-
数据库的星型模型与雪花模型
1.什么是星型模型
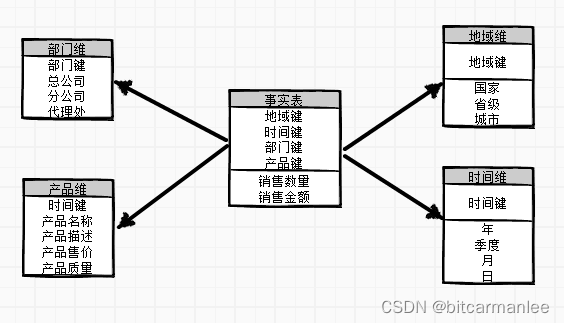
星型模式模型可以被描述为一个简单的星型结构:一个中心表包含事实数据,多个表从它向外辐射,由数据库的主键和外键连接。 在星型模式实施中,数据库的构建者将所有维度级别的维度数据存储在单个表或视图中。
例如,如果您使用星型模式实现Product维度,那么数据库构建者将使用单个表来实现维度中的所有级别,如屏幕截图所示。 所有级别中的属性都映射到名为PRODUCT的单个表中的不同列。(图片来自参考文献1)
2.什么是雪花模型
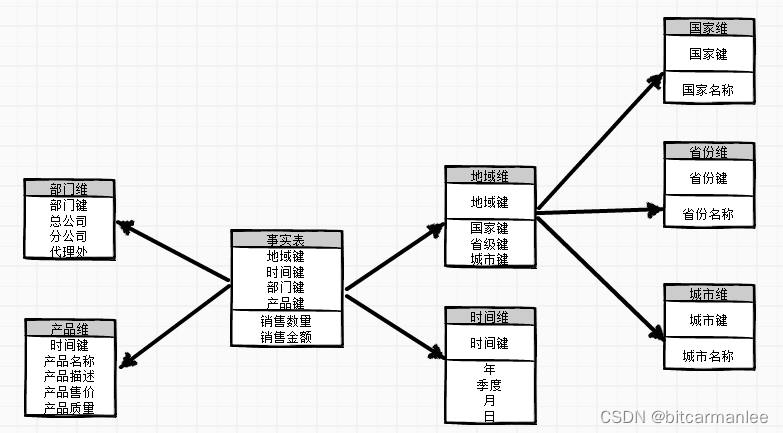
雪花模式表示一个维度模型,它也由一个中心事实表和一组构成维度表组成,这些维度表进一步规范化为子维度表。 数据库构建者使用多个表或视图来存储维度数据。 单独的数据库表或视图存储与维度中每个级别有关的数据。
下图显示了 Product 维度的雪花实现。 维度中的每个级别都映射到不同的表。
3.星型模型与雪花模型对比
1.星型模型因为数据存在冗余,很多时候进行查询统计时不需要再join外部维度表,因此在很多OLAP的场景中,星型模型的效率比雪花模型要高。
2.星型模型不用考虑很多正规化的因素,设计和实现都比较简单
3.雪花模型去除了数据冗余,因此可以节省存储资源。但是在进行分析的时候,需要join外部较多维度表才能得到结果,查询比较复杂效率也较慢。
4.正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。4.使用场景
一般我们在数仓底层能见到许多大宽表,这些大宽表就是基于星型模型设计的。
Ralph Kimbal作为数据仓库的大牛,在相关著作中列举了三个雪花模型的设计场景1.大型客户维度。例如,80% 的事实表涉及匿名用户,或者能收集到很少详细信息的用户,另外有20% 涉及到可靠的注册客户,这些注册用户的用户维度信息与多个用户维度表相连接。
2.银行、经纪行和保险公司的金融产品维度,因为每个单个产品具有许多其他产品不具备的特殊属性。
3.多个企业共用的日历维度表。但每个企业的财政周期不同,节假日不同等等。在数据仓库的环境中用雪花模型,降低储存的空间,到了具体某个主题的数据集市再用星型模型。
参考文献:
1.https://www.jianshu.com/p/81685a8414bf
2.https://en.wikipedia.org/wiki/Ralph_Kimball
3.https://www.oracle.com/webfolder/technetwork/tutorials/obe/db/10g/r2/owb/owb10gr2_gs/owb/lesson3/starandsnowflake.htm -
相关阅读:
Redis 排障:你永远不知道告警和下班,谁先到来?
Spring AOP原理之动态代理
AndroidStudio gradle 7.0+配置说明
React——form的校验和验证规则(使用formik,yup)
学习黑马AJAX
面试准备2022-08
TSINGSEE青犀视频AI智能算法平台电动车入梯检测解决方案
CorelDRAW2024最新版本的图形设计软件
leetcode每日一题第二十五天-剑指 Offer 67. 把字符串转换成整数(middle)
sourTree提交代码遇到问题解决办法
- 原文地址:https://blog.csdn.net/bitcarmanlee/article/details/126584817