-
再看目标检测map指标
1、引言
对于目标检测,我们该怎么判断检测的整体好坏呢?如下面这张图:

IOU大于指定阈值?类别正确?还是置信度大于指定阈值?直观的感觉是都要考虑到。
2、几个关键指标
TP、FP、FN,其实就是正确检出、误检和漏检的数量。
TP(True Positive,正确检出):IOU>0.5的检测框数量(同一Ground Truth只计算一次);
FP(False Positive,误检):IOU
FN(False Negative,漏检):没有检测到的GT的数量;
查准率、查全率:
Precision(查准率、精度):TP / (TP + FP) 模型预测的所有目标中,预测正确的比例;
Recall(查全率):TP / (TP + FN) 所有真实目标中,模型预测正确的目标比例;
查准率描述了模型本身的准确率,查全率反映了有正样本被检测到的比例。两个指标一般要一块用,单独一个指标没有特别的参考意义。如下图,绿色为真值,红色为检测结果。左图模型只检测到一个目标,且是正确的,根据定义Precision=1,但是漏掉了很多目标。右图,检测到比实际多很多的框,数量取胜,所有目标均检测到,根据定义Recall=1,但是有很多的错误。所以,一般两个指标结合着使用,AP。

AP:P-R曲线下的面积,AP越大模型检测效果越好;
P-R曲线:Precision-Recall曲线;
mAP:mean Average Precision,即各类被的AP平均值;
3、AP计算
绿色为真值,红色为检测框。统计每张图的与真值有交集的检测框:GT ID、置信度、是否是目标(IOU>0.5),然后按照置信度倒排序。过程如下:
第一张图:

第二张图:
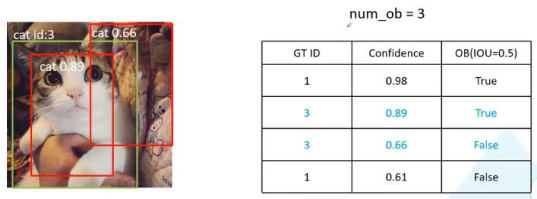
第三张图:

按照置信度倒排序,从上至下,依次计算查全率和查准率。结果如下:

按这个结果给出的PR曲线会出现Recall高时反而精度比Recall低时高的情况,这里每个Recall的取它下面排名中最大的Precision,相同Recall只统计一次,结果如下:
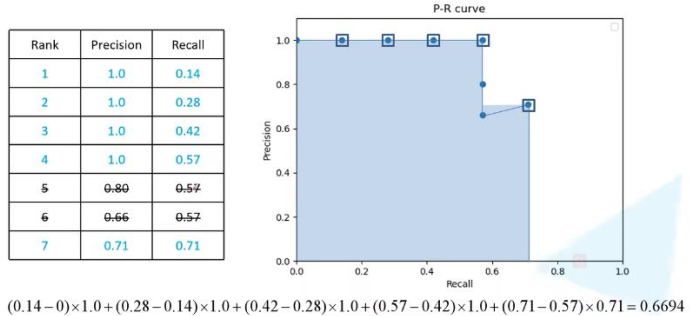
上面即为VOC2017 mAP指标计算方式。
4、coco指标说明
coco的官网给出指标说明,COCO - Common Objects in Context,这里摘取:
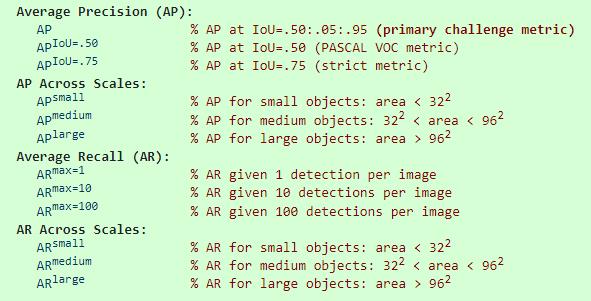
Average Precision(AP):
根据不同Iou约束,确定的AP。
AP:及Iou为0.5:0.05:0.95是所有AP的平均值;
APIou=0.5:即VOC2017的AP;
APIou=0.7:Iou更严格的AP。
AP Across Scales:
根据不同面积约束,确定的AP。
APsmall:面积小于32*32的所有目标的AP平均值;
APmedium:面积在32*32至96*96的所有目标的AP平均值;
APlarge:面积大于96*96的所有目标的AP平均值。
Average Recall(AR):
根据约束每张图上检测目标个数,确定的AP。
APmax=1:每张图上最多只检测1个目标是的AP;
APmax=10:每张图上最多只检测10个目标是的AP;
APmax=100:每张图上最多只检测100个目标是的AP。
-
相关阅读:
SpringCloud学习笔记(二)Eureka 服务注册与发现
position left设置居中,除了auto以外,还有什么方式
webpack之性能优化
MySql ocp认证之备份与恢复(四)
指数族分布与相关性质(1) 定义、联合分布、微分性质
山西电力市场日前价格预测【2023-11-19】
ESP32 vscode环境搭建
Java 定时任务-最简单的3种实现方法
高并发下秒杀商品,你必须知道的9个细节
Prometheus 监控 Hyperledger Fabric 网络
- 原文地址:https://blog.csdn.net/weixin_34910922/article/details/126562380