-
ElasticSearch高阶操作
1. 准备工作
默认数据库有下面这张表
CREATE TABLE `t_hotel` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '酒店名称', `address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '酒店地址', `brand` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌', `type` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '类型', `price` int(11) NULL DEFAULT NULL COMMENT '酒店价格', `specs` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '规格', `salesVolume` int(11) NULL DEFAULT NULL COMMENT '销量', `synopsis` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '酒店简介', `area` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '区', `imageUrl` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '图片路径', `createTime` date NULL DEFAULT NULL COMMENT '创建时间', `isAd` tinyint(1) NULL DEFAULT 0 COMMENT '是否广告', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 293659 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '酒店信息' ROW_FORMAT = Dynamic;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
表中有N条数据类似于下面这种
INSERT INTO `t_hotel` VALUES (1, '北京市东城区七天酒店', '广西壮族自治区北京县东丽郑州路N座 818276', '七天', '酒店', 847, '五星级', 47, '度假天堂', '北京市', 'https://www.hilton.com.cn/file/images/20160923/20160923102144437IHi7uQu_thum_mid.jpg', '2015-10-26', 0);- 1
我们通过kibana创建索引结构
PUT hotel { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "name":{ "type": "text" }, "address":{ "type": "text" }, "brand":{ "type": "keyword" }, "type":{ "type": "keyword" }, "price":{ "type": "integer" },"specs":{ "type": "keyword" }, "salesVolume":{ "type": "integer" }, "area":{ "type": "text" }, "imageUrl":{ "type": "text" }, "synopsis":{ "type": "text" }, "createTime":{ "type": "date", "format": "yyyy-MM-dd" }, "isAd":{ "type":"integer" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
然后通过自定义的接口把mysql里的数据导入到ES中去
2. 基础查询
1. 查询所有酒店
GET hotel/_search { "query": { "match_all": {} } }- 1
- 2
- 3
- 4
- 5
- 6
2. 分页查询酒店列表
GET hotel/_search { "query": { "match_all": {} }, "from": 0, "size": 5 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3. 分页查询酒店列表
wildcard:会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0个或多个字符)GET hotel/_search { "query": { "wildcard": { "brand": { "value": "美*" } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4. 分页查询酒店列表
展示出"万豪"品牌下的所有酒店信息
term:不会对查询条件进行分词GET hotel/_search { "query": { "term": { "brand": "万豪" } } }- 1
- 2
- 3
- 4
- 5
- 6
可以看到没有匹配到任何结果,因为term是拿整个词“万豪”进行匹配, 而ES默认保存数据是做单字分 词, 将“万豪”划分为了“万”和“豪”, 所以匹配不到结果。
3. bool查询
1. should查询: 只要其中一个为true则成立。

2. must查询: 必须所有条件都成立。

3. must_not查询:必须所有条件都不成立。

4. filter过滤查询: 查询品牌为万豪下的酒店

4. 聚合查询操作
统计品牌为万豪的最贵酒店价格,max、min、sum等等。

5. 分词查询操作
查询出了很多万豪相关的酒店,现在以 北京市东城区万豪酒店 查询name域,可以发现无法查询到结果。

在创建索引时,对于name域,数据类型是 text 。当添加文档时,对于该域的值会进行分词,形成若干 term(词条)存储在倒排索引中。根据倒排索引结构,当查询条件在词条中存在,则会查询到数据。如果词条中没有,则查询不到数
据。
那么对于 北京市东城区万豪酒店 的分词结果是什么呢?

此时可以发现,每个字形成了一个词,所以并没有找到相匹配的词,导致无法查询到结果在ES中内置了很多分词器
• Standard Analyzer - 默认分词器,按英文空格切分
• Simple Analyzer - 按照非字母切分(符号被过滤)
• Stop Analyzer - 小写处理,停用词过滤(the,a,is)
• Whitespace Analyzer - 按照空格切分,不转小写
• Keyword Analyzer - 不分词,直接将输入当作输出
• Patter Analyzer - 正则表达式,默认\W+(非字符分割)
而我们想要的是,分词器能够智能的将中文按照词义分成若干个有效的词。此时就需要额外安装中文分 词器。 对于中文分词器的类型也有很多,其中首选的是:IK分词器。6. IK分词器
1、 首先下载IK分词器
2、 执行安装
采用本地文件安装方式, 进入ES安装目录, 执行插件安装命令:[elsearch@localhost plugins]$../bin/elasticsearch-plugin install file:///usr/local/elasticsearch-7.10.2/elasticsearch-analysis-ik-7.10.2.zip- 1
- 2
安装成功后, 会给出对应提示:

3、重启ElasticSearch服务4、IK分词器最佳运用
analyzer指定的是构建索引的分词,search_analyzer指定的是搜索关键字的分词。
实践运用的时候, 构建索引的时候采用max_word,将分词最大化; 查询的时候则使用 smartword智能化分词,这样能够最大程度的匹配出结果。
例如在创建索引的时候指定分词器

7. 搜索匹配进阶
1. or关系

match搜索实质上就是or关系, 分为”金龙“ 和”金辉“两个关键词进行or关系搜索。2. or关系最小词匹配

这里minimum_should_match设定为2, 只要匹配两个字符,即出现"金龙" 和 “金辉”,那么这样 的数据都会展示出来。
3. and关系

通过operator属性来标识对应的操作。这个时候搜索出来的name会包含"金龙"和"金辉"两个关键 字。4. 短语查询
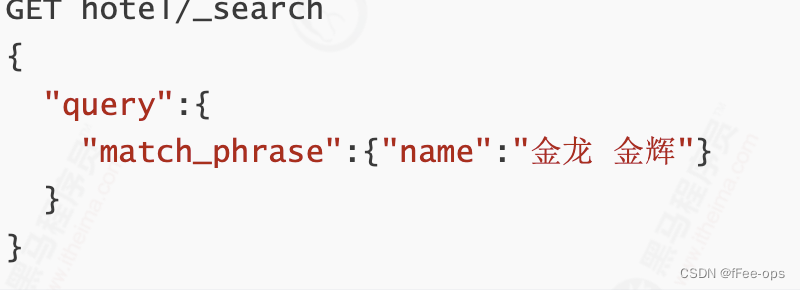
如果想直接搜索某个短语, 比如:金龙 金辉, 可以采用match_phrase
5. 多字段查询
如果想对多个字段同时查询, 可以采用multi_match方式。

同时查询name和address两个属性, 都包含“如心 天津市”的记录, 相比一个属性name的查询, 多出 更多的记录。8. Query String查询
可以采用更简便的方式,直接使用AND、OR和NOT操作。

-
相关阅读:
Android wpa_supplicant 启动
LeetCode每日一题(1169. Invalid Transactions)
在CentOS7中,安装并配置Redis【个人笔记】
【Mycat2实战】四、Mycat实现分库分表【概念篇】
千年常见问题解决办法
技术实现 | Apache Doris Binlog 导入设计与实现
Python之字符串、正则表达式练习
TypeScript的函数(方法)
【经验分享】突然我的SM.MS的图床没法访问了(内附解决方法)
如何做到一套FPGA工程无缝兼容两款不同的板卡?
- 原文地址:https://blog.csdn.net/qq_21040559/article/details/126569029