-
一文解读所有HashMap的面试题
关于 HashMap 阿粉相信大家再面试的时候,是非常容易被问到的,为什么呢?因为至少是在 JDK8 出来之后,非常容易被问到关于 HashMap 的知识点,而如果对于没有研究过他的源代码的同学来说,这个可能只是说出一部分来,比如线程安全,链表+红黑树,以及他的扩容等等,今天阿粉就来把 HashMap 上面大部分会被在面试中问到的内容,做个总结。
HashMap
说到 HashMap 想必大家从脑海中直接复现出了一大堆的面试题,
- HashMap 的数据结构
- JDK7 和 JDK8 HashMap哪里不一样
- HashMap是否安全
- HashMap 的扩容机制
说到这里,我们就来挨着分析一下这个 HashMap 的这写面试题。
HashMap 的数据结构
这个 HashMap 的数据结构,面试官这个问题,属于那种可大可小的,往大了说,那就是需要你把所有的关于 HashMap 中的内容都详细的解释明白,但是如果要是往小了说,那就是介绍一下内部结构,就可以了。
阿粉今天来分析一下这个数据结构了。
HashMap 里面有几个比较重要的参数:
//默认初始容量——必须是2的幂 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//当没有构造函数中指定使用的负载系数 static final float DEFAULT_LOAD_FACTOR = 0.75f;
//扩容的阈值,等于 CAPACITY * LOAD_FACTOR static final int TREEIFY_THRESHOLD = 8;
//降容的阈值 static final int UNTREEIFY_THRESHOLD = 6;
//扩容的另外一个参数 static final int MIN_TREEIFY_CAPACITY = 64;
参数我们都看到了上述的这些内容了,如果用大白话,怎么去形容这些参数呢?其实这就涉及到这个后面的 JDK8 中的 HashMap 不一样的结构了,
我们也知道 JDK8 中的 HashMap ,如果在横向上是数组的话,那么他的纵向的每一个元素上面,都是一个单项的链表,而这个链表,会根据长度,来进行不通的演化,而这个演化就是扩容成为树结构和降容成为链表结构的关键,而这些关键,都是通过这些参数来进行的定义。
CAPACITY 就相当于是 HashMap 中的默认初始容量。
LOAD_FACTOR 负载因子 。
TREEIFY_THRESHOLD 树化的阈值,也就是说table的node中的链表长度超过这个阈值的时候,该链表会变成树 。
UNTREEIFY_THRESHOLD 树降级成为链表的阈值(也就是说table的node中的树长度低于这个阈值的时候,树会变成链表) 。
MIN_TREEIFY_CAPACITY 树化的另一个参数,就是当hashmap中的node的个数大于这个值的时候,hashmap中的有些链表才会变成树。
transient Node
有些小伙伴在面试的时候,就会说,当 HashMap中的某个 node 链表长度大于 8 的时候,HashMap 中的这个链表就会变成树,实际上不是的,这个还和 MIN_TREEIFY_CAPACITY 有关系,也就是说整个 HashMap 的 node 数量大于64,node 的链表长度大于 8 才会变成树。
JDK7 和 JDK8 HashMap哪里不一样
JDK7我们大家也都知道,如果按照横向是数组,那么他的纵向每个元素上面,都是一个单向的链表,而横向上,每一个实体,就相当于是一个 Entry 的实例。
而这每一个 Entry 中都包含了四个属性,
- key
- value
- hash值
- 用于单项列表的next
就像下图这个样子:
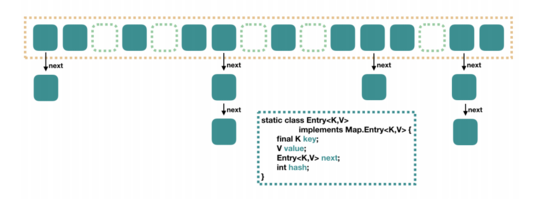
JDK7
所以 JDK7 的 HashMap 的数据结构就是 数组+链表 的形式构成 。
而 JDK8 就不一样了,因为他们的内部很巧妙的给增加了红黑树,如下图:

JDK8
所以 JDK8 的 HashMap 的数据结构就是 数组+链表+红黑树 的形式构成了。
HashMap是否安全
一说这个,肯定都是非常基础的面试题,都知道 HashMap 是属于那种线程不安全的类,为什么不安全,他不安全到底会提现在哪个地方,难道面试的时候,你就只会说他的内部没有被 synchronize 关键字控制么?
所以,说起 HashMap 的不安全,那么就得从 put 和 get 方法说起了。
这个直接先看内部实现,我们先来看 put 方法,然后去分析这个 put 方法,
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node看到源码之后,我们猜想一下都会有哪些地方会出问题呢?比如,这时候如果有两个线程同时去执行 put
一个线程 A 执行put("1","A");
一个线程 B 执行put("2","B");
如果这个时候线程 A 和 B 都执行了 if ((p = tab[i = (n - 1) & hash]) == null) 但是,如果这个时候线程 A 先执行了 tab[i] = newNode(hash, key, value, null); 这时候,内部是没啥问题的,已经放进去了,
这时候如果线程 B 去执行 tab[i] = newNode(hash, key, value, null); 就会导致 A 线程中的 key 为 1 的元素 A 丢失。直接被线程 B 进行了覆盖,这也是为什么会有一些人说, JDK7 中是对扩容时会造成环形链或数据丢失,而在 JDK8 中是会会发生数据覆盖的情况。
就会出现 null 的问题,这个问题,不论是 JDK7 还是 JDK8 全都有这个问题,如果面试的时候,能够从这个地方分析一下的,至少这个线程不安全,你确实是自己去研究了一下,所以这就可以完美的解释了,HashMap 的线程不安全的问题了。
HashMap 的扩容机制
我们在上面也都列举了一下 HashMap 的一些关键参数,接下来,就来分析他的扩容是怎么实现的 ,
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }这段代码,写的看起来非常的舒服,指定了初始容量和加载因子,下一次需要扩容的容量 threshold 值由 tableSizeFor 方法得出
static final int tableSizeFor(int cap) { int n = cap - 1; // >>>:无符号右移。无论是正数还是负数,高位通通补0。 n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }而 tableSizeFor 这个方法是用于计算出大于等于 cap 值的最大的2的幂值,而后续 HashMap 需要扩容时,每次 table 数组长度都扩展为原来的两倍,所以,table 数组长度总是为2的幂值。
为什么用位移运算,不直接使用.pow的方法, 这个东西,很明显, 位运算这种方式,效率可比.pow的效率要高很多,接下来就是正儿八经的扩容方法了。
final Node
总的来说,扩容就是创建一个新的数组,数组长度为原来的两倍,并将下一次需要扩容的阈值设置为新数组乘以加载因子的大小。
然后将原来数组中的数据移动到新数组中。
如果数组中的元素不是链表和红黑树,那么直接移动到原来旧数组中下标的位置。
否则如果是链表或红黑树,那么其中的数据可能会在原来的位置,或者在原来的位置+原来数组长度的位置,此时将原来的链表或红黑树分为两个链表或红黑树,再把数据移动到相应位置。
你明白了么?
-
相关阅读:
ZXMPS330 全新原装产品 规格及开局设置
正则表达式——Pattern.DOTALL
python在centos7.x下建立虚拟环境
自媒体写手提问常用的ChatGPT通用提示词模板
k8s知识点
Linux 命令行——Linux 正则:grep 的使用
程序员怎样才能写出一篇好的博客或者技术文章?
Android 深入理解 Service 的启动和绑定
2006-2020年各省研发投入强度
给 Linux0.11 添加网络通信功能 (Day1: 确认 qemu-system-i386 提供了虚拟网卡)
- 原文地址:https://blog.csdn.net/m0_73257876/article/details/126578370