-
sql15
 正确答案: A B C 你的答案: B C (错误)
正确答案: A B C 你的答案: B C (错误)幸运安琪头像
幸运安琪
left join 关联条件可以直接用where吗?我记得一般是用ON啊
发表于 2016-08-03 16:24:35
回复(7)
牛客316444号头像
牛客316444号
D的话 s_id 不是teacher表里字段
发表于 2016-06-19 16:21:59努力划水运动员
对于A 选项的解释
1、内联接
(典型的联接运算,使用像 = 或 <> 之类的比较运算符)。包括相等联接和自然联接。
内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。2、外联接。
外联接可以是左向外联接、右向外联接或完整外部联接。
在 FROM子句中指定外联接时,可以由下列几组关键字中的一组指定:
1)LEFT JOIN或LEFT OUTER JOIN
左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值(null)
2)RIGHT JOIN 或 RIGHT OUTER JOIN
将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
3)FULL JOIN 或 FULL OUTER JOIN
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。3、交叉联接
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
FROM 子句中的表或视图可通过内联接或完整外部联接按任意顺序指定;但是,用左或右向外联接指定表或视图时,表或视图的顺序很重要。例子:
a表 id name b表 id job parent_id
1 张3 1 23 1
2 李四 2 34 2
3 王武 3 34 4
a.id同parent_id 存在关系1) 内连接
select a.,b. from a inner join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
a表和b表中中的id为3去掉
假如使用where语句来写:
select a.,b. from a , b where a.id=b.parent_id
2)左连接
select a.,b. from a left join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
3 王武 null3) 右连接
select a.,b. from a right join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
null 3 34 44) 完全连接
select a.,b. from a full join b on a.id=b.parent_id
结果是
1 张3 1 23 1
2 李四 2 34 2
null 3 34 4
3 王武 null发表于 2016-08-01 14:14:52
 正确答案: A 你的答案: A (正确)
正确答案: A 你的答案: A (正确)
青山崖野
在创建表时,启用全文本搜索:
fulltext(detail)
selete与match()和against()一起使用:match():指定被搜素的列;against():指定要使用的搜索表达式,即:
selecte *
from product
where match(detail) against(‘rabbit’);
发表于 2017-08-29 22:47:57
回复(0)正确答案: A B C E 你的答案: E (错误)
我要拿offer!
无论是聚集索引还是非聚集索引,都存在无需访问数据页就可以得到数据
发表于 2019-09-06 17:25:05
ShineHui123
聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度。
发表于 2022-04-16 14:55:31
asnn头像
asnn
AD
A 聚集索引会将表的物理存储顺序改变 所以一个表 只有一个聚集索引
B 全文索引可以用于模糊查询
C 哈希索引仅仅能满足 = in <= >的操作,不能用于范围查询
D 是肯定的菜鸟葫芦娃头像
菜鸟葫芦娃
A D
A 聚簇索引也称为聚集索引,聚类索引,簇集索引,聚簇索引确定表中数据的物理顺序。聚簇索引类似于电话簿,后者按姓氏排列数据。由于聚簇索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚簇索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。B 如果使用模糊匹配 这等价于全表扫描 此时索引就不起效果了。这里说的是模糊匹配 ,而不是全文索引。何为全文索引?
在大微软的数据库中:
MicroSoft SqlServer 中的全文索引是由一系列存储过程来完成的,这些存储过程按先后顺序罗列如下:
1、启动数据库的全文索引服务存储过程:sp_fulltext_service
2、初始化全文索引存储过程:sp_fulltext_database
3、建立全文索引目录存储过程:sp_fulltext_catalog
4、在全文索引目录中添加删除表标记存储过程:sp_fulltext_table
5、在全文索引目录的表中添加或删除列标记存储过程:sp_fulltext_column
说到底是调用一些列存储过程搞定的而并非模糊查询 。个人这么认为全文索引和普通索引(唯一索引、聚集、非聚集之类)的区别(从百度知道搞来的,讲的还是有道理的,连接:http://zhidao.baidu.com/question/1818128608088158588.html)
两种索引的功能和结构都是不同的
普通索引的结构主要以B+树和哈希索引为主,用于实现对字段中数据的精确查找,比如查找某个字段值等于给定值的记录,A=10这种查询,因此适合数值型字段和短文本字段
全文索引是用于检索字段中是否包含或不包含指定的关键字,有点像搜索引擎的功能,其内部的索引结构采用的是与搜索引擎相同的倒排索引结构,其原理是对字段中的文本进行分词,然后为每一个出现的单词记录一个索引项,这个索引项中保存了所有出现过该单词的记录的信息,也就是说在索引中找到这个单词后,就知道哪些记录的字段中包含这个单词了。因此适合用大文本字段的查找。大字段之所以不适合做普通索引,最主要的原因是普通索引对检索条件只能进行精确匹配,而大字段中的文本内容很多,通常也不会在这种字段上执行精确的文本匹配查询,而更多的是基于关键字的全文检索查询,例如你查一篇文章信息,你会只输入一些关键字,而不是把整篇文章输入查询(如果有整篇文章也就不用查询了)。而全文索引正是适合这种查询需求。
C 哈希索引精确查找是比较给力的。
哈希索引的限制:
a、哈希索引只包含哈希码和行指针,不存储字段值,所以无法用索引中的值来避免去读取行。
b、哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。
c、哈希索引也不支持部分索引列匹配查找,必须利用所有索引列,因为哈希值是通过所有索引列计算的。
d、哈希索引只支持等值比较查询,包括=、in()、<=>(安全比较)比较包含null的时候用。哈希也不支持任何范围查询,比方说where price > 100
e、哈希索引非常快,除非有哈希冲突(不同的索引值会有相同的哈希值),这个时候引擎必须遍历链表中的所有行来匹配。
f、哈希冲突较多的时候,比方列上相同的值比较多的时候,索引维护代价就会比较高。D 是对 字段太多 查询的时候索引会根据索引立面包含的列进行检测和排序,所以建立索引也要视情况而定。
编辑于 2015-12-01 17:02:22
一头小菜鸡头像
一头小菜鸡
hash索引适合单值查询,btree索引寄适合单值查询又适合范围查询
发表于 2019-09-01 10:04:19此广告位出租
hash索引用于=、in查询,为确定值的查询。btree用于<、>和between的范围查询,并且支持排序。
发表于 2019-12-28 00:47:58
正确答案: D 你的答案: B (错误)
解析
SQL的执行顺序是:FROM–WHERE–GROUP BY–HAVING–SELECT–ORDER BY
正确答案: B 你的答案: A (错误)
1129
正确答案: B 你的答案: C (错误)
张(…)♡
用订单表和订单项表解释一下,订单表相当于父表,订单项表相当于子表,一个订单中可以包括多个订单项。订单id是父表的主键,根据订单id在子表查询相应的订单项集合。因为使用的是订单id,所以应该对应父表是主索引,而在子表中只是一个普通字段,所以是普通索引。
发表于 2019-09-29 14:44:44

正确答案: A 你的答案: C (错误)
正确答案: A 你的答案: C (错误)
在进行数据库逻辑设计时,可将 E-R 图中的属性表示为关系模式的属性,实体表示为元组,实体集表示为关系,联系表示为关系。故正确答案为 A 。
omerryo
编辑于 2018-11-22 11:41:36
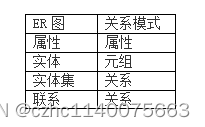
图片转载自omerryo
看了下哪个练
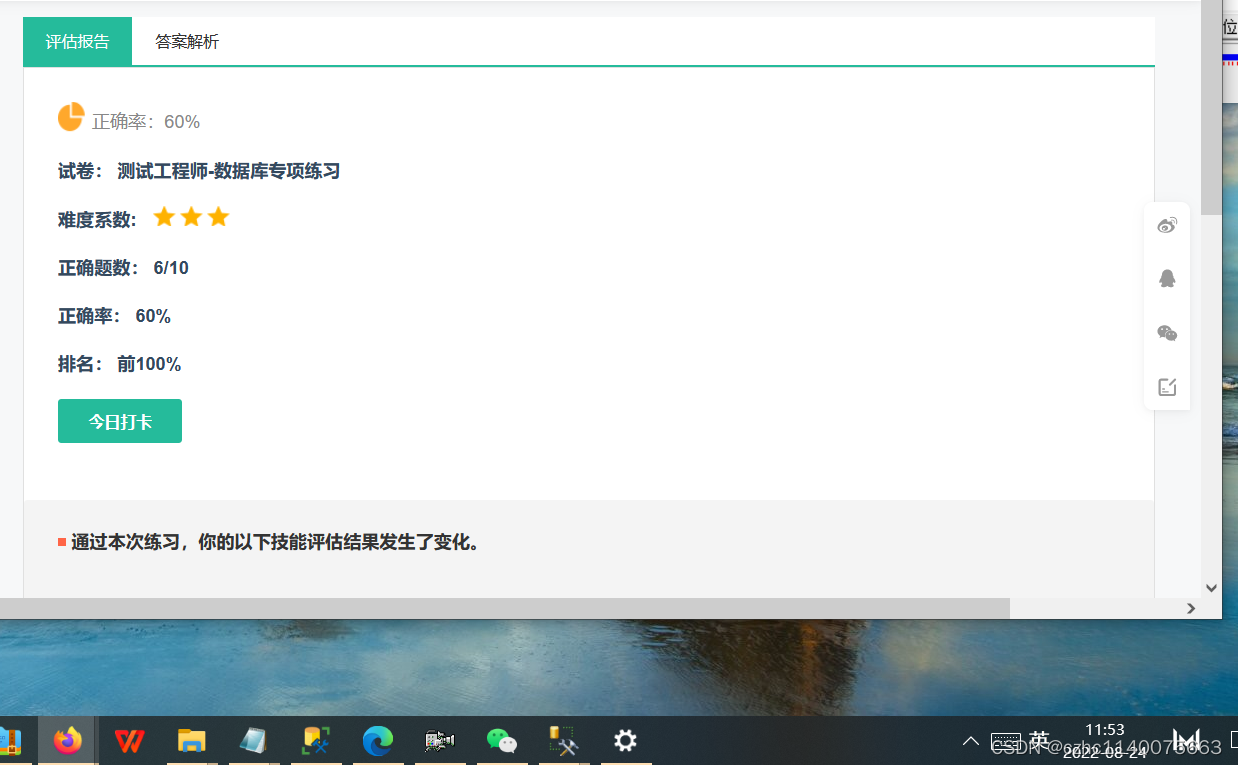 正确答案: B 你的答案: B (正确)
正确答案: B 你的答案: B (正确)Aline.ET头像
Aline.ET
为了反映事物本身及事物之间的联系,数据库中的数据必须有一定的结构,这种结构用数据模型来表示,一个具体的数据模型应当正确地反映出数据之间存在的整体逻辑关系,所以数据模型质量的高低直接影响数据库性能的好坏。
发表于 2018-08-27 09:07:10答案错了
正确答案: D 你的答案: A (错误)
正确答案: D 你的答案: B (错误)三毛12头像
三毛12
并发不加以控制会带来数据的不一致性问题,而对并发加以控制了,也就是加锁了,但是锁的控制没有弄好,才会带来死锁问题
发表于 2017-09-11 15:06:43
正确答案: A 你的答案: D (错误)
已注销这是关系代数运算中 专门的关系运算中的除运算,语义是:
设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性及其值,且T的元组与关系S的元组的所有组合都在R中。- 1
对于这个题来说,关系T包含所有在SC但不在C中的属性及其值,且T的元组与关系C的元组的所有组合都在SC中。
组合起来之后就是
T C
101 C1
101 C2
102 C1
102 C2
… …这个结果就是选修了表C中全部课程的学生学号
发表于 2018-12-26 16:13:00fkyyds头像
fkyyds
T=πid,sno(SC)/C,有两次操作,首先得到SC在学号和课号上的投影R:
id sno
101 C1
101 C2
102 C1
102 C2
103 C1
然后才是除运算:R/C
通过象集可以判断。
假设R(X,Y),C(Y,Z),除运算得到的新关系就是P(X):R元组在X上分量值x的象集Yx包含C在Y上投影的集合,Yx就是当X=x时,对应的Y的取值集合。
本题中R(id,sno),C(sno),进行R/C运算,显而易见最后的关系T肯定是学号
R:
101的象集:{C1,C2}
102的象集:{C1,C2}
103的象集:{C1}
C在sno上的投影:
C1
C2
只有101、102的象集包含了C的投影,也就是学号101、102的学生选择了全部课程,
R/C={101,102}发表于 2021-09-26 11:33:12
fkyyds头像
fkyyds
T=πid,sno(SC)/C,有两次操作,首先得到SC在学号和课号上的投影R:
id sno
101 C1
101 C2
102 C1
102 C2
103 C1
然后才是除运算:R/C
通过象集可以判断。
假设R(X,Y),C(Y,Z),除运算得到的新关系就是P(X):R元组在X上分量值x的象集Yx包含C在Y上投影的集合,Yx就是当X=x时,对应的Y的取值集合。
本题中R(id,sno),C(sno),进行R/C运算,显而易见最后的关系T肯定是学号
R:
101的象集:{C1,C2}
102的象集:{C1,C2}
103的象集:{C1}
C在sno上的投影:
C1
C2
只有101、102的象集包含了C的投影,也就是学号101、102的学生选择了全部课程,
R/C={101,102}发表于 2021-09-26 11:33:12
回复(2)
闲鱼总算翻了身头像
闲鱼总算翻了身
设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性及其值,且T的元组与关系S的元组的所有组合都在R中。
对于这个题来说,关系T包含所有在SC但不在C中的属性及其值,且T的元组与关系C的元组的所有组合都在SC中。
发表于 2021-07-22 15:52:33
没看懂
1355
正确答案: B C 你的答案: B (错误)bighand头像
bighand
创建索引的语句是create index indexname on tablename (username (length))
其中若是char和varchar类型,length可以小于字段实际长度,若是blob或text类型,必须指定length!
发表于 2019-06-11 12:49:20
看下到那儿了
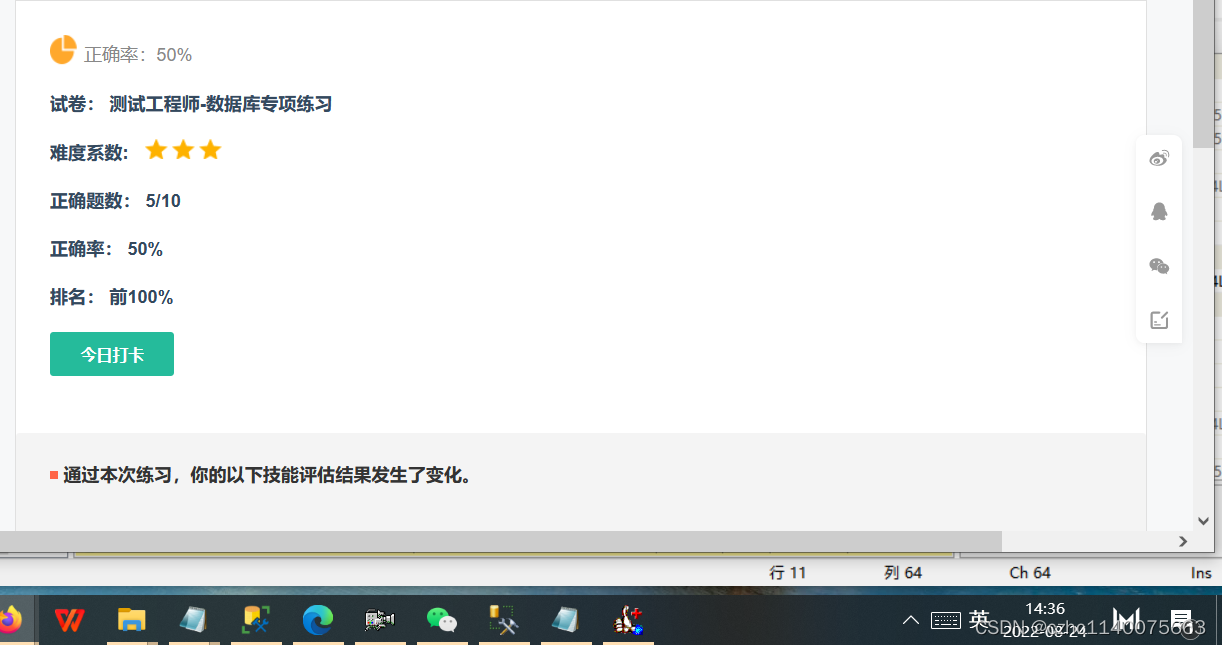 正确答案: C 你的答案: B (错误)
正确答案: C 你的答案: B (错误)其实是菜鸟头像
其实是菜鸟
数据库的三级模式结构分为:概念模式,外模式,内模式
概念模式:也称为逻辑模式
是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
是数据库模式结构的中间层
一个数据库只有一个概念模式
外模式:也称为子模式
对应于用户级
一个数据库可以有多个外模式
内模式:也称为存储模式
对应于物理级
是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式
一个数据库只有一个内模式两级映像:(为了能够在以上三个抽象层次之间的联系和转换,在三级模式之间设计了两层映像)
两层映像保证了数据库中的数据能够具有较高的逻辑独立性和物理独立性。
外模式/模式映像
外模式/模式映像,保证了当模式改变时,外模式不用变(逻辑独立性)
模式/内模式映像
模式/内模式映像,保证了当内模式改变时,模式不用变(物理独立性)摘自:https://blog.csdn.net/u010297957/article/details/50846279
发表于 2018-05-11 10:08:25正确答案: A 你的答案: B (错误)
解析
本题考察知识点:JOIN连接的使用(LEFT JOIN 、JOIN、INNER JOIN、RIGHT JOIN)解题思路:
要找到每个人的任务情况,这就需要连接两张表。但是题目说了没有任务也要输出结果,就表明了即便task没有对应值,也要返回一个NULL值。也就是说person表要获取所有记录。所以此题用LEFT JOIN即可解决,最后按id降序排列。
因此A选项是正确的查询语句;
B选项错在会只获取两表相匹配的数据,没有对应值的就会pass,所以会漏掉没有任务的情况;
C选项错在会获取task表的所有记录,刚好和题意相反了;
D选项同样错在会获取两个表中字段匹配关系的记录,漏掉没有任务的情况。
正确答案: A 你的答案: B (错误)
1522
一包薯条呸呸实体完整性约束
实体完整性(Entity integrity)是指关系的主关键字不能重复也不能取“空值"。
域完整性约束
域完整性是保证数据库字段取值的合理性。
参照完整性约束
参照完整性(Referential Integrity)是定义建立关系之间联系的主关键字与外部关键字引用的约束条件。
用户完整性约束
实体完整性和参照完整性适用于任何关系型数据库系统,它主要是针对关系的主关键字和外部关键字取值必须有效而做出的约束。用户定义完整性(user defined integrity)则是根据应用环境的要求和实际的需要,对某一具体应用所涉及的数据提出约束性条件。这一约束机制一般不应由应用程序提供,而应有由关系模型提供定义并检验
用户定义完整性主要包括字段有效性约束和记录有效性。
发表于 2019-03-08 09:26:25
回复(0)
正确答案: A C D 你的答案: C D (错误)
1523
软工小狮子
自连接查询:在一个连接查询中,涉及的两张表是同一个张表,则是自连接查询 这两张表在一个数据库,相当于连接本身
发表于 04-04 14:26
正确答案: A B C E F G 你的答案: E F (错误)
小小程序元
存储过程一般作为独立的部分进行运行 ,不作为查询语句的一部分
发表于 2019-09-25 16:22:36
StevenDream
SQL中存储过程和函数的区别
函数只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行。执行的本质都一样。 函数限制比较多,比如不能用临时表,只能用表变量.还有一些函数都不可用等等.而存储过程的限制相对就比较少- 一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
- 对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
- 存储过程一般是作为一个独立的部分来执行(EXEC执行),而函数可以作为查询语句的一个部分来调用(SELECT调用),由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
- 当存储过程和函数被执行的时候,SQL Manager会到procedure ***中去取相应的查询语句,如果在procedure ***里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
Procedure 中保存的是执行计划 (execution plan) ,当编译好之后就执行procedure 中的execution plan,之后SQL SERVER会根据每个execution plan的实际情况来考虑是否要在中保存这个plan,评判的标准一个是这个execution plan可能被使用的频率;其次是生成这个plan的代价,也就是编译的耗时。保存在中的plan在下次执行时就不用再编译了。
原为链接:https://www.cnblogs.com/jacketlin/p/7874009.html
编辑于 2019-11-27 16:58:54
看下在哪
 通过对比 发现
通过对比 发现
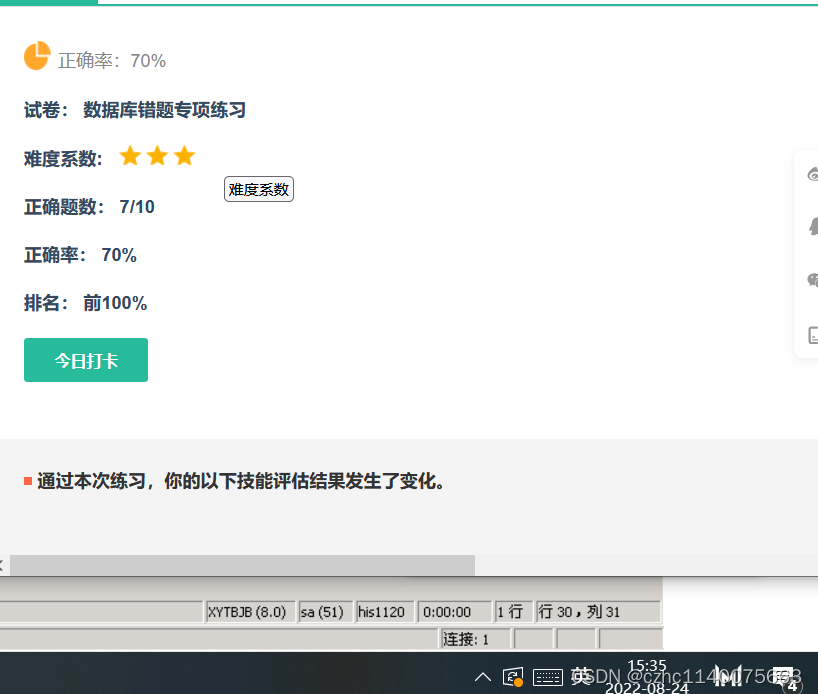 解析
解析SQL的执行顺序是:FROM–WHERE–GROUP BY–HAVING–SELECT–ORDER BY
尚尚😝
三级模式
内模式(存储模式 物理级别)-----模式(概念模式 概念级)-----外模式(子模式 用户级)
模式 看全局 开发者的
外模式 看部分,给用户的
内模式 数据的底层描述
发表于 2019-07-23 14:25:08
回复(0)牛客316444号
D的话 s_id 不是teacher表里字段
发表于 2016-06-19 16:21:59
正确答案: A B C 你的答案: A B C (正确)
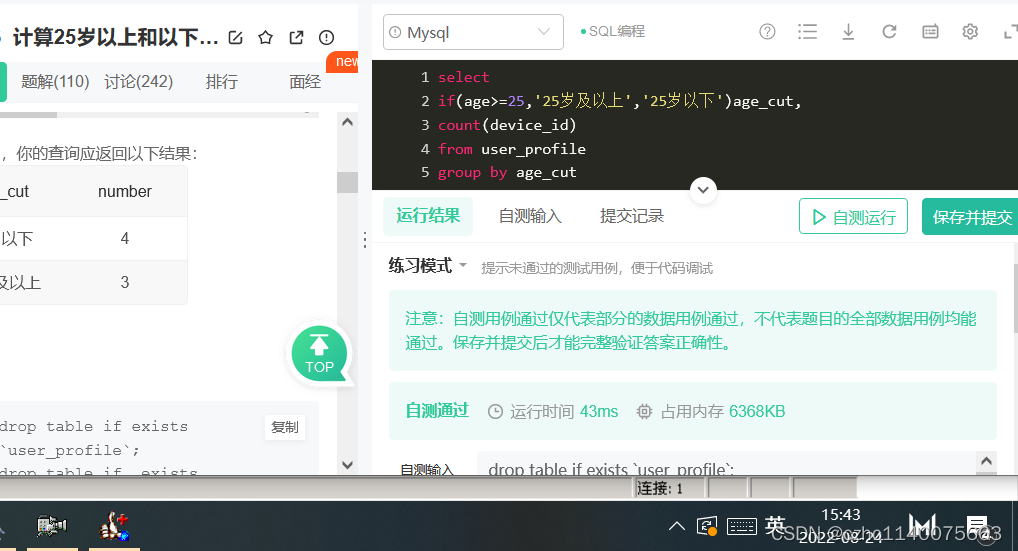
在这里插入代码片select if(age>=25,'25岁及以上','25岁以下')age_cut, count(device_id) from user_profile group by age_cut- 1
- 2
- 3
- 4
- 5

0ed0a4d09149bb8449199818a23354.png)
在这里插入代码片select device_id,gender, if(age>=25,'25岁及以上', if(age between 20 and 24,'20-24岁',if(age<20,'20岁以下','其他')))age_Cut from user_profile- 1
- 2
- 3
- 4
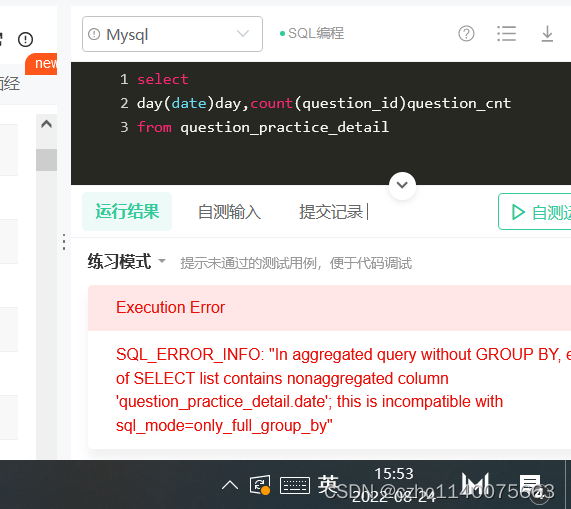
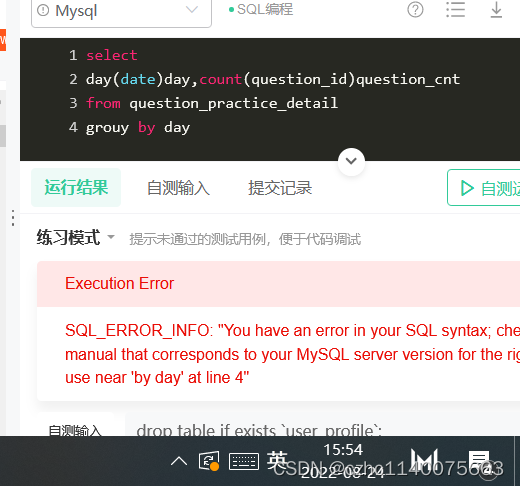
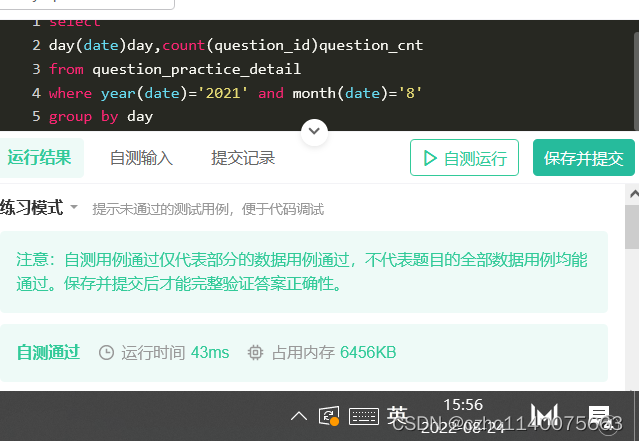
在这里插入代码片select day(date)day,count(question_id)question_cnt from question_practice_detail where year(date)='2021' and month(date)='8' group by day- 1
- 2
- 3
- 4
- 5
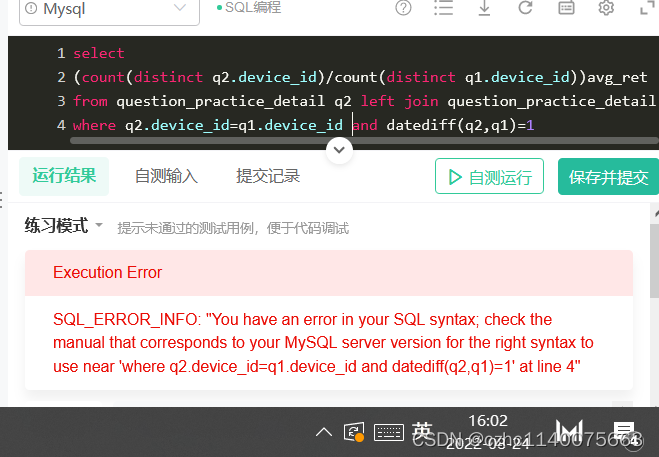
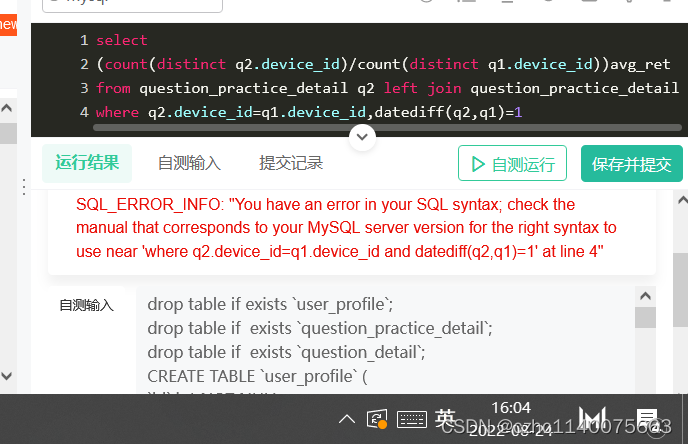
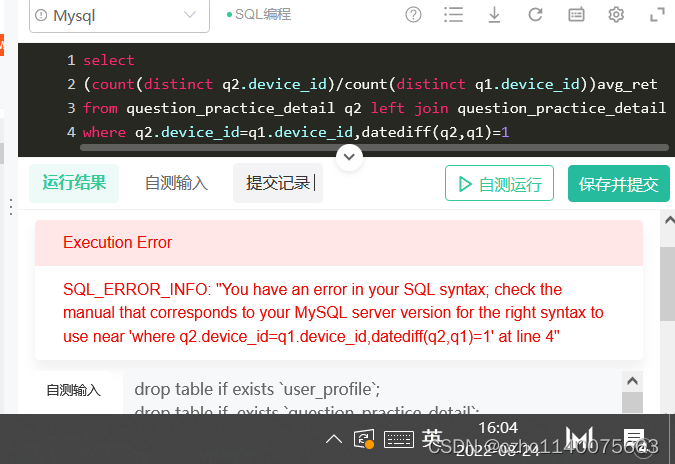 差得有点远啊
差得有点远啊
weis为什么q1左连接q2呢?
GarvinMu
发表于 2021-10-15 15:27
借鉴的到目前为止是2楼的答案,但加上自己的一些理解:(为简便,id=deviceid)- 根据需求首先应该想到计算公式是什么,应该是
(滞后一天日期且前一天上线的唯一id的总数量) / (前一天上线的唯一id的总数量),
也就是用同id但是不同日期的数量进行相除
那么同时考虑id和日期的数量应该考虑同一个id在不同日期的组合
即count(distinct id, date) - 那么第二个问题来了,数量有了,但是如何区分日期呢
那也就用到了datediff,则datediff(date1, date2) = 1即可 - 我们现在有了计算公式的基本元素,那么接下来应该如何执行计算呢
则需要连接两个表,为的就是能够将滞后一天日期的唯一id数量与前一天的进行错位
即select count(distinct q2.id, q2.date) / count(distinct q1.id, q1.date) as avg_reg
from 就这个表 as q1
left outer join 同样这个表 as q2
on q1.id = q2.id
and datediff(date1, date2) = 1;
这里再说一下为什么要用left outer join,因为我们要保证分母的完整性,如果只用了join则会根据联结条件去除q1表中不符合条件的行,则最后结果应该会变成1(自己想的,不知道对不对),所以要用外联结。
看下昨天记得 找不到哪个平路 那个评论了
 开了编辑模式 关了
开了编辑模式 关了
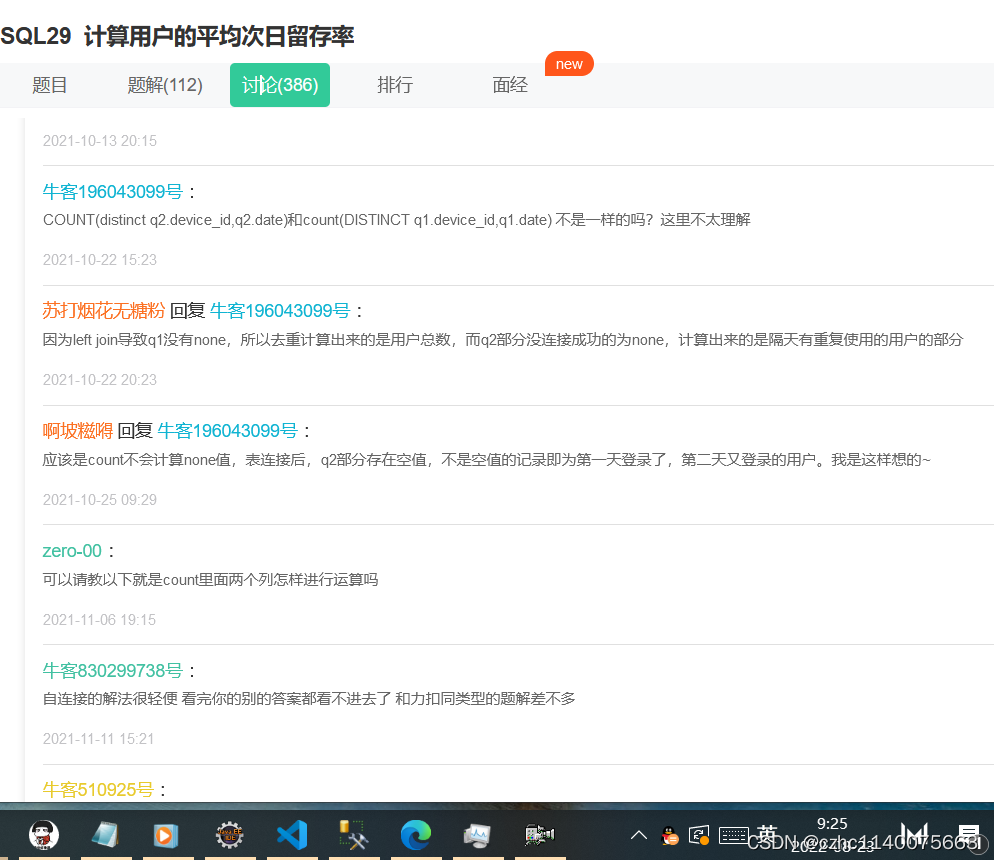 为什么需要去重呢?
为什么需要去重呢?
leftjoin 查一下
添加链接描述
添加链接描述
添加链接描述
 大致理解了》
大致理解了》
left join q1 left join q2 是因为q1是被参照的主体,留存率是是参照前一天的数据。(在代码中,q1所有记录都会被count,而q2作为参照,会出现空值,在日期不同的两天内,而count 是不会计算空值的,所以一÷ 就是参照下 留存率吧)
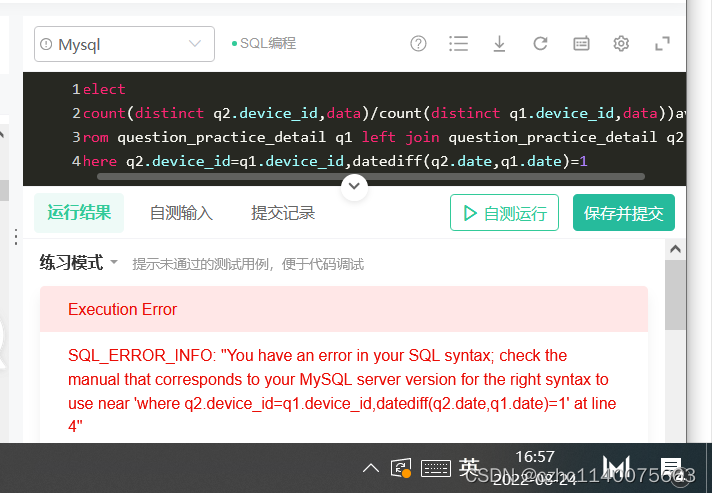
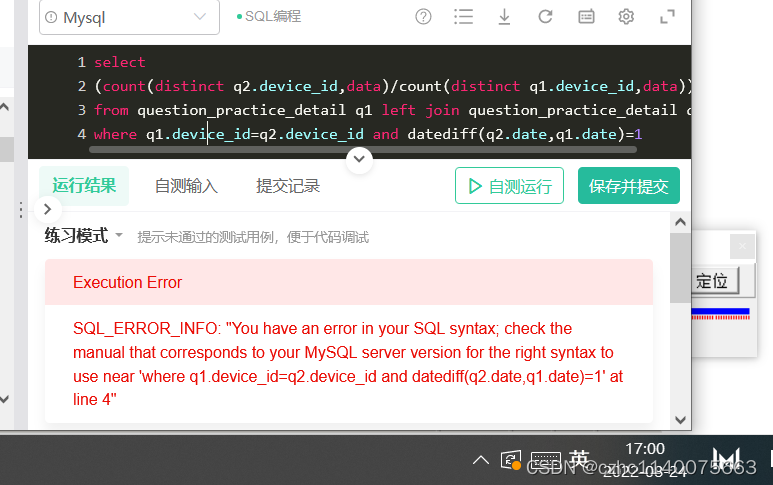
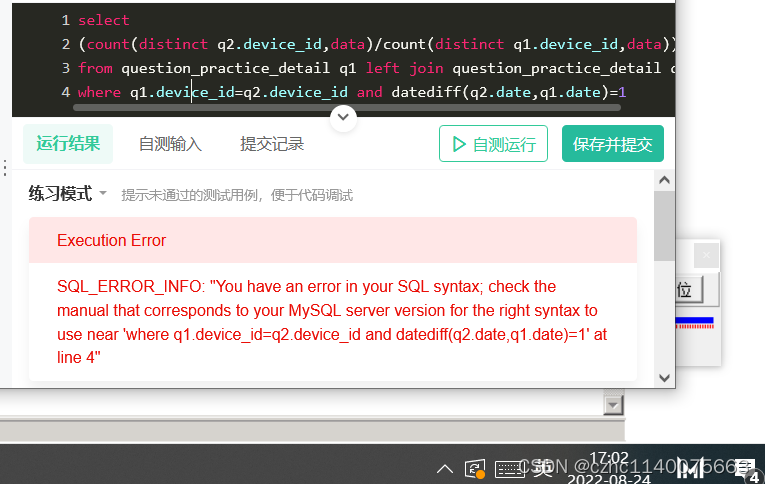
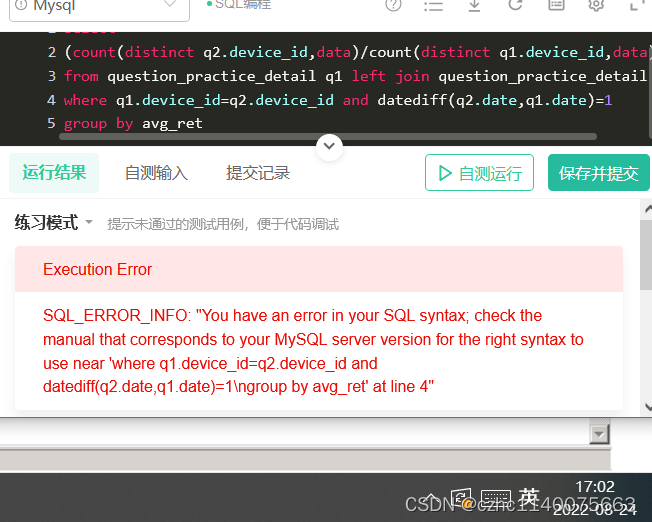
 left join 后跟where 查一下
left join 后跟where 查一下
添加链接描述
添加链接描述
连接时还是得加on啊 改
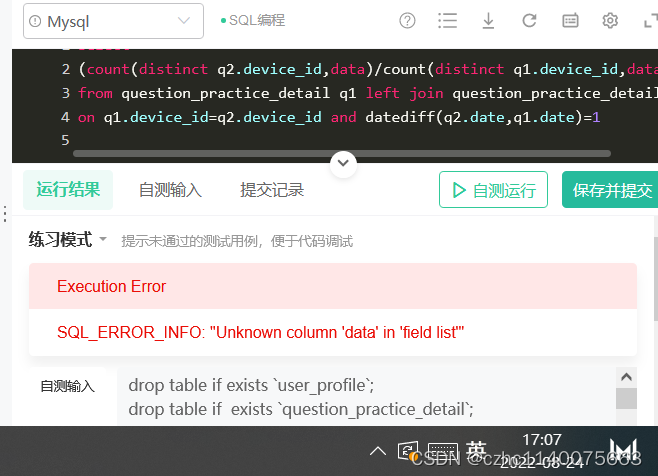 maye 拼错了
maye 拼错了
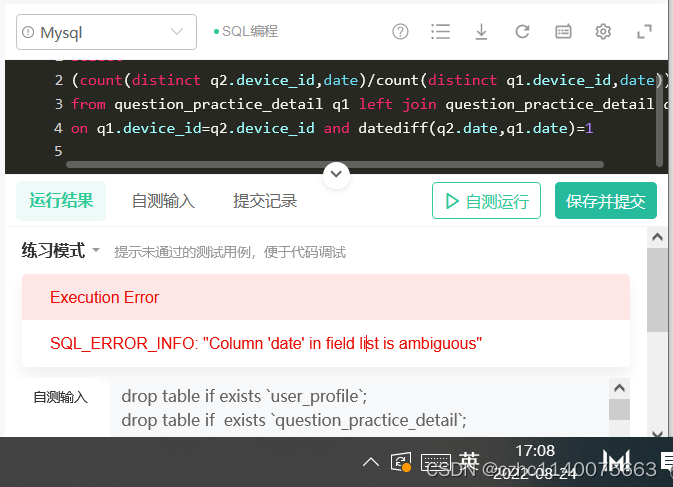
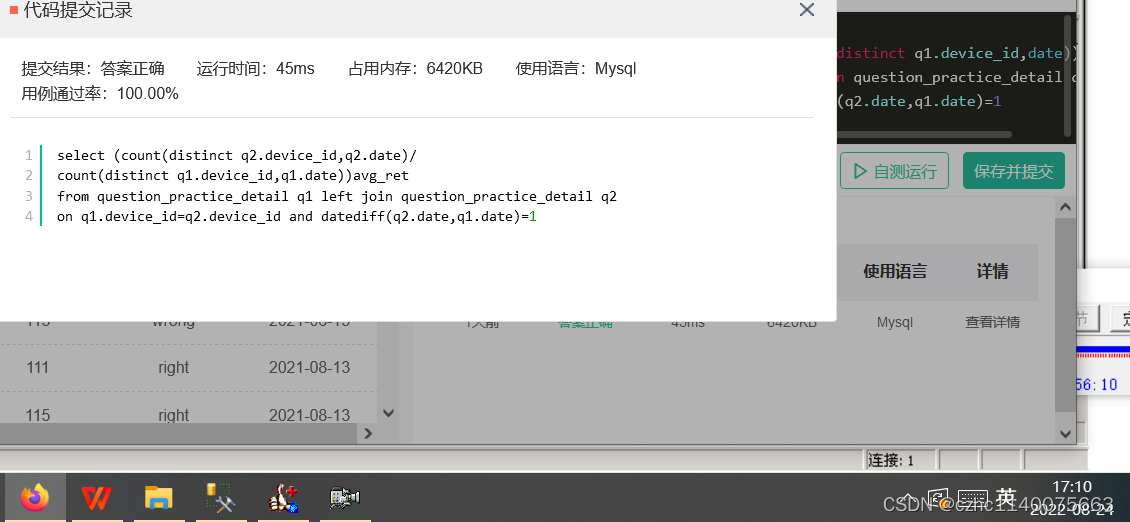
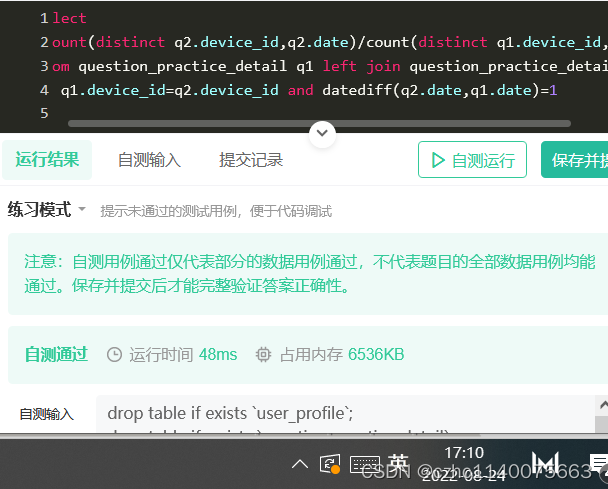

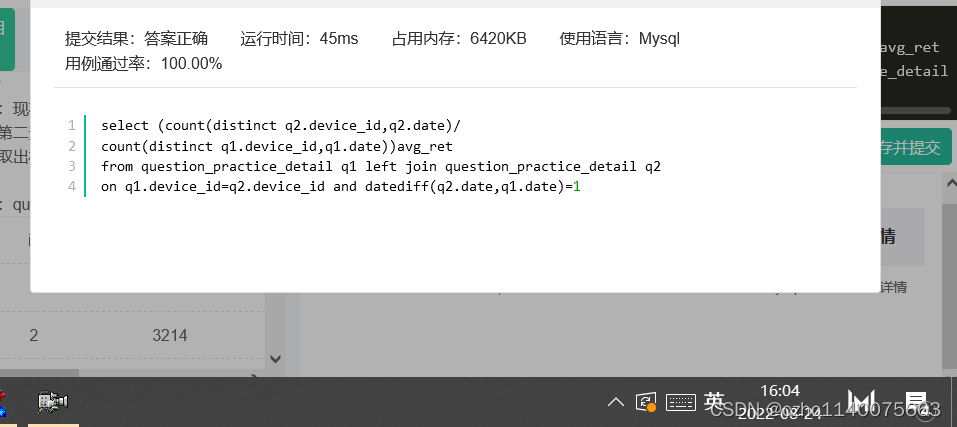
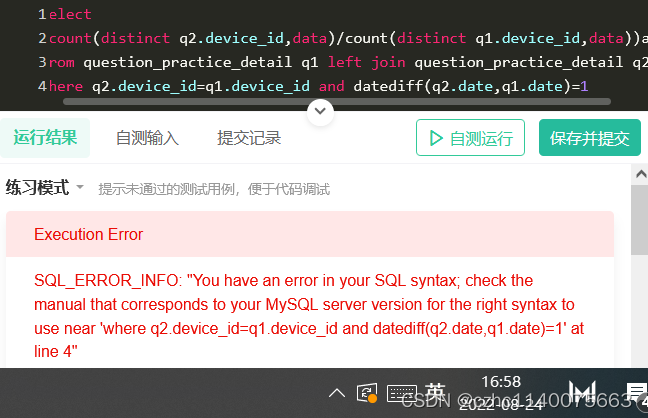
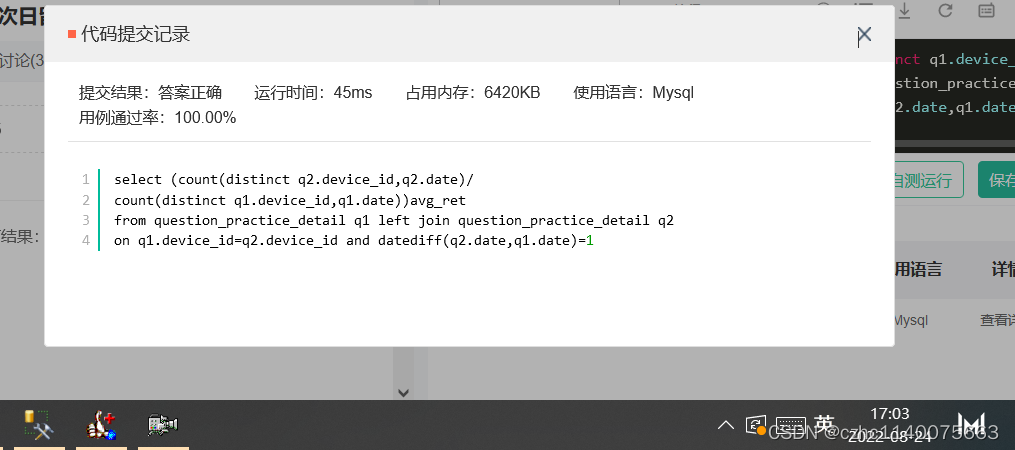
在这里插入代码片select (count(distinct q2.device_id,q2.date)/count(distinct q1.device_id,q1.date))avg_ret from question_practice_detail q1 left join question_practice_detail q2 on q1.device_id=q2.device_id and datediff(q2.date,q1.date)=1- 1
- 2
- 3
- 4
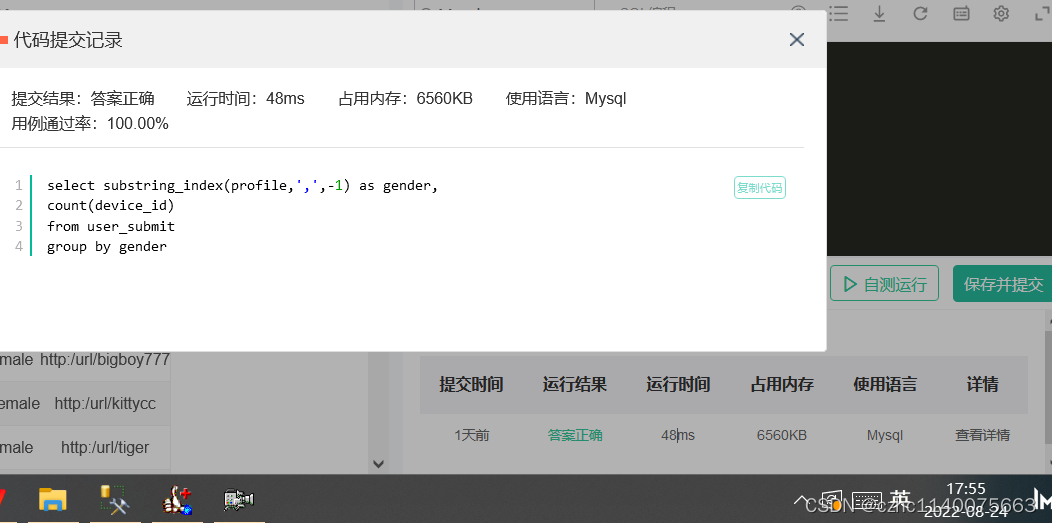 忘了
忘了
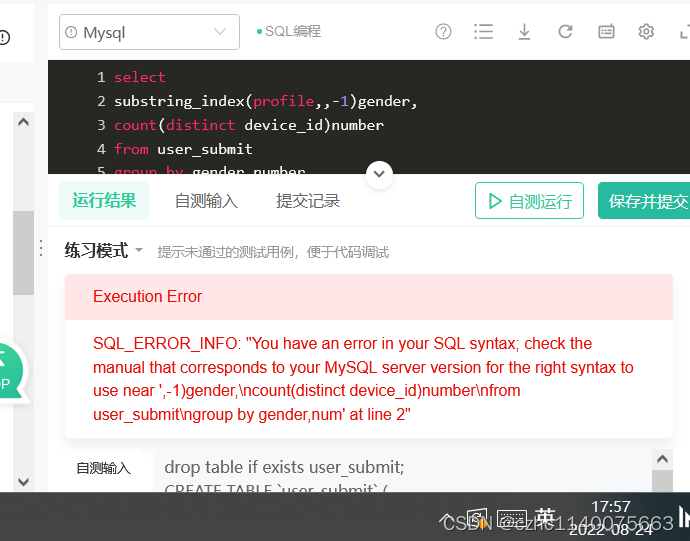
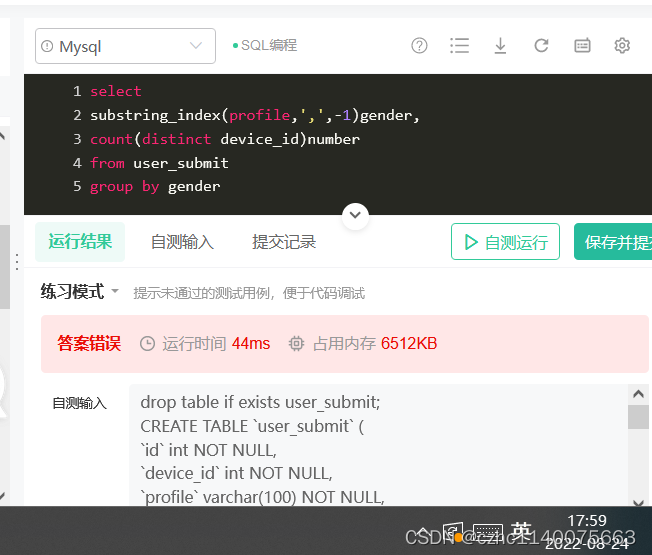
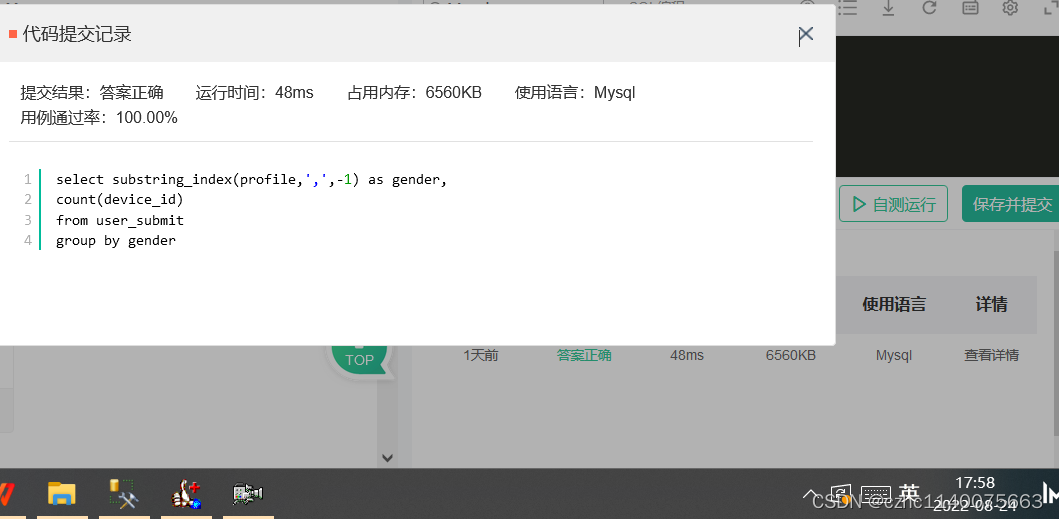 格式不对
格式不对
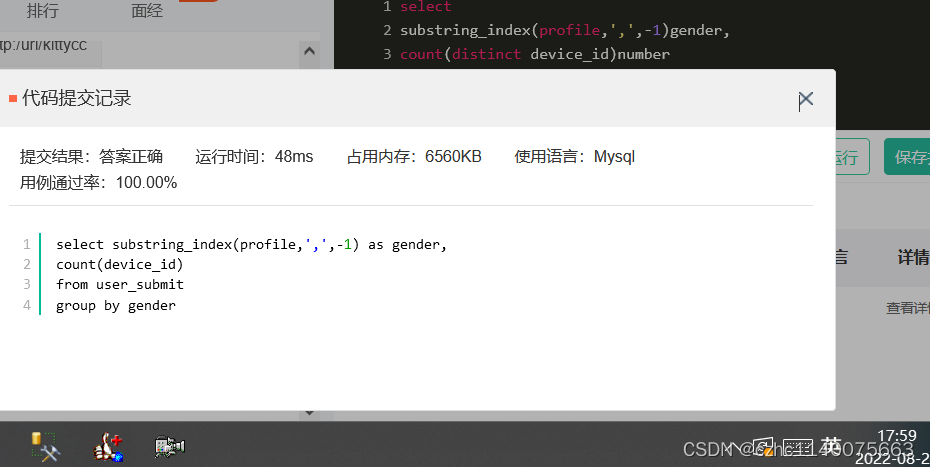

-
相关阅读:
Spark系列之Spark的RDD详解
生产部长修炼宝典_第一篇章:制造企业如何提升生产异常的管理效率?
.NET WinForm开放中的 窗体的 Designer.cs作用
基于SqlSugar的数据库访问处理的封装,支持.net FrameWork和.net core的项目调用
K8S-资源清单和Pod生命周期
ssm学生成绩管理
html常用标签简单汇总
爬虫获取接口数据
【Java】微服务——Feign远程调用
【场景化解决方案】深度融合钉能力,打造全生命周期项目管理
- 原文地址:https://blog.csdn.net/czhc1140075663/article/details/126497327