-
什么是分子优化(Molecule Optimization)以及相关论文
药物与生物大分子的相互关系(分子与药物以及人体关系)_马鹏森的博客-CSDN博客
这里说的“分子优化”,其实就是“药物中的分子优化”的简称 ,药物中的分子与人体内的生物大分子(蛋白质、核酸、多糖和脂类)结合从而抗病。
此时我们“分子优化”的目的就是 通过化学修饰分子从而改善候选药物的所需特性,使药物特性最大化,同时保持与输入分子的相似性
什么是分子优化?(Molecule Optimization OA)
分子优化是药物发现的关键步骤,,可通过化学修饰分子从而改善候选药物的所需特性,目标是发现与已知起始分子相比具有改善的药物特性的分子(产生新的有效分子,使药物特性最大化,同时保持与输入分子的相似性)。例如,在先导优化中,可以改变先导分子的化学结构以提高它们的选择性和特异性。传统上,这种分子优化过程是根据药物化学家的知识和经验规划的,并通过基于片段的筛选或合成来进行。因此,它不可扩展或自动化 。
药物中的小分子以及他的药理学是什么?
小分子(英语:small molecule)是一个有机化学概念。一般将分子量小于900道尔顿的有机化合物分子称为小分子。目前大部分药物都是小分子类药物,蛋白质、核酸等生物大分子的基本组成单位(如氨基酸、核糖核苷酸、脱氧核苷酸)也是小分子。小分子药物一般是抑制剂,通过干扰蛋白间相互作用起效。
药理学
目前大部分的药物都是小分子药物。小分子的分子量上限一般设在900道尔顿,这是因为900道尔顿以下的分子在人体内能较快速地扩散进入细胞,到达作用靶点。根据里宾斯基五规则,口服给药的小分子药物的分子量最好能低于500道尔顿,否则损耗率会出现明显上升。
1、A Deep Generative Model for Molecule Optimization via One Fragment Modification
通过一个片段修饰进行分子优化的深度生成模型
A Deep Generative Model for Molecule Optimization via One Fragment Modification | Papers With Code
这里面的数据集似乎不错?(有paired ...)
数据集的说明:
1. Use provided processed dataset
If you want to use our provided processed dataset, please check the directories below:
-
./data/logp06/: the dataset of pairs of molecules with 0.6 similarity and different on penalized logp property. ./data/drd2_25: the dataset of pairs of molecules with 0.6 similarity and different on DRD2 property. The property difference between each pair of molecules is greater than 0.25../data/qed_1: the dataset of pairs of molecules with 0.6 similarity and different on QED property. The property difference between each pair of molecules is greater than 0.1. The QED properties of these molecules are greater than 0.7../data/drd2_25_qed6: the dataset of pairs of molecules with 0.6 similarity and different on QED property and DRD2 property. The property differences on DRD2 between each pair of molecules are greater than 0.25 (i.e.,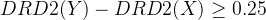 ). The QED property of each pair of molecules should satisfy QED(X)<0.6≤QED(Y).
). The QED property of each pair of molecules should satisfy QED(X)<0.6≤QED(Y).
In each directory, you will see the following files:
1、multiple zipped
tensors-*.pklfiles. These binary files contain the processed data including pairs of molecules and their edit paths. The data in these*.pklfiles should be used for model training. All thetensors-*.pklfiles will be read into Modof as training data. If you are using your own training data rather than the provided one, you can generate suchtensors-*.pklusing the data processing tools as will be described below.Note: Due to the limit of file size, we only provide part of the processed file here. To use the whole training dataset, please use the provided data preprocessing script to preprocess the dataset. Please decompress the zipped file before using them to train the model.
2、train_pairs.txtfile in logp06 dataset. This file contains all pairs of molecules used in Jin’s paper. This file is identical to train_pairs.txt file in (iclr19-graph2graph/data/logp06 at master · wengong-jin/iclr19-graph2graph · GitHub). Please note that the molecule pairs contained intensors-*.pklfiles are a subset of all the molecule pairs in train_pairs.txt.- File format: each line in
train_pairs.txthas two SMILE strings, separated by an empty space. The first SMILE string represents the molecule with worse properties, and the second SMILE string represent the molecule with better properties.
3、one_ds_pairs.txtfile. This file contains the pairs of molecules used in Modof.- File format: each line in
one_ds_pairs.txthas two SMILE strings, separated by an empty space.
4、test.txt. This file contains the SMILE strings of single molecules that are used as the testing molecules in XXX’s paper. These molecules are also the testing molecules used in our Modof.- File format: each line in
test.txtis a SMILE string of a testing molecule.
5、vocab.txt. This file contains all the substructures of training molecules intensors-*.pklfiles. These substructures are in SMILE strings.- File format: each line in vocab.txt is a SMILE string of a substructures. The i-th row represents the i-th substructure (i.e., ‘i’ here is the substructure ID).
2、Unpaired Generative Molecule-to-Molecule Translation for Lead Optimization
用于先导化合物优化的不成对生成分子到分子转换
3、Mol-CycleGAN: a generative model for molecular optimization
Mol-CycleGAN:用于分子优化的生成模型
Mol-CycleGAN - a generative model for molecular optimization | Papers With Code
4、Differentiable Scaffolding Tree for Molecule Optimization
Differentiable Scaffolding Tree for Molecule Optimization | Papers With Code
5、CORE: Automatic Molecule Optimization using Copy and Refine Strategy
CORE: Automatic Molecule Optimization Using Copy & Refine Strategy | Papers With Code
6、Molecular Optimization by Capturing Chemist's Intuition Using Deep Neural Networks
-
-
相关阅读:
简单对比一下 C 与 Go 两种语言
Sendable 和 @Sendable 闭包 —— 代码实例详解
Spring Boot + Vue的网上商城之商品管理
2023-11-9
【SQL注入】(1)原理,框架
如何将本地文件上传到Gitee
Redis_哨兵模式配置文件详解
【无标题】
B2B企业如何打造独立站:从策略到实施的全面指南
ECMAScript 6 解构
- 原文地址:https://blog.csdn.net/weixin_43135178/article/details/126566163