-
【CSAPP:3 计算机系统】课堂笔记 Computer Systems from a Programmer’s Perspective
第一章 简介
「软件」如何由代码得到程序?

- 预处理阶段:将源程序
test.c进行预处理成test.i,例如将头文件、宏命令补全等等 - 编译阶段:编译器将文本文件翻译成文本文件
test.s包含了一个汇编语言程序 - 汇编阶段:汇编器将汇编语言程序翻译成机器语言指令
test.o - 链接阶段:将函数等单独预编译的目标文件合并到主程序中,得到可执行文件
「硬件」计算机如何运行程序?
硬件组成
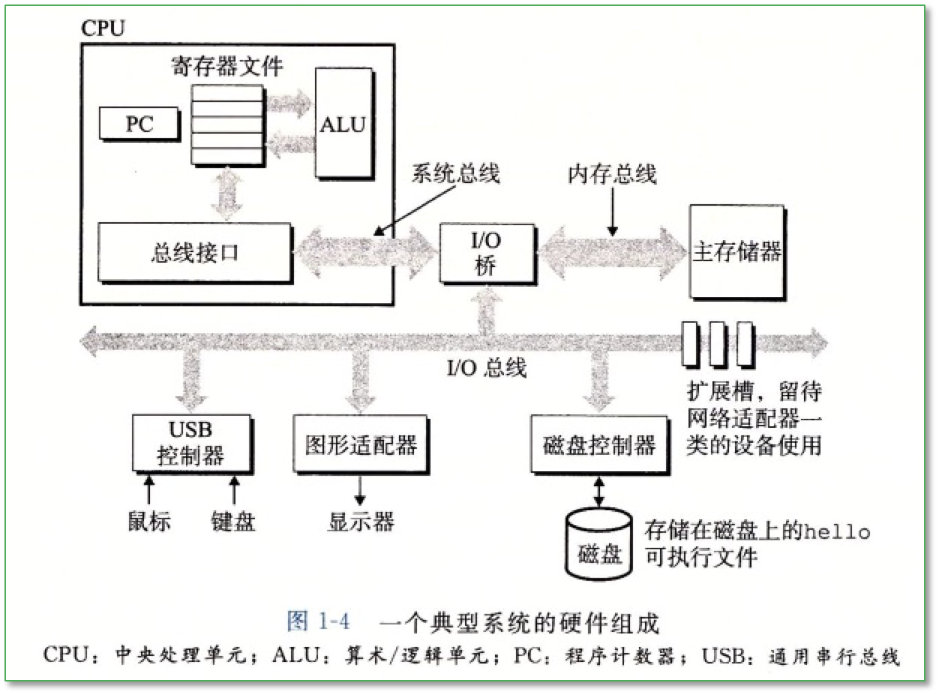
-
总线
- 字(word),字长
-
I/O 设备
-
输入/输出
-
控制器、适配器
-
-
主存
-
存放程序指令和数据
-
一个字节数组,每字节具有唯一地址
-
-
处理器
-
解释(执行)指令
-
程序计数器(PC)指向内存中某条指令
-
执行操作:加载、存储、操作(运算)、跳转
-
hello.c程序运行样例:- 读取
hello命令

- 从磁盘加载可执行文件到主存

- 从主存输出字符串到显示器

储存器层次结构 Memory Hierarchy

上一层的存储器作为下一层储存器的高速缓存
「抽象表示」
操作系统抽象层次

- 文件——I/O设备
- 虚拟内存——程序储存器
- 进程——正在运行程序
- 虚拟机——整个计算机
几个抽象概念
-
进程

-
线程
-
-
文件
Amdahl定律
当我们对系统某个部分加速时,其对系统整体性能的影响取决于该部分的重要性和加速程度。
加速比计算: S = 1 ( 1 − α ) + α / k S={1\over(1-α)+α/k} S=(1−α)+α/k1
α : 该部分占比时间 ; k : 性能提升比例 \alpha : 该部分占比时间; k : 性能提升比例 α:该部分占比时间;k:性能提升比例
并发与并行
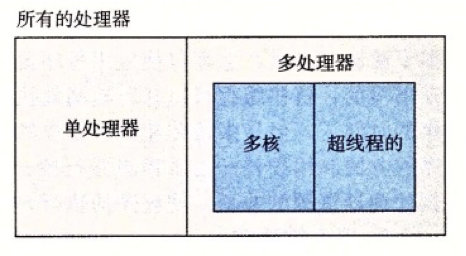
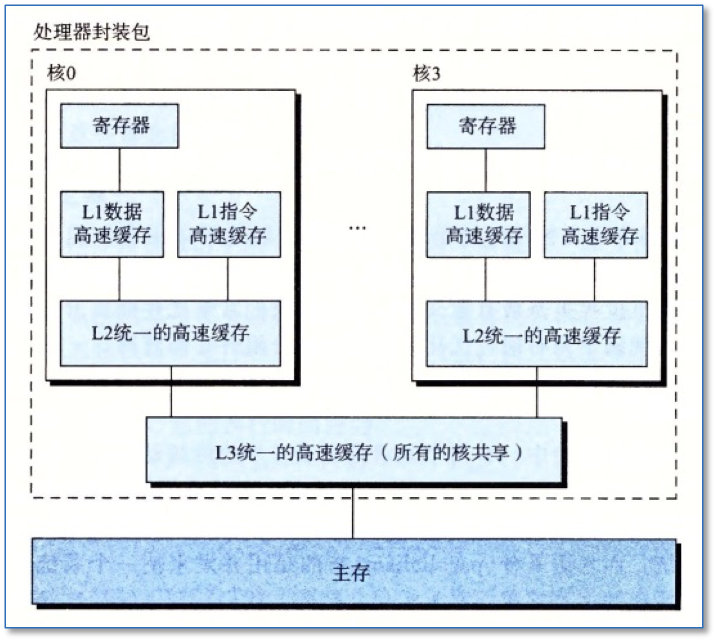
- 线程级并发
- 线程
- 单处理器
- 多核处理器
- 超线程
- 指令级并行
- 流水线
- 超标量
- 单指令、多数据并行
- SIMD
- 视音频处理
第二章 信息的表示与处理
2.1 信息储存
字数据大小

寻址和字节顺序
- 一个block为8位,是两个十六进制数值。
- 跨越多个字节的程序对象如何在内存中储存?
- 连续的字节序列
- 地址为所有字节中最小的地址
- 大端法与小端法
- 大端法:最高有效字节在最前面
- 小端法:最低有效字节在最前面
C语言中的位级运算
应用 - 掩码运算
0屏蔽,F取值。
移位运算
- 左移运算
x << k: 右端补 k k k个 0 0 0 - 右移运算
x >> k- 逻辑右移(
unsigned):左端补 k k k个 0 0 0 - 算术右移(
signed):左端补 k k k个原最高位值
- 逻辑右移(
2.2 整数表示
无符号数的编码 B 2 U w ( ) B2U_w() B2Uw()
Binary to Unsigned int:

- 按正常位进行权运算
- 范围: [ 0 , 2 w − 1 ] [0,2^w-1] [0,2w−1]
补码编码 B 2 T w ( ) B2T_w() B2Tw()
Binary to Two’s-complement:

-
除去最高位取负号运算以外,其他位按权运算
-
最高位决定了符号(可以以符号位进行理解), 1 1 1为负
-
非负数时 B 2 U w B2U_w B2Uw 和 B 2 T w B2T_w B2Tw 值相同
-
范围: [ − 2 w − 1 , 2 w − 1 − 1 ] [-2^{w-1},2^{w-1}-1] [−2w−1,2w−1−1]
-
000...000 = 0 000...000=0 000...000=0; 111...111 = − 1 111...111=-1 111...111=−1
有符号数和无符号数之间的转换 T 2 U w ( ) T2U_w() T2Uw() & U 2 T w ( ) U2T_w() U2Tw()



- 减掉最高位的权+1

- 加上最高位的权+1
C语言中的有符号数和无符号数
当表达式中的
unsigned和signed混用时,signed将被强制转换为unsigned注意:
sizeof()本身就是unsigned long下面这个例子将会发生内存错误:
unsigned i; for (i = n - 1; i >= 0; --i) // i 总是大于零,无法跳出循环 f(a[i]);- 1
- 2
- 3
扩展一个数字的位表示
无符号数
零扩展
有符号数
符号扩展,假如是负数,扩展 1 1 1;假如是正数,扩展 0 0 0
- 在C语言中,遇到符号、大小同时需要转换的情况,先转换大小,最后转换符号
截断数字
删除最高位。本质上其实是取模运算。 补码运算来说,如果最高位有很多个重复的
1,则可以删除前面的进行运算。2.3 整数运算
无符号加法
定义: w w w 位无符号整数 x x x, y y y 之和:将 x + y x+y x+y 截断成 w w w 位后的无符号数。
溢出:发生了截断的操作。


运算符: + w u +_w^u +wu
无符号数求反: − w u -^u_w −wu

/* 检测是否会溢出的函数 */ int uadd_ok(unsigned int x, unsigned int y) { unsigned int sum = x + y; return sum >= x; }- 1
- 2
- 3
- 4
- 5
- 6
补码加法
定义: w w w 位补码数 x x x, y y y 之和:将 x + y x+y x+y 截断成 w w w 位后的补码数。
运算符: + w t +_w^t +wt


/* 检测是否会溢出的函数 */ int taad_ok(int x, int y) { int sum = x + y; int neg_over = x < 0 && y < 0 && sum >= 0; int pos_over = x >= 0 && y >= 0 && sum < 0; return !neg_over && !pos_over; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
补码的非

运算符: − w t -_w^t −wt
− x = -x= −x= ~ x + 1 x+1 x+1
无符号乘法
运算符: ∗ w u *_w^u ∗wu
做法:按位乘法运算之后,截取最低的 w w w 位

补码乘法
运算符: ∗ w t *_w^t ∗wt
做法:按位乘法运算之后,截取最低的 w w w 位

低位等价性:补码与无符号的乘法产生的位模式相同
/* 检查是否溢出的函数 */ int tmult_ok(int x, int y) { int p = x * y; return !x || p / x == y; }- 1
- 2
- 3
- 4
- 5
- 6
乘以常数
乘以二的幂: x 2 k x2^k x2k =
x << k乘以不是二的幂 –> 乘法分配律拆成二的幂相加/减的形式
除以 2 2 2 的幂
对于无符号数来说,
x >> k逻辑右移,可以产生数值 ⌊ x / 2 k ⌋ \lfloor x/2^k \rfloor ⌊x/2k⌋;这个操作是向零舍入的。对于补码数来说,
x >> k算术右移,来产生数值 ⌊ x / 2 k ⌋ \lfloor x/2^k \rfloor ⌊x/2k⌋;这个操作对负数是向下舍入的,不好🙅。因此使用偏置(偏量为 y − 1 y-1 y−1 )来解决:(x + (1 << k) - 1) >> k;这个操作对负数是向零舍入的,好!总结就是:x < 0 ? (x + (1 << k) - 1) >> k) : (x >> k)。2.4 浮点数
二进制小数
- 二进制中,小数点左移一位相当于除以2,小数点右移一位相当于乘以2
- 使用近似表示的方法进行
IEEE 浮点表示
数值表示形式
( − 1 ) s M 2 E (-1)^s\ M\ 2^E (−1)s M 2E
其中, s s s为符号位, E E E为阶码(exp), M M M为尾数(frac)
IEEE 浮点数标准的编码

对于不同精度,有不同的长度格式:
- 32位单精度:1 - 8 - 23
- 64位双精度:1 - 11 - 52
- 80位超长精度:1 - 15 - 64
规格化的数
-
当 e x p ≠ 000 … 0 exp≠000…0 exp=000…0 和 e x p ≠ 111 … 1 exp≠111…1 exp=111…1
-
E 的值: E x p − B i a s Exp-Bias Exp−Bias (阶码值 = 阶码字段 - 偏置值)
其中, B i a s = 2 k − 1 − 1 Bias=2^{k-1}-1 Bias=2k−1−1, k k k 为阶码字段的位数。单精度为 127 127 127,双精度为 1023 1023 1023 -
M 的值: 1. f r a c 1.frac 1.frac (小数值 = 小数字段 + 1)
非规格化数
- 当 e x p = 000 … 0 exp = 000…0 exp=000…0
- E 的值:
1
−
B
i
a
s
1-Bias
1−Bias (阶码值 = 1 - 偏置值)
其中, B i a s = 2 k − 1 − 1 Bias=2^{k-1}-1 Bias=2k−1−1, k k k 为阶码字段的位数。单精度为 127 127 127,双精度为 1023 1023 1023 - M 的值: 0. f r a c 0.frac 0.frac (小数值 = 小数字段)
特殊值
- e x p = 111...11 , f r a c = 000...0 exp=111...11, frac = 000...0 exp=111...11,frac=000...0: ∞ ∞ ∞
- e x p = 111 … 11 , f r a c ≠ 000 … 0 exp=111…11, frac≠000…0 exp=111…11,frac=000…0: N a N NaN NaN
可视化

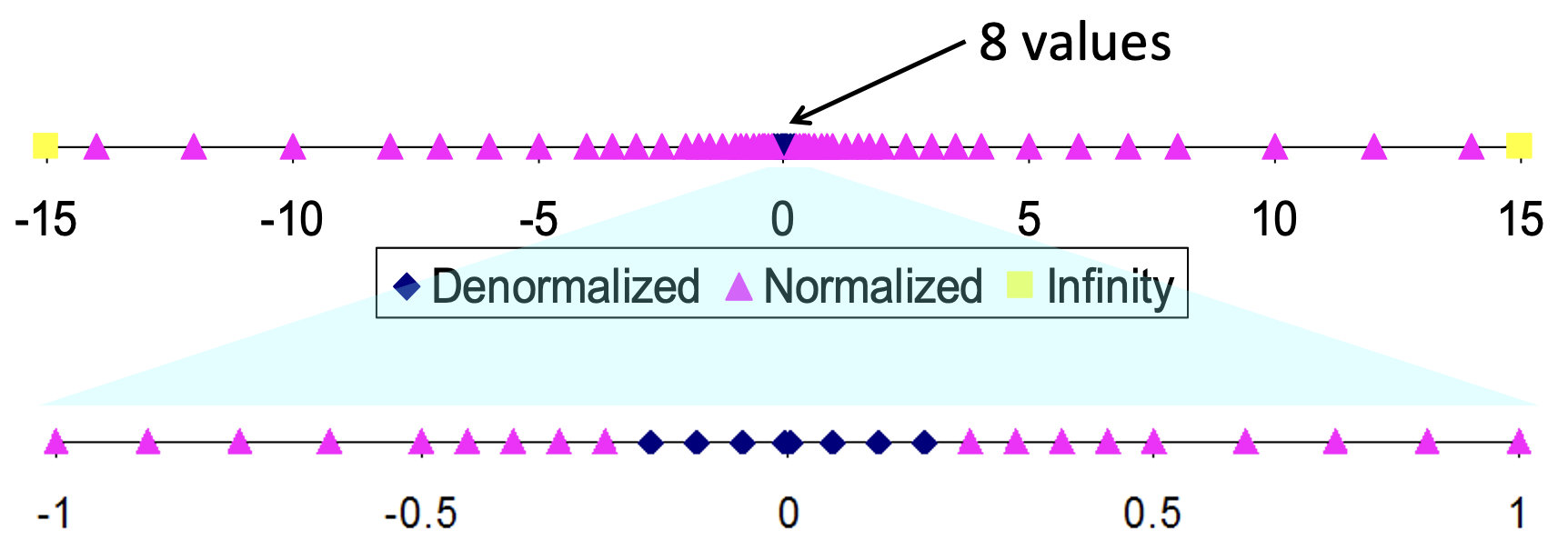
舍入

默认方式,向偶数舍入。在二进制中,最低有效位 0 0 0是偶数, 1 1 1是奇数。 < 1 / 2 <1/2 <1/2 - 舍; > 1 / 2 >1/2 >1/2 - 入; = 1 / 2 =1/2 =1/2 - 偶数舍入(要么丢掉,要么看成1,不能显式修改前面的数字位,只能通过进位完成)
浮点运算
- 先计算出精确值
- 然后根据精度进行调整:阶码太大时可能溢出;可能舍入到小数范围
乘法运算
( − 1 ) s 1 M 1 2 E 1 ∗ ( − 1 ) s 2 M 2 2 E 2 = ( − 1 ) s M 2 E (-1)^{s_1}\ M_1\ 2^{E_1} * (-1)^{s_2}\ M_2\ 2^{E_2} = (-1)^{s}\ M\ 2^{E} (−1)s1 M1 2E1∗(−1)s2 M2 2E2=(−1)s M 2E
M = M 1 ∗ M 2 M=M_1*M_2 M=M1∗M2
E = E 1 + E 2 E=E_1+E_2 E=E1+E2
- 假如M>=2,M小数点左移,E增加一
- 将M精确到指定位数
加法运算
( − 1 ) s 1 M 1 2 E 1 + ( − 1 ) s 2 M 2 2 E 2 = ( − 1 ) s M 2 E (-1)^{s_1}\ M_1\ 2^{E_1} + (-1)^{s_2}\ M_2\ 2^{E_2} = (-1)^{s}\ M\ 2^{E} (−1)s1 M1 2E1+(−1)s2 M2 2E2=(−1)s M 2E
- 阶码对齐(随E较大的),尾数相加
运算规则
-
加法、乘法运算具有交换性,但是没有结合性
-
单调性
-
不可分配性
精度
float<int<double第三章 机器级编程
3.1 Introduction
- compile a source file into an assembling file:
gcc -Og -S- 1
- disassemble an object code:
objdump -d" using object-dump gdb " using GDB disassemble - 1
- 2
- 3
- 4
3.2 程序编码
程序员可见状态:
- 程序计数器:将要执行的下一条指令在内存中的地址
- 寄存器文件:16个命名的位置,储存地址/整型数据
- 条件码:储存算术或逻辑指令的状态信息
- 内存
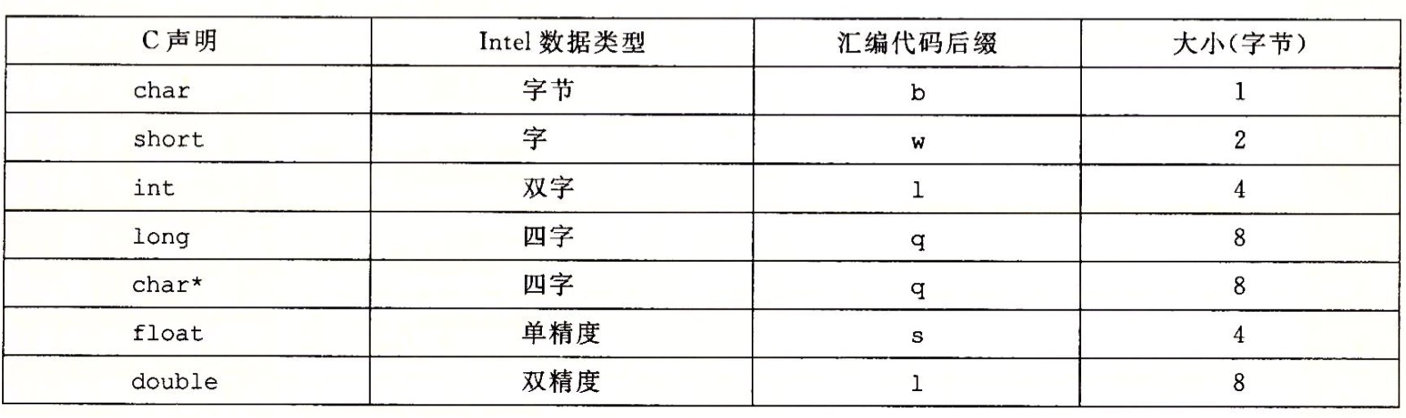
3.3 数据格式
3.4 访问信息
通用目的寄存器/整数寄存器

%rsp只可用于栈指针的存储操作数指令符

数据传送指令
movq
其中,
movq会先将32位扩展成64位的值,而moveabsq可以直接以任意64位立即数作为源操作数❓扩展指令
- 零扩展(MOVEZ)

- 符号扩展(MOVES)

例子1
void swap(long *xp, long *yp) { long t0 = *xp; long t1 = *yp; *xp = t1; *yp = t0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
swap: movq (%rdi), %rax movq (%rsi), %rdx movq %rdx, (%rdi) movq %rax, (%rsi) ret- 1
- 2
- 3
- 4
- 5
- 6
例子2
decode1: movq (%rdi), %r8 movq (%rsi), %rcx movq (%rdx), %rax movq %r8, (%rsi) movq %rcx, (%rdx) movq %rax, (%rdi) ret- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
void decode1(long *xp, long *yp, long *zp) { long x = *xp; long y = *yp; long z = *zp; *yp = x; *zp = y; *xp = z; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
压入和弹出栈数据


注意,
x86-64中,栈向低地址方向发展。3.5 算术和逻辑操作

每一个指令,都对应了
b,w,l,q四种长度相关的变种加载有效地址
leaq- 调用
lea时,传输的是整个地址,而不是地址中的值
leaq (%rdi), %rax <-> a = &(*p);- 1

一元和二元操作
-
一元
incqdecqnegqnotq
-
二元
addqsubqimulqxorqorqandq
移位操作
- Left
salqshlq
- Right
sarq- arithmaticshrq- logical
❓特殊的算术操作

这种操作支持全128位结果,具体是使用了
%rdx和%rax,用于储存「乘法:高64位|低64位」/「除法:余数|商」一个样例
long arith(long x, long y, long z) { long t1 = x + y; long t2 = z + t1; long t3 = x + 4; long t4 = y * 48; long t5 = t3 + t4; long rval = t2 * t5; return rval; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
arith: leaq (%rdi, %rsi), %rax # t1 addq %rdx, %rax # t2 leaq (%rsi, %rsi, 2), %rdx salq $4, %rdx # t4 leaq 4(%rdi, %rdx), %rcx # t5 imulq %rcx, %rax # rval ret- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.6 控制
❓ 条件码
CF:进位标志(无符号数)-(unsigned) t < (unsigned) aZF:零标志 -t == 0SF:符号标志 -t < 0OF:溢出标志 -(a < 0 == b < 0) && (t < 0 != a < 0)
设置条件码的指令

- CMP
- CF set if carry out from most significant bit (used for unsigned comparisons)
- ZF set if
a == b - SF set if
(a-b) < 0(as signed) - OF set if two’s-complement (signed) overflow
(a>0 && b<0 && (a-b)<0) || (a<0 && b>0 && (a-b)>0)
- TEST(一个数字)
- ZF set when
a&b == 0 - SF set when
a&b < 0
- ZF set when
访问条件码
SET将寄存器/内存地址的低位字节设置成0or1
Example:
int comp (data_t a, data_t b) { return a < b; } /* comp: cmpq %rsi, %rdi 比较 a:b setl %al 将 %eax 低位设置成 0 或 1 movzbl %al, %eax 清除 %eax 多余部分 ret */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
跳转指令的编码
JUMP条件跳转到程序其他部分- 直接跳转:以代码中的标号作为跳转目标,例如
.L3 - 间接跳转:
jmp *%rax / jmp *(%rax) - 无条件跳转
- 条件跳转(只能直接跳转)

用条件控制来实现条件分支
if-elseif () else 在汇编语言中这样处理 t = if (!t) goto flase; goto done; false: done: - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Example:
void cond(long a, long *p) { if (p && a > *p) *p = a; } /* cond: testq %rsi, %rsi je .L1 cmpq %rdi, (%rsi) jge .L1 movq %rdi, (%rsi) .L1: rep; ret */ void goto_cond(long a, long *p) { if (p == 0) goto done; if (*p >= a) goto done; *p = a; done: return; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
用条件传送来实现条件分支
cmov有条件地传送数据(BAD!!!)v = test-expr ? then-expr : else-expr; v = then-expr; ve = else-expr; t = test-expr; if (!t) v = ve;- 1
- 2
- 3
- 4
- 5
- 6

将条件操作的两种结果计算出来,最后根据条件是否满足选取一个。
Example:
long absdiff(long x, long y) { long result; if (x < y) result = y - x; else result = x - y; return result; } /* absdiff: movq %rsi, %rax subq %rdi, %rax rval = y-x movq %rdi, %rdx subq %rsi, %rdx eval = x-y cmpq %rdx, %rax ret */ long cmovdiff(long x, long y) { long rval = y-x; long eval = x-y; long ntest = x >= y; if (ntest) rval = eval; return rval; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
循环
do-whiledo Body while (Test); loop: Body if (Test) goto loop- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Example:
long fact_do(long n) { long result = 1; do { result *= n; n = n - 1; } while (n > 1); return result; } /* fact_do: movl $1, %eax .L2: imulq %rdi, %rax subq $1, %rdi cmpq $1, %rdi jg .L2 rep; ret */ long fact_do_goto(long n) { long result = 1; loop: result *= n; n = n - 1; if (n > 1) goto loop; return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
whilewhile (Test) Body // jump to the middle goto test; loop: Body test: if (Test) goto loop; done: // guarded-do if (!Test) goto done; loop: Body if (Test) goto loop; done:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Example:
long fact_while(long n) { long result = 1; while (n > 1) { result *= n; n = n - 1; } return result; } /* fact_while: movl $1, %eax jmp .L5 .L6: imulq %rdi, %rax subq $1, $rdi .L5: cmpq $1, %rdi jg .L6 rep; ret */ // jump to the middle long fact_while_jm_goto(long n) { long result = 1; goto test; loop: result *= n; n = n - 1; test: if (n > 1) goto loop; return result; } // guarded do long fact_while_gd_goto(long n) { long result = 1; if (n <= 1) goto done; loop: result *= n; n = n - 1; if (n != 1) goto loop; done: return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
for
switch语句跳转表结构

Example

- 第一步,偏移,这一步能够得到最小情况的值
- 第二步,设置默认跳转,这一步能够得到最大情况的值
- 第三步,查看跳转表,其中与上面一步得到的超过最大情况的(defult)相同的,都是没有提及的defult情况;其余的一一对应
3.7 过程
过程机制(函数)
- 传递控制
- 跳转到函数头部
- 返回到原先程序
- 传递数据
- 函数传参
- 函数返回值
- 内存管理
- 函数内部参数空间分配与释放
栈

控制传递
Call 指令:
call label- 将返回地址压入栈
- 将跳转地址记录到
%rip - 跳转到标签
Return 指令:
rep; ret- 假设栈顶有一个跳转地址
- 将该地址弹出栈
- 运行至该地址(返回原程序运行)
传递数值
对于数据的存储
- 前六个存放在特定寄存器中

- 返回值存放在
%rax中 - 超过六个参数的使用栈内存
本地数据管理(引用/递归)
栈帧

每次调用一个新的嵌套函数,只需要往栈中不断压入即可。FILO
- 原有栈帧
- 供函数传递的参数
- 本地变量(不在寄存器中)
- 寄存器信息
%rbx
- 调用栈帧
- 返回地址
- 函数本身的参数
寄存器保留规则
-
rax
- Return value
- Also caller-saved
- Can be modified by procedure
-
rdi, …, %r9
- Arguments
- Also caller-saved
- Can be modified by procedure
-
%r10, %r11
-
Caller-saved
-
Can be modified by procedure

-
-
%rbx, %r12, %r13, %r14, %r15
- Callee-saved
- Callee must save & restore
-
%rbp
- Callee-saved
- Callee must save & restore
- May be used as frame pointer
- Can mix & match
-
%rsp
- Special form of callee save
- Restored to original value upon exit from procedure

3.8 数组分配和访问
基本原则
- 数组元素
i在内存中的地址为:p + i * sizeof(T) - 访问数组元素:
(%rdx, %rcx, 4)->a[4]
指针运算
C语言 汇编代码 pmove %rdx, %raxp[0]move (%rdx), %raxp[i]movl (%rdx, %rcx, 4), %eax&p[i]leaq (%rdx, %rcx, 4), %raxp + i - 1leaq -4(%rdx, %rcx, 4), %rax嵌套的数组
二维数组的元素行首地址在内存中的表示:
A + i * (j * sizeof(t))Example:
int get_univ_digit(size_t index, size_t digit) { return univ[index][digit]; } /* salq $2, %rsi # 4*digit addq univ(,%rdi,8), %rsi # p = univ[index] + 4*digit movl (%rsi), %eax # return *p ret */- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
定长数组



变长数组



3.9 异质数据结构
结构体
struct在内存中顺序存储,记录下每个元素的位置并通过偏置进行访问。
例子——单链表:

struct rec { int a[4]; int i; struct rec *next }; /* 汇编语言 .L11: # loop: movslq 16(%rdi), %rax # i = M[r+16] movl %esi, (%rdi,%rax,4) # M[r+4*i] = val movq 24(%rdi), %rdi # r = M[r+24] testq %rdi, %rdi # Test r jne .L11 # if !=0 goto loop */ /* 优化后的等价C代码 */ void set_val(struct rec *r, int val) { while (r) { int i = r->i; r->a[i] = val; r = r->next; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
需要进行数据对齐:
最大的类型的整数倍

结构体组

Advanced
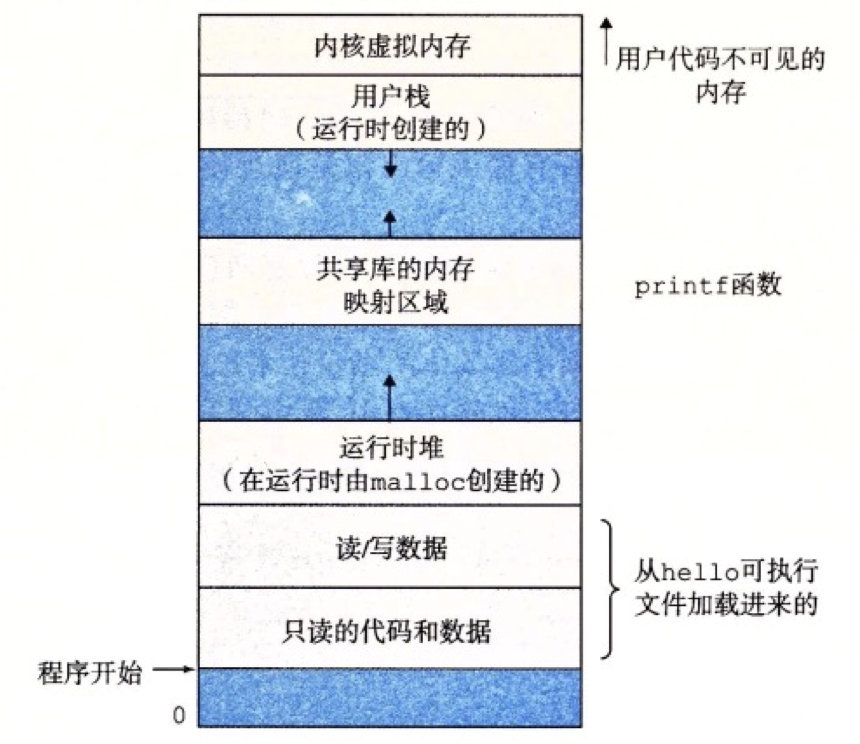
x86-64 Linux Memory Layout

- Stack
- Runtime stack (8MB limit)
- e.g., local variables
- Heap
- Dynamically allocated as needed
- When call malloc(), calloc(), new()
- Data
- Statically allocated data
- e.g., global vars, static vars, string constants
- Text / Shared Libraries
- Executable machine instructions
- Read-only
第六章 存储结构
6.1 存储技术
随机访问存储器(RAM)和非易失性储存器(ROM)
静态RAM——SRAM和动态RAM——DRAM
- SRAM 比 DRAM 拥有更多晶体管
- SRAM 访问速度 DRAM 快
- SRAM 保持不变,DRAM 需要刷新
- SRAM 不敏感,不太需要 EDC
- SRAM 比 DRAM 贵好多
- SRAM 主要应用于高速缓存储存器,DRAM 主要用于主存,帧缓冲区
传统 DRAM
- d x w DRAM:
- DRAM 被分成 d 个超单元,每个超单元都由 w 个 DRAM 单元组成,DRAM 储存的信息大小就为 d ⋅ w d⋅ w d⋅w ,而 d = r o w ∗ c o l d = row * col d=row∗col
-

- 每次从输入引脚处获取行与列的信息,寻找到以后将该处信息通过输出引脚传出
- 先选择行,将其置入内置行缓冲区,然后选择列,分两步完成
内存模块
运用多个DRAM芯片,对应不同地址单元。例如DRAM0对应第一个低位字节,DRAMx对应第x个低位字节
增强的DRAM
- SDRAM:同步DRAM
- DDR SDRAM:双时钟,DDR-2bits,DDR2-4bits,DDR3-8bits……
ROM
- ROM:只读
- PROM:可编程(仅一次)
- EPROM:可擦写PROM
- EEPROM:电子EPROM
- 闪存 Flash Memory,基于EEPROM(SSD也是)
- 里面主要存有固件(BIOS,IO……)
访问主存的过程
总线结构(抽象)

- 读取数据(
mov A, %eax)- CPU将地址
A放置在内存总线上

- 主存从内存总线中读取
A,并取出其中的内容x,将其放入内存总线

- CPU将
x从总线中读出并复制到寄存器%eax中

- CPU将地址
- 写入数据
mov %rax, A- CPU将地址
A放在内存总线,主存读取地址等待数据

- CPU将数据
y放入总线

- 主存从总线读取
y,并将其储存在A

- CPU将地址
磁盘存储
构造
盘片——表面——磁道——扇区+间隙
磁盘容量
影响因素
- 记录密度:磁道单位长度可以放入的位数
- 磁道密度:半径方向单位长度的磁道数
- 面密度:磁道密度 * 记录密度
磁盘容量计算公式:每个扇区的字节数 * 每个磁道的扇区数 * 每个面的磁道数 * 每个盘面的表面数 * 总共盘片数
此处, 1 G B = 1 0 9 b y t e s , 1 T B = 1 0 12 b y t e s 1GB=10^9\ bytes, 1TB=10^{12}\ bytes 1GB=109 bytes,1TB=1012 bytes
磁盘读取操作
- 寻道: T a v g s e e k = 3 − 9 m s T_{avg\ seek} = 3 - 9ms Tavg seek=3−9ms ——几乎不可变
- 旋转: T m a x r o t a t i o n = 1 / R P M × 60 s / 1 m i n T_{max\ rotation}=1/RPM\times60s/1min Tmax rotation=1/RPM×60s/1min(转速的倒数); T a v g r o t a t e = T m a x r o t a t i o n ÷ 2 T_{avg\ rotate}=T_{max\ rotation}\div 2 Tavg rotate=Tmax rotation÷2 ——顺序读取快多了(碎片处理)
- 数据传送:$ T_{avg\ transfer}=1/RPM\times1/(每条磁道的平均扇区数)\times60s/1min$(转速的倒数 除以 每条磁道的平均扇区数) ——几乎可以忽略不计
顺序读写和随机读写的差距:
顺序读写只需要第一次 T a v g s e e k + T a v g r o t a t e T_{avg\ seek} + T_{avg\ rotate} Tavg seek+Tavg rotate 加上 圈数 × T m a x r o t a t e 圈数 \times T_{max\ rotate} 圈数×Tmax rotate,而随机读写每次都需要 T a v g s e e k + T a v g r o t a t e T_{avg\ seek} + T_{avg\ rotate} Tavg seek+Tavg rotate
逻辑磁盘块
磁盘控制器完成映射;固件完成快速表查找(盘面,磁道,扇区)
I/O总线

磁盘访问
- CPU将命令、逻辑块号、目的内存地址写到与磁盘相关联的内存映射地址,发起磁盘读取

- 磁盘读取扇区,DMA传送到主存

- DMA完成后,磁盘控制器中断通知CPU

固态硬盘SSD
块-页的存储:写入页必须要移除整个块

顺序快,随机满;读取快,写入慢
对比机械硬盘:
- 更快,功耗更低,更安全
- 多次写入容易造成存储单元损坏
6.2 局部性
定义
时间局部性:【使用同一个变量进行操作】被引用过一次的内存位置很可能在不远的将来再被多次引用

空间局部性:【使用相邻位置的内存】被引用过的内存位置,它附近的内存位置很可能在不远的将来被引用

数组中的空间局部性
int i, sum = 0; for (i = 0; i < n; ++i) sum += v[i]; return sum;- 1
- 2
- 3
- 4
- 数据引用的局部性
- 对于
sum:时间局部性 - 对于
++i:空间局部性
- 对于
- 取指令的局部性
- 循环:时间局部性
- 顺序读取:空间局部性
6.3 存储器层次结构

k k k 层更小更快的存储设备作为$ k+1 $层更大更慢存储设备的缓存
缓存

- 缓存命中
- 刚好在上一层找到了想要的对象
- 缓存不命中
- 替换/驱逐原有块,原有块成为牺牲块
- 缓存不命中种类
- 冷不命中
- 空缓存
- 容量不命中
- 缓存 < 工作集
- 冲突不命中
- 限制性放置策略
- 冷不命中
6.4 高速缓存储存器
通用的高速缓存存储器组织结构 (S, E, B)

整个高速存储器被这样分割:
- 高速缓存器总大小: C a c h e s i z e = S × E × B Cache\ size = S\times E \times B Cache size=S×E×B
- S = 2 s S = 2^s S=2s 个组
- 每个组有 E = 2 e E = 2^e E=2e 个行
- 每一行有效数据有 B = 2 b B = 2^b B=2b 个 bytes,附加一个有效位,和一个标记
访问高速缓存

- 定位高速缓存组
- 定位到标记所在行
- 成功定位 + 有效,即命中
- 通过偏移定位需要访问的字节
直接映射高速缓存( E = 1 E = 1 E=1)
每组只有一行地址构成的叫做直接映射高速缓存

假如不命中,将会移除旧的行并且用新的数据替代
组相连高速缓存( E ≠ 1 E \neq 1 E=1)
- 假如不命中,采用的标记替换策略:Random / Least Recently Used / Least Frequently Used

全相连高速缓存
写入数据
命中写入
- 直写(Write Through)
- 写回(Write Back)
- 直到最后要被替代的时候才修改下一层
- 需要 dirty bit 标记
不命中写入
- 写分配(Write-allocate)
- 将数据加载入缓存中,以命中的方式写入
- 非写分配(Non-write-allocate)
- 直接写入下层内存
高速缓存参数对性能的影响
- 不命中率
- 不命中数量 / 引用数量 不命中数量 / 引用数量 不命中数量/引用数量
- 命中率
- 1 − 不命中率 1 - 不命中率 1−不命中率
- 命中时间
- 不命中处罚
6.5 编写利于高速缓存的代码
- 集中在内循环上
- 将内循环的不命中率降到最低
- 时间局部性(重复引用同一个变量)
- 空间局部性(相邻位置的应用)
6.6 高速缓存对程序性能的影响
储存器山

步长 - 空间局部性
大小 - 时间局部性
重新排列循环
一个例子:计算矩阵的内积
-
a-row, b- col, c-fixed
for (i=0; i<n; i++) { for (j=0; j<n; j++) { sum = 0.0; for (k=0; k<n; k++) sum += a[i][k] * b[k][j]; c[i][j] = sum; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

Miss Rate: A-0.25, B-1.0, C-0.0
-
a-fixed, b-row, c-row
for (k=0; k<n; k++) { for (i=0; i<n; i++) { r = a[i][k]; for (j=0; j<n; j++) c[i][j] += r * b[k][j]; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

Miss Rate: A-0.0, B-0.25, C-0.25
-
a-col, b-fixed, c-col
for (j=0; j<n; j++) { for (k=0; k<n; k++) { r = b[k][j]; for (i=0; i<n; i++) c[i][j] += a[i][k] * r; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

Miss Rate: A-1.0, B-0.0, C-1.0
写入比读取更加灵活

运用分块提高时间局部性
分块矩阵的运算
第七章 链接
7.1 编译器驱动程序

为什么要使用链接?
- 模块化
- 模块化编程
- 标准库的引用
- 提高效率
- 拆分编译
- 程序库直接引用
7.2 静态链接
链接器操作步骤:
- 符号解析
- 函数/全局变量/静态变量
- 重定位
- 合并
7.3 目标文件
- 可重定位目标文件
.o- 二进制数据和代码
- 链接的时候合并
- 可自行目标文件
.out- 可以直接复制到内存运行
- 共享目标文件
.so.dll- 可动态加载的重定向文件
上面所有的可重定位目标文件都可称为——可执行可链接格式(ELF)
7.4 可重定位目标文件

-
ELF头
-
.text
- 已编译程序的机器代码
- 只读
-
.rodata
- 只读数据(例如跳转表、格式串)
-
.data
- 已初始化的全局和静态C变量(局部变量位于栈)
-
.bss (block started by symbol)
- 未初始化的全局和静态C变量,和初始化为0的全局或静态变量
- 不占用实际空间,仅仅占位
-
.systab
- 符号表,存放定义和引用的函数和全局变量信息
-g调试才会生成这张表
-
.rel.text
- text节的重定位信息
-
.rel.data
- 被引用或定义的所有全局变量的重定位信息
-
.debug
-g调试才会生成这张表
-
.line
- 行号与
.text中的机器指令进行映射 -g调试才会生成这张表
- 行号与
-
.strtab
- 字符串表(包括
.systab和.debug节中的符号表)
- 字符串表(包括
7.5 符号和符号表
- 全局符号
- 由自己定义并能被其他模块引用的
- 非静态的C函数和全局变量
- 外部符号
- 有其他模块定义并且被自己引用的
- 其他模块的非静态的C函数和全局变量
- 局部符号
- 只被自己定义和引用
static属性的C函数、全局变量

- 符号表
- 是否为
.systab节条目?- 不是局部变量的都要!
- 符号类型(
type)- 数据(
OBJECT) - 函数(
FUNC)
- 数据(
- 节(
Ndx).data:已初始化的全局和静态C变量.text:机器代码(和模块名相同).bss:未初始化的静态变量,以及初始化为0的全局/静态变量- 三个特殊的伪节
COMMOM:未初始化的全局变量UNDEF:未定义的符号(引用了外部定义的模块)ABS:无需重定位
- 是否为
7.6 符号解析
链接器如何解析多重定义的全局符号
假如多个模块定义了同名的全局符号:
- 强符号
- 过程(函数等)
- 已初始化的全局变量
- 弱符号
- 未初始化的全局变量
规则:
- 不允许多个同名的强符号
- 一个强符号+多个弱符号,选择强符号
- 多个弱符号,随便选
因此对于全局变量来说:
- 避免使用
- 尽量使用
static - 主动初始化
- 假如要引用外部的使用
extern
与静态库链接
基于已有的链接框架的选择:
- 将所有标准库函数全部放在一个
.o文件中- 程序每次要链接一个巨大的文件
- 省时间和空间
- 为每个标准库函数创建一个
.o文件- 程序选择性调用
- 更加省空间,但是对程序员来说事情多了
解决方案:静态库链接(老式)
.aarchive file利用上面的方案二,将所有的库函数全部生成
.o文件,但是多了一个表格,指明每个.o文件的偏移量以便直接调用。所以只需要将arch file传递过去即可。
unix> ar rs libc.a atoi.o printf.o … random.o- 1
然后用什么拿什么。
链接器如何使用静态库来解析应用
- 按照命令行顺序扫描
.o&.a文件 - 生成一个函数没有定义的引用列表
- 对于每次新输入的
.o&.a文件,尝试去解析那些没有定义的列表项目 - 假如这个列表在程序运行结束的时候依然不为空,那么报错
流程简述就是:先运行前面的➡️碰到能解析前面的就解析
但是库有先后顺序!!!
又要注意!目标文件是不需要重复引用的!
7.7 重定位(链接时)

编译器不知道链接器会选择什么地址,只好创建临时条目来储存链接器指令。

a : R_X86_64_32 array重定位条目
typedef struct { long offset; // 重定位的偏移位置 a long type:32; // 如何修改新的引用 R_X86_64_32 long symbol:32; // 指向的符号 array long append; // 符号参数(偏移调整) - } Elf64_Rela;- 1
- 2
- 3
- 4
- 5
- 6
重定位符号的引用
foreach section s { foreach section entry r { refptr = s + r.offset; /* ptr to reference to be relocated */ /* Relocate a PC-relative reference */ if (r.type == R_X86_64_PC32) { refaddr = ADDR(s) + r.offset; // 1 *refptr = (unsigned) (ADDR(r.symbol) + r.append - refaddr); // 2 } /* Relocate an absolute reference */ if (r.type == R_X86_64_32) *refptr = (unsigned) (ADDR(r.symbol) + r.append); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 计算PC的步骤:
- refaddr = .text 中的重定位地址 - r.offset
- *refptr = 调用模块的重定位地址 + r.append
7.8 可执行目标文件

程序头部表
- 只读代码段
- 读/写数据段
包含了:
off:目标文件的偏移vader/paddr:开始于内存地址align:对齐filesz:目标文件中的段大小memsz:总的内存大小flags:访问权限vaddrmodalign=offmodalign
7.9 加载可执行目标文件
可执行程序在Linux系统之下的内存结构抽象图

7.10 动态链接共享库
和静态库不同,动态链接共享库并不在一开始就链接,而是在加载时链接(动态链接器)/运行时链接(
dlopen,用于分发/服务器/库打桩)/多进程共享。通常为.dll,.so
7.11 从应用程序中加载和链接共享库
Example:
/* dll.c */ #include#include #include int x[2] = {1, 2}; int y[2] = {3, 4}; int z[2]; int main() { void *handle; void (*addvec)(int *, int *, int *, int); char *error; /* Dynamically load the shared library that contains addvec() */ handle = dlopen("./libvector.so", RTLD_LAZY); if (!handle) { fprintf(stderr, "%s\n", dlerror()); exit(1); } /* Get a pointer to the addvec() function we just loaded */ addvec = dlsym(handle, "addvec"); if ((error = dlerror()) != NULL) { fprintf(stderr, "%s\n", error); exit(1); } /* Now we can call addvec() just like any other function */ addvec(x, y, z, 2); printf("z = [%d %d]\n", z[0], z[1]); /* Unload the shared library */ if (dlclose(handle) < 0) { fprintf(stderr, "%s\n", dlerror()); exit(1); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
❓ 7.12 位置无关的代码PIC
- 现代系统编译共享模块代码的方法
- 使之可加载到内存的任何位置而无需链接器修改
- 使得多个进程可以共享一个共享模块代码段的单一副本
-fpic
- 符号引用的问题
- 对同一目标模块内的符号引用
- 编译时PC
- 静态链接器重定位
- 对共享模块定义的外部过程和全局变量的引用
- 加载时,由动态链接器重定位
- 对同一目标模块内的符号引用
- 延迟绑定:将过程地址的绑定推迟到第一次调用该过程时
- 生成重定位记录,加载时解析
- GOT与PLT交互
7.13 库打桩机制
编译时打桩(源代码)
- Apparent calls to
malloc/freeget macro-expanded into calls tomymalloc/myfree - Simple approach. Must have access to source & recompile
- 加上
-I.让预处理器现在当前目录下查找文件
链接时打桩(可重定位对象文件)
- Use linker trick to have special name resolutions
malloc➡️__wrap_malloc__real_malloc➡️malloc
-Wl,--wrap,file
运行时打桩(可自行目标文件)
LD_PRELOAD,解析未定义的引用时,先查看LD_PRELOAD库
第八章 异常
8.0 EFC
- 底层机制
- 异常
- 系统事件的切换
- 运用硬件与软件的结合部署
- 异常
- 高层机制
- 进程上下文
- timer计时器切换
- 信号signal
- 非本地跳转
- 进程上下文
8.1 异常

Example: Divide by 0, arithmetic overflow, page fault, I/O request completes, typing Ctrl-C
异常处理
运用异常表,不同的异常对应不同的处理结果

异常的类别

- 异步异常
- 中断

- 由外部设备信号引起
- 例如:timer interrupt,I/O interrupt from external devices
- 中断
- 同步异常
- 陷阱

- 程序有意的自己中断,例如系统调用
- 例如:system calls, breakpoint traps, special instructions
- 故障

- 无意的但是可能恢复的,可以重新执行的
- 例如:page faults (recoverable), protection faults (unrecoverable), floating point exceptions
- 终止

- 无意的并且不可恢复
- 例如:illegal instruction, parity error, machine check
- 陷阱
8.2 进程
两个假象:
- 一个独立的逻辑控制流:程序独自占用处理器
- 一个私有的地址空间:程序独自占用内存系统
逻辑控制流
程序计数器(PC)
一个运行到一半被暂时挂起,执行另一个

并发流
客户端视角来观察:

私有地址空间

用户模式和内核模式

上下文切换中的两个模式:
- 模式位(sudo设置)——内核模式
- 用户模式
- 不允许执行特权指令
- 切换的唯一方式是异常
8.3 系统调用错误处理
8.4 进程处理
获取进程ID
#include#include pid_t getpid(void); /* get current PID */ pid_t getppid(void); /* get parent PID */ - 1
- 2
- 3
- 4
- 5
创建和终止进程
进程永远是这三种状态:
- 运行
- 正在执行
- 等待被执行,被内核调度
- 停止
- 被挂起
- 不会被调度
- 终止
- 永远停止
终止进程
终止原因:1. 收到了终止信号;2. 从
main()返回;3. 显式调用exit()。exit():会有一个结束状态void exit(int status);被调用一次,但是永远不会返回值创建进程
#include#include pid_t fork(void); - 1
- 2
- 3
- 4
- 调用一次,返回两次!!
- 子进程返回 0 0 0,父进程返回子进程的PID
- 子进程和父进程并发执行,顺序未知
- 子进程的地址空间和父进程的值完全相同,但是是独立的
- 子进程可以访问父进程已经打开的文件
回收子进程
-
当进程终止的时候,并不会被抛弃,而是会继续存在,占用系统资源,成为「僵尸进程」
-
回收进程
- 父进程使用
wait/waitpid终止子进程 - 父进程给出终止的status
- 内核回收
- 父进程使用
-
假如父进程没有回收
- 孤儿进程由
pid=1的init系统进程进行回收 - 长时间运行的进程会导致子进程的内存泄漏
- 孤儿进程由
wait
#include#include pid_t wait(int* statusp); // <=> waitpid(-1, &status, 0); - 1
- 2
- 3
- 4
waitpid
pid_t waitpid(pid_t pid, int &status, int options);- 1
-
pidpid>0单独子进程pid=-1所有子进程
-
optionsWNOHANG等待子进程终止的同时还想做其他事情WUNTRACED检查已终止的、被停止的子进程WCONTINUED等
-
statusp -
没有子进程,返回
-1,errno = ECHILD;中断,返回-1,errno = EINTR
让进程休眠
#includeunsigned int sleep(unsigned int secs); /* 返回剩余秒数 */ int pause(void); /* 总是返回-1 */ - 1
- 2
- 3
- 4
加载并运行程序
#includeint execve(const char *filename, const char argv[], const char *envp[]); - 1
- 2
- 3
- 加载并运行可执行目标文件
filename,带有参数列表argv和环境变量envp - 调用一次,从不返回!!
- 错误的情况下才返回
-1

利用
fork和execve运行程序只能回收前台进程,解决方法——ECF!
8.5 信号

信号术语
- 发送信号
- 内存检测到了系统事件,发送Linux信号
- 调用了
kill函数,显式要求发送信号
- 接收信号
- 进程可以忽略信号
- 也可以调用默认行为
- 还可以执行信号处理程序 (signal handler)

- 当遇到多个同一类的信号时,只会保留一份
- 阻塞信号只会发送不会接收
- 一个待处理信号最多只能被接受一次(pending / blocked)
发送信号
进程组
pid_t getpgrp(void); /* 返回进程组ID */ int setpgid(pid_t pid, pid_t pgid); /* 成功返回0,错误返回-1, pid=0 代表当前进程 */- 1
- 2
- 3
用
/bin/kill程序发送信号linux> /bin/kill [-x the operation code] [x pid] [-x process group id]- 1
运用键盘发送信号
例如
ctrl-c = SIGINT/ctrl-z = SIGTSTP运用
kill函数发送信号#includeint kill(pid_t pid, int sig); /* 成功返回0,错误返回-1 */ - 1
- 2
- 3
对子进程的kill并不会回收
运用
alarm函数发送信号unsigned int alarm(unsigned int secs);- 1
接收信号
处理未被阻塞的待处理信号的集合。如果非空,那么就会强制接收信号。
预定义的默认行为:
- 进程终止
- 进程终止并转储内存
- 进程停止(挂起)直到被SIGCONT重启
- 忽略
SIGSTOP SIGKILL 不能修改
signal handler 和 signal 函数
#includetypedef void (*sighandler_t)(int); sighander_t signal(int signum, sighandler_t handler); - 1
- 2
- 3
如何改变?
handler == SIG_IGN忽略信号handler == SIG_DFL恢复默认- 用户函数的地址,称设置信号处理程序,调用过程称捕获信号
阻塞信号
- 隐式阻塞
- 在运行一个处理程序的时候收到了另一个信号
- 显式阻塞
- 使用
sigprocmask
- 使用
8.6 非本地跳转
#includeint setjmp(jmp_buf env); /* 调用一次,返回多次,返回值为0 */ void longjmp(jmp_buf env, int retval); /* 调用一次,从不返回 */ - 1
- 2
- 3
- 4
第九章 虚拟内存
9.1 物理寻址和虚拟寻址
物理寻址系统

虚拟寻址系统

- MMU:地址翻译器,利用主存中的页表,将虚拟地址转换为物理地址
9.2 地址空间
9.3 虚拟内存作为缓存的工具
-
虚拟内存:在外部存储磁盘上的
- 虚拟页(VP)
- 三种情况

- 未分配
- 缓存的
- 未缓存的(尚未加载到物理内存)
-
物理内存:物理内存(DRAM)
- 物理页(PP)
DRAM缓存的组织结构
- DRAM的特点
- 慢
- 虚拟页非常大
- 全相联
- 不命中的替换策略很重要
- 使用写回,不用直写
页表
- 功能
- MMU中的地址翻译硬件读取,将VP->PP
- 位置
- 主存中(高速缓存/内存)
- 组织
- PTE——数量: N − P = 2 n − 2 p N-P=2^n-2^p N−P=2n−2p

页命中

缺页

假如不命中,就会前往虚拟内存中找到该页,将它放入物理内存中并且修改PTE表。同时,被替换掉的物理内存被称为“牺牲页”。
目前都是采用按需页面调度
分配页面
使用
malloc()的时候,会发生这个过程。现在虚拟内存中开辟一个新的空间并储存数据,然后再修改PTE表。
局部性
保证了程序总在一个较小的页面集合上活动,成为工作集/常驻集合
9.4 虚拟内存作为内存管理的工具
- 简化链接
- 每个进程的内存映像格式一致
- 简化加载
- 内存映射
- 简化共享
- 共享页面
- 简化内存分配
- malloc使得在虚拟内存中可以储存连续的数据
9.5 虚拟内存作为内存保护的工具
带许可位的页表
9.6 地址翻译
虚拟地址、物理地址的格式转换

-
VPO-虚拟页内部偏移量 = PPO-物理页内部偏移量
-
VPN-虚拟页号 → page table \stackrel{\text{page table}}{\rightarrow} →page table PPN-物理页号
-
操作过程
-
页面命中

- CPU生成虚拟地址并请求MMU
- MMU生成PTE地址,从高速缓存/内存请求PTE
- 高速缓存/内存返回PTE
- MMU从PTE中取出并构造物理地址,发送给高速缓存/内存
- 高速缓存/内存返回数据内容
-
缺页

- CPU生成虚拟地址并请求MMU
- MMU生成PTE地址,从高速缓存/内存请求PTE
- 高速缓存/内存返回PTE
- 找不到目标物理地址,触发异常
- 缺页处理程序确定牺牲页,如果已经被修改,换出到磁盘
- 缺页处理程序调入新的界面,更新内存中的PTE
- 重新开始运行程序
结合高速缓存和虚拟内存

-
利用TLB加速地址的翻译
PTE即使放在L1中仍然不好,所以就在MMU中增加了一个后备缓冲器

TLB HIT:

TLB MISS:

多级页表

-
一级页表
- 全局页表
- 常驻主存
-
二级页表
- 按需创建
- 最常用部分缓存在主存
-
k级页表

端到端的地址翻译
- Step1: 虚拟地址分割成(TLBT+TLBI+VPO)
- Step2: 根据TLBI、TLBT查表获得PPN
- Step3: 将得到的PPN+VPO(=PPO)合起来分割成高速缓存格式(CT+CI+CO)
- Step4: 高速缓存获取数据
9.7 案例研究:Intel Core i7/Linux 内存系统
Core i7 地址翻译


Linux 虚拟内存系统


- 虚拟内存:区域的集合
- 区域:已分配的虚拟内存的连续片
- 内存为每个进程维护一个
task_struct mm_struct:虚拟内存的当前状态pdg指向第一级页表的基址mmap指向vm_area_struct链表(描述一系列区域)
缺页异常处理

- 段错误
- 访问不存在的页面
- 保护异常
- 试图越过权限的操作
- 正常缺页
9.8 内存映射
定义:讲一个内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容
虚拟内存区域可以映射到两种类型的对象中的一种:
- 普通文件
- 按需调度:不进入物理内存,直到第一次引用
- 匿名文件——请求为
0
0
0 的页,《预先申请》
- 内核在物理内存中找到牺牲页面,用二进制零覆盖页面并更新页表。磁盘-内存之间没有数据传输
再看共享对象
-
共享对象-共享区域

操作会直接反映在原始对象上 -
私有对象-私有区域

写入操作不会反映在磁盘上的原始对象。而会另找一块区域。(COW)
再看
fork函数再看
execve函数
加载并运行一个程序需要的步骤:
- 删除已存在的用户区域
- 映射私有区域
- 映射共享区域
- 设置程序计数器(PC)
使用
mmap函数的用户级内存映射#include#include void *mmap(void *start, /* 起始地址(可由内核决定,通常为NULL)*/ size_t length, /* 字节空间 */ int prot, /* 访问权限 */ int flags, /* 映射对象类型 */ int fd, /* 文件指针 */ off_t offset); /* 文件中的偏移量 */ void munmap(void *start, size_t length); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

9.9 动态内存分配

动态内存分配器:维护一个进程的虚拟内存区域,称为堆
分配器将堆视为一组不同大小的块,每个块是连续的虚拟内存片。
块的状态分为 已分配 和 空闲
- 分配器的两种风格
- 显式分配
mallocfreenewdelete
- 隐式分配
- 显式分配但是没有释放的
- 垃圾收集
- 显式分配
malloc和free函数会有对齐:32 - 8;64 - 16
分配器的要求和目标
显式分配器的要求:
- 处理任意请求序列
- 立即响应请求
- 只是用堆
- 对齐
- 不修改已分配的块
目标
- 最大化吞吐率
- 吞吐率 = 所有请求 / 使用时间
- 最大化内存利用率
- 峰值利用率 = 聚集有效载荷/ 当前堆大小
碎片
- 内部碎片
- 已分配块大小 - 有效载荷大小

- 已分配块大小 - 有效载荷大小
- 外部碎片
- 根据请求的大小而定,可能是碎片也可能不是
实现问题
吞吐率 与 内存利用率 二选一

隐式空闲链表


放置策略
分割空闲块
获取额外的堆内存
合并空闲块
- 立即合并
- 推迟合并
带边界标记的合并

已分配的可以不需要脚部
显式空闲链表

分离的空闲链表
- 简单分离储存
- 分离适配
- 伙伴系统
9.10 垃圾收集器
保守的垃圾收集器
mark&sweep[Facepalm]
- 预处理阶段:将源程序
-
相关阅读:
以效率为导向:用ChatGPT和HttpRunner实现敏捷自动化测试(二)
QT day3
读《遇见未知的自己》笔记
这里有你想知道的ES2020中Javascript10个新特性
shell脚本
530. 二叉搜索树的最小绝对差
nacos的服务发现详解
IO学习系列之使用fgetc和fputc复制文件内容
SpringBoot使用DevTools实现后端热部署
用Python进行数学建模(二)
- 原文地址:https://blog.csdn.net/weixin_45481260/article/details/126567064