-
【JavaScript 逆向】Protobuf 协议之万方数据平台正逆分析
前言
现在一些网站对 JavaScript 代码采取了一定的保护措施,比如变量名混淆、执行逻辑混淆、反调试、核心逻辑加密等,有的则在数据传输过程中进行了混淆,本次的案例为 Protobuf 协议反序列化。
声明
本文章中所有内容仅供学习交流,相关链接做了脱敏处理,若有侵权,请联系我立即删除!
Protobuf 浅析
Protobuf 协议
Protobuf(Protocol Buffer)是 Google 开发的一套数据存储传输协议,为二进制序列化格式,可用作 JSON 或 XML 等格式的更有效替代方案。开发人员可以在 .proto 文件中定义消息格式,并使用 protobuf 编译器(protoc)按他们选择的语言生成消息处理程序。Protobuf 编码是二进制的,与 json、xml 不同,它不是可读的,也不容易手动修改。Protobuf 能够把数据压缩得很小,所以传输数据就比 xml 和 json 快几倍,使用其有利于提高效率,但同时增加了分析或修改数据的难度。
序列化 (Serialization) 是指将对象转换为字节序列的过程,在序列化期间,对象将其当前状态写入到临时或持久性存储区,以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
Protobuf 协议分析可参考:Protobuf 协议浅析
Protobuf 环境配置
protobuf 模块及编译器 protoc 下载地址:protobuf 模块及编译器下载地址,以上两个都需要下载安装:
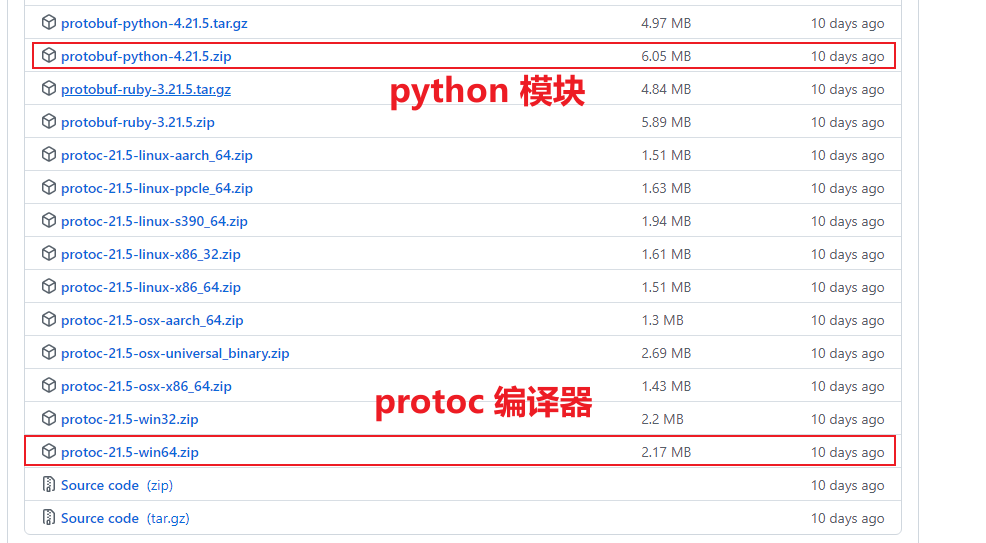
具体安装配置过程及 Protobuf 相关可阅读:目录三:Protobuf 环境配置
Protobuf 实现基本过程
- 编写 .proto 文件
- 将 .proto 文件编译成对应编程语言的包
- 将包导入,通过代码实现 .proto 文件的序列化,并将序列化后的内容保存到 .bin 文件中,序列化后的数据可读性极差
- Protobuf 序列化完成,若想还原为可读数据,则需进行反序列化操作
Python 演示
1. 编写 .proto 文件
- // 指定使用 proto3 语法, 默认为 proto2
- syntax = "proto3";
- // message: 语法关键字
- // SearchRequest: 变量名
- message Blog {
- // 两个字段
- // 字段数据类型 字段名称 = 数字标识号;
- // 标识号最小从 1 开始
- string blog_title_name = 1;
- string blogger_name = 2;
- int32 blog_id = 3;
- // enum 枚举,默认是第一个定义的枚举值必须为 0
- // 枚举即为字段指定某预定义值序列中的一个值
- enum BlogType {
- Life = 0;
- Educational = 1;
- Technical = 2;
- }
- // 消息类型嵌套
- message BlogInfo {
- // repeated 声明重复字段
- repeated string blogger_name = 1;
- // 引用类型
- BlogType type = 2;
- }
- // 调用消息
- repeated BlogInfo info = 4;
- }
2. 将 .proto 文件编译成对应编程语言的包,cmd 进入 .proto 文件所在文件夹,输入以下命令,即可将 .proto 文件编译成 xxx_pb2.py 文件,若缺少 builder 模块,需自行安装,pip3 install builder:
- // 格式: protoc --编程语言_out=. 文件名.proto, _out=. 后有空格
- protoc --python_out=. pb_demo.proto
文件大致内容如下:
- from google.protobuf.internal import builder as _builder
- from google.protobuf import descriptor as _descriptor
- from google.protobuf import descriptor_pool as _descriptor_pool
- from google.protobuf import symbol_database as _symbol_database
- # @@protoc_insertion_point(imports)
- _sym_db = _symbol_database.Default()
- DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(
- b'\n\rpb_demo.proto\"\xda\x01\n\x04\x42log\x12\x17\n\x0f\x62log_title_name\x18\x01 \x01(\t\x12\x14\n\x0c\x62logger_name\x18\x02 \x01(\t\x12\x0f\n\x07\x62log_id\x18\x03 \x01(\x05\x12\x1c\n\x04info\x18\x04 \x03(\x0b\x32\x0e.Blog.BlogInfo\x1a>\n\x08\x42logInfo\x12\x14\n\x0c\x62logger_name\x18\x01 \x03(\t\x12\x1c\n\x04type\x18\x02 \x01(\x0e\x32\x0e.Blog.BlogType\"4\n\x08\x42logType\x12\x08\n\x04Life\x10\x00\x12\x0f\n\x0b\x45\x64ucational\x10\x01\x12\r\n\tTechnical\x10\x02\x62\x06proto3')
- _builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
- _builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'pb_demo_pb2', globals())
- if _descriptor._USE_C_DESCRIPTORS == False:
- DESCRIPTOR._options = None
- _BLOG._serialized_start = 18
- _BLOG._serialized_end = 236
- _BLOG_BLOGINFO._serialized_start = 120
- _BLOG_BLOGINFO._serialized_end = 182
- _BLOG_BLOGTYPE._serialized_start = 184
- _BLOG_BLOGTYPE._serialized_end = 236
- # @@protoc_insertion_point(module_scope)
3. 将包导入,通过代码实现 .proto 文件的序列化
- # 导入 XXX_pb2
- import pb_demo_pb2
- # 调用消息类
- msg = pb_demo_pb2.Blog()
- msg.blog_title_name = "Yy_Rose's blog"
- msg.blogger_name = "Yy_Rose"
- msg.blog_id = 123
- bt = msg.info.add()
- bt.type = 3
- with open("pb_demo_b.bin", "wb") as f:
- # SerializeToString() 序列化字符串
- print(msg.SerializeToString())
- f.write(msg.SerializeToString())
- # b'\n\x0eYy_Rose\'s blog\x12\x07Yy_Rose\x18{"\x02\x10\x03'
4. 反序列化
方法一,导入 _pb2 调用模块:
- import pb_demo_pb2
- def list_msg(m):
- print("id: %s" % m.blog_title_name)
- print("name: %s" % m.blogger_name)
- print("email: %d" % m.blog_id)
- for blog_t in m.info:
- print("phone type: %s" % blog_t.type)
- msg = pb_demo_pb2.Blog()
- with open("pb_demo_b.bin", "rb") as f:
- msg.ParseFromString(f.read())
- list_msg(msg)
- # id: Yy_Rose's blog
- # name: Yy_Rose
- # email: 123
- # phone type: 3
方法二,导入反序列化包 blackboxprotobuf:
Blackbox Protobuf 是一个反序列化工具,旨在允许在没有消息定义的情况下使用协议缓冲区,其最初是作为 Burp 扩展实现的,用于在移动渗透测试期间解码和修改消息,但也被用于逆向工程。
Github:blackboxprotobuf: Blackbox protobuf
- import blackboxprotobuf
- with open(r"pb_demo_b.bin", "rb") as fp:
- data = fp.read()
- # protobuf_to_json: protobuf 转 json, 解包
- deserialize_data, message_type = blackboxprotobuf.protobuf_to_json(data)
- # 原始数据
- print("原始数据: %s" % deserialize_data)
- # 消息类型
- print("消息类型: %s" % message_type)
运行结果:
- 原始数据: {
- "1": "Yy_Rose's blog",
- "2": "Yy_Rose",
- "3": "123",
- "4": {
- "2": "3"
- }
- }
- 消息类型: {'1': {'type': 'bytes', 'name': ''}, '2': {'type': 'bytes', 'name': ''}, '3': {'type': 'int', 'name': ''}, '4': {'type': 'message', 'message_typedef': {'2': {'type': 'int', 'name': ''}}, 'name': ''}}
Protobuf 3 语法可参考:Protobuf 3 语法中文指南
案例目标
网址:
aHR0cHM6Ly93d3cud2FuZmFuZ2RhdGEuY29tLmNuL2luZGV4Lmh0bWw=
数据接口:
aHR0cHM6Ly9zLndhbmZhbmdkYXRhLmNvbS5jbi9TZWFyY2hTZXJ2aWNlLlNlYXJjaFNlcnZpY2Uvc2VhcmNo
以上均做了脱敏处理,Base64 编码及解码方式:
- import base64
- # 编码
- # result = base64.b64encode('待编码字符串'.encode('utf-8'))
- # 解码
- result = base64.b64decode('待解码字符串'.encode('utf-8'))
- print(result)
常规 JavaScript 逆向思路
一般情况下,JavaScript 逆向分为三步:
- 寻找入口:逆向在大部分情况下就是找一些加密参数到底是怎么来的,关键逻辑可能写在某个关键的方法或者隐藏在某个关键的变量里,一个网站可能加载了很多 JavaScript 文件,如何从这么多的 JavaScript 文件的代码行中找到关键的位置,很重要;
- 调试分析:找到入口后,我们定位到某个参数可能是在某个方法中执行的了,那么里面的逻辑是怎么样的,调用了多少加密算法,经过了多少赋值变换,需要把整体思路整理清楚,以便于断点或反混淆工具等进行调试分析;
- 模拟执行:经过调试分析后,差不多弄清了逻辑,就需要对加密过程进行逻辑复现,以拿到最后我们想要的数据
接下来开始正式进行案例分析:
寻找入口
在搜索栏搜索围棋,会出现以下结果:
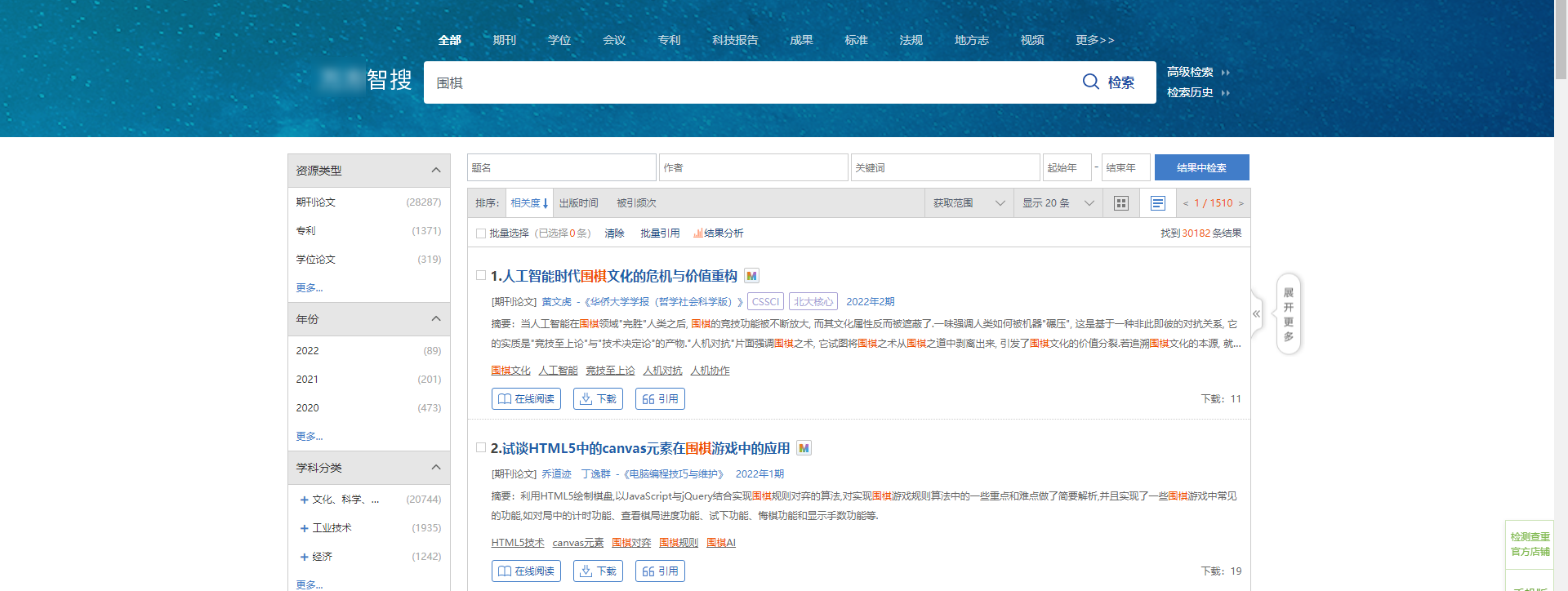
右键点击页面,选择检查网页源代码,ctrl + f 搜索第一篇论文的标题,会发现没有任何结果,由此可知,页面内容是通过 ajax 加载的:

F12 打开开发者人员工具,在 Network 的筛选栏选择 XHR,刷新网页,会看到抓包到了一些数据,search 中能找到我们输入的关键词围棋,但是发现请求被混淆了 :
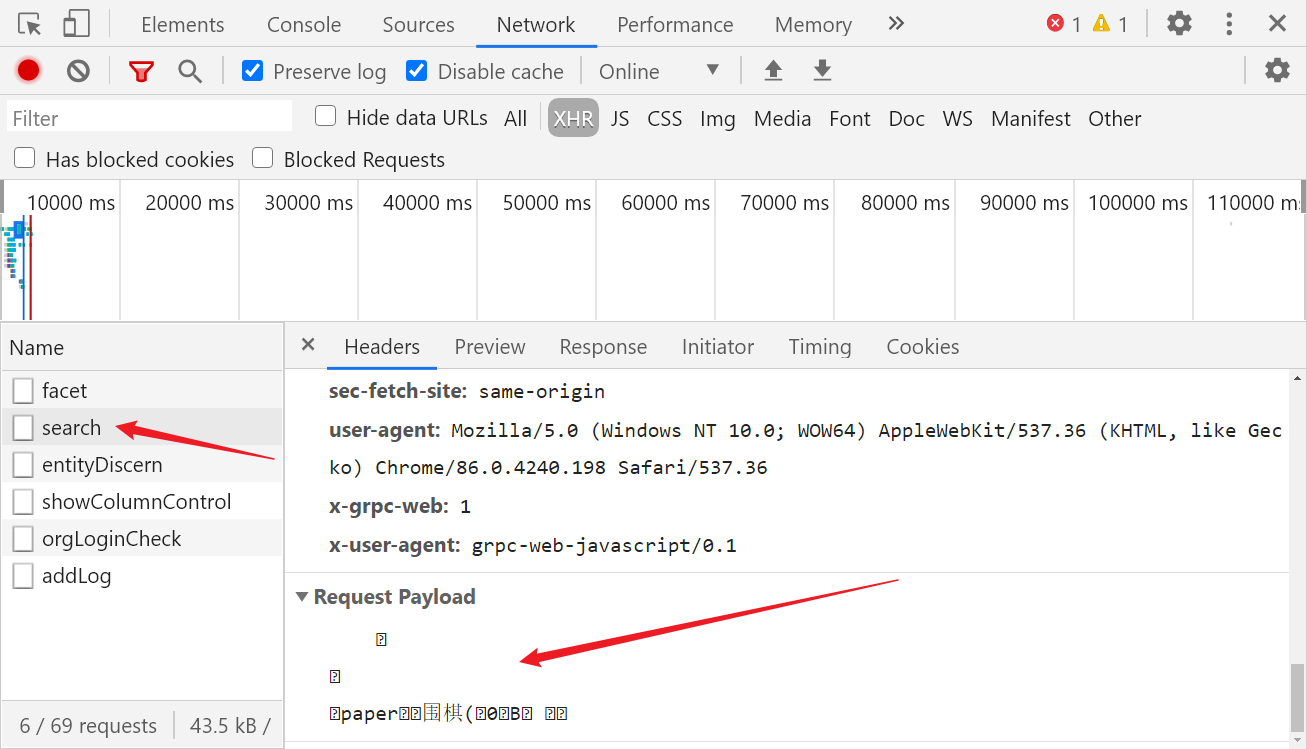
响应返回的数据也是一大串不可读的内容:

我们能在这个数据包的请求头中发现如下特征,很明显以上数据是 protobuf 序列化后的结果:
- // 请求体类型: proto
- content-type: application/grpc-web+proto
以下通过两种方式对其进行反序列化操作:
方法一:构造 .protoc 文件
首先需要通过逆向找到数据加载生成的位置,有两种方式:
1. 跟栈
network 中打开抓包到的接口,选择 Initiator,向下跟栈,关键数据加载位置在 requestList 中:

点击后面链接跳转进去,在 app.d26aece8.js 文件中,在第 21673 行打下断点调试分析,Object(C["a"])({}, this.composeRequestParams()) 的控制台打印内容中存在搜索的关键词,包括一些原始请求参数:
- currentPage: 1
- pageSize: 20
- searchFilter: [0]
- searchScope: 0
- searchSort: {__ob__: Mt}
- searchType: "paper"
- searchWord: "围棋"
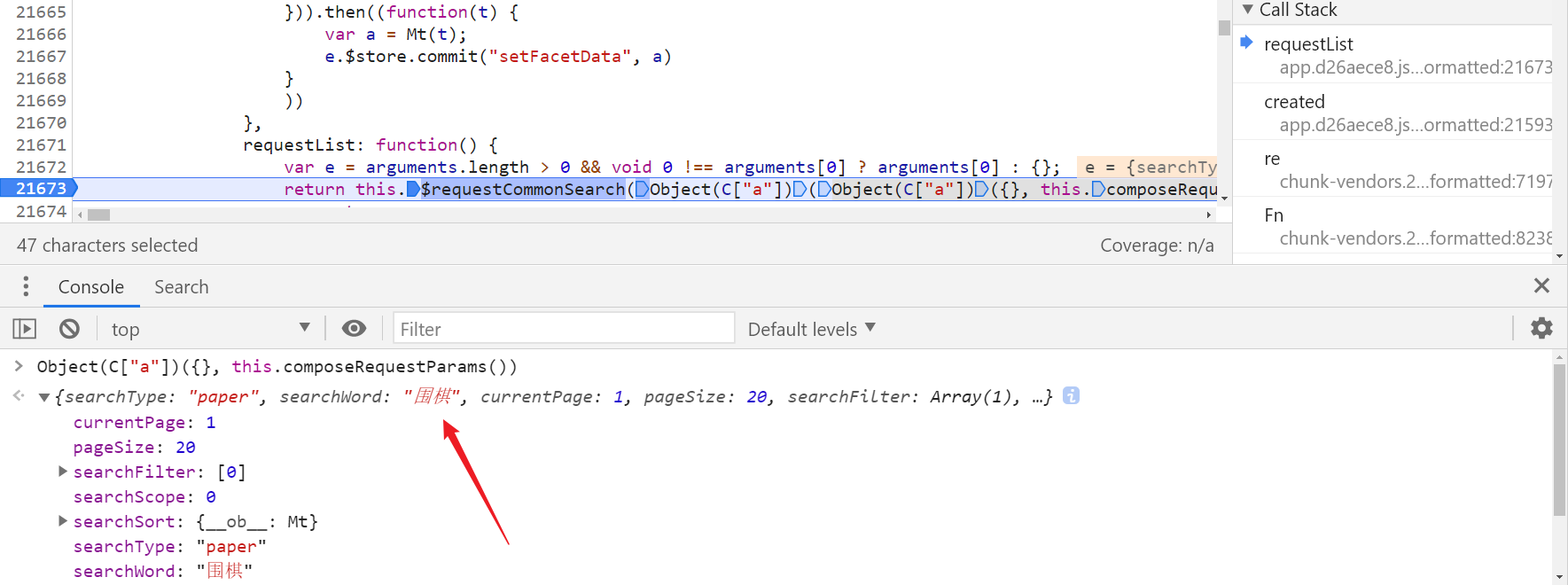
在其下一行断点调试可知,return e 即返回的是当页 20 条数据内容:

wf.proto
根据以上获取到的原始请求参数内容,构建 proto 文件:
- syntax = 'proto3';
- message SearchService{
- enum SearchScope {
- A = 0;
- }
- enum SearchFilter {
- B = 0;
- }
- message CommonRequest{
- string searchType = 1;
- string searchWord = 2;
- int32 currentPage = 3;
- int32 pageSize = 4;
- SearchScope searchScope = 5;
- repeated SearchFilter searchFilter = 6;
- }
- message SearchRequest{
- CommonRequest commonrequest = 1;
- }
- }
wf_pb2.py
运行以下命令即可生成 wf_pb2.py 文件:
protoc --python_out=. pb_demo.protowf_pb2.py 文件内容:
- # -*- coding: utf-8 -*-
- # Generated by the protocol buffer compiler. DO NOT EDIT!
- # source: s.proto
- """Generated protocol buffer code."""
- from google.protobuf.internal import builder as _builder
- from google.protobuf import descriptor as _descriptor
- from google.protobuf import descriptor_pool as _descriptor_pool
- from google.protobuf import symbol_database as _symbol_database
- # @@protoc_insertion_point(imports)
- _sym_db = _symbol_database.Default()
- DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(
- b'\n\x07s.proto\"\xc7\x02\n\rSearchService\x1a\xc2\x01\n\rCommonRequest\x12\x12\n\nsearchType\x18\x01 \x01(\t\x12\x12\n\nsearchWord\x18\x02 \x01(\t\x12\x13\n\x0b\x63urrentPage\x18\x03 \x01(\x05\x12\x10\n\x08pageSize\x18\x04 \x01(\x05\x12/\n\x0bsearchScope\x18\x05 \x01(\x0e\x32\x1a.SearchService.SearchScope\x12\x31\n\x0csearchFilter\x18\x06 \x03(\x0e\x32\x1b.SearchService.SearchFilter\x1a\x44\n\rSearchRequest\x12\x33\n\rcommonrequest\x18\x01 \x01(\x0b\x32\x1c.SearchService.CommonRequest\"\x14\n\x0bSearchScope\x12\x05\n\x01\x41\x10\x00\"\x15\n\x0cSearchFilter\x12\x05\n\x01\x42\x10\x00\x62\x06proto3')
- _builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, globals())
- _builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 's_pb2', globals())
- if _descriptor._USE_C_DESCRIPTORS == False:
- DESCRIPTOR._options = None
- _SEARCHSERVICE._serialized_start = 12
- _SEARCHSERVICE._serialized_end = 339
- _SEARCHSERVICE_COMMONREQUEST._serialized_start = 30
- _SEARCHSERVICE_COMMONREQUEST._serialized_end = 224
- _SEARCHSERVICE_SEARCHREQUEST._serialized_start = 226
- _SEARCHSERVICE_SEARCHREQUEST._serialized_end = 294
- _SEARCHSERVICE_SEARCHSCOPE._serialized_start = 296
- _SEARCHSERVICE_SEARCHSCOPE._serialized_end = 316
- _SEARCHSERVICE_SEARCHFILTER._serialized_start = 318
- _SEARCHSERVICE_SEARCHFILTER._serialized_end = 339
- # @@protoc_insertion_point(module_scope)
wf.py
- import wf as pb
- import requests
- search_request = pb.SearchService.SearchRequest()
- search_request.commonrequest.searchType = "paper"
- search_request.commonrequest.searchWord = '围棋'
- search_request.commonrequest.searchScope = 0
- search_request.commonrequest.currentPage = 1
- search_request.commonrequest.pageSize = 20
- search_request.commonrequest.searchFilter.append(0)
- bytes_body = search_request.SerializeToString()
- bytes_head = bytes([0, 0, 0, 0, len(bytes_body)])
- url = 'aHR0cHM6Ly9zLndhbmZhbmdkYXRhLmNvbS5jbi9TZWFyY2hTZXJ2aWNlLlNlYXJjaFNlcnZpY2Uvc2VhcmNo'
- headers = {
- 'Content-Type': 'application/grpc-web+proto',
- }
- resp = requests.post(url=url, data=bytes_head + bytes_body, headers=headers)
- print(resp.text)
运行后得到 protobuf 序列化后的结果,还需进行反序列化操作增强可读性,反序列化方式在后文:
2. XHR 断点
由于页面数据是通过 ajax 加载的,所以可以通过打 XHR 断点的方式定位到数据生成的位置,选择 + 号将接口链接的一部分内容添加到 XHR 断点中,这里添加的是 SearchService.SearchService/search :

刷新页面,在 chunk-vendors.2745eef3.js 文件的第 19276 行 send 处断住,再向下跟栈也能跟到上面所讲的位置,后续做法就跟之前一样了:

方法二:抓包,blackboxprotobuf 反序列化
通过 Fiddler 进行抓包,SearchService.SearchService/search 接口中是我们需要的数据,直接通过 requests 方法访问该接口是获取不到如下数据内容的:
在 HexView 中能看到一堆十六进制形式的数据:

黑色部分,去掉开头五个字节和末尾二十个字节,将剩余内容选中,右键选择 Save Selected Bytes To File,将其保存为 .bin 文件:

当然也可以直接全选,然后在代码中将多余部分剔除,例如:
blackboxprotobuf.protobuf_to_json(data[5:-20])此时 bin 文件中的内容为 protobuf 序列化后的结果,跟上文逆向后编写 proto 文件获取到的结果是一样的,这里对其进行反序列化操作:

创建 .py 文件,导入 blackboxprotobuf 模块,读取调用 .bin 文件,若读取报错,则为选取十六进制文件范围问题,以下代码即可获取到原始数据和消息类型:
- import blackboxprotobuf
- with open('test.bin', 'rb') as f:
- data = f.read()
- deserialize_data, message_type = blackboxprotobuf.protobuf_to_json(data)
- # deserialize_data, message_types = blackboxprotobuf.protobuf_to_json(data[5:-20])
- print("原始数据: %s" % deserialize_data)
- print("消息类型: %s" % message_type)
原始数据中即包含网页中的相关数据信息,可以通过正则等进行提取:
总结
以上是对 Protobuf 序列化协议的正向及逆向分析,逆向案例不难,主要是了解 Protobuf 协议的使用流程及逆向方式,如有任何见解欢迎评论区或私信指正交流~
-
相关阅读:
Huggingface transformers 镜像使用,本地使用,tokenizer参数介绍
PCB如何入门---一些经验与教训
ventory做U盘启动,使用vmware进行测试U盘系统盘是否制作成功
汽车ECU软件升级方案介绍
STM32H7 DMA阅读笔记
机器学习笔记 - k-NN算法的数学表达
Linux调试器-gdb使用
Nginx网络服务的配置
大数据计算,如何优化SQL?
Qt窗体间值的传递方法
- 原文地址:https://blog.csdn.net/Yy_Rose/article/details/126418857
