-
GitModel|Task04|随机模拟
动手学随机模拟
1. 如何通过随机模拟估计看涨期权的报酬分布
关键字:随机模拟,看涨期权,报酬分布
1.1 金融知识:股票与看涨期权
- 权利金
- 行权价格
- 行权
- 买进看涨期权
- 期权的标的资产
期权买方享有权利而不用承担义务
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.sans-serif']=['SimHei','Songti SC','STFangsong'] plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 price_arr = np.linspace(0, 40, 10000) # 定义价格波动,从0~100波动 def get_earnings(price: float, contract_sum: float, contract_cost: float) -> float: return price - (contract_sum + contract_cost) if price > contract_sum else -contract_cost my_earn = [get_earnings(price=price, contract_sum=20, contract_cost = 2) for price in price_arr] plt.figure(figsize=(8,6)) plt.plot(price_arr, my_earn, lw=4, alpha=0.75) plt.xlabel("Price") plt.ylabel("my_earns") plt.title("榴莲合约的收益曲线") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
购买了看涨期权,收益上不封顶,亏损最多就是合约金(权利金)
一般来说,权利金的数额是远远低于标的资产(股票)本身的资产价格。换句话来说,期权是有杠杆的,现在你用2元的本金撬动了几十元的收益,这是个十分关键的地方1.2 问题分析与确定建模思路
看涨期权能得到报酬的关键点就是标的资产的价格,对于看涨期权来说,标的资产的价格越高,我们获得报酬相应的也会越高。
问题的关键是:
- (1)在某个时刻如何估计股票的价格分布
- (2)在某个时刻结合行权价格与股票的价格分布,模拟看涨期权的报酬分布
股票价格是一个随机过程,而看涨期权的价格(也是衍生品的价格)是随机过程的函数
估计股票价格=>使用随机过程近似股票价格这个随机过程# 获取工商银行股票价格数据 import baostock as bs #登录系统 lg=bs.login() #显示登录返回信息 print('login respond error_code:'+lg.error_code) print('login respond error_msg:'+lg.error_msg) stock_code = 'sh.601398' rs = bs.query_history_k_data_plus(stock_code, "date,close", start_date='2016-01-04', end_date='2021-12-31', frequency="d", adjustflag="3") print('query_history_k_data_plus respond error_code:'+rs.error_code) print('query_history_k_data_plus respond error_msg:'+rs.error_msg) #### 打印结果集 #### data_list = [] while (rs.error_code == '0') & rs.next(): # 获取一条记录,将记录合并在一起 data_list.append(rs.get_row_data()) gsyh = pd.DataFrame(data_list, columns=rs.fields) gsyh['close'] = gsyh['close'].astype('float') gsyh['date'] = pd.to_datetime(gsyh['date'], format='%Y-%m-%d') gsyh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
# 查看工商银行的价格走势图 plt.figure(figsize=(8,6)) plt.plot(gsyh['date'], gsyh['close'], lw=2, alpha=0.8) plt.xlabel("date") plt.ylabel("Price") plt.title("工商银行价格走势图") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
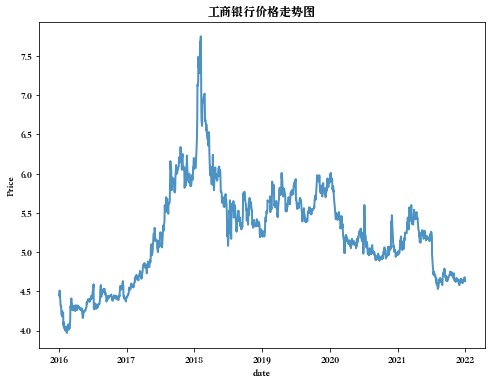
我们发现曲线有如下特点:
- (1)股票价格走势具有强烈的随机性;
- (2)股票价格的曲线是一条"不平滑"的曲线,与我们前面学习的可微分的曲线不太一样。
可以尝试使用物理中的布朗运动去近似股票价格的无规律波动,数学上对布朗运动的描述发展相比于物理上的布朗运动要慢一些
1.3 如何模拟股票价格:布朗运动
设有一个粒子在直线上随机游动, 该粒子在每个单位时间内等可能地向左或向右移动一个单位长度,观察这个例子的轨迹图
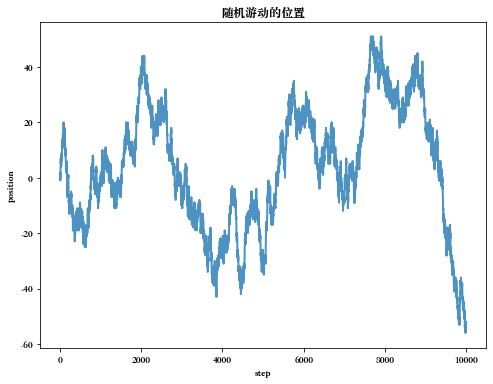
# 获取随机游动的位置 def get_particle_pos(n_times): position_ls = [0] for i in range(n_times-1): left_or_right = np.random.rand() if left_or_right >= 0.5: position_ls.append(1.0) else: position_ls.append(-1.0) position_ls = np.cumsum(position_ls) return position_ls n_times = 10000 position_arr = get_particle_pos(n_times = n_times) plt.figure(figsize=(8, 6)) plt.plot(np.arange(n_times), position_arr, lw=2, alpha=0.8) plt.xlabel("step") plt.ylabel("position") plt.title("随机游动的位置") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
我们将粒子的随机游动与股价走势放在一起对比一下:
plt.figure(figsize=(16, 6)) plt.subplot(1,2,1) plt.plot(np.arange(n_times), position_arr, lw=2, alpha=0.8) plt.xlabel("step") plt.ylabel("position") plt.title("随机游动的位置") plt.subplot(1,2,2) plt.plot(gsyh['date'], gsyh['close'], lw=2, alpha=0.8) plt.xlabel("date") plt.ylabel("Price") plt.title("工商银行价格走势图") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
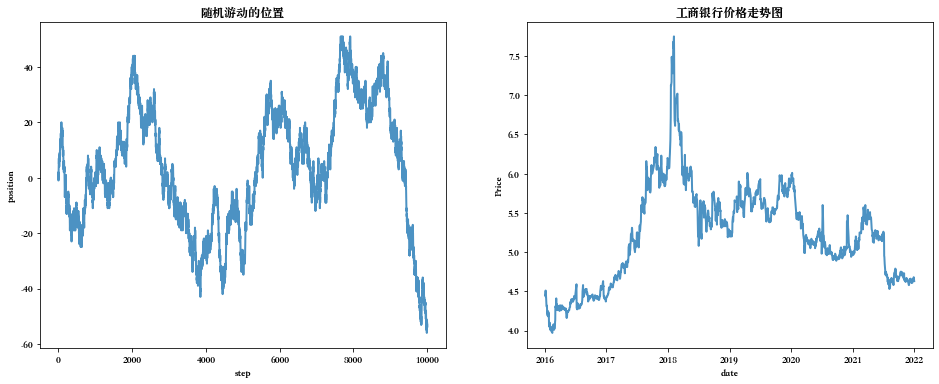
通过对比一维布朗运动走势和股票价格的走势可以发现,这两者在形状上非常相似布朗运动详细定义
随机过程 { X ( t ) , t ⩾ 0 } \{X(t), t \geqslant 0\} {X(t),t⩾0} 如果满足:
(1) X ( 0 ) = 0 X(0)=0 X(0)=0;
(2) { X ( t ) , t ⩾ 0 } \{X(t), t \geqslant 0\} {X(t),t⩾0} 有平稳独立增量;
(3) 对每个 t > 0 , X ( t ) t>0, X(t) t>0,X(t) 服从正态分布 N ( 0 , σ 2 t ) N\left(0, \sigma^{2} t\right) N(0,σ2t),
则称 { X ( t ) , t ⩾ 0 } \{X(t), t \geqslant 0\} {X(t),t⩾0} 为 Brown 运动, 也称为 Wiener 过程, 常记为 { B ( t ) , t ⩾ 0 } \{B(t), t \geqslant 0\} {B(t),t⩾0} 或 { W ( t ) , t ⩾ 0 } \{W(t), t \geqslant 0\} {W(t),t⩾0} 。
如果 σ = 1 \sigma=1 σ=1, 我们称为标准 Brown 运动; 如果 σ ≠ 1 \sigma \neq 1 σ=1, 则可考虑 { X ( t ) / σ , t ⩾ 0 } \{X(t) / \sigma, t \geqslant 0\} {X(t)/σ,t⩾0}, 它是标准 Brown 运动。我们可以验证一维布朗运动(随机游走)的定义(3),即:均值函数和方差函数分别为:0与 σ 2 t \sigma^2 t σ2t以及每个时刻的位置分布为正态分布。
plt.figure(figsize=(16, 6)) plt.subplot(1,2,1) ## 模拟10000次随机漫步 simulate_time = 10000 n_times = 100 result_ls = [] for i in range(simulate_time): position_arr = get_particle_pos(n_times=n_times) plt.plot(np.arange(n_times), position_arr, lw=2, alpha=0.8) result_ls.append(position_arr.tolist()) pos_mean = np.mean(result_ls, axis=0) pos_var = np.var(result_ls, axis=0) plt.plot(np.arange(n_times), pos_mean, lw=4, alpha=0.8, c='red', label='mean_func') plt.plot(np.arange(n_times), pos_var, lw=4, alpha=0.8, c='blue', label='var_func') plt.xlabel("step") plt.ylabel("position") plt.title("随机游动的位置") plt.legend() plt.subplot(1,2,2) ## 选取index=60的位置分布 pos_60 = np.array(result_ls)[:, 60] plt.hist(pos_60, bins=100, density=1) plt.title("index=60的位置分布") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
随机游动的均值函数为0, 方差函数是一个关于时间 t t t的直线函数,index为60的位置分布也符合正态分布,以上都是布朗运动的表现。
plt.figure(figsize=(12, 8)) simulate_times = 12 n_times = 10000 for i in range(simulate_times): position_arr = get_particle_pos(n_times=n_times) plt.plot(np.arange(n_times), position_arr, lw=2, alpha=0.75) plt.axhline(y=0, lw=6) plt.plot(np.arange(n_times), np.sqrt(np.arange(n_times)), lw=6, c='red', alpha=0.8, label=r'$t=pos^2$') plt.plot(np.arange(n_times), -np.sqrt(np.arange(n_times)), lw=6, c='red', alpha=0.8) plt.legend() plt.xlabel("t") plt.ylabel("position") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
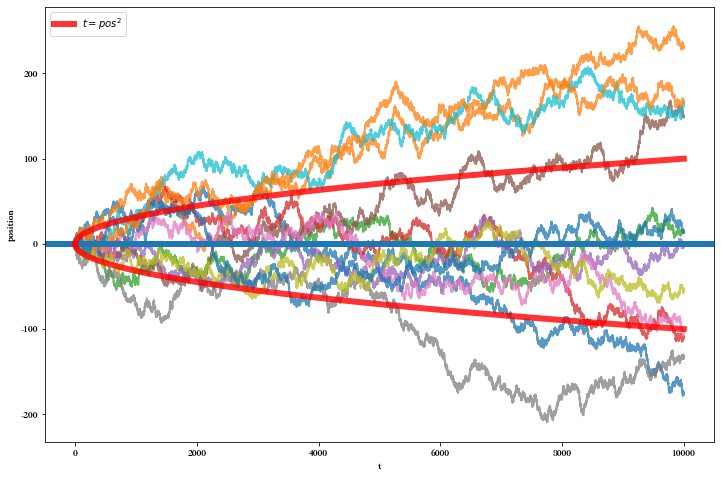
- (1)布朗运动的轨迹线会频繁穿越
p
o
s
=
0
pos = 0
pos=0的水平线
我们把0基准线看成是股票的开盘价,频繁穿越0基准线意味着股价很大概率会在开盘价上下波动,而不是始终维持在开盘价的上方或者下方。这一点的性质在很多股票投资的实践经验都有印证 - (2)在任意时刻
t
t
t, 样本轨迹的位置
B
(
t
)
B(t)
B(t) 不会偏离正负一个标准差太远:我们在布朗运动的定义中的(3)可以知道,对每个
t
>
0
,
X
(
t
)
t>0, X(t)
t>0,X(t) 服从正态分布
N
(
0
,
σ
2
t
)
N\left(0, \sigma^{2} t\right)
N(0,σ2t),一个标准差即
σ
t
\sigma \sqrt{t}
σt,上图中的红色曲线可以包含绝大多数的样本轨迹。这点可以说明,随着交易时间
t
t
t的推移,
t
t
t时刻的股票价格始终不会偏离开盘价(0基准线)
±
t
×
\pm \sqrt{t} \times
±t× 价格波动的标准差,就算偏离也不会太远(除了小概率事件)。
缺点
布朗运动可以是负数,因为布朗运动的样本轨迹会频繁穿越0基准线。然而,股票价格却肯定不会是负数,这是布朗运动的理论与现实的矛盾。为了解决这个问题,我们可以改进布朗运动描述股票价格走势,使用几何布朗运动描述股票价格。
1.4 如何更真实地模拟股票价格:几何布朗运动
为了解决使用布朗运动描述股票价格走势会出现负数的问题,我们尝试给布朗运动加上一个仅和时间 t t t 有关的漂移项 μ t \mu t μt, 以及一个尺度参数 σ \sigma σ,这样就可以得到带漂移项的布朗运动:
因为 X ( t ) X(t) X(t) 与 B ( t ) B(t) B(t) 的取值随着时间 t t t 的变化也可以是负数, 但是股票的价格显然不能是负数,这种办法并没有解决实际问题。
我们假设使用 S ( t ) S(t) S(t)表示股票价格而 X ( t ) X(t) X(t)是股票价格的自然对数,即: X ( t ) = l n ( S ( t ) ) X(t) = ln(S(t)) X(t)=ln(S(t))。因此,带漂移项的布朗运动就变成了:
X ( t ) = l n ( S ( t ) ) = μ t + σ B ( t ) X(t) = ln(S(t)) = \mu t+\sigma B(t) X(t)=ln(S(t))=μt+σB(t)我们对 X ( t ) = l n ( S ( t ) ) = μ t + σ B ( t ) X(t) = ln(S(t)) = \mu t+\sigma B(t) X(t)=ln(S(t))=μt+σB(t)进行微分(简单的对数函数求导),即:
d S ( t ) S ( t ) = μ d t + σ d B ( t ) \frac{d S(t)}{S(t)}=\mu d t+\sigma d B(t) S(t)dS(t)=μdt+σdB(t)
d S ( t ) / S ( t ) d S(t) / S(t) dS(t)/S(t) 就 是这段间隔内的收益率
化简上述的式子 d S ( t ) S ( t ) = μ d t + σ d B ( t ) \frac{d S(t)}{S(t)}=\mu d t+\sigma d B(t) S(t)dS(t)=μdt+σdB(t)得到:
d S ( t ) = μ S ( t ) d t + σ S ( t ) d B ( t ) d S(t)=\mu S(t) d t+\sigma S(t) d B(t) dS(t)=μS(t)dt+σS(t)dB(t)式子: d S ( t ) = μ S ( t ) d t + σ S ( t ) d B ( t ) d S(t)=\mu S(t) d t+\sigma S(t) d B(t) dS(t)=μS(t)dt+σS(t)dB(t)是一个微分方程,这个微分方程是带有随机性的微分方程,简称"随机微分方程"。因此,满足上述随机微分方程 d S ( t ) = μ S ( t ) d t + σ S ( t ) d B ( t ) d S(t)=\mu S(t) d t+\sigma S(t) d B(t) dS(t)=μS(t)dt+σS(t)dB(t)的股价 S ( t ) S(t) S(t) 是一个几何布朗运动。
我们可以使用欧拉离散化可以得到离散时间模型:
S t = S t − Δ t e ( μ − 1 2 σ 2 ) Δ t + σ ε t Δ t S_{t}=S_{t-\Delta t} e^{\left(\mu-\frac{1}{2} \sigma^{2}\right) \Delta t+\sigma \varepsilon_{t} \sqrt{\Delta t}} St=St−Δte(μ−21σ2)Δt+σεtΔt
离散时间模型的参数含义:- S t S_{t} St : 证券在t时刻的价格;
- S t − Δ t \mathrm{S}_{\mathrm{t}-\Delta \mathrm{t}} St−Δt : 证券在t − Δ t -\Delta \mathrm{t} −Δt 时刻的价格;
- μ \mu μ :证券收益率的期望值;
- σ \sigma σ :证券收益率的波动率;
- ε t \varepsilon_{t} εt : 服从正态分布(期望为 0 , 方差为 1 )
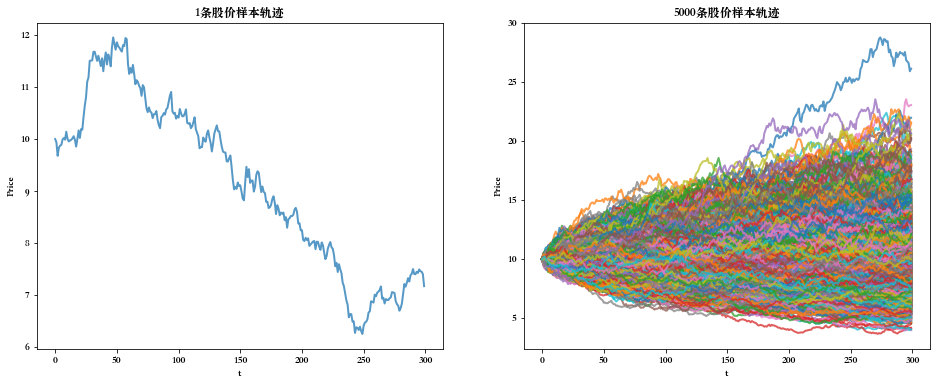
接下来,我们模拟证券初始价格为10(日收益率均值漂移项为0.005,波动率为0.25),模拟天数为300天,次数为5000次的几何布朗运动价格。
# 我们模拟证券初始价格为10(日收益率均值漂移项为0.005,波动率为0.25),模拟天数为300天,次数为5000次的几何布朗运动价格 S0 = 10 # 初始价格 n_days = 300 # 模拟天数 mu = 0.005 sigma = 0.25 delta_t = 1/n_days n_times = 5000 # 模拟次数 price_arr = np.zeros((n_times, n_days)) # n_times*n_days个价格 price_arr[: , 0] = S0 # 初始价格 for t in range(1, n_days): price_arr[:, t] = price_arr[:, t-1]*np.exp((mu-0.5*np.square(sigma))*delta_t+sigma*np.random.standard_normal(n_times)*np.sqrt(delta_t)) # 分别绘制一条轨迹和所有轨迹 plt.figure(figsize=(16, 6)) plt.subplot(1,2,1) plt.plot(np.arange(n_days), price_arr[0, :], lw=2, alpha=0.75) plt.xlabel("t") plt.ylabel("Price") plt.title("1条股价样本轨迹") plt.subplot(1,2,2) for i in range(n_times): plt.plot(np.arange(n_days), price_arr[i, :], lw=2, alpha=0.75) plt.xlabel("t") plt.ylabel("Price") plt.title("5000条股价样本轨迹") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
# 绘制某一天的价格分布 plt.figure(figsize=(8, 6)) plt.hist(price_arr[60, :], bins=50, density=True) plt.xlabel("price") plt.title("index=60的价格分布") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
以上的案例给定了离散时间模型的参数值,这是一种只会存在于习题中的情况,因为当我们想模拟一只具体的股票时,这些参数信息不会一下子弹到我们脑边,我们需要根据实际数据估计其中的参数值。估计方法如下(不给证明了):
μ = E [ ln ( S t + Δ t S t ) ] / Δ t σ 2 = var [ ln ( S t + Δ t S t ) ] / Δ t μ=E[ln(St+ΔtSt)]/Δtσ2=var[ln(St+ΔtSt)]/Δt μσ2=E[ln(StSt+Δt)]/Δt=var[ln(StSt+Δt)]/Δt# 使用工商银行股票价格数据和几何布朗运动模拟股价 ## 1. 获取2021年的工商银行股票价格数据 # 登陆系统 lg = bs.login() # 显示登陆返回信息 print('login respond error_code:'+lg.error_code) print('login respond error_msg:'+lg.error_msg) stock_code = 'sh.601398' rs = bs.query_history_k_data_plus(stock_code, "date,close", start_date='2021-01-01', end_date='2021-12-31', frequency="d", adjustflag="3") print('query_history_k_data_plus respond error_code:'+rs.error_code) print('query_history_k_data_plus respond error_msg:'+rs.error_msg) #### 打印结果集 #### data_list = [] while (rs.error_code == '0') & rs.next(): # 获取一条记录,将记录合并在一起 data_list.append(rs.get_row_data()) gsyh_2021 = pd.DataFrame(data_list, columns=rs.fields) gsyh_2021['close'] = gsyh_2021['close'].astype('float') gsyh_2021['date'] = pd.to_datetime(gsyh_2021['date'], format='%Y-%m-%d') ## 2.估计几何布朗运动中的mu和sigma price_ls = gsyh_2021['close'].tolist() delta_t = 1/len(price_ls) mu = np.mean(np.log(price_ls[1:]) - np.log(price_ls[:-1])) / delta_t sigma2 = np.var(np.log(price_ls[1:]) - np.log(price_ls[:-1])) / delta_t ## 3.使用几何布朗运动模拟股价走势 print("==============开始模拟================") S0 = price_ls[-1] # 初始价格 print("初始价格:", S0) n_days = 300 # 模拟天数 sigma = np.sqrt(sigma2) print("估计的mu = ", mu) print("估计的sigma = ", sigma) delta_t = 1/n_days n_times = 10000 # 模拟次数 price_arr = np.zeros((n_times, n_days)) # n_times*n_days个价格 price_arr[: , 0] = S0 # 初始价格 for t in range(1, n_days): price_arr[:, t] = price_arr[:, t-1]*np.exp((mu-0.5*np.square(sigma))*delta_t+sigma*np.random.standard_normal(n_times)*np.sqrt(delta_t)) # 分别绘制一条轨迹和所有轨迹 plt.figure(figsize=(16, 6)) plt.subplot(1,2,1) plt.plot(np.arange(n_days), price_arr[0, :], lw=2, alpha=0.75) plt.xlabel("t") plt.ylabel("Price") plt.title("1条股价样本轨迹") plt.subplot(1,2,2) for i in range(n_times): plt.plot(np.arange(n_days), price_arr[i, :], lw=2, alpha=0.75) plt.xlabel("t") plt.ylabel("Price") plt.title("10000条股价样本轨迹") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
可以从上述模拟中得到第300天的模拟价格分布,即:
import seaborn as sns palette = plt.get_cmap('tab20c') price_300 = price_arr[299, :] plt.figure(figsize=(8,6)) sns.histplot(price_300, kde = True, stat='probability', bins = 20, shrink = 1, color = palette.colors[0], edgecolor = palette.colors[-1]) plt.xlabel("Price") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
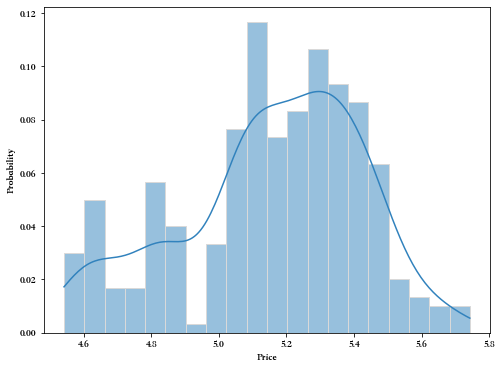
小节:我们通过带漂移项的布朗运动 X ( t ) = μ t + σ B ( t ) X(t)=\mu t+\sigma B(t) X(t)=μt+σB(t)可以知道, X ( t ) X(t) X(t) 的期望为 E [ X ( t ) ] = μ t E[X(t)]=\mu t E[X(t)]=μt,即t时刻的价格期望为 μ t \mu t μt。这是个十分有趣的结论,因为假如 μ > 0 \mu > 0 μ>0,那么t时刻的价格期望也会大于0。因此如果我们坚信股市长期来看是一个向上的牛市(虽然很缓慢),那么我们就应该接受短期波动而坚持长期持股,就像巴菲特的价值投资一样。
1.5 估计看涨期权的报酬分布
现在我们假设行权价格是4.7元,我们来分析报酬在第300天的时候的报酬分布情况(忽略权利金、远期利率和股息):
当股票价格大于行权价格,那么我将获利;
当股票价格小于行权价格,那么我将亏损;# 绘制报酬分布图 price_300 = price_arr[299, :].tolist() contract_sum = 4.7 profit_sum = [price - contract_sum if price > contract_sum else 0 for price in price_300] #剔除负数 plt.figure(figsize=(8,6)) plt.hist(profit_sum, bins=40, density=True) plt.xlabel("Profit") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.6 随机模拟的几个关键点
我们可以将随机模拟分解为以下步骤:
- (1)确定事件的过程(仿真);
- (2)在事件中添加合适的分布的随机数(随机模拟);(关键)
- (3)得到模拟的结论;
采样算法:(拒绝采样、MCMC采样)
(因为要从某个分布中采样,采样的样本就是所谓的随机数)
2.随机模拟的关键:随机数生成
- 计算机生成随机数的基础算法:均匀分布采样
- 分布函数采样
- 拒绝采样
- MCMC采样
2.1 随机数生成的基础:均匀分布的随机数
伪随机数生成的方法有很多, 比较简单的一种方式比如:
x n + 1 = ( a x n + c ) m o d m \mathrm{x}_{\mathrm{n}+1}=(\mathrm{ax_n} +\mathrm{c}) \bmod \mathrm{m} xn+1=(axn+c)modm其中, X X X 为伪随机序列,
- m , m > 0 m, m>0 m,m>0, 模数, 也是生成序列的最大周期
-
a
,
0
<
a
<
m
a, 0
-
c
,
0
≤
c
<
m
c, 0 \leq c
c,0≤c<m , 增量 -
X
0
,
0
≤
X
0
<
m
X_{0}, 0 \leq X_{0}
X0,0≤X0<m , 种子点 (起始值)
X n / n \mathrm{X}_{\mathrm{n}} / n Xn/n 近似服从 ( 0 , 1 ) (0,1) (0,1) 上的均匀分布。
这种方法叫线性同余法,使用线性同余法时需要特别小心参数设置,否则生成的随机数将会十分糟糕。下面通过一组实验看看不同的参数设置下生成的随机数序列:
# 线性同余法 def get_uniform_sample(a, c, m, x0, n_times): uniform_ls = [] for i in range(n_times): uniform_sample = (a*x0+c) % m uniform_ls.append(uniform_sample) x0 = uniform_sample return uniform_ls n_times = 10 # 实验次数 ## 第一组实验: a, c, m, x0 = 11, 0, 8, 1 uniform_ls = get_uniform_sample(a, c, m, x0, n_times) print("第一次实验:") print("a = %d, c = %d, m = %d, x0 = %d:\n" % (a, c, m, x0)) print(uniform_ls) print("============================") ## 第二组实验: a, c, m, x0 = 25214903917, 11, 2**48, 1 # 这也是java.util.Random中的默认参数设置 uniform_ls = get_uniform_sample(a, c, m, x0, n_times) print("第二次实验:") print("a = %d, c = %d, m = %d, x0 = %d:\n" % (a, c, m, x0)) print(uniform_ls)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
构造满足某个离散分布的随机数
上面的线性同余法是构造均匀分布的随机数,如果我们需要构造满足某个离散分布的随机数,如: x = 1 , 2 , 3 , 4 x = 1, 2, 3, 4 x=1,2,3,4分别满足概率 [ 0.1 , 0.3 , 0.5 , 0.1 ] [0.1, 0.3, 0.5, 0.1] [0.1,0.3,0.5,0.1]这个离散分布的随机数。其实这个问题的解决方法并不难,需要用到均匀分布的随机数:
- 生成一个 [ 0 , 1 ] [0,1] [0,1]的均匀分布的随机数 x x x;
- 如果 x x x在 [ 0 , 0.1 ) [0, 0.1) [0,0.1),那么 x = 1 x = 1 x=1, 如果 x x x在 [ 0.1 , 0.4 ) [0.1, 0.4) [0.1,0.4),那么 x = 2 x = 2 x=2,如果 x x x在 [ 0.4 , 0.9 ) [0.4, 0.9) [0.4,0.9),那么 x = 3 x = 3 x=3,如果 x x x在 [ 0.9 , 1 ) [0.9, 1) [0.9,1),那么 x = 4 x = 4 x=4。
- 重复以上步骤n_times次就能获得n_times个符合离散分布的随机数
# 生成10000个离散分布的随机数 from collections import Counter def get_discrete_sample(x_ls, p_ls, size): """ :param x_ls: 类别序列 :param p_ls: 类别的概率序列 :param size: 生成随机数个数 :return: 随机数序列 """ p_ls = np.cumsum(p_ls) # [0.1, 0.4, 0.9, 1] x_sample_ls = [] for i in range(size): p_uniform = np.random.uniform(0, 1) tmp_ls = [1 if p_uniform < p else 0 for p in p_ls] index = len(tmp_ls) - np.sum(tmp_ls) x_sample_ls.append(x_ls[index]) return x_sample_ls size = 10000 x_ls = [1, 2, 3, 4] p_ls = [0.1, 0.3, 0.5, 0.1] x_sample_ls = get_discrete_sample(x_ls, p_ls, size) x_count = Counter(x_sample_ls) x_count = list(x_count.items()) x_ratio = [(x[0], x[1] / len(x_sample_ls)) for x in x_count] print(x_ratio)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.2 分布函数生成随机数(逆变换)
通过使用均匀分布的随机数构造别的分布的随机数呢?答案是肯定的,这个方法叫逆变换法。
逆变换法的理论依据是:假设 X \mathrm{X} X 是一个连续型随机变量,它的累积分布函数为 F X ( x ) F_{X}(x) FX(x) ; 现在,定义随机变量 Y = F X ( X ) Y=F_{X}(X) Y=FX(X) 。那么, Y Y Y 服从 ( 0 , 1 ) (0,1) (0,1) 上的均匀分布,即
P ( Y ≤ y ) = y , 0 < y < 1 . P(Y \leq y)=y, 0换句话说,任意分布的分布函数值服从 ( 0 , 1 ) (0,1) (0,1)上的均匀分布
接下来,我们尝试使用逆变换法通过均匀分布的随机数构造指数分布的随机数:-
指数分布的概率密度函数为 f X ( x ) = f_{X}(x)= fX(x)= λ e − λ x , x > 0 \lambda e^{-\lambda x}, x>0 λe−λx,x>0 ,它的累积分布函数为
F X ( x ) = 1 − e − λ x , x ≥ 0 \mathrm{F}_{X}(x)=1-e^{-\lambda x}, \quad \mathrm{x} \geq 0 FX(x)=1−e−λx,x≥0 -
产生 ( 0 , 1 ) (0,1) (0,1) 均匀分布的随机数 V V V(当作是指数分布的分布函数值)
-
令 Y = − 1 λ log ( V ) Y=-\frac{1}{\lambda} \log (V) Y=−λ1log(V)(将满足均匀分布的分布函数进行逆变换), Y Y Y 即为服从指数分布的随机数
逆变换法构造指数分布的随机数 def get_exp_sample(lmd, size): uniform_samples = np.random.uniform(0, 1, size) exp_samples = [] for uniform_sample in uniform_samples: exp_sample = -1.0/lmd*np.log(uniform_sample) exp_samples.append(exp_sample) return exp_samples lmd = 1 size = 10000 exp_samples = get_exp_sample(lmd, size) plt.figure(figsize=(8, 6)) plt.hist(exp_samples, bins=50, density=True, alpha=0.75) plt.xlabel("X") plt.title("X~exp(1)") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2.3 拒绝采样生成随机数
逆变换法需要求分布函数和逆变换
拒绝采样开始采用蒙特卡洛的思想构造随机数,我们先来看看下图:- p ( x ) p(x) p(x)是我们需要采样的分布,有时候十分复杂,这里的 p ( x ) = 0.3 e − ( x − 0.3 ) 2 + 0.7 e − ( x − 2.0 ) 2 0.3 p(x) = 0.3 e^{-(x - 0.3)^2} + 0.7e^{-\frac{(x - 2.0)^2}{0.3}} p(x)=0.3e−(x−0.3)2+0.7e−0.3(x−2.0)2,其中 0 ≤ x ≤ 4 0 \le x \le 4 0≤x≤4
- q ( x ) q(x) q(x)是我们的构造的分布,这里我们假设为[0, 4]的均匀分布
# 拒绝采样演示: M = 4 z0 = 2.5 x = np.linspace(0,4,1000) q_x = np.array([1.0/4]*1000) p_x = 0.3*np.exp(-(x-0.3)**2)+0.7*np.exp(-(x-2.0)**2/0.3) plt.figure(figsize=(8,6)) plt.plot(x, p_x, lw=4, alpha=0.8, label=r'$p(x) = 0.3 e^{-(x - 0.3)^2} + 0.7e^{-\frac{(x - 2.0)^2}{0.3}}$') plt.plot(x, M*q_x, lw=4, alpha=0.8, label=r'$Mq(x)$') plt.vlines(x=0, ymin=0, ymax=1, colors='gray',linestyles='--') plt.vlines(x=4, ymin=0, ymax=1, colors='gray',linestyles='--') plt.vlines(x=z0, ymin=0, ymax=1, colors='red',linestyles='--', lw=2) plt.scatter(z0, 0.3*np.exp(-(z0-0.3)**2)+0.7*np.exp(-(z0-2.0)**2/0.3), s=90, color='red') plt.text(z0+0.1, 0.3*np.exp(-(z0-0.3)**2)+0.7*np.exp(-(z0-2.0)**2/0.3), r'$u_0$') plt.legend() plt.xlabel("x") plt.ylabel("f(x)") plt.title("拒绝采样演示图") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
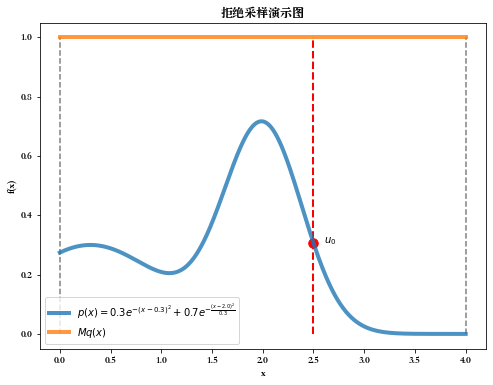
由于 p ( x ) p(x) p(x)太复杂,我们无法直接采样,因此我们借助辅助的分布 q ( x ) q(x) q(x),这个辅助的分布满足一个特点: q ( x ) q(x) q(x)乘一个常数 M M M后的 M q ( x ) Mq(x) Mq(x)曲线能完全包住我们想要采样的分布 p ( x ) p(x) p(x)。
拒绝采样的过程如下:
- 通过辅助分布 q ( x ) q(x) q(x)采样 z 0 z_0 z0,辅助分布可以选择常见的均匀分布或者正态分布;
- 计算 u 0 = p ( z 0 ) u_0 = p(z_0) u0=p(z0)(图中红色的点);
- 在区间 ( 0 , M q ( z 0 ) ] (0, Mq(z_0)] (0,Mq(z0)]范围的均匀分布随机采样 k k k,即在红色的直线范围按均匀分布采样 k k k;
- 判断
k
k
k的大小,
如果 k < u 0 kk<u0 (即 k k k位于 u 0 u_0 u0下方),则接受 z 0 z_0 z0是来自分布 p ( x ) p(x) p(x)的随机数;
反之,如果 k ≥ u 0 k \ge u_0 k≥u0(即 k k k位于 u 0 u_0 u0上方),则拒绝 z 0 z_0 z0是来自分布 p ( x ) p(x) p(x)的随机数。 - 重复以上过程,知道采样个数为size为止。
# 通过拒绝采样0.3*np.exp(-(x-0.3)**2)+0.7*np.exp(-(x-2.0)**2/0.3)分布的随机数 from scipy.stats import uniform def get_px(x): return 0.3*np.exp(-(x-0.3)**2)+0.7*np.exp(-(x-2.0)**2/0.3) def get_px_samples(size): M = 4 px_sample_ls = [] while len(px_sample_ls) <= size: z0 = np.random.uniform(0, 4) u0 = get_px(z0) k = np.random.uniform(0, M*uniform(0, 4).pdf(z0)) if k < u0: px_sample_ls.append(z0) return px_sample_ls size = 10000 px_samples = get_px_samples(size) plt.figure(figsize=(8, 6)) plt.hist(px_samples, bins=50, density=True, alpha=0.75) plt.xlim(0,4) plt.xlabel("X") plt.title("X~p(x)") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2.4 MCMC(蒙特卡洛马尔可夫)生成随机数
我们在马尔可夫链中又一个重要的结论:只要转移概率矩阵合适,不管初始分布如何都会收敛到同一个平稳分布。
如果我们能找到一个转移概率矩阵,这个矩阵得到的平稳分布刚好就是我们想要采样的分布,那么我们可以让平稳后的状态就是我们所需要的采样样本,因为这些状态都是由平稳分布得到的。
已知条件是平稳分布(我们需要采样的分布),想要求一个转移概率矩阵
随便找一个转移概率矩阵 Q Q Q, π ( i ) Q ( i , j ) ≠ π ( j ) Q ( j , i ) \pi(i) Q(i, j) \neq \pi(j) Q(j, i) π(i)Q(i,j)=π(j)Q(j,i)。如果想让平稳条件成立,可以引入 α ( i , j ) \alpha(i, j) α(i,j),则:
π ( i ) Q ( i , j ) α ( i , j ) = π ( j ) Q ( j , i ) α ( j , i ) \pi(i) Q(i, j) \alpha(i, j)=\pi(j) Q(j, i) \alpha(j, i) π(i)Q(i,j)α(i,j)=π(j)Q(j,i)α(j,i)
最简单的 α ( i , j ) \alpha(i, j) α(i,j)与 α ( j , i ) \alpha(j, i) α(j,i)是:
α ( i , j ) = π ( j ) Q ( j , i ) α ( j , i ) = π ( i ) Q ( i , j ) α(i,j)=π(j)Q(j,i)α(j,i)=π(i)Q(i,j) α(i,j)=π(j)Q(j,i)α(j,i)=π(i)Q(i,j)α ( i , j ) \alpha(i, j) α(i,j) 我们有一般称之为接受率, α ( i , j ) \alpha(i, j) α(i,j)取值在 [ 0 , 1 ] [0,1] [0,1] 之间, 可以理解为一个概率值(可以从均匀分布中采样)。
最后,我们总结下MCMC采样的过程:
- 输入任意的转移概率矩阵 Q ( i , j ) Q(i,j) Q(i,j),假设 n 1 n_1 n1次转移后能够到达平稳,需要采 n 2 n_2 n2个样本。因此采样算法从 n 1 n_1 n1次后才真正进行,目的是放弃平稳前的采样值,因为只有平稳后的分布才是我们的目标采样分布,如果采用了平稳前的样本,这些样本的分布将不是我们的目标分布。
- 随机产生一个初始值 x 0 x_0 x0
- for
t
=
0
t=0
t=0 to
n
1
+
n
2
−
1
n_{1}+n_{2}-1
n1+n2−1 :
- 从条件概率分布 Q ( x ∣ x t ) Q\left(x \mid x_{t}\right) Q(x∣xt) 中采样得到样本 x ∗ x_{*} x∗
- 从均匀分布采样 u ∼ u n i f o r m [ 0 , 1 ] u \sim uniform[0,1] u∼uniform[0,1]
- 如果 u < α ( x t , x ∗ ) = π ( x ∗ ) Q ( x ∗ , x t ) u<\alpha\left(x_{t}, x_{*}\right)=\pi\left(x_{*}\right) Q\left(x_{*}, x_{t}\right) u<α(xt,x∗)=π(x∗)Q(x∗,xt) ,则接受转移 x t → x ∗ x_{t} \rightarrow x_{*} xt→x∗ ,即 x t + 1 = x ∗ x_{t+1}=x_{*} xt+1=x∗
- 否则不接受转移,即 x t + 1 = x t x_{t+1}=x_{t} xt+1=xt - 样本集 ( x n 1 , x n 1 + 1 , … , x n 1 + n 2 − 1 ) \left(x_{n_{1}}, x_{n_{1}+1}, \ldots, x_{n_{1}+n_{2}-1}\right) (xn1,xn1+1,…,xn1+n2−1) (注意不能取前 n 1 n_1 n1个样本)即为我们需要的平稳分布对应的随机样本。
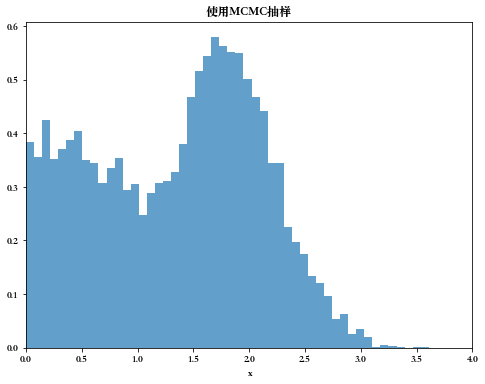
exp
现在,我们使用MCMC采样来对 p ( x ) = 0.3 e − ( x − 0.3 ) 2 + 0.7 e − ( x − 2.0 ) 2 0.3 p(x) = 0.3 e^{-(x - 0.3)^2} + 0.7e^{-\frac{(x - 2.0)^2}{0.3}} p(x)=0.3e−(x−0.3)2+0.7e−0.3(x−2.0)2,其中 0 ≤ x ≤ 4 0 \le x \le 4 0≤x≤4进行随机采样:- 假设 Q ( i , j ) Q(i,j) Q(i,j)为$\mu , , ,\sigma$的正态分布
- 初始样本 x 0 = 0 x_0 = 0 x0=0
# 使用MCMC采样来对正态分布进行随机采样 # 定义任意分布Q的密度函数 def Gussian_q(x,mu,sigma): return 1/(np.sqrt(2*np.pi)*sigma)*np.exp(-np.square((x-mu))/(2*np.square(sigma))) # 从任意分布Q中获取一个样本 def get_q_sample(mu, sigma): return np.random.normal(mu, sigma) # 定义需要采样的分布的密度函数 def p(x): return 0.3*np.exp(-(x-0.3)**2) + 0.7* np.exp(-(x-2.0)**2/0.3) if (x>0) & (x<4) else 0 def get_mcmc_normal(size): mu = 0 sigma = 1 x_0 = 0 # 初始的随机状态x0 n1 = 5000 n2 = size p_sample_ls = [] t = 0 while len(p_sample_ls) < n2: t += 1 x_1 = get_q_sample(mu, sigma) u = np.random.uniform(0, 1) if u < p(x_1)*Gussian_q(x_0, mu, sigma)/Gussian_q(x_1, mu, sigma): x_0 = x_1 if t >= n1: p_sample_ls.append(x_0) return p_sample_ls p_sample_ls = get_mcmc_normal(size=10000) plt.figure(figsize=(8, 6)) plt.hist(p_sample_ls, bins=50, density=True, alpha=0.7) plt.xlim(0,4) plt.xlabel("x") plt.title("使用MCMC抽样") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
-
相关阅读:
linux修改locale字符集编码为UTF-8/GBK,修改语言区域为zh-CN(中文-中国)
使用 IPtables 进行 DDoS 保护
2024年最新版云开发cms开通步骤,开始开发微信小程序前的准备工作,认真看完奥!
不破楼兰终不还——Go 延迟语句defer指南
使用RobustPCA 进行时间序列的异常检测
超市微信小程序是怎么做的
idea 部署项目问题整理
使用 Fastai 构建食物图像分类器
Netty 学习(十):ChannelPipeline源码说明
DS@命题公式等值演算@常用等值式模式
- 原文地址:https://blog.csdn.net/m0_52024881/article/details/126574192
