-
【Selenium】Selenium获取Network数据(高级版)
前言
为解决从Selenium中获取Network接口数据,潜心研究了一小会儿,遂有此文
基本看这篇文章的,多多少少都跟
spider沾亲带故。所以直接进入正题。- 只想要代码,文章前边自取
- 想看长篇大论,先看这篇 【Selenium】控制当前已经打开的 chrome浏览器窗口(高级版)
应用场景
Chrome浏览器 -> 开发者工具 -> Network 中所有的数据包,我要全部拿下来。
举个例子🌰
- 网站通过XHR异步加载数据,然后再渲染到网页上。而通过Selenium去获取渲染后的数据,是同HTML打交道的
- 异步加载返回数据是json文件的,有时渲染在网页上,不一定是完整的json文件中的数据;最重要的是,json文件解析起来很方便
通过selenium去拿网页数据,往往是两个途径:
- selenium.page_source,通过解析HTML
- 通过中间人进行数据截获,数据源是啥就是啥
这两种方法各有利弊,但是这篇文章就可以将他们相结合起来了,实在是妙啊!
可能你会有疑惑👀?直接使用
requests去请求不就完事了,请你想一下,我这都使用上selenium了,你觉得我还会去使用
requests再多请求一遍吗???完整代码
Selenium3获取Network
这里指定9527端口打开浏览器,也可以不指定,看上一篇文章
代码讲解在下面
# -*- coding: utf-8 -*- # @Time : 2022-08-27 11:59 # @Name : selenium_cdp.py import json from selenium import webdriver from selenium.common.exceptions import WebDriverException from selenium.webdriver.chrome.options import Options caps = { "browserName": "chrome", 'goog:loggingPrefs': {'performance': 'ALL'} # 开启日志性能监听 } options = Options() options.add_experimental_option("debuggerAddress", "127.0.0.1:9527") # 指定端口为9527 browser = webdriver.Chrome(desired_capabilities=caps, options=options) # 启动浏览器 browser.get('https://blog.csdn.net/weixin_45081575') # 访问该url def filter_type(_type: str): types = [ 'application/javascript', 'application/x-javascript', 'text/css', 'webp', 'image/png', 'image/gif', 'image/jpeg', 'image/x-icon', 'application/octet-stream' ] if _type not in types: return True return False performance_log = browser.get_log('performance') # 获取名称为 performance 的日志 for packet in performance_log: message = json.loads(packet.get('message')).get('message') # 获取message的数据 if message.get('method') != 'Network.responseReceived': # 如果method 不是 responseReceived 类型就不往下执行 continue packet_type = message.get('params').get('response').get('mimeType') # 获取该请求返回的type if not filter_type(_type=packet_type): # 过滤type continue requestId = message.get('params').get('requestId') # 唯一的请求标识符。相当于该请求的身份证 url = message.get('params').get('response').get('url') # 获取 该请求 url try: resp = browser.execute_cdp_cmd('Network.getResponseBody', {'requestId': requestId}) # selenium调用 cdp print(f'type: {packet_type} url: {url}') print(f'response: {resp}') print() except WebDriverException: # 忽略异常 pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
运行效果看下面动图,轻松拿到该网页请求中的所有数据包~

Selenium4获取Network
在Selenium 4中,
desired_capabilities已经被弃用,所以不能再在webdriver.Chrome()中使用它。需要将desired_capabilities转换为options。收到小伙伴的反馈,在
Selenim4中报错,现在来调整一下代码。
TypeError: WebDriver.init() got an unexpected keyword argument ‘desired_capabilities’- 其它代码与上面的一致,只需要修改开头的部分即可。
options = Options() caps = { "browserName": "chrome", 'goog:loggingPrefs': {'performance': 'ALL'} # 开启日志性能监听 } # 将caps添加到options中 for key, value in caps.items(): options.set_capability(key, value) # 启动浏览器 browser = webdriver.Chrome(options=options) browser.get('https://blog.csdn.net/weixin_45081575') # 访问该url- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
知识点📖📖
Chrome DevTools Protocol允许使用工具来检测、检查、调试和分析 Chromium、Chrome 和其他基于 Blink 的浏览器。Chrome DevTools Protocol,简称CDP看以下 Chrome DevTools Protocol官方文档 ,感兴趣的可以深入去学习了解。这个将另起一篇文章来讲。

再看 Selenium官方文档,所以是可以通过CDP协议去操作Selenium打开的Chrome浏览器的。

代码解析
在上一篇文章 【Selenium】控制当前已经打开的 chrome浏览器窗口(高级版) 中,介绍了链接Chrome浏览器,这里进一步介绍。
以调试模式启动Selenium,打上断点,跟一下源码。来到下面这里,因为咱们指定了端口为
9527,否则这个port将是随机的,至于为什么,看源码site-packages\selenium\webdriver\common\utils.py

回到上面的代码中,
'goog:loggingPrefs': {'performance': 'ALL'},这段代码是开启浏览器的性能日志记录
caps = { "browserName": "chrome", 'goog:loggingPrefs': {'performance': 'ALL'} # 开启性能日志记录 }- 1
- 2
- 3
- 4
简单理解为 开发者工具中的
performance,看下图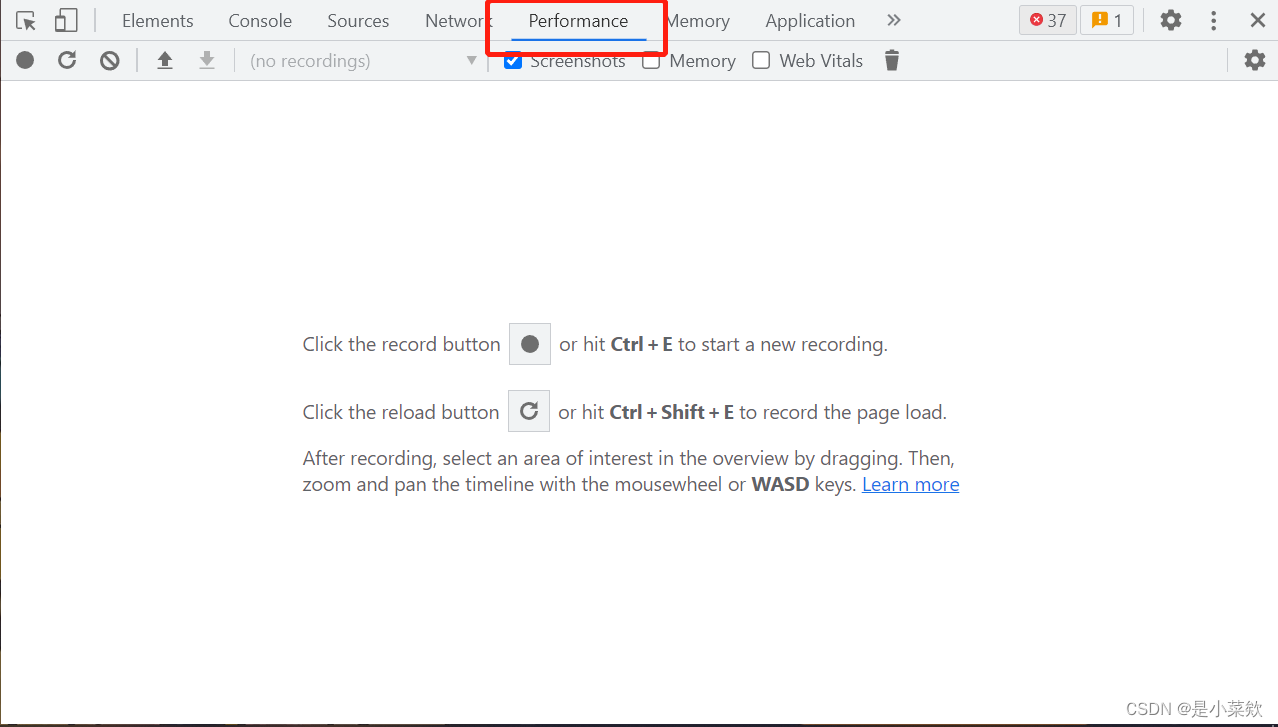
以下代码返回的是一个列表,装着该网页请求中所有的数据包
performance_log = browser.get_log('performance')- 1
看下图
- 因为我们要获取的是 Network中的返回值,所以只取
method =Network.responseReceived

知识补充
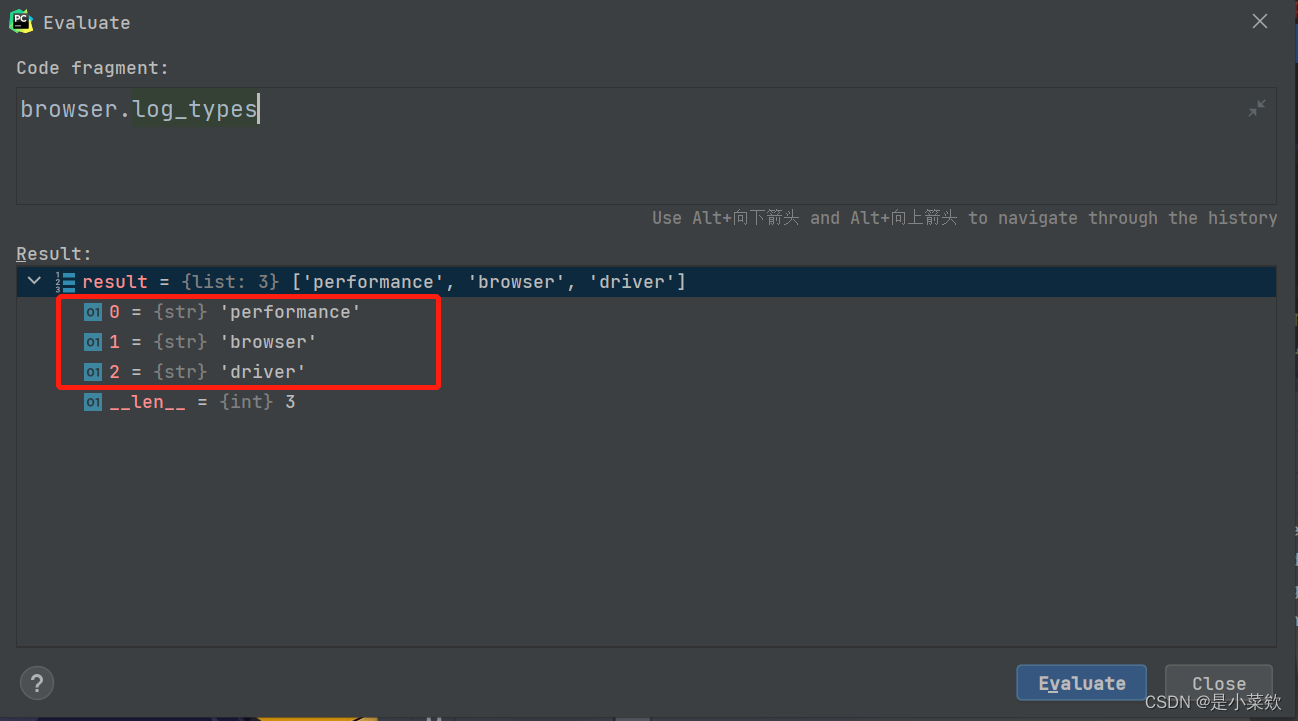
使用
browser.log_types可以查看当前的可用日志类型的列表,
下面两幅图分别是开启性能日志记录 和 不开启性能日志记录 的可用日志类型返回值~
再接下来就是过滤请求包,一般来说,像图片、css&js文件等,往往是不需要的,所以可以对它们过滤~(这一步可以根据自己的需求来过滤)
def filter_type(_type: str): types = [ 'application/javascript', 'application/x-javascript', 'text/css', 'webp', 'image/png', 'image/gif', 'image/jpeg', 'image/x-icon', 'application/octet-stream' ] if _type not in types: return True return False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
最后是获取数据包的
requestId,这个是调用 cdp 的关键,它就好比每个网络数据包的身份证。
在Selenium中调用cdp时候,需要传入requestId,浏览器会验证是否存在该requestId,- 如果存在,则响应并返回数据;
- 如果不存在,则会抛出
WebDriverException异常。
在这里的代码中,我对这个异常进行了忽略的处理~
try: resp = browser.execute_cdp_cmd('Network.getResponseBody', {'requestId': '123123123'}) # selenium调用 cdp print(f'type: {packet_type} url: {url}') print(f'response: {resp}') print() except WebDriverException: # 忽略异常 pass- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意事项🏹🏹
至于原因,网上找了找,大概如下:
- 页面加载过程中的限制:有些网络请求可能在页面加载过程中发生,而在获取 CDP 日志之前已经完成。您可以尝试在页面加载完成后等待一段时间,然后再获取 CDP 日志,以确保捕获到所有的网络数据包;
- 动态加载的内容:如果页面上的某些内容是通过 JavaScript 动态加载的,那么这些请求可能不会立即出现在 CDP 日志中。您可以尝试等待一段时间,直到页面上的所有动态内容加载完成,然后再获取 CDP 日志;
- 丢失的请求:由于网络请求是异步的,CDP 可能在某些情况下无法捕获到请求的详细信息。这可能是由于请求在 CDP 启动之前或之后发送,或者由于请求速度过快而导致 CDP 无法及时处理;
- 资源策略和跨域限制:某些网络请求可能会被浏览器的安全策略或防火墙阻止,导致无法在 CDP 日志中捕获到这些请求。这些策略可能导致某些请求无法通过 CDP 访问;
- CDP主要关注HTTP和HTTPS请求,其它协议的可能无法捕获;
- 浏览器或驱动程序版本差异,某些版本可能会限制或更改网络数据的记录方式
数据不全
使用 Chrome DevTools Protocol (CDP) 不一定能够抓取到全部的网络数据包,因为它并不是一个专门用于抓取和分析网络数据的工具。
当发现获取数据包不全时候,可以尝试等待直到页面上所有的动态内容加载完成后,再去获取CDP日志
当发现获取数据包不全时候,可以尝试等待直到页面上所有的动态内容加载完成后,再去获取CDP日志
当发现获取数据包不全时候,可以尝试等待直到页面上所有的动态内容加载完成后,再去获取CDP日志
最简单的,就是加一个等待
time.sleep(10)- 1
后话
简单来说,本文章所能实现的,还算是有用的😎😎
远的不说,起码本文章就帮助我解决了mitmproxy + Selenium 的组合拳(现在只用Selenium就可以完成了~
See you. -
相关阅读:
CEC2023:基于自适应启动策略的混合交叉动态约束多目标优化算法(MC-DCMOEA)求解CEC2023(提供MATLAB代码及参考文献)
『手撕Vue-CLI』编码规范检查
C++11多线程第三篇:线程传参详解,detach()大坑,成员函数做线程参数
基础课8——中文分词
深度学习(四)——torchvision中数据集的使用
JVM常见参数总结
Android11系统桌面隐藏指定APP图标
线程安全问题
CSS代码收集(持续更新)
ElementUI之动态树+数据表格+分页
- 原文地址:https://blog.csdn.net/weixin_45081575/article/details/126551260