-
Redis入门
图形化Redis
这里采用的图形化Redis是GUI For Redis
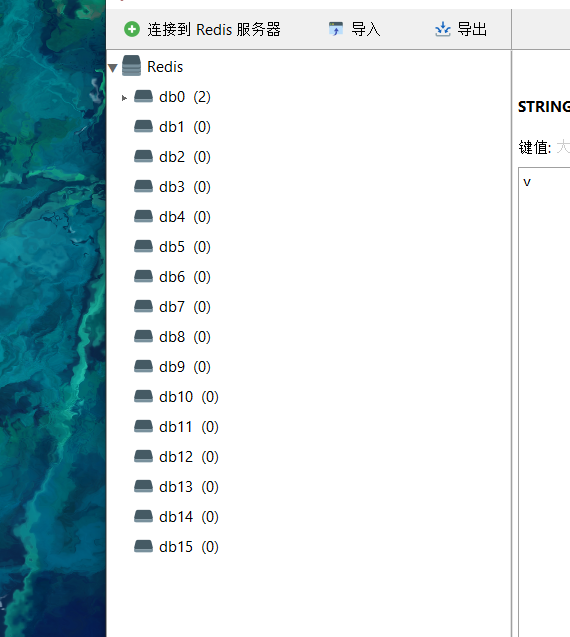
连接到Redis可以看到,默认是16个库,且默认选中是0
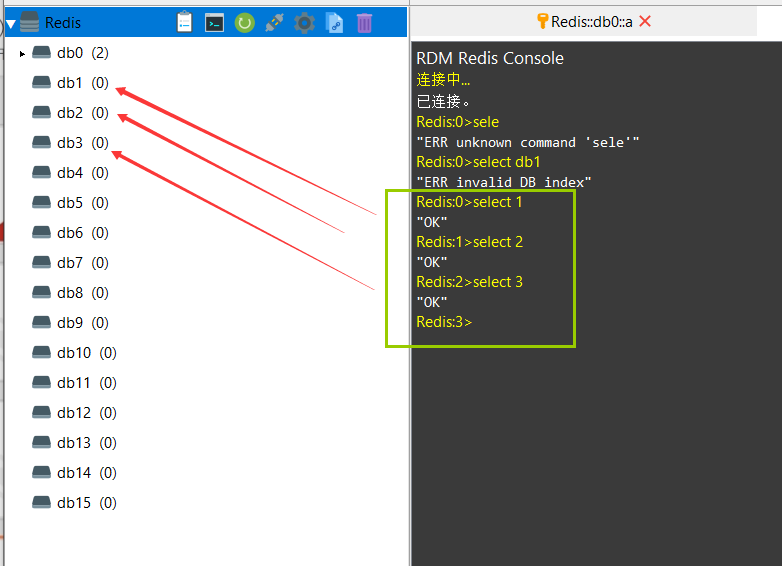
用select命令来切换不同的库
基础回顾
redis都是以k-v的形式缓存数据的
并且,缓存如果过多也是会造成溢出,所以要设置对应的生存时间


再次强调:基础数据类型都指的是value,而非key基础类型-String
基础内容
String数据类型的逻辑

冗余设计很好的避免了内存需要频繁分配的问题
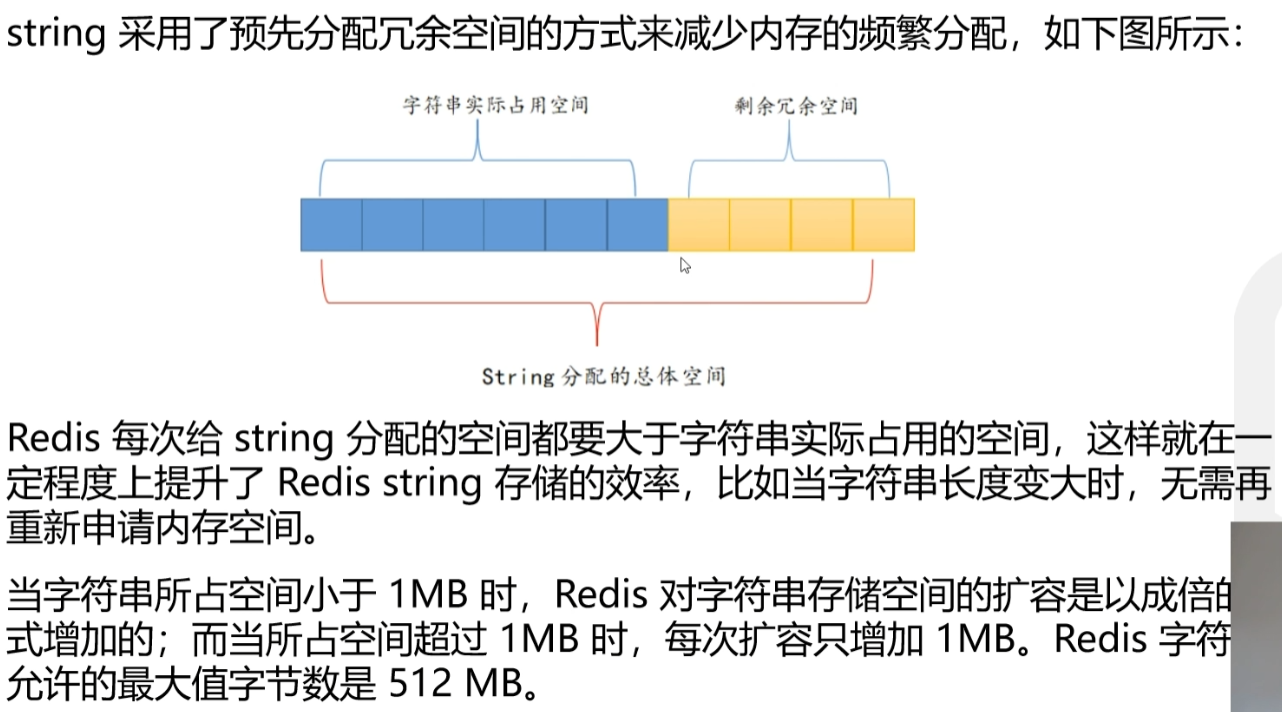
单一String的操作

注意,设置超时时间EX或者PX不可以用表达式(60*60这种)
使用示例

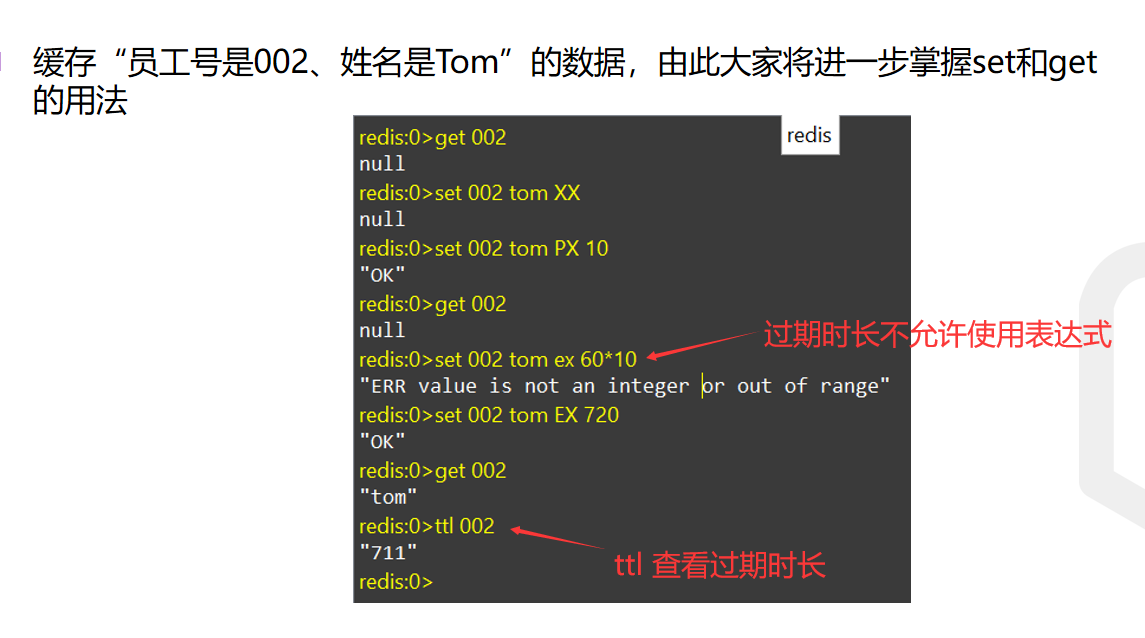
解释:由于一开始没有设置key为002的值,因此第1行的get命令将返回null 接着set命令里添加了XX参数,表示002号key存在时才进行操作,但此时002号key不存在,所以不操作,该set命令的返回结果依然是null 然后虽然成功地设置了值,但是通过PX命令设置了该键值对的生存时间是10毫秒,很快会过期,所以接下来的get命令依然无法得到值 通过EX参数设置了以秒为单位的生存时间,但是生存时间一定是数值,不能是表达式,会返回错误。 最后通过ttl可以参考key的剩余生存时间 字符串可以用双引号包含,也可以用单引号包含,还可以不带任何符号。- 1
- 2
- 3
- 4
- 5
- 6
设置获取多个String类型操作

操作示例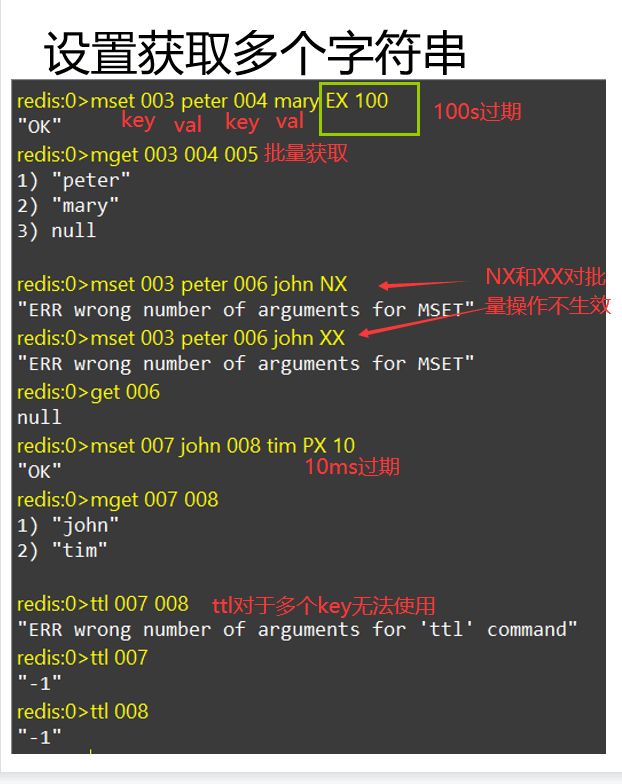
增减操作
通过incr key命令能对key所对应的数字类型值进行加1操作,如果k不存在,默认在0的基础上+1
通过decr key命令能对key所对应的值进行减1操作,如果k不存在,默认在0的基础上-1
通过incrby key increment命令能对key对应的值进行加increment的操作
通过decrby by decrement命令能对key对应的值进行减decrement的操作。
运行上述命令时,需要确保key对应的值是数字类型,否则会报错。
在实际项目里,上述命令一般会用在统计流量和控制并发的场景中

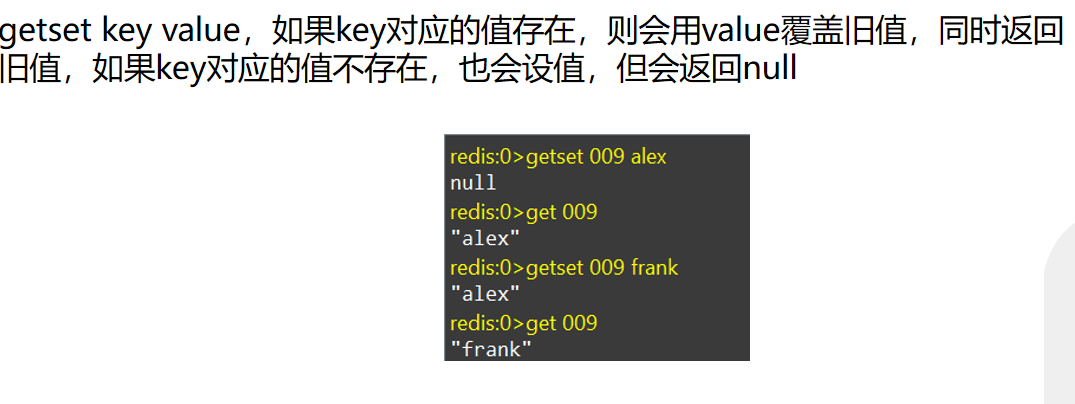
其他指令
了解即可,比set指令多了一个返回被覆盖值的操作
基础类型-Hash
基础内容
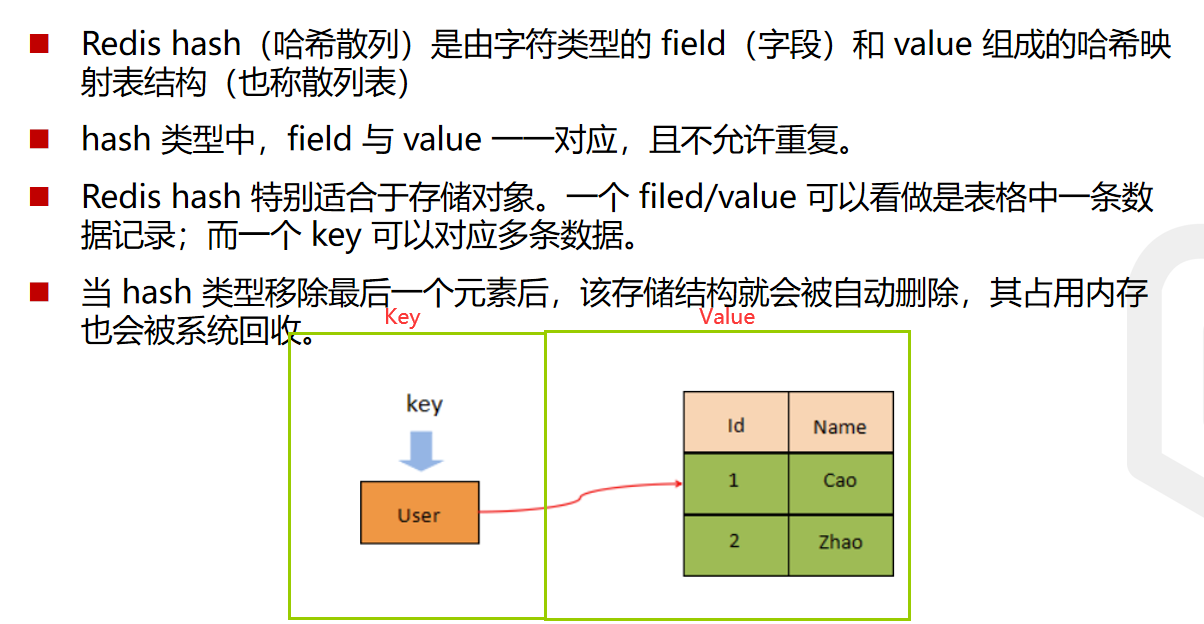

哈希表
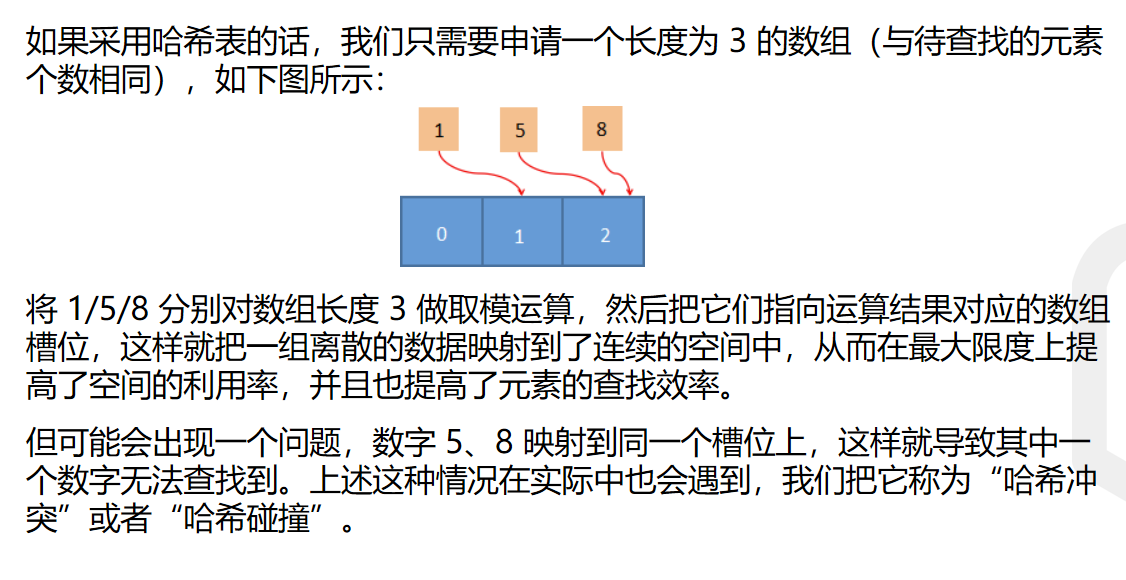
初衷是希望借助数组索引的帮助来进行快速定位,从而拿到数据
图上的1、5、8是value,也就是要被查的数据
依靠下面的索引来做key,顺便加快访问,那么这种情况下,我只需要索引,数组的数据对我来说是无所谓的,像1、5、8以外的数据都是无意义的

越糟糕的哈希算法,其哈希碰撞率是越高的
解决哈希碰撞的方法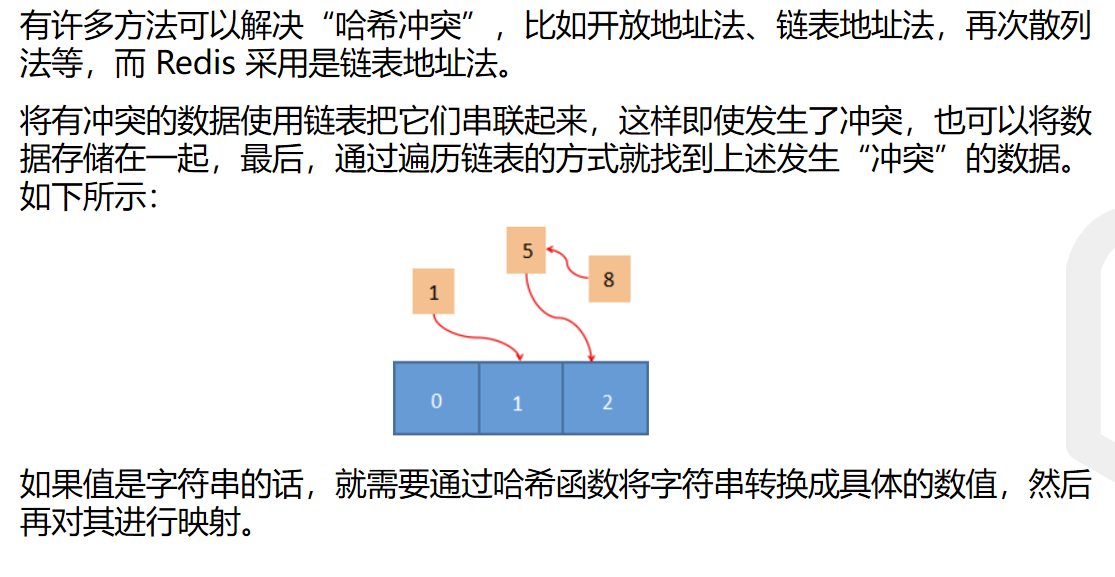
Hash操作
有点类似Map存对象的操作
{ 大key1:{key1:value1,key2:value2}, 大key2:{key3:value3,key4:value4}, }- 1
- 2
- 3
- 4
hash key key1 value1 key2 value2
图中的field是字段的意思

应用举例
如果想get某个数据的话
就需要get key key对应的字段名

hsetnx,允许后面的数据覆盖相同key的数据

针对key的操作

判断field下是否有数据(value)

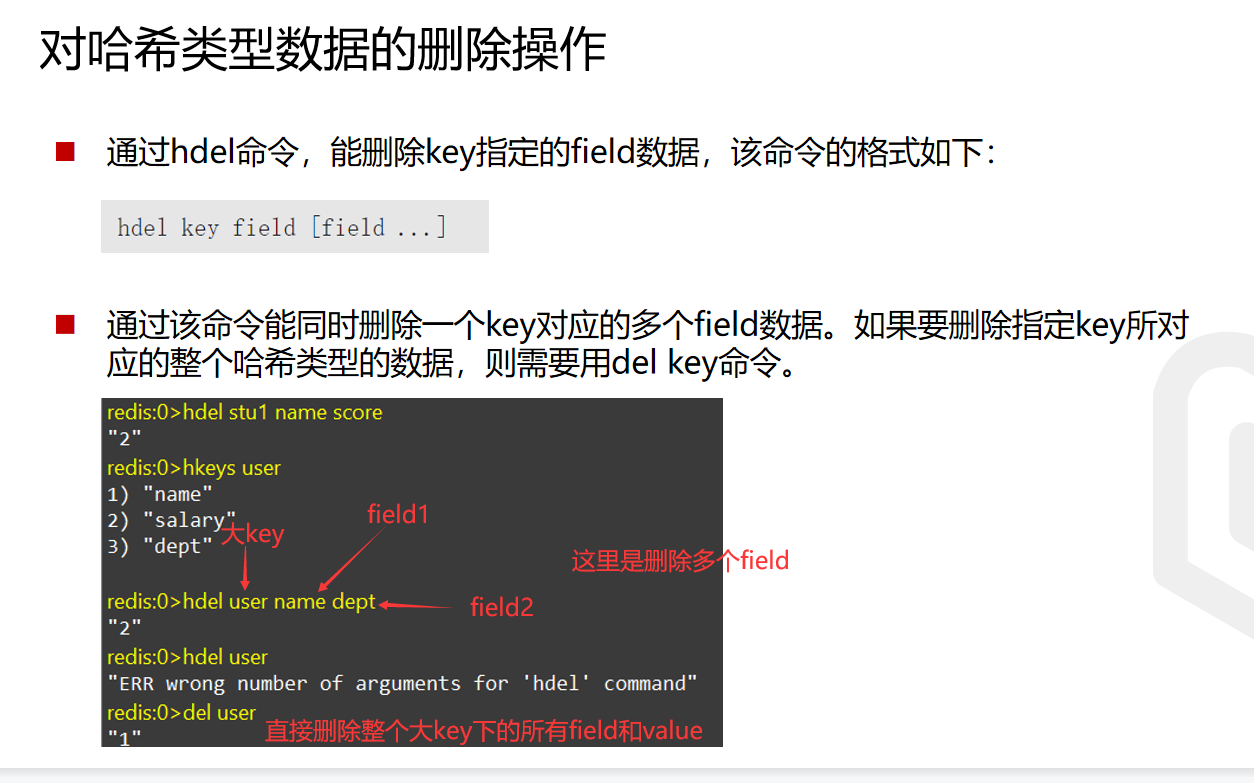
删除操作
删除分为删除大key、删除field以及field下的value
基础类型-List
基础内容
Redis list(列表)相当于 Java 语言中的 LinkedList 结构,是一个链表而非数组,其插入、删除元素的时间复杂度为 O(1),但是查询速度欠佳,时间复杂度为 O(n)。
当向列表中添加元素值时,首先需要给这个列表指定一个 key 键,然后使用相应的命令,从列表的左侧(头部)或者右侧(尾部)来添加元素,这些元素会以添加时的顺序排列。
当列表弹出最后一个元素时,该结构会被自动删除。实际上List结构在redis中对应的是
{
key1:链表1,
key2:链表2,
key3:链表3,
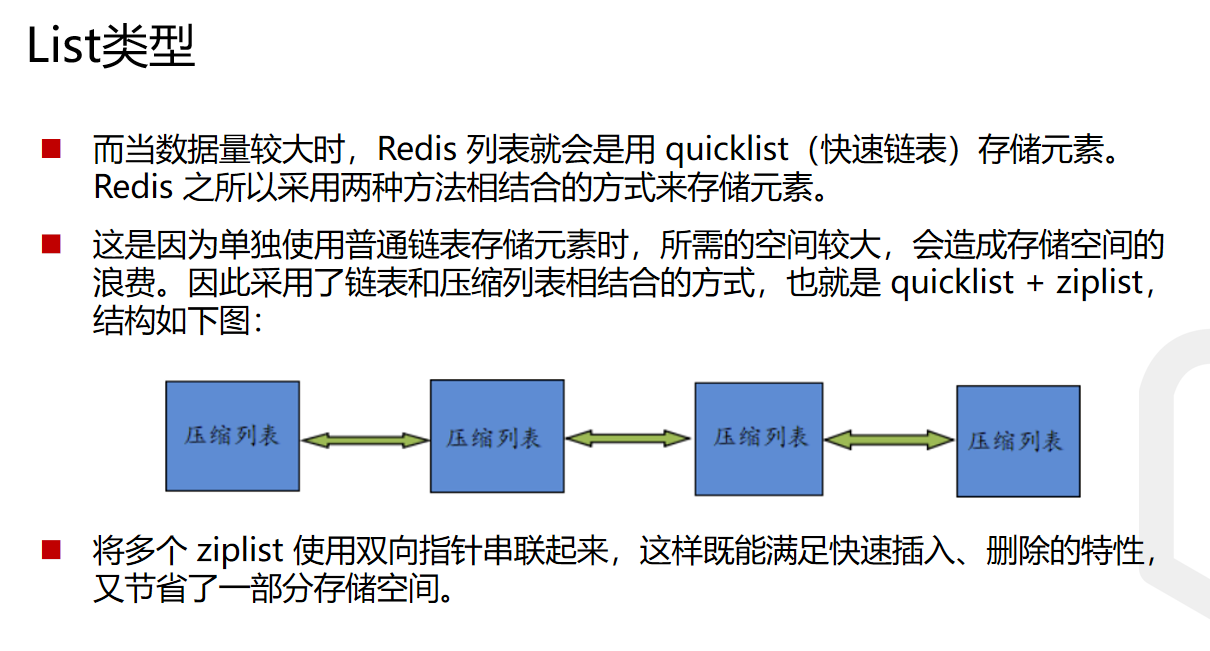
}List存储的底层逻辑(当存储元素较小且较少时采用压缩列表)

也就是说,数据量较少的时候,会采用压缩列表的形式对数据进行储存,因为连续的大块内存空间也是比较难找的而数据量比较大的时候,会采用就会改用快速链表(即链表+压缩列表的形式)最大化利用内存且保证了一定的性能
头部插入lpush
因为是链表嘛,所以可以从左边(链表头部)进行数据插入或者右边(链表尾部)进行数据插入
比如从左边(链表头部)插入就是lpush从右边(链表尾部)插入就是rpush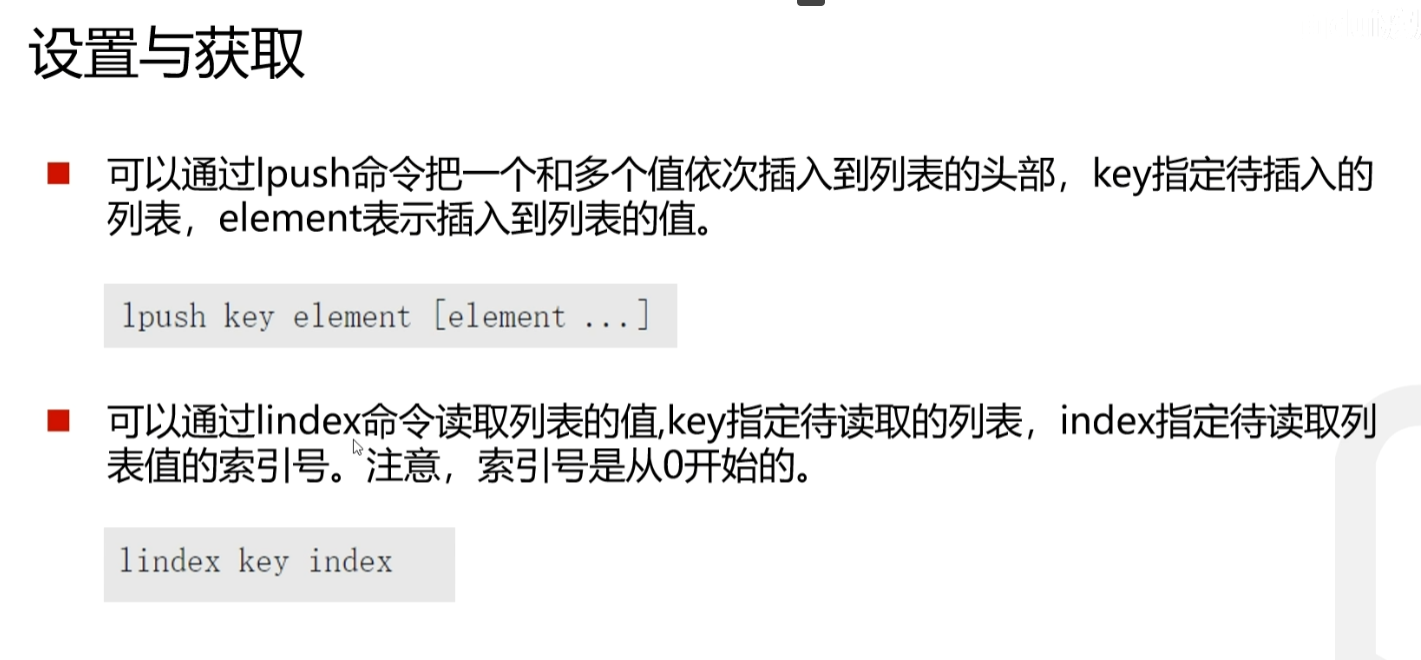
使用示例

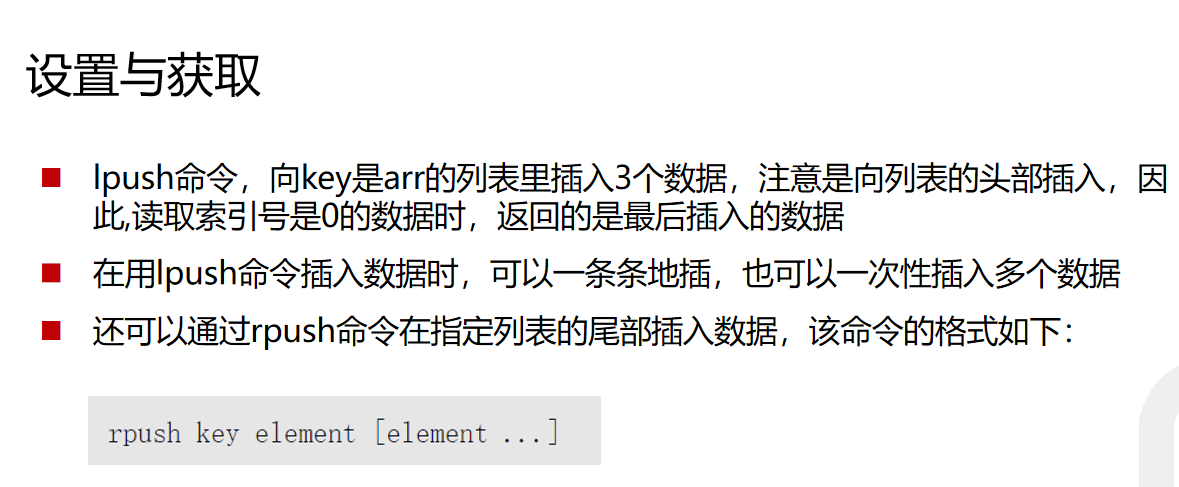
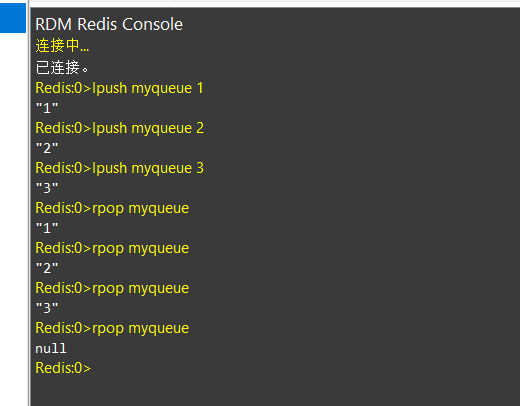
对应的能插入就可以弹出,从右侧就可以弹出来
lpop就可以把数据从最左侧弹出尾部插入rpush
对应的能插入就可以弹出,从右侧就可以弹出来
rpop就可以把数据从最右侧弹出利用不同的插入方式模拟栈
lpush和rpush的第一个字母分别是l和r,顾名思义,分别是向左边(list头)和右边(list尾)添加数据
与之对应的有lpop和rpop命令,表示分别从list头和list尾读数据,而且读完会把该数据从列表里弹出。
通过如下的lpush和lpop命令能模拟“先入后出”的堆栈效果。

利用不同的方法模拟队列
和上面的刚好相反,队列先进后出
获取区间数据
注意,只有lrange,没有rrange
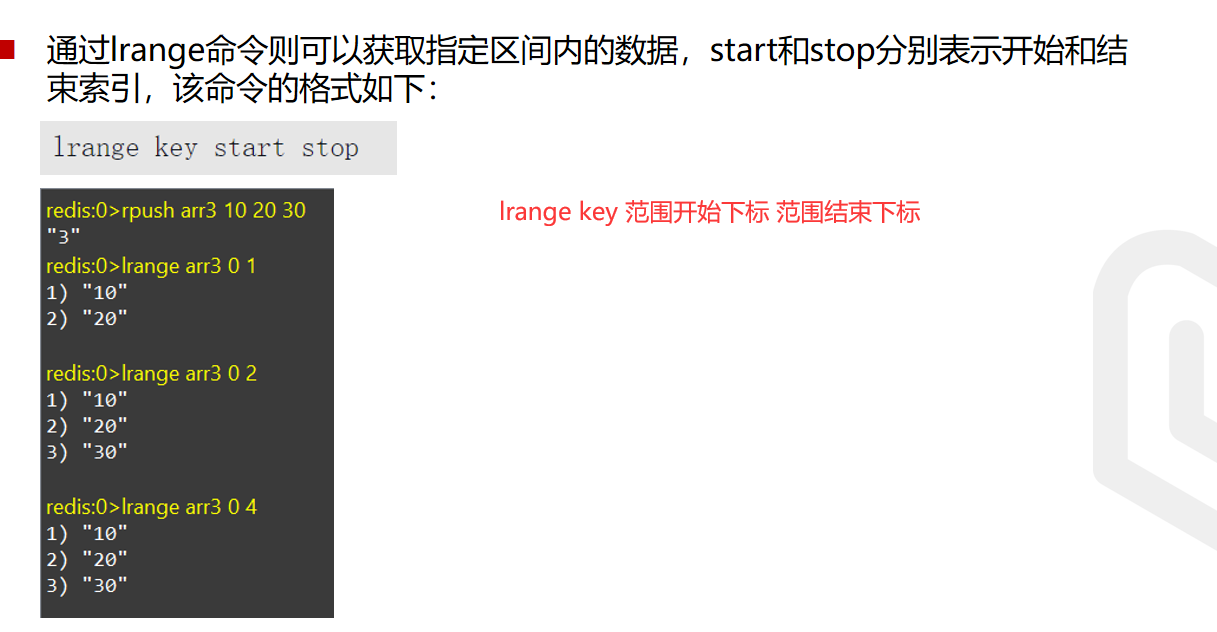
lrange是支持负数的,负数代表倒数的意思一个快捷地获取列表包含的所有元素的方法,就是使用0作为起始索引、-1作为结束索引去调用LRANGE命令,这种方法非常适合于查看长度较短的列表
列表中的最后一个元素索引为-1,依次类推根据下标修改元素(更新)

指定位置插入元素
LINSERT
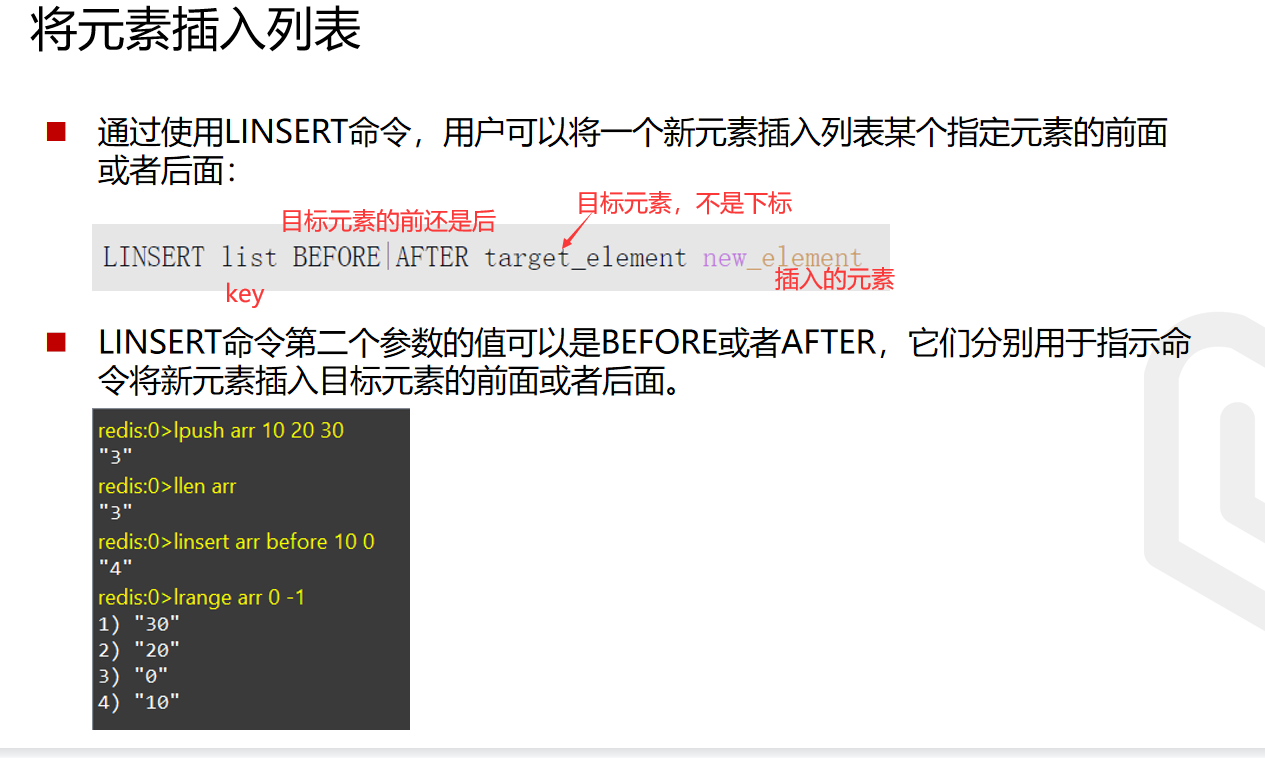
其他操作
获取长度

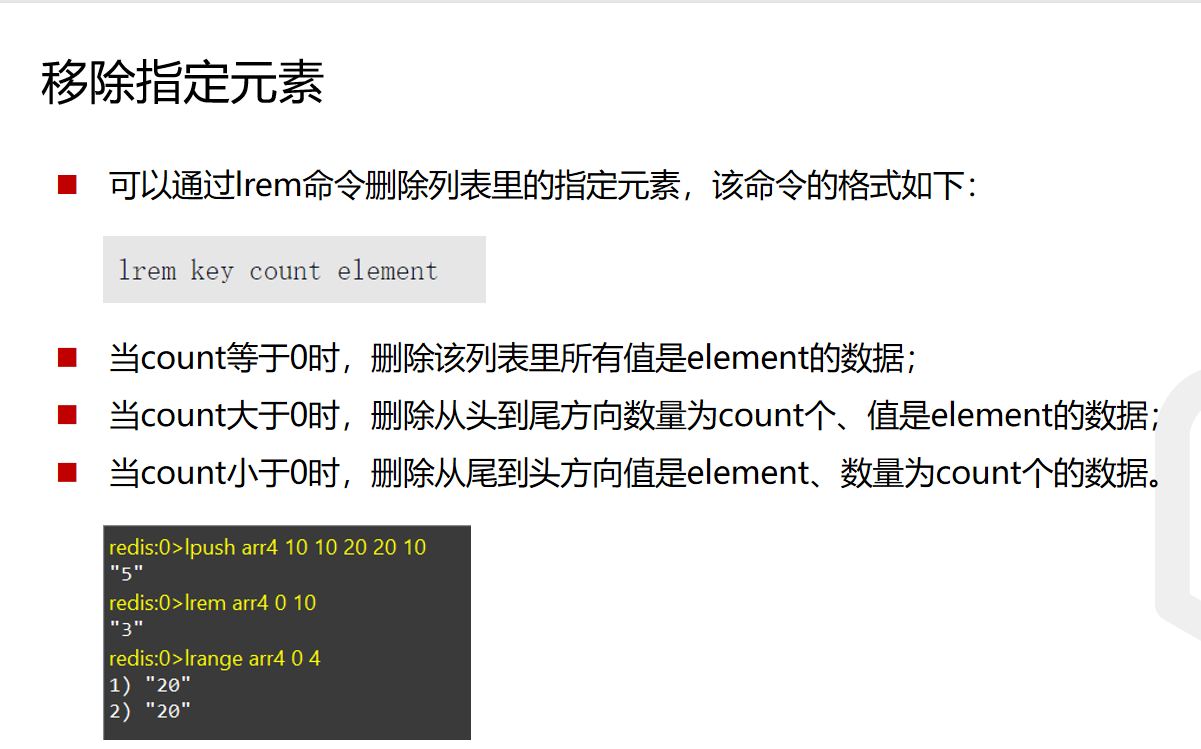
删除元素
修剪元素范围
只保留规定的部分,其余部分删除
比如指定0-3 就是四个元素,其余下标的部分全部删除

基础类型-Set
基础内容
自带去重属性,会自动忽略重复的元素

相比于List,Set在操作的复杂度上为O(1)

增删改查操作
添加操作
SADD key value1 value2 value3 .....

删除操作SREM 目标key value1,value2,value3
可以同时删除多个元素
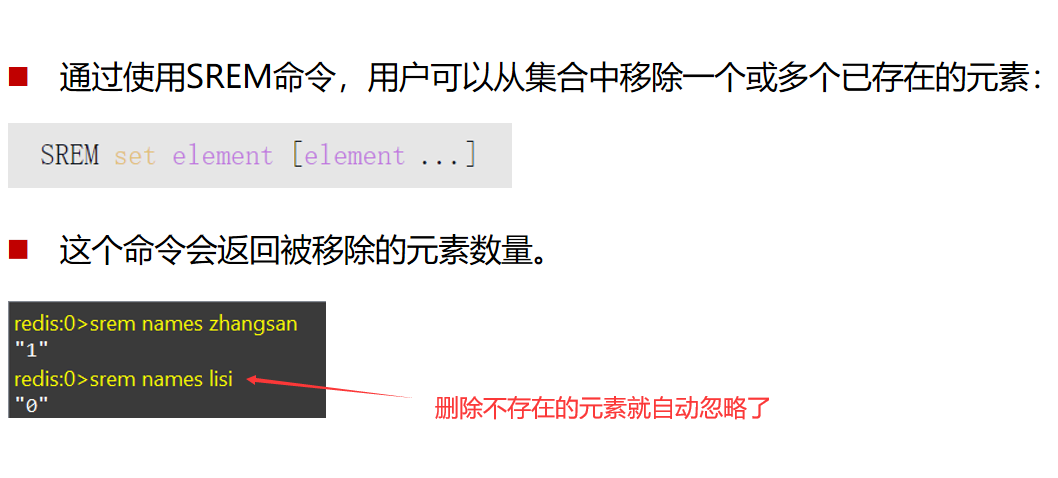
集合移动,相当于剪切操作SMOVE 源集合的key 目标集合的key 元素
如果目标集合已经有了这个元素,则会覆盖(好像废话)
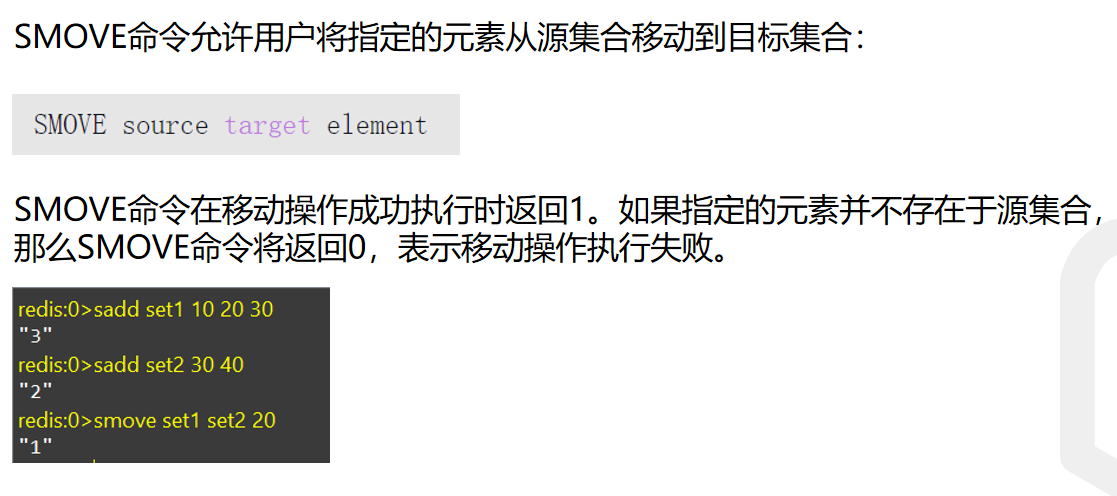
获取集合的所有元素SMEMBERS 集合key

获取集合的元素数量以及判断某些元素是否存在

随机操作
获取随机元素
从集合中随机的取出元素

随机获取元素
随机的从集合中删除某些元素

还有其他的一些对于集合做交集差集并集的操作,这里就不多演示了
基础类型-ZSet
基础内容
Redis的有序集合(sorted set)同时具有“有序”和“集合”两种性质
这种数据结构中的每个元素都由一个成员和一个与成员相关联的分值组成,其中成员以字符串方式存储,而分值则以64位双精度浮点数格式存储。
与集合一样,有序集合中的每个成员都是独一无二的,同一个有序集合中不会出现重复的成员。
有序集合的成员将按照它们各自的分值大小进行排序,而不是根据本身的值进行排序:比如,分值为3.14的成员将小于分值为10.24的成员,而分值为999的成员也会小于分值为10086的成员。
有序集合的分值除了可以是数字之外,还可以是字符串"+inf"或者"-inf",这两个特殊值分别用于表示无穷大和无穷小。虽然同一个有序集合不能存储相同的成员,但不同成员的分值却可以是相同的。当两个或多个成员拥有相同的分值时,Redis将按照这些成员在字典序中的大小对其进行排列:
举个例子,如果成员"apple"和成员"zero"都拥有相同的分值100,那么Redis将认为成员"apple"小于成员"zero",这是因为在字典序中,字母"a"开头的单词要小于字母"z"开头的单词。增删改查操作
添加对象ZADD key 分值1 对象1 分值2 对象2 …
移除指定成员 ZREM key 目标成员
操纵分值ZINCRBY 集合key 正值或者负值 目标元素

获取排名ZRANK key 元素

其他内容可以自行百度,用的不是很多
Redis其他常用命令
上面的内容都是关于value的相关内容以及操作,我们知道,Redis都是k-v的内容居多,光说value的内容还不够,现在要针对key进行内容梳理。
键操作命令
判断指定key是否存在,以及 keys的对应值匹配

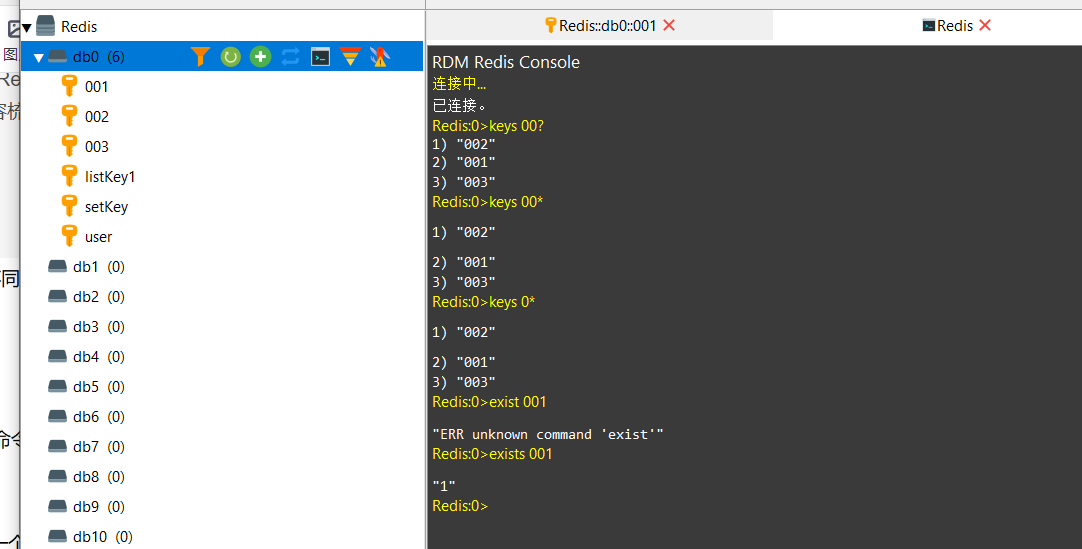
重命名key rename 旧key名 新key名

删除某个keydel key1 key2 .....

设置key的有效时间expire key 秒数
键的结构
Redis的key允许有多个单词形成层级结构,多个单词之间用’:'隔开,格式如下:
项目名:业务模块:ID
也可以根据自己的需求来删除或添加词条
Redis会自动以树形结构存储key
层级结构会自动变成文件夹,根据key进行分层分级
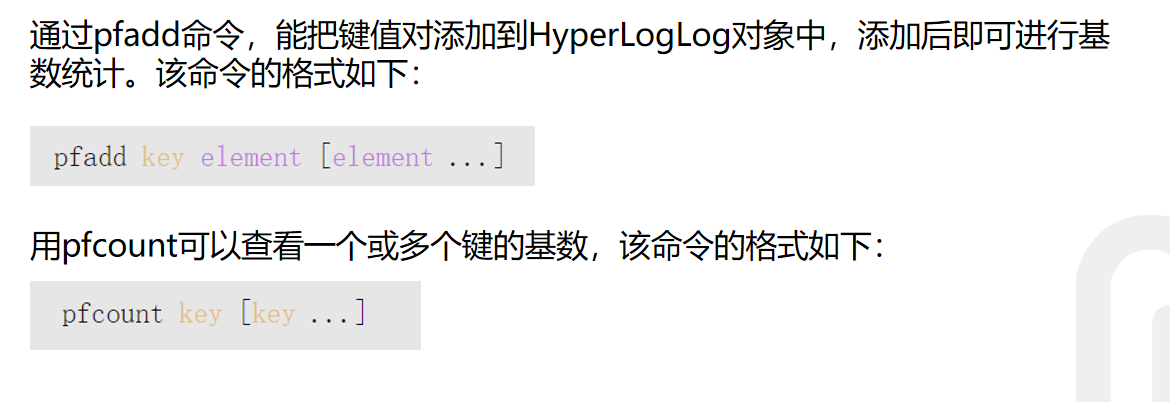
统计基数HyperLogLog

HyperLogLog主要用于对大量元素进行计数,并计算出这些元素的近似基数。
无论被计数的元素有多少个,HyperLogLog只使用固定大小的内存,其内存占用不会因为被计数元素增多而增多。
通过Redis的HyperLogLog对象能高效地统计基数。
在其他统计基数的场景里,元素的数量和内存的消耗量是成正比的,但在Redis里每个HyperLogLog对象大概只需要用12KB的内存就能计算2^64个元素的基数。HyperLogLog操作命令
添加操作
pfadd key 元素1,元素2,元素3.......
查询操作pfcount key1 key2 key3....

排序相关指令
数字类型排序
sort key asc/desc

字符型排序sort key alpha asc/desc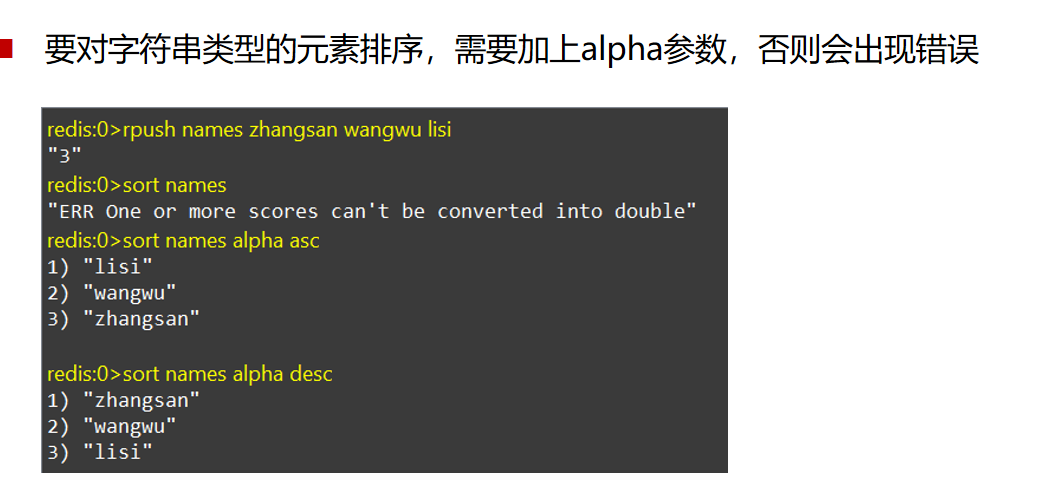


Redis数据库操作
切换库操作
前面我们说到,Redis默认开启会有16个库,并且默认是选中第0个数据库的
因为编号是从0~15号,当然,这是可以更改的。
一般来说,我们在分开使用多个Redis库时,会把例如订单库和商品库分开来存。来做到隔离。
那么如何切换数据库?select 数据库编号Redis事务操作
Redis的事务和传统的事务肯定有些差别
Redis的事务更像一个批处理,统一提交过之后才会返回结果在Redis里,有4个命令和事务有关:可以用multi命令开启Redis事务,用exec命令提交事务,用discard命令取消事务,用watch命令来监视指定的键值对,从而让事务有条件地执行。
中间的Queue是队列的意思
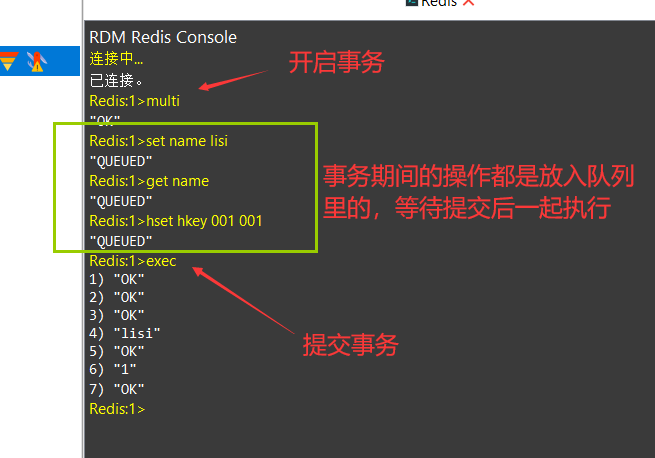
在exec之前可以通过discard来中断事务,进行撤销

Redis持久化

Redis持久化的方式有两种:
一种是Append Only File(AOF),另一种是Redis DataBase(RDB)。持久化之AOF
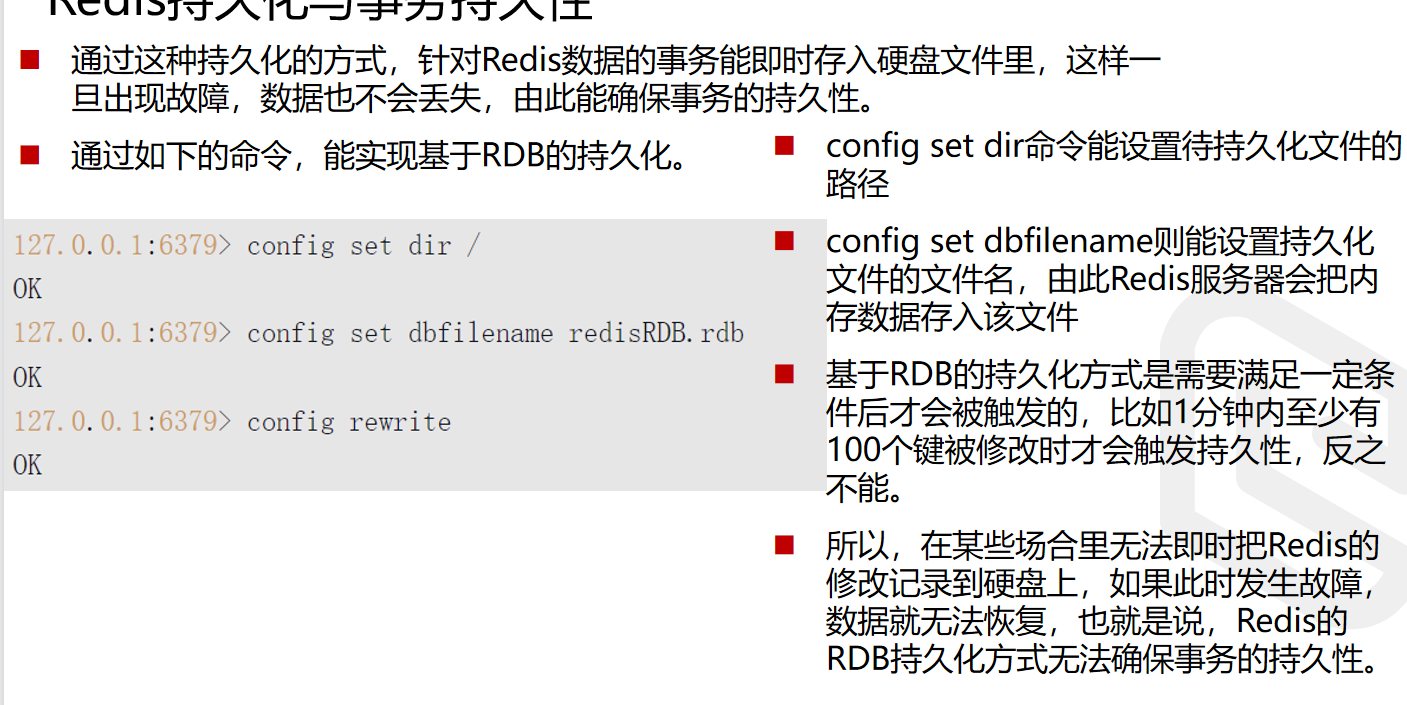
Redis的AOF持久化方式能确保事务的持久性,而RDB方式则不能。
通过如下的命令能让Redis服务器实现基于AOF的持久化。

config set命令能把Redis服务器配置文件里的appendfsync属性设置为always
config rewrite命令把这个修改提交到redis.conf文件里,以此实现基于AOF的持久化这种持久化的方式就是把操作指令即时的写入硬盘记录下来
优点就是持久化比较及时,比RDB达到某种条件才持久化更加及时,且只有AOF在Redis中才支持事务
但是缺点更明显,因为是全量的记录写入数据,占用的空间也就更大,并且相比于RDB的恢复数据效率也要略低持久化之RDB
RDB是默认的存储方式 在默认配置中,Redis将内存数据库快照保存在名字为dump.rdb的二进制文件中。
当然,具体怎么持久化,什么时候持久化都是由用户自行设定的
watch命令监视指定键(事务隔离)
如果两个或多个事务同时对某个键对应的值进行操作,就需要考虑因并发而导致的影响。
比如某个账户里有1000元,有两个事务同时对该账户进行读取值并加100元的操作。事务A和B读账户时,读到的值均是1000,但事务B在加100元前,事务A已经把账户值修改为1100,此时事务B就不应该继续把账户值加为1200,而应当终止。
在进行Redis事务相关操作时,可以通过watch命令来监控一个或多个键,如果被监控的键只被本事务修改,在其他场合没有修改,那么该事务能正确执行,反之被监控的键不仅被本事务修改,在本事务执行时还被其他客户端修改,本事务就不能正确执行。

此时,因为对bonus设置了watch的监控,所以,这个时候再提交是不生效的,因为事务的前和后bonus数据不一致了,自然事务也就操作失败了

但是毕竟不是专门干事务的,所以Redis主要还是要干缓存的活 -
相关阅读:
.net core 3.0 + angular 8.0 ----项目创建过程
内存取证系列4
《MySQL高级篇》五、InnoDB数据存储结构
实体链指(1)Entity Linking 综述
Elixir-Tuples
阿里云服务器ECS登录用户名是什么?系统不同默认账号也不同
在windows下vs c++运行g2o的BA优化程序示例
1195 巧妙推算走楼梯
java支持多任务之间的依赖协作关系
【论文翻译】增强复制状态机的两阶段提交协议
- 原文地址:https://blog.csdn.net/weixin_46906696/article/details/126512374