-
八大排序算法和时间复杂度
时间复杂度一套图 搞懂“时间复杂度”_12 26 25的博客-CSDN博客_时间复杂度
排序代码 数据结构和算法Java实现(韩顺平)_看向未来213的博客-CSDN博客
冒泡排序
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。
比较相邻的元素。如果第一个比第二个大,就交换它们两个;对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;针对所有的元素重复以上的步骤,除了最后一个;重复以上步骤,直到排序完成。
两两相比,错位则交换。每次找出一个最大值。双层for循环,时间复杂度为O(n2)


选择排序
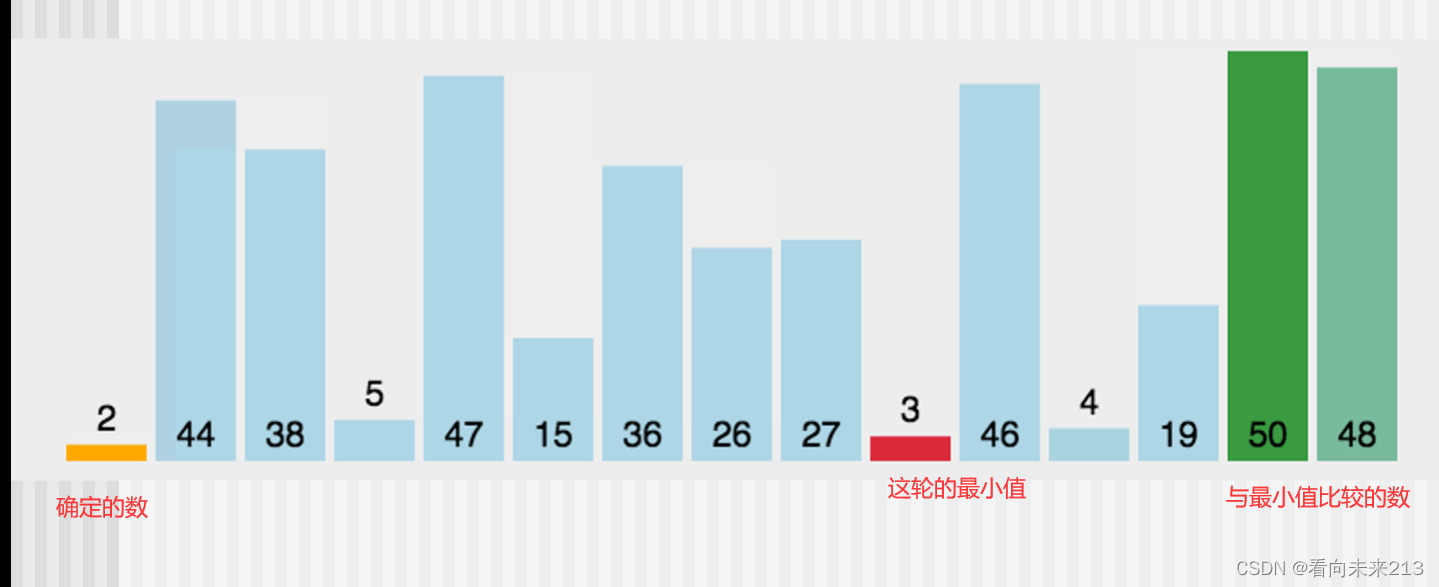
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕.
找一个数,设其为最小值,依次跟其他数比较,找到比设定的最小值更小的数,将其设为最小值,一轮比较结束后,将最小值设置到外层for循环记录的位置上。
两层for循环,时间复杂度为O(n2)
插入排序
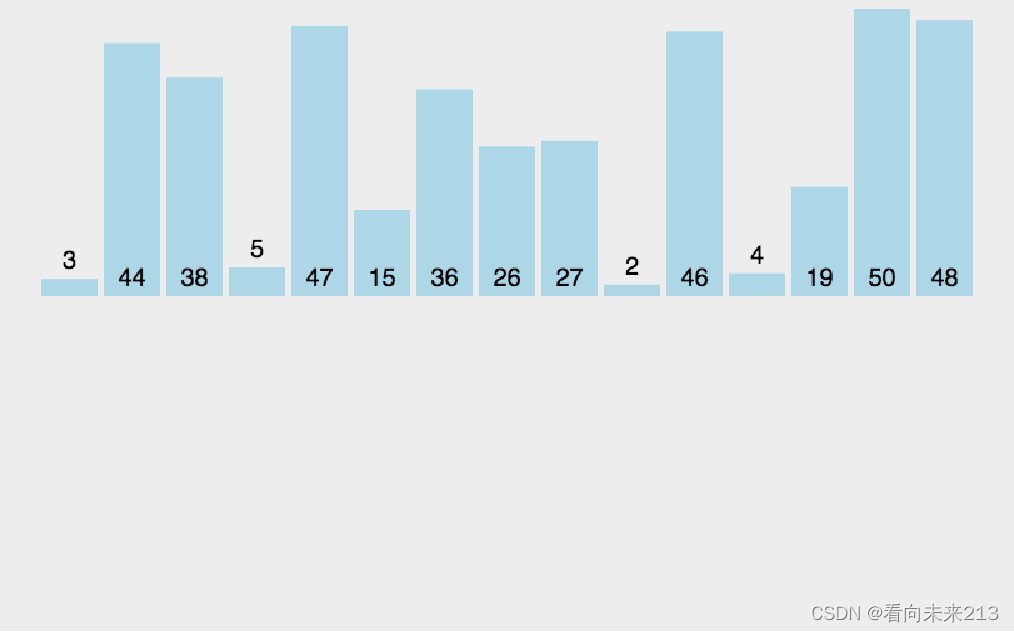
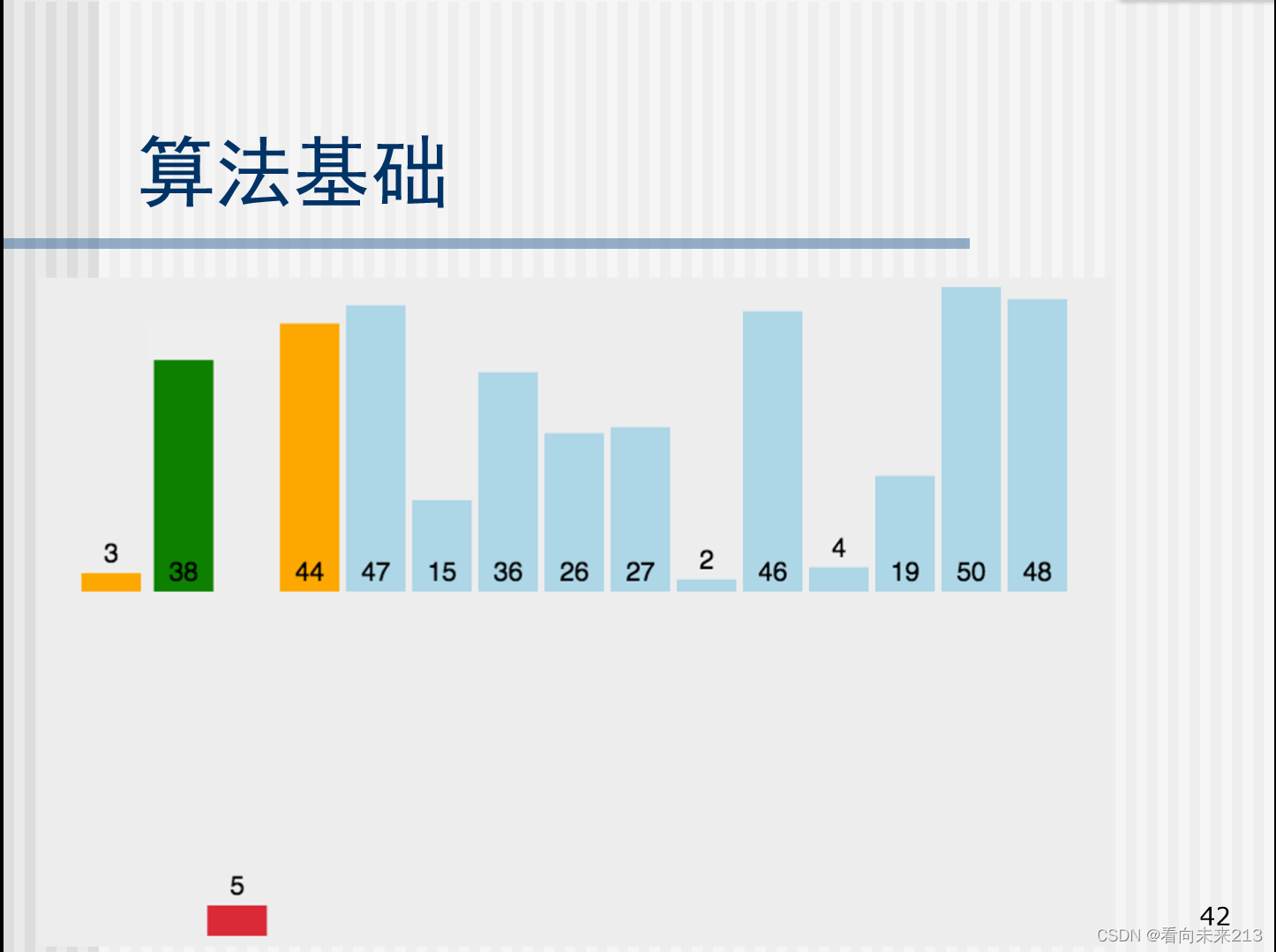
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
将第一个数看成一个有序队列,剩下的数看成一个无序队列,从无序队列中取出一个数(设为 t ),将其值和下标都保存在一个变量中,将这个数根据从后往前的顺序,在有序队列中寻找自己的位置。如果 t 大于有序队列中的数,则该位置就是 t 的位置。如果 t 小于有序队列中的数(设为 x ),x 后移一位。下标前移,再次比较。
两层for循环,时间复杂度为O(n2)
希尔排序
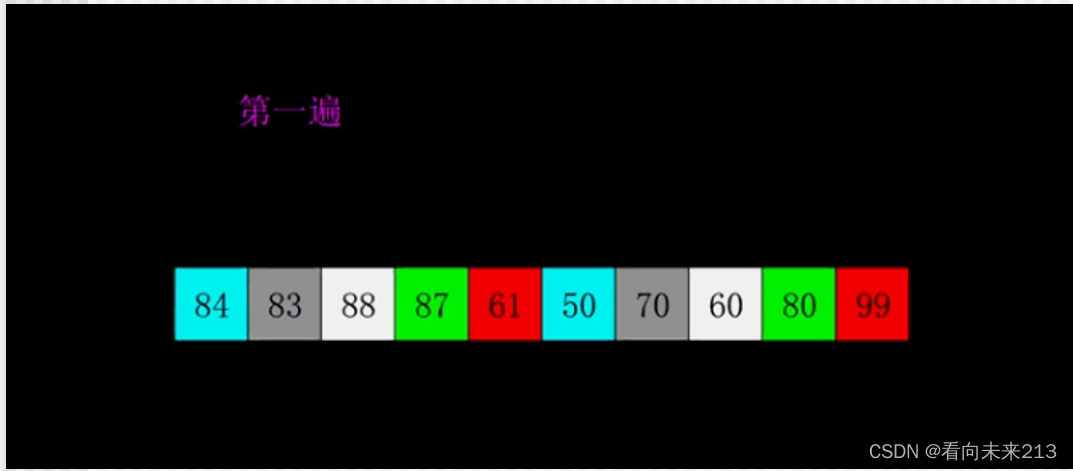
前面的几个排序都是依次相邻的数,进行比较。希尔排序就不是这样,他是横跨几个元素进行比较,就假设有6个数,第一轮,第一个数和第四个数比较,第二个数和底五个数进行比较,第三个数和第六个数比较,跨度为三,按从小到大的顺序排序。第二轮,将跨度除2,跨度为1,即两两比较。
在两个数交换时,不要临时创建变量,大数据量的情况下,浪费大量资源
我们下面选择的增量序列{n/2,(n/2)/2...1}(希尔增量),其最坏时间复杂度依然为O(n2),一些经过优化的增量序列如Hibbard经过复杂证明可使得最坏时间复杂度为O(n3/2)。
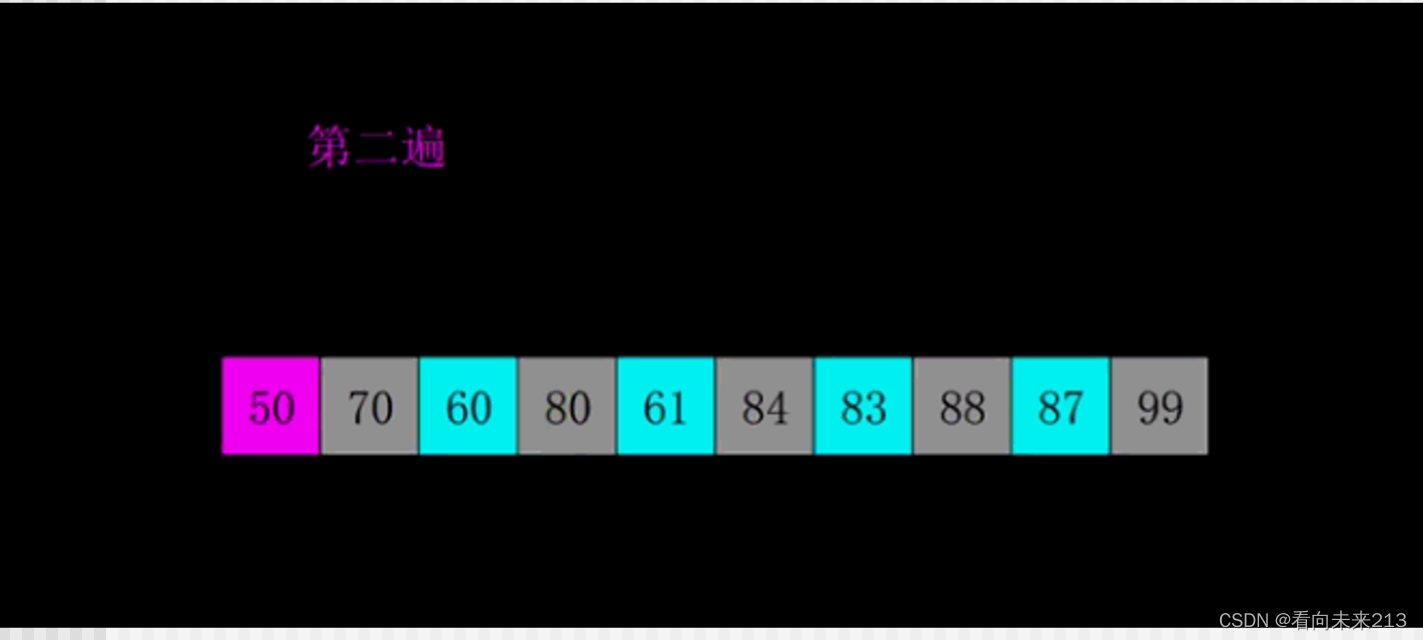
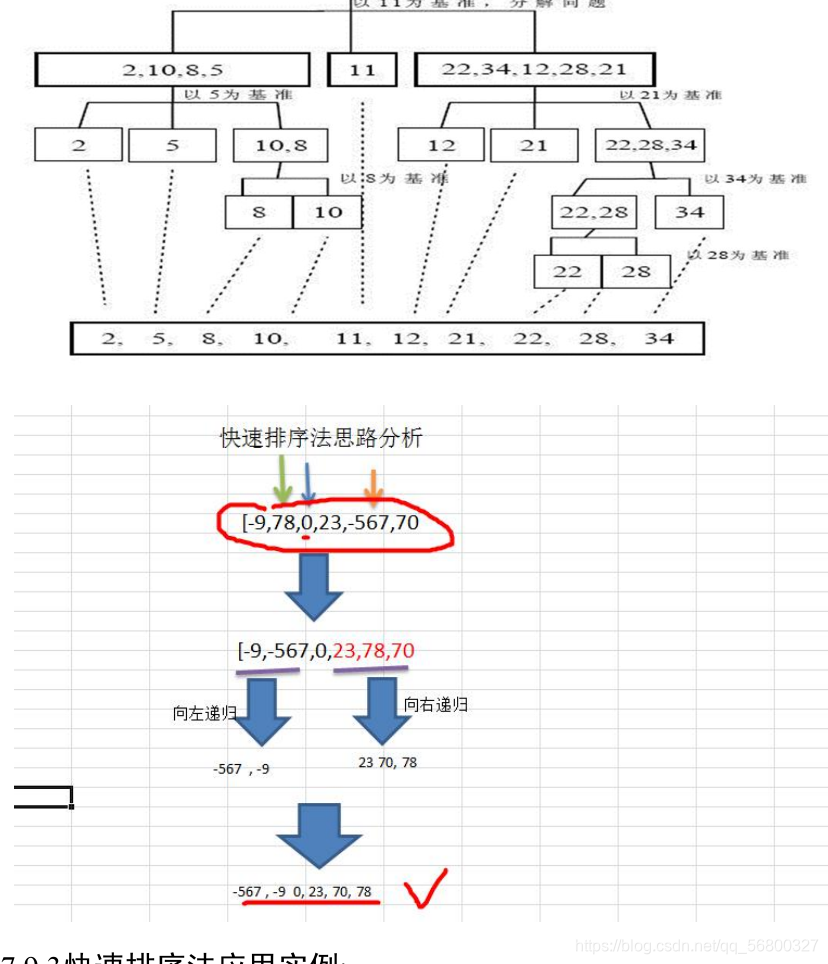
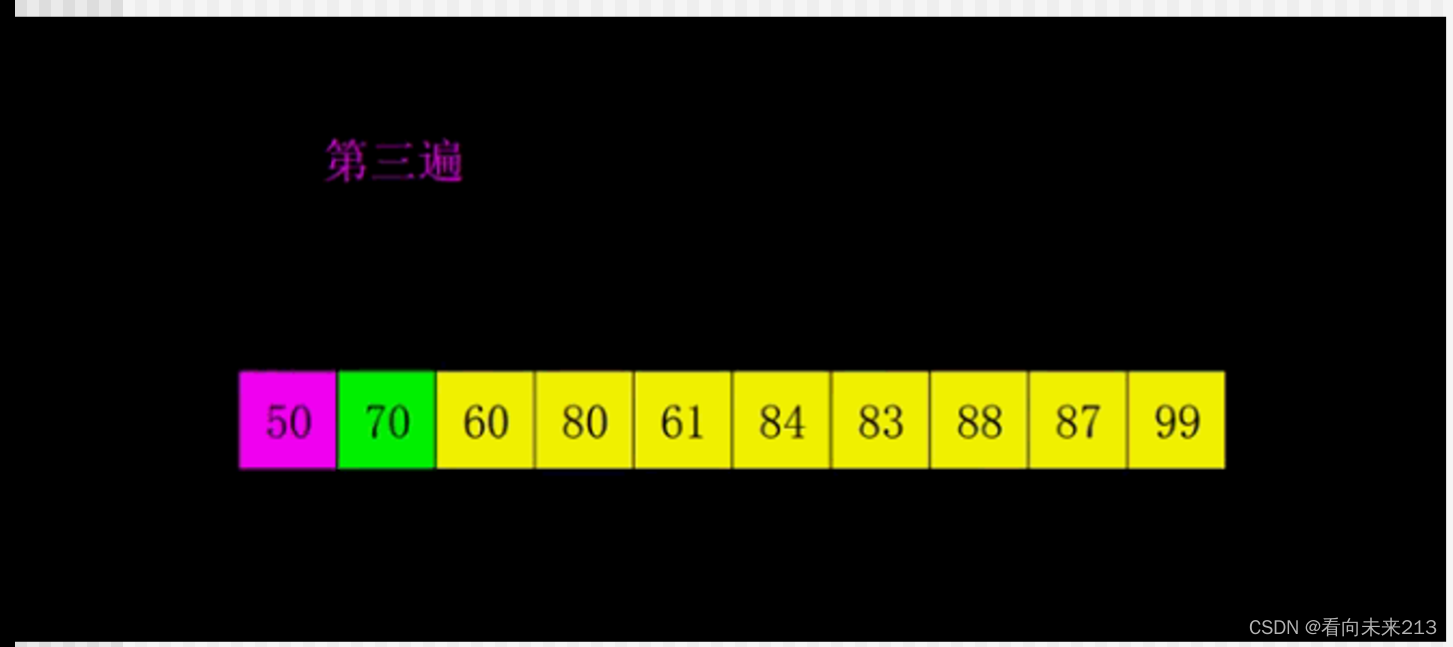 快速排序
快速排序在数组中,拿第一个数,设置为temp。temp右边的下标设置为x,数组末端的下标设置为y。
移动y,与temp上的值比较,找到一个小于temp的下标,取代x的位置。
移动x,与temp上的值比较,找到一个大于temp的下标,取代y下标的值
在不超过下标的前提下,循环执行
当x==y时,找到了temp的正确位置。再递归temp的两边。
归并排序
-
相关阅读:
DFP 数据转发协议 规则说明(二)
在Python中寻找数据异常值的三种方法
ES6 Proxy
10CQRS
10.springboot热部署
博客园美化显示效果
Java8实战-总结34
数据库设计与前端框架
Spring解析之finishBeanFactoryInitialization即初始化单例bean
提升您的 Go 应用性能的 6 种方法
- 原文地址:https://blog.csdn.net/qq_56800327/article/details/126584857