-
hadoop生态圈面试精华之MapReduce(一)
hadoop生态圈面试精华之MapReduce
介绍下MapReduce
问过的一些公司:字节x2,字节(2021.09),美团,美团(2021.08),网易有道(2021.10) 回答技巧:结合MapReduce的优缺点回答(下一题)
参考答案:
MapReduce 是一个分布式运算程序的编程框架,它的核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。MapReduce的核心思想是将用户编写的逻辑代码和架构中的各个组件整合成一个分布式运算程序,实现 一定程序的并行处理海量数据,提高效率。
海量数据难以在单机上处理,而一旦将单机版程序扩展到集群上进行分布式运行势必将大大增加程序的 复杂程度。引入MapReduce架构,开发人员可以将精力集中于数据处理的核心业务逻辑上,而将分布式 程序中的公共功能封装成框架,以降低开发的难度。
一个完整的mapreduce程序有三类实例进程
MRAppMaster:负责整个程序的协调过程MapTask:负责map阶段的数据处理
ReduceTask:负责reduce阶段的数据处理MapReduce优缺点
问过的一些公司:小米参考答案:
优点- MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使 得 MapReduce 编程变得非常流行。
41 良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
42 高容错性
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行, 不至于这个任务运行失败, 而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
43 适合 PB 级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点 - 不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
44 不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为
MapReduce 自身的设计特点决定了数据源必须是静态的。
45 不擅长 DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不 是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘, 会造成大量的磁盘 IO,导致性能非常的低下。
MapReduce架构
可回答:MapReduce的几部分
问过的一些公司:美团,唯品会(2021.10) 参考答案:
与HDFS一样,MapReduce也是采用Master/Slave的架构,其架构图如下所示。
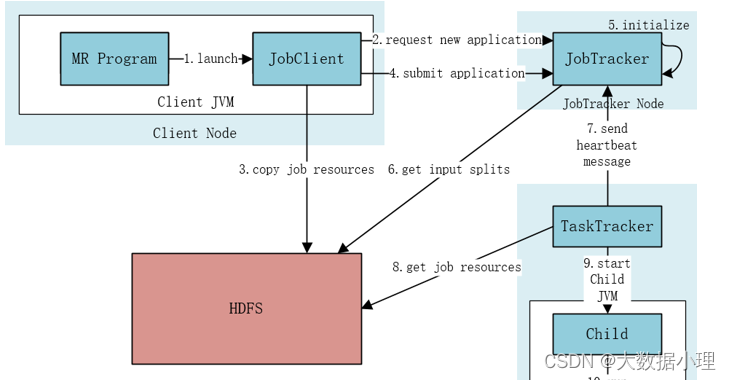
MapReduce包含四个组成部分,分别为Client、JobTracker、TaskTracker和Task,下面我们详细介绍这四个组成部分。
1)Client 客户端
每一个 Job 都会在用户端通过 Client 类将应用程序以及配置参数 Configuration 打包成 JAR 文件存储在HDFS,并把路径提交到 JobTracker 的 master 服务,然后由 master 创建每一个 Task(即 MapTask 和ReduceTask) 将它们分发到各个 TaskTracker 服务中去执行。
2)
JobTracker
JobTracke负责资源监控和作业调度。JobTracker 监控所有TaskTracker 与job的健康状况,一旦发现失败,就将相应的任务转移到其他节点;同时,JobTracker 会跟踪任务的执行进度、资源使用量等信息, 并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop 中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的调度器。
3)TaskTracker
TaskTracker 会周期性地通过Heartbeat 将本节点上资源的使用情况和任务的运行进度汇报给JobTracker, 同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker 使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop 调度器的作用就是将各个TaskTracker 上的空闲slot 分配给Task 使用。slot 分为Map slot 和Reduce slot 两种,分别供Map Task 和Reduce Task 使用。TaskTracker 通过slot 数目(可配置参数)限定Task 的并发度。
4)
Task
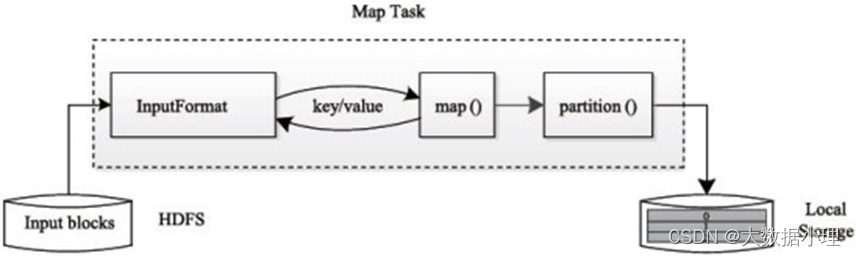
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。
Map Task 执行过程如下图所示:由该图可知,Map Task 先将对应的split 迭代解析成一个个key/value 对,依次调用用户 自定义的map() 函数进行处理,最终将临时结果存放到本地磁盘上, 其中临时数据被分成若干个partition,每个partition 将被一个Reduce Task 处理。
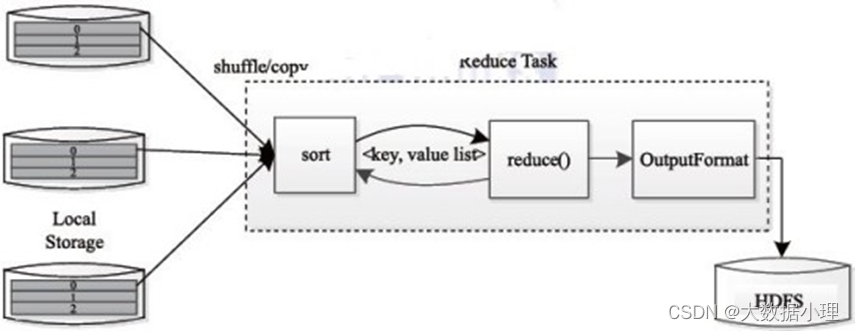
Reduce Task 执行过程下图所示。该过程分为三个阶段:
注意:
从远程节点上读取Map Task 中间结果(称为“Shuffle 阶段”); 按照key对key/value 对进行排序(称为“Sort 阶段”);
依次读取< key, value list>,调用用户自定义的reduce() 函数处理,并将最终结果存到HDFS 上(称为
“Reduce 阶段”)。MapReduce工作原理
可回答:1)MapReduce(执行)流程;2)对MapReduce的理解;3)MapReduce过程;4)MapReduce 的详细过程;5)MapReduce原理;6)MapReduce中有没有涉及到排序;7)MapReduce提交job到YARN 的流程;8)MapReduce原理,map和reduce过程;9)说一下MapReduce流程
问过的一些公司:阿里×4,字节×7,字节(2021.08)x3-(2021.10),头条,滴滴,百度,腾讯×4,Shopee, 小米,爱奇艺,祖龙娱乐,360×5,商汤科技,网易×5,51×2,星环科技,招银网络,作业帮,映客直 播,美团×16,美团(2021.09)x2,字节×2,有赞,58×3,华为x2,创略科技,米哈游,快手,快手(2021.09),京东×4,趋势科技,海康威视,顺丰,好未来x3,一点资讯,冠群驰骋,中信信用卡中心, 金山云,米哈游,途牛,大华(2021.07),京东(2021.07),Shopee(2021.08),多益(2021.09),荣耀(2021.09),百度(2021.08、2021.09),阿里蚂蚁(2021.08),携程(2021.09),虎牙(2021.08),重庆富民银行(2021.09),网易有道(2021.09),携程(2021.09),陌陌(2021.10),腾讯(2022.03)
参考答案:
版本一
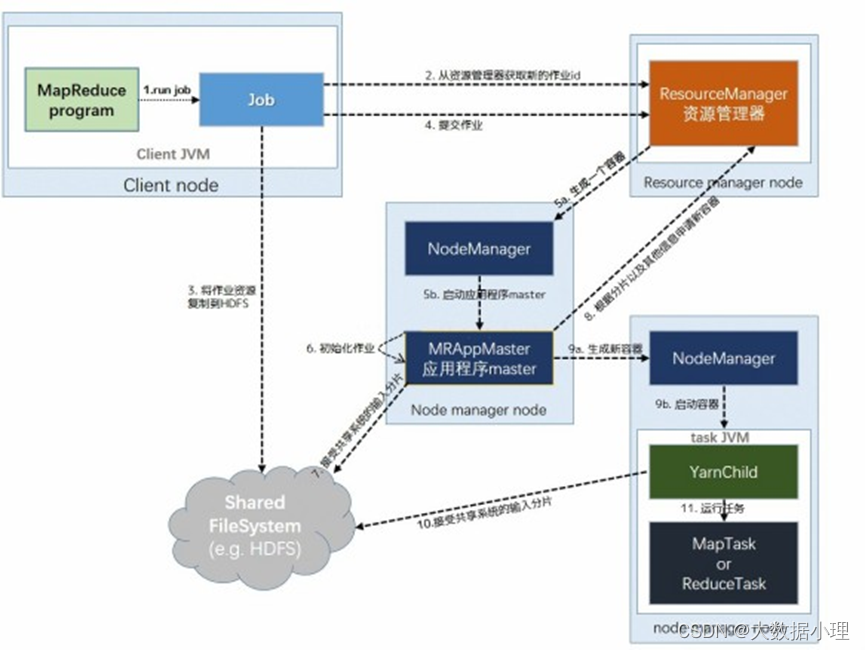
1、提交作业Client提交Job:
Client编写好Job后,调用Job实例的Sumit() 或者waitForCompletion() 方法提交作业;
从RM(而不是Jobtracker)获取新的作业ID,在YARN命名法中它是一个Application ID(步骤2)。
Job提交到RM:
Client检查作业的输出说明,计算输入分片,并将作业资源(包括作业JAR、配置和分片信息)复 制到HDFS(步骤3);
调用RM的submitApplication() 方法提交作业(步骤4)。
2、作业初始化
给作业分配ApplicationMaster:
RM收到调用它的submitApplication() 消息后,便将请求传递给scheduler (调度器);
scheduler分配一个Container,然后RM在该NM的管理下在Container中启动ApplicationMaster(步 骤5a & 5b)。
ApplicationMaster初始化作业:
MR作业的ApplicationMaster 是一个Java应用程序,它的主类是MRAppMaster。它对作业进行初始化:通过创建多个薄记对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告
(步骤6);
ApplicationMaster 从HDFS中获取在Client 计算的输入分片(map、reduce任务数)(步骤7)【对每一个分片创建一个map 任务对象以及由mapreduce.job.reduces 属性确定的多个reduce 任务对象】。
注意:
ApplicationMaster决定如何运行构成 MapReduce 作业的各个任务。如果作业很小,就选择在与它同一个
JVM上运行。
3、任务分配
ApplicationMaster 为该作业中的所有map 任务和reduce 任务向RM 请求Container (步骤8);
【随着心跳信息的请求包括每个map任务的数据本地化信息,特别是输入分片所在的主机和相应机 架信息。理想情况下,它将任务分配到数据本地化的节点,但如果不可能这么做,就会相对于本地 化的分配优先使用机架本地化的分配】
注意:
请求也为任务指定了内存需求。在默认情况下, map任务和reduce任务都分配到 1024MB 的内存,但这可以通过 mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb来设置。
4、任务执行
一旦RM 的scheduler 为任务分配了Container, ApplicationMaster就通过与NM通信来启动Container (步骤9a & 9b);
该任务由主类为YardChild 的Java应用程序执行。在它运行任务之前,首先将任务需要的资源本地化(包括作业的配置、JAR文件和所有来自分布式缓存的文件)(步骤10);
最后,运行map 任务或reduce 任务(步骤11)。
5、进度和状态的更新
在YARN下运行,任务每 3s通过umbilical 接口向ApplicationMaster 汇报进度和状态(包括计数器),作为作业的汇聚试图(aggregate view)。
6、作业完成
除了向ApplicationMaster 查询进度外,Client 每 5s还通过调用Job 的waitForCompletion() 来检查作业是否完成【查询的间隔可以通过mapreduce.client.completion.pollinterval 属性进行设置】。
作业完成后, ApplicationMaster 和任务容器清理其工作状态, OutputCommitter 的作业清理方法会被调用。作业历史服务器保存作业的信息供用户需要时查询。
版本二:Map、Reduce任务中ShuGle和排序的过程
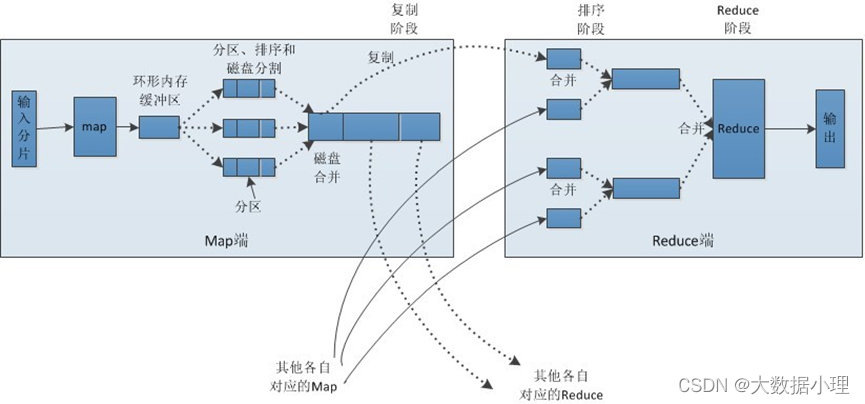
Map端
每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分 片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大 小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个 文件。
在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任 务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到 很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的 数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可 能少的数据写入到磁盘。
当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中 会不断地进行排序和combia操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复 制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这 里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是 哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置 就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看: 一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的 过程呢?呵呵。
Reduce端
Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的 数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制, 表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节 省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白 了有些人为什么会说:排序是hadoop的灵魂。
合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少, 并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。MapReduce哪个阶段最费时间
问过的一些公司:阿里参考答案:
Shuffle阶段MapReduce中的Combine是干嘛的?有什么好处?
问过的一些公司:字节参考答案:在MapReduce中,Combine 阶段是当Map阶段所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机 读取带来的开销。
Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出k-v应该跟reducer的输入 k-v类型要对应起来。MapReduce为什么一定要有环型缓冲区
问过的一些公司:字节参考答案:
在MapReduce的流程中,环形缓冲区是在溢写到磁盘之前的操作
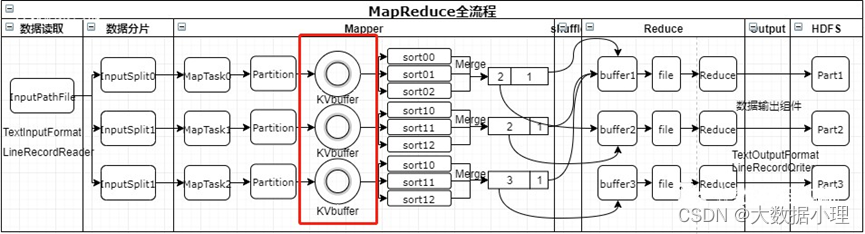
我们先来剖析下环形缓冲区
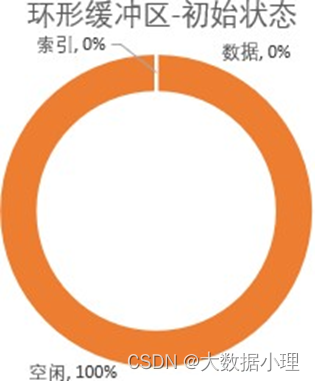
环形缓冲区分为三块,空闲区、数据区、索引区。初始位置取名叫做“赤道”,就是圆环上的白线那个位 置。初始状态的时候,数据和索引都为0,所有空间都是空闲状态。
tips: 这 里 有 一 个 调 优 参 数 , 可 以 设 置 环 形 缓 冲 区 的 大 小 : mapreduce.task.io.sort.mb,默认100M,可以稍微设置大一些,但不要太大,因为每个spilt就128M。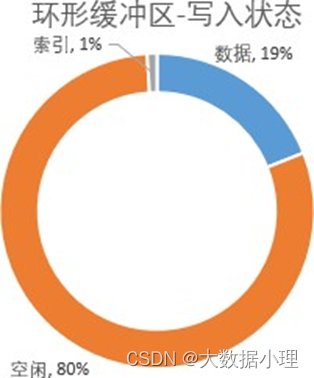
环形缓冲区写入的时候,有个细节:数据是从赤道的右边开始写入,索引(每次申请4kb)是从赤道是 左边开始写。这个设计很有意思,这样两个文件各是各的,互不干涉。
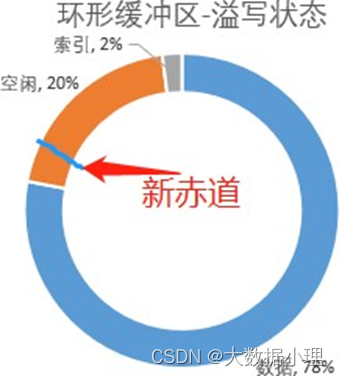
在数据和索引的大小到了mapreduce.map.sort.spill.percent参数设置的比例时(默认80%,这个是调优的 参数),会有两个动作:
1、对写入的数据进行原地排序,并把排序好的数据和索引spill到磁盘上去;
2、在空闲的20%区域中,重新算一个新的赤道,然后在新赤道的右边写入数据,左边写入索引;
3、当20%写满了,但是上一次80%的数据还没写到磁盘的时候,程序就会panding一下,等80%空间腾 出来之后再继续写。
如此循环往复,永不停歇,直到所有任务全部结束。整个操作都在内存,形状像一个环,所以才叫环形 缓冲区。
为什么要有环形缓冲区?
主要有以下几点
1、使用环形缓冲区,便于写入缓冲区和写出缓冲区同时进行。
2、为了防止阻塞,所以环型缓冲区不会等缓冲区满了再spill
3、每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构中,使用环形数据结构是为 了更有效地使用内存空间,在内存中放置尽可能多的数据。
4、环形缓冲区不需要重新申请新的内存,始终用的都是这个内存空间。大家知道MR是用java写的,而Java有一个最讨厌的机制就是Full GC。Full GC总是会出来捣乱,这个bug也非常隐蔽,发现了也不好处理。环形缓冲区从头到尾都在用那一个内存,不断重复利用,因此完美的规避了Full GC导致的各种问题,同时也规避了频繁申请内存引发的其他问题。5、环形缓冲区同时做了两件事情:1、排序;2、索引。在这里一次排序,将无序的数据变为有序,写 磁盘的时候顺序写,读数据的时候顺序读,效率高非常多!
在这里设置索引区也是为了能够持续的处理任务。每读取一段数据,就往索引文件里也写一段,这样在 排序的时候能加快速度。MapReduce为什么一定要有ShuGle过程
问过的一些公司:百度,头条,字节(2021.09) 参考答案:
MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负 责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过ShuGle 来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。ShuGle横跨Map端和Reduce端,在Map端 包括Spill过程,在Reduce端包括copy和sort过程。MapReduce的ShuGle过程及其优化
可回答:1)Hadoop的Shuffle过程;2)为什么Map端输出的时候需要排序?不排序直接输出难道不好 吗?3)介绍下MapReduce的Shuffle机制;3)你觉得MapReduce有哪些需要优化的地方;4)哪些操作引 起shuffle;5)说一下shuffle机制;6)说一下reduce的shuffle?7)shuffle流程的细节是什么
问过的一些公司:字节×4,字节(2021.07)(2021.08),头条,百度×2,第四范式,360,猿辅导,美团×3, 美团(2021.08)(2021.09),平安,创略科技,网易x2,多益,顺丰,转转,抖音,一点咨询,作业帮×2, 东方头条,大华(2021.07),字节(2021.08),荣耀(2021.09)x2,贝壳(2021.08),蔚来(2021.09)
参考答案:
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数 据。
为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶 段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端 包括Spill过程,在Reduce端包括copy和sort过程,如图所示:
在数据和索引的大小到了mapreduce.map.sort.spill.percent参数设置的比例时(默认80%,这个是调优的 参数),会有两个动作:
1、对写入的数据进行原地排序,并把排序好的数据和索引spill到磁盘上去;
2、在空闲的20%区域中,重新算一个新的赤道,然后在新赤道的右边写入数据,左边写入索引;
3、当20%写满了,但是上一次80%的数据还没写到磁盘的时候,程序就会panding一下,等80%空间腾 出来之后再继续写。
如此循环往复,永不停歇,直到所有任务全部结束。整个操作都在内存,形状像一个环,所以才叫环形 缓冲区。
为什么要有环形缓冲区?
主要有以下几点
1、使用环形缓冲区,便于写入缓冲区和写出缓冲区同时进行。
2、为了防止阻塞,所以环型缓冲区不会等缓冲区满了再spill
3、每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构中,使用环形数据结构是为 了更有效地使用内存空间,在内存中放置尽可能多的数据。
4、环形缓冲区不需要重新申请新的内存,始终用的都是这个内存空间。大家知道MR是用java写的,而Java有一个最讨厌的机制就是Full GC。Full GC总是会出来捣乱,这个bug也非常隐蔽,发现了也不好处理。环形缓冲区从头到尾都在用那一个内存,不断重复利用,因此完美的规避了Full GC导致的各种问题,同时也规避了频繁申请内存引发的其他问题。5、环形缓冲区同时做了两件事情:1、排序;2、索引。在这里一次排序,将无序的数据变为有序,写 磁盘的时候顺序写,读数据的时候顺序读,效率高非常多!
在这里设置索引区也是为了能够持续的处理任务。每读取一段数据,就往索引文件里也写一段,这样在 排序的时候能加快速度。MapReduce为什么一定要有ShuGle过程
问过的一些公司:百度,头条,字节(2021.09) 参考答案:
MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负 责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过ShuGle 来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。ShuGle横跨Map端和Reduce端,在Map端 包括Spill过程,在Reduce端包括copy和sort过程。MapReduce的ShuGle过程及其优化
可回答:1)Hadoop的Shuffle过程;2)为什么Map端输出的时候需要排序?不排序直接输出难道不好 吗?3)介绍下MapReduce的Shuffle机制;3)你觉得MapReduce有哪些需要优化的地方;4)哪些操作引 起shuffle;5)说一下shuffle机制;6)说一下reduce的shuffle?7)shuffle流程的细节是什么
问过的一些公司:字节×4,字节(2021.07)(2021.08),头条,百度×2,第四范式,360,猿辅导,美团×3, 美团(2021.08)(2021.09),平安,创略科技,网易x2,多益,顺丰,转转,抖音,一点咨询,作业帮×2, 东方头条,大华(2021.07),字节(2021.08),荣耀(2021.09)x2,贝壳(2021.08),蔚来(2021.09)
参考答案:
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数 据。
为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶 段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。
从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端 包括Spill过程,在Reduce端包括copy和sort过程,如图所示: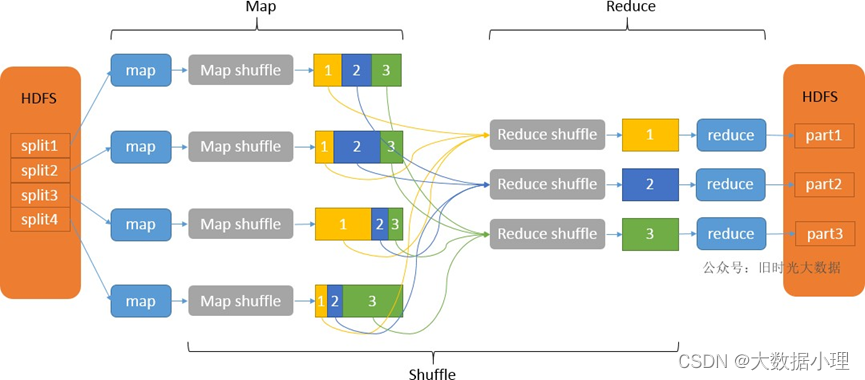
1、Spill过程
Spill过程包括输出、排序、溢写、合并等步骤,如图所示:
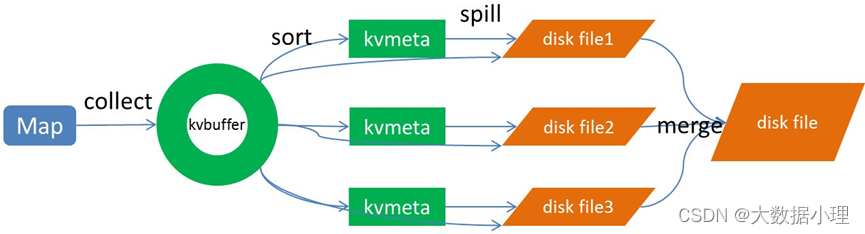
collect过程
每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构 是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
注意:关于环形缓冲区,也可以看看前面的题目解答
这个数据结构其实就是个字节数组,叫Kvbuffer, 名如其义,但是这里面不光放置了数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。数据区域和索引数据区域在Kvbuffer中是相邻不 重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次 Spill之后都会更新一次。初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:
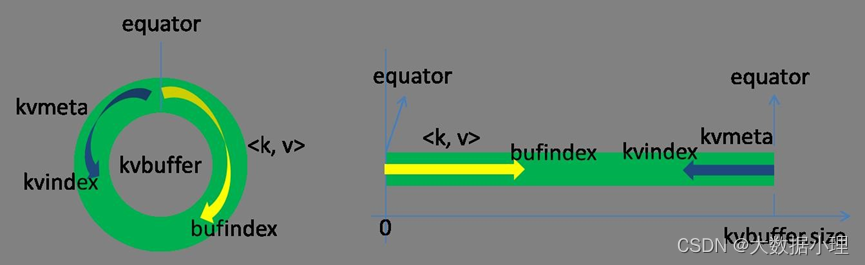
Kvbuffer的存放指针bufindex是一直闷着头地向上增长,比如bufindex初始值为0,一个Int型的key写完之 后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8。索引是对在kvbuffer中的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度, 占用四个Int长度,Kvmeta的存放指针Kvindex每次都是向下跳四个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如 Kvindex初始位置是-4,当第一个写完之后,(Kvindex+0)的位置存放value的起始位置、(Kvindex+1)的位置存放key的起始位置、 (Kvindex+2)的位置存放partition的
值、(Kvindex+3)的位置存放value的长度,然后Kvindex跳到-8位置,等第二 个和索引写完之后,Kvindex 跳到-32位置。
Kvbuffer的大小虽然可以通过参数设置,但是总共就那么大,和索引不断地增加,加着加着,Kvbuffer总 有不够用的那天,那怎么办?把数据从内存刷到磁盘上再接着往内存写数据,把 Kvbuffer中的数据刷到磁盘上的过程就叫Spill,多么明了的叫法,内存中的数据满了就自动地spill到具有更大空间的磁盘。
关于Spill 触发的条件,也就是Kvbuffer用到什么程度开始Spill,还是要讲究一下的。如果把Kvbuffer用得死死得,一点缝都不剩的时候再开始 Spill,那Map任务就需要等Spill完成腾出空间之后才能继续写数
据;如果Kvbuffer只是满到一定程度,比如80%的时候就开始 Spill,那在Spill的同时,Map任务还能继续写数据,如果Spill够快,Map可能都不需要为空闲空间而发愁。两利相衡取其大,一般选择后 者。
Spill这个重要的过程是由Spill线程承担,Spill线程从Map任务接到“命令”之后就开始正式干活,干的活叫SortAndSpill,原来不仅仅是Spill,在Spill之前还有个颇具争议性的Sort。
sort过程
先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是
Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
Spill过程
Spill线程为这次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录, 找到之后在其中创建一个类似于 “spill12.out”的文件。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到这个文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍 历完。一个partition在文件中对应的数据也叫段(segment)。
所有的partition对应的数据都放在这个文件里,虽然是顺序存放的,但是怎么直接知道某个partition在这 个文件中存放的起始位置呢?强大的索引又出场了。有一个三元组记录某个partition对应的数据在这个 文件中的索引:起始位置、原始数据长度、压缩之后的数据长度,一个partition对应一个三元组。然后 把这些索引信息存放在内存中,如果内存中放不下了,后续的索引信息就需要写到磁盘文件中了:从所 有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out.index” 的文件,文件中不光存储了索引数据,还存储了crc32的校验数据。 (spill12.out.index不一定在磁盘上创建,如果内存(默认1M空间)中能放得下就放在内存中,即使在磁盘上创建了,和 spill12.out文件也不一定在同一个目录下。)
每一次Spill过程就会最少生成一个out文件,有时还会生成index文件,Spill的次数也烙印在文件名中。 索引文件和数据文件的对应关系如下图所示: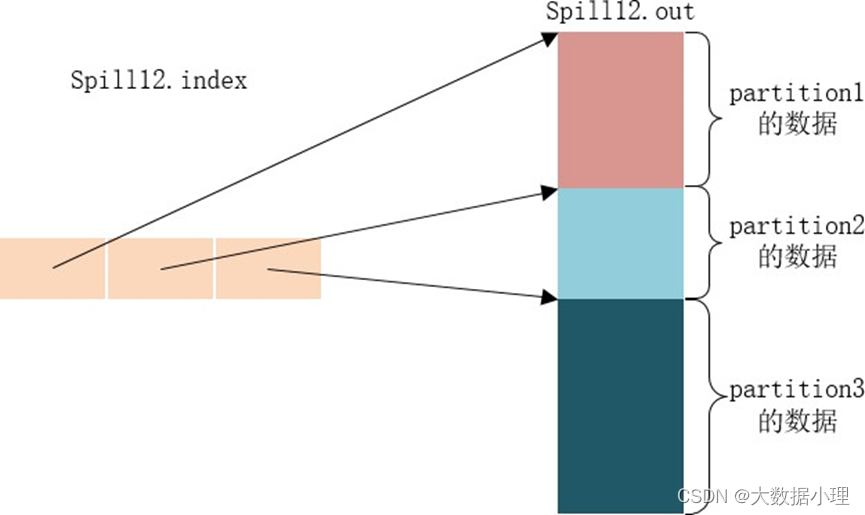
在Spill线程如火如荼的进行SortAndSpill工作的同时,Map任务不会因此而停歇,而是一无既往地进行着 数据输出。Map还是把数据写到kvbuffer中,那问题就来了:只顾着闷头按照bufindex指针向上增长, kvmeta只顾着按照Kvindex向下增长,是保持指针起始位置不变继续跑呢,还是另谋它路?如果保持指 针起始位置不变,很快bufindex和Kvindex就碰头了,碰头之后再重新开始或者移动内存都比较麻烦,不 可取。Map取 kvbuffer中剩余空间的中间位置,用这个位置设置为新的分界点,bufindex指针移动到这个分界点,Kvindex移动到这个分界点的-16位置,然后两者就可以和谐地按照自己既定的轨迹放置数据
了,当Spill完成,空间腾出之后,不需要做任何改动继续前进。分界点的转换如下图所示: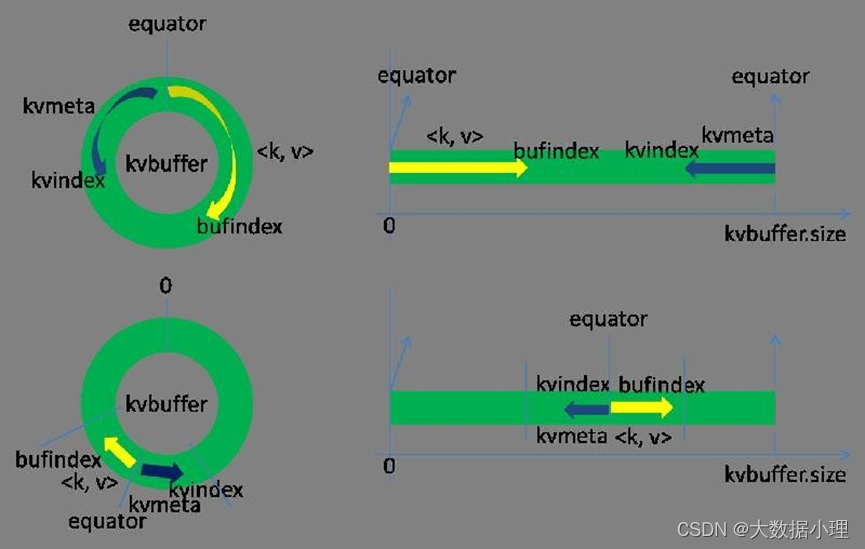
Map任务总要把输出的数据写到磁盘上,即使输出数据量很小在内存中全部能装得下,在最后也会把数 据刷到磁盘上。
merge过程
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同 的磁盘上。最后把这些文件进行合并的merge过程闪亮登场。Merge过程怎么知道产生的Spill文件都在哪了呢?从所有的本地目录上扫描得到产生的Spill文件,然后把 路径存储在一个数组里。Merge过程又怎么知道Spill的索引信息呢?没错,也是从所有的本地目录上扫 描得到Index文件,然后把索引信息存储在一个列表里。到这里,又遇到了一个值得纳闷的地方。 在之前Spill过程中的时候为什么不直接把这些信息存储在内存中呢,何必又多了这步扫描的操作?特别是Spill的索引数据,之前当内存超限之后就把数 据写到磁盘,现在又要从磁盘把这些数据读出来,还是需要装到更多的内存中。之所以多此一举,是因为这时kvbuffer这个内存大户已经不再使用可以回 收,有内存空间来装这些数据了。(对于内存空间较大的土豪来说,用内存来省却这两个io步骤还是值得考虑 的。)
然后为merge过程创建一个叫file.out的文件和一个叫file.out.Index的文件用来存储最终的输出和索引。
一 个partition一个partition的进行合并输出。对于某个partition来说,从索引列表中查询这个partition对应的所有索引信 息,每个对应一个段插入到段列表中。也就是这个partition对应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文 件名、起始位置、长度等等。
然后对这个partition对应的所有的segment进行合并,目标是合并成一个segment。当这个 partition对应很多个segment时,会分批地进行合并:先从segment列表中把第一批取出来,以key为关键字放置成最 小堆,然后从最小 堆中每次取出最小的输出到一个临时文件中,这样就把这一批段合并成一个临时的段,把它加回到segment列表中;再从segment列表中把第二批取出 来合并输出到一个临时segment,把其加入到列表中;这样往复执行,直到剩下的段是一批,输出到最终的文件中。
最终的索引数据仍然输出到Index文件中。
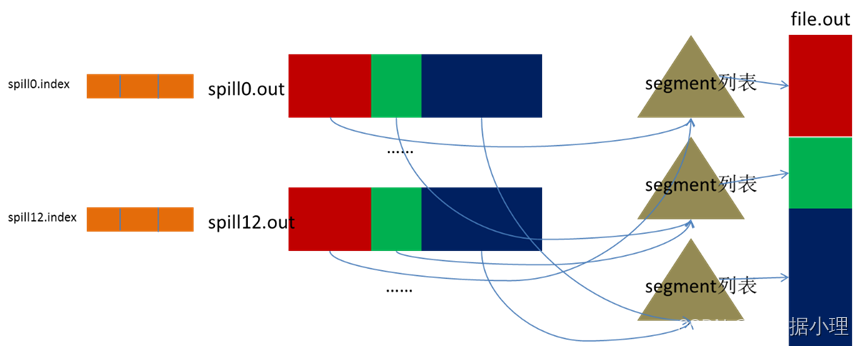
Map端的Shuffle过程到此结束。
2、copy过程
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。每个节点都会启动一个常驻的HTTP server, 其中一项服务就是响应Reduce拖取Map数据。当有MapOutput的HTTP请求过来的时候,HTTP server就读取相应的Map输出文件中对应这个Reduce部分的数据通过网络流输出给Reduce。
Reduce任务拖取某个Map对应的数据,如果在内存中能放得下这次数据的话就直接把数据写到内存中。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存中存储的Map数据占用空间 达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中。
如果在内存中不能放得下这个Map的数据的话,直接把Map数据写到磁盘上,在本地目录创建一个文 件,从HTTP流中读取数据然后写到磁盘,使用的缓存区大小是64K。拖一个Map数据过来就会创建一个 文件,当文件数量达到一定阈值时,开始启动磁盘文件merge,把这些文件合并输出到一个文件。
有些Map的数据较小是可以放在内存中的,有些Map的数据较大需要放在磁盘上,这样最后Reduce任务 拖过来的数据有些放在内存中了有些放在磁盘上,最后会对这些来一个全局合并。
3、merge sort过程这里使用的Merge和Map端使用的Merge过程一样。Map的输出数据已经是有序的,Merge进行一次合并排 序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个 阶段是重叠而不是完全分开的。
Reduce端的Shuffle过程至此结束。
MapReduce ShuGle后续优化方向
压缩:对数据进行压缩,减少写读数据量;
减少不必要的排序:并不是所有类型的Reduce需要的数据都是需要排序的,排序这个nb的过程如 果不需要最好还是不要的好;
内存化:Shuffle的数据不放在磁盘而是尽量放在内存中,除非逼不得已往磁盘上放;当然了如果有 性能和内存相当的第三方存储系统,那放在第三方存储系统上也是很好的;这个是个大招;
网络框架:netty的性能据说要占优了;
本节点上的数据不走网络框架:对于本节点上的Map输出,Reduce直接去读吧,不需要绕道网络框 架。Reduce怎么知道去哪里拉Map结果集?
问过的一些公司:携程(2021.09),美团(2021.09) 参考答案:
每个节点都会启动一个常驻的HTTP server,其中一项服务就是响应Reduce拖取Map数据。Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。当有MapOutput的HTTP请求过来的时候,HTTP server就读取相应的Map输出文件中对应这个Reduce部分的数据通过网络流输出给Reduce。Reduce阶段都发生了什么,有没有进行分组
问过的一些公司:陌陌(2021.10) 参考答案:-
Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一 定阈值,则写到磁盘上,否则直接放到内存中。
-
Merge阶段:在远程拷贝数据的同时,ReduceTask启动了两个后台线程对内存和磁盘上的文件进行合 并,以防止内存使用过多或磁盘上文件过多。
-
Sort阶段:按照MapReduce语义,用户编写reduce()函数输入数据是按key进行聚集的一组数据。为了 将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理 结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
-
Reduce阶段:reduce()函数将计算结果写到HDFS上。
在ReduceTask的Shuffle阶段,会获取到比较器,将从Map获取到的数据中key相同的分为同一组 -
public RawComparator getOutputValueGroupingComparator() {
-
// 从配置中读取mapreduce.job.output.group.comparator.class,
-
Class theClass = getClass(JobContext.GROUP_COMPARATOR_CLASS, null, RawComparator.class);
-
//如果没有设置,默认使用MapTask对key排序时,key的比较器
-
if (theClass == null) {
-
return getOutputKeyComparator();
7 } -
// 否则用户设置了,就使用用户自定义的比较器
-
return ReflectionUtils.newInstance(theClass, this); 10 }
11
MapReduce ShuGle的排序算法
可回答:shuffle时会对数据进行排序吗问过的一些公司:字节(2021.08)
参考答案:
1、排序的简单介绍
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中 的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放在环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对 缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁 盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写 磁盘上,否则存储在内存中,如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大 文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数 据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。
2、排序的分类
部分排序
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。 全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处 理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行框架。
辅助排序:(GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个活几个字段相同(全部 字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
3、自定义排序原理分析
bean对象做为key传输,需要实现 WritableComparable 接口重写compareTo方法,就可以实现排序。 - MapReduce 易于编程
-
相关阅读:
【毕业设计源码】基于java的房地产企业销售信息管理系统
Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks
盲盒电商模式:融合神秘感与趣味性,带来消费者购买欲望与商业利益
集群节点批量执行 shell 命令
Multer 实现文件上传功能
2.0、C语言数据结构——时间复杂度和空间复杂度 (1)
vs中集成vcpkg
LLC开关电源开发:第三节,LLC电路原理图及开环仿真
以用地业务链串接为核心的自然资源业务数据治理与重构路径
JMeter入门教程(9) --参数化
- 原文地址:https://blog.csdn.net/m0_46914845/article/details/126563991