginx日志、mysql日志给不同的主题,就是不同的类型
- partition:分区
- 一般来说有几个broker就设置几个partition
- 提高吞吐量、提高并发
- 多个partition会造成消息顺序混乱,如果对消息顺序有要求就只设置一个partition就可以了
- replica:副本
- kafka里的高可用,就是完整的分区备份
- broker数量如果和replica一致,可以坏掉n-1台
kafka如何保证高可用
多个broker + 多个partition + 多个replica
ISR -- 集合列表 -- in-sync-replica
需要同步的follower集合
比如有5个副本,将1个leader、4个follower写进ISR,如果一个follower挂了,那就从这个列表里删除了,如果一个follower卡住或者同步过慢,也会从ISR里删除,如果有一个机器宕机,后续启动后想要加入ISR,必须得同步到其他机器得HW值
kafka可以按照两个维度清理数据
- 按大小
- 按时间
任意一个条件满足,都可以触发日志清理
zookeeper是什么
分布式应用协调管理服务,用于配置管理、域名管理、分布式数据存储、集群管理
zookeeper是怎么选举的
zookeeper采取一致性算法进行选举,相当于少数服从多数,投票票数过半当选为leader
zookeeper不是强一致性,它是属于最终一致性
zookeeper数据同步
客户端连接任意一台zk都可以操作,但是数据的增删改查等操作都必须在leader上操作
如果客户端不在leader上,follower会返回给leader的IP,最终客户端还是在leader上操作
可以直接连接follower进行查询操作,数据的同步,只要过半节点同步完成,表示数据已经commit
每个节点数据量默认不超过1M
zk集群中,节点存活数必须过半,集群才能正常使用
zk在kafka中的作用
- 保存kafka的元信息、topic、partition、副本信息
- 选举kafka controller,通过抢占的方式来选出controller
- 选举出的kafka controller管理kafka副本的leader、follower、同步和选举
如何保证数据的一致性
生产者层面
- producer可以通过设置request.required.acks来实现
- acks=0:生产者不会等待任何来自服务器的响应
- acks=1:默认值,只要集群的leader节点收到消息,生产者就会收到一个来自服务器的成功响应
- acks=-1:当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应,这个是最安全但效率最慢的
消费者层面
- 消费者消费数据时,引入了High Water Mark机制,也就是木桶短板效应
- 消费者只能消费到ISR列表里偏移量最少的副本的消息数量
生产者和消费者只和leader打交道,leader再根据ISR同步给其他follower
生产者怎么知道那台是leader呢?
生产者发送消息的时候随机挑选任意一台都可以,中间会有协商,这个broker会返回副本leader的信息,生产者再跟leader交互
消费组
一个消费组里面可以有多个消费者,同一个消费组里面的消费者在同一时刻只能消费一个partition
可以有多个消费组,不同的消费组之间互不干扰
消费者如何知道自己消费到了哪里
offset,会记录消费者消费的偏移量
python清洗数据存入数据库
使用python编写脚本,将日志中的省份、运营商等信息清洗出来,存入数据库
此处脚本就没有粘贴上来了
整体大图

- 硬件层面
-
相关阅读:
为什么会出现,HR到处抱怨招不到测试员,测试员到处抱怨市场饱和,找不到工作?
React核心原理与实际开发
如果客户端禁止 cookie,session 还能用吗?
利用TreeMap来达成离散化的目的
Scrapy入门
当酷雷曼VR直播遇上视频号,会摩擦出怎样的火花?
查重的标准是什么?
小程序面试题
数据库课程设计——学籍管理系统
S7-200 SMART PLC 子程序功能块(阀门控制)
- 原文地址:https://blog.csdn.net/weixin_57475485/article/details/126593382