-
通过WordCount案例深入理解MapReduce的实现过程
1.0MapReduce流程介绍
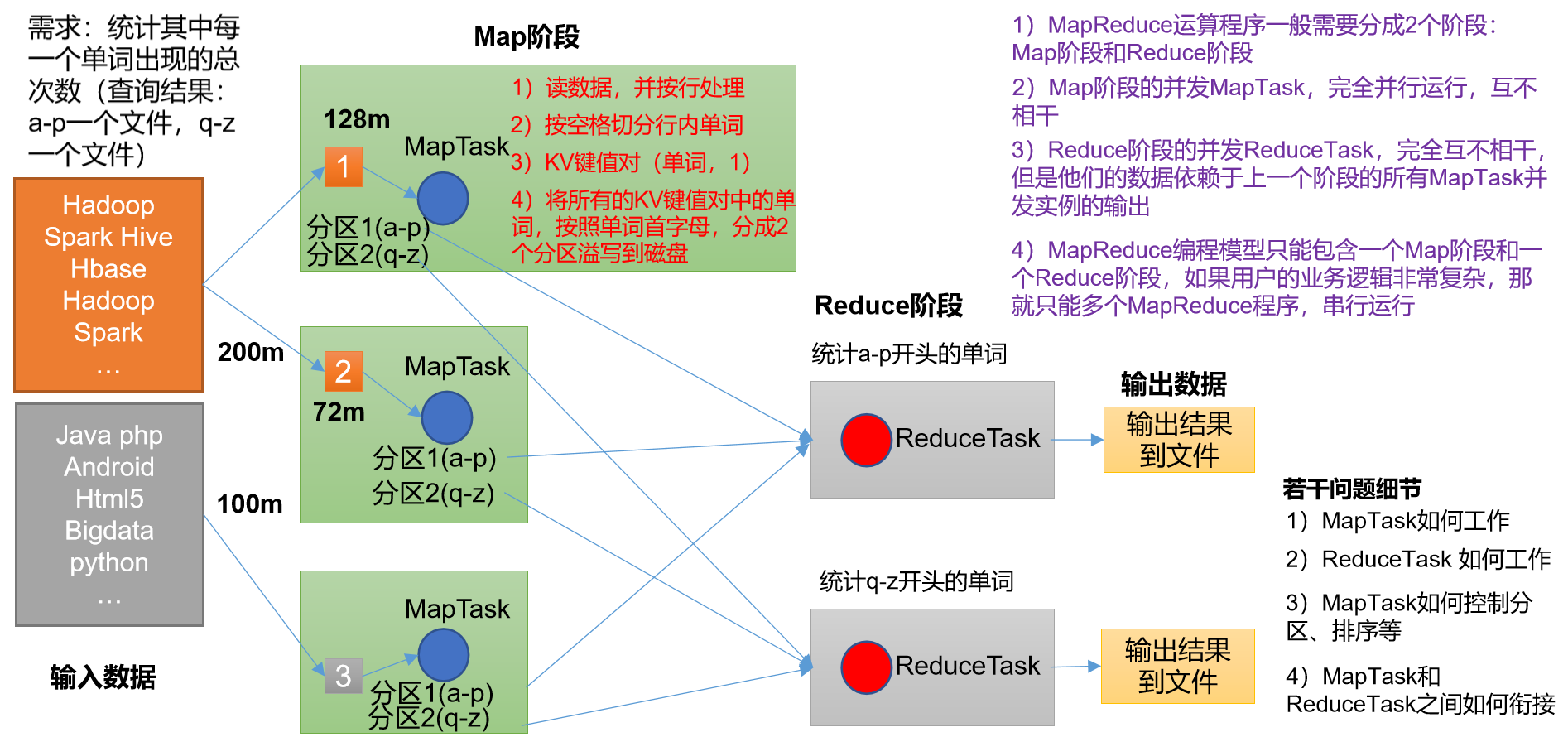
一个完整的MapReduce程序分布运行时有三类实例进程
- MrAppMaster:负责整个程序的过程调度和状态协调
- MapTask:负责Map阶段的整个数据处理流程
- ReduceTask:负责Reduce阶段的整个数据处理过程
理解MapReduce序列化类型
Java类型 Hadoop Writable类型 Boolean BooleanWritable Byte ByteWritable Int IntWritable Float FloatWritable Long LongWritable Double DoubleWritable String Text Map MapWritable Array ArrayWritable Null NullWritable 2.0MapReduce编程规范
用户编写程序分成三个部分:Mapper、Reducer、Driver
Mapper阶段
- 用户自定义的Mapper要继承自己的父类
- Mapper的输入数据是KV对的形式(KV的类型可自己定义)
- Mappper中的业务逻辑写在map()方法中
- Mapper的输出数据是KV对的形式
- map()方法(MapTask进程)对每一个
Reduce阶段:
- 用户自定义的Reduce要继承自己的父类
- Reduce的输入数据类型应对Mapper的输出数据类型也是KV
- Reduce的业务;逻辑写在reduce方法中
- Reduce进程对每一组相同的
Driver阶段:
相当于Yarn集群的客户端,用于提交我们,整个程序到Yarn集群,提交的是封装了MapReduce程序相关运行参数的job对象
3.0编码实现
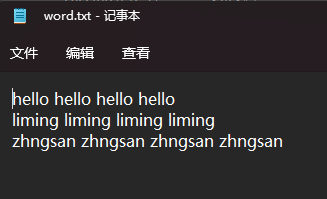
3.1材料准备
准备一个word.txt文件输入相关内容
3.2业务流程介绍

3.3项目准备
2.添加依赖
org.apache.hadoop hadoop-client 3.1.3 junit junit 4.12 org.slf4j slf4j-log4j12 1.7.30 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.创建日志打印文件
(2)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(3)创建包名:com.fang.wordcount
3.3程序编写(详细注释)
创建三个类
实现Mapper的过程
package com.fang.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * KEYIN 输入类型 long * VALUEIN 输入值类型 String * KEYOUT 输出类型 String * VALUEOUT 输出值类型 Int */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { /** * 对于context的理解 * 充当,Map和Reduce之间联络员的角色 */ // 1 获取一行 String line = value.toString(); // 2 切割 String[] words = line.split(" "); // 3 输出 for (String word : words) { k.set(word); context.write(k, v); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
实现Reducer的过程
package com.fang.wordcount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ int sum; IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { /** * 对于Interable的理解 * 将传入的值变成(zhangsan(1,1,1,1))类型 */ // 1 累加求和 sum = 0; for (IntWritable count : values) { sum += count.get(); //获取到count的值为1 } // 2 输出 v.set(sum); context.write(key,v); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
实现Driver的过程
package com.fang.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1 获取配置信息以及获取job对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 关联本Driver程序的jar job.setJarByClass(WordCountDriver.class); // 3 关联Mapper和Reducer的jar job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 4 设置Mapper输出的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 设置最终输出kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 设置输入和输出路径 FileInputFormat.setInputPaths(job, new Path("F:\\桌面\\input\\word.txt")); FileOutputFormat.setOutputPath(job, new Path("F:\\桌面\\output6")); // 7 提交job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
运行结果:

-
相关阅读:
SpringBoot整合Mybatis
深入解析kubernetes controller-runtime
爬虫这样怎么提取href?
亚马逊测评自养号卖家应该要学习哪些知识点呢?
Linux使用netstat查看网络状态
利用Promise封装AJAX
Apollo planning之PathBoundsDecider
Vue2组件通信 - dispatch 和 broadcast
Java入门-------构造方法和构造方法的重载
阿里云产品试用系列-函数计算 FC
- 原文地址:https://blog.csdn.net/m0_58022371/article/details/126542392