-
Mobile-Former: Bridging MobileNet and Transformer详解
1.解决问题
实现transformer全局特征与CNN局部特征的融合,在较低的成本内,创造一个高效的网络
2.创新点
论文中提出了Mobile-Former,一个并行设计的MobileNet和transformer之间的双向桥。这种结构利用了MobileNet在本地处理中的优势和在全局交互中的优势。该桥可以使局部和全局特征能够双向融合。与最近关于vision transformer的研究不同,Mobile-Former中的transformer包含很少的标记(例如6个或更少的标记),这些标记被随机初始化以学习全局先验,导致较低的计算成本。结合提出的轻量级交叉注意桥模型,Mobile-Former不仅具有计算效率,而且具有更强的表示能力。
3.Mobile-Former
Parallel structure
Mobile-Former并行化MobileNet和transformer,并通过双向交叉注意将它们连接起来(见图1)。MobileNet以一个图像作为输入(
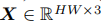 ),并应用反向瓶颈块[28]来提取局部特征。前者(指transformer)以可学习参数(或tokens)作为输入,记为
),并应用反向瓶颈块[28]来提取局部特征。前者(指transformer)以可学习参数(或tokens)作为输入,记为 ,其中M和d分别为tokens的数量和维数。这些tokens是随机初始化的。与视觉转换器(ViT)[10]不同,其中标记线性投影局部图像patch,前者的标记明显更少(本文中的M≤6),每个标记都代表图像的全局先验。这就导致了更少的计算成本。
,其中M和d分别为tokens的数量和维数。这些tokens是随机初始化的。与视觉转换器(ViT)[10]不同,其中标记线性投影局部图像patch,前者的标记明显更少(本文中的M≤6),每个标记都代表图像的全局先验。这就导致了更少的计算成本。 Mobile and Former通过一个双向桥进行通信,其中本地和全球功能是双向融合的。这两个方向分别表示为Mobile and Former和Mobile←Former。我们提出了一个轻量级的交叉注意来建模它们,其中投影
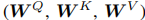 从Mobile移除以节省计算,但保留在前一侧。交叉关注是在通道数量较低的移动瓶颈处计算的。具体来说,从局部特征映射X到全局标记Z的轻量级交叉注意力计算为:
从Mobile移除以节省计算,但保留在前一侧。交叉关注是在通道数量较低的移动瓶颈处计算的。具体来说,从局部特征映射X到全局标记Z的轻量级交叉注意力计算为: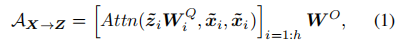
其中,局部特征X和全局标记Z被分成h头,如
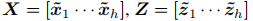 ,用于多头注意。第i个头
,用于多头注意。第i个头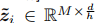 的分裂与第i个标记
的分裂与第i个标记 不同。
不同。 是第i个头的查询投影矩阵。
是第i个头的查询投影矩阵。 用于将多个头组合在一起。Attn(Q,K,V)是查询Q、键K和值V的标准注意函数,为
用于将多个头组合在一起。Attn(Q,K,V)是查询Q、键K和值V的标准注意函数,为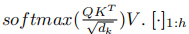 表示h元素的连接。请注意,键和值的投影矩阵从Mobile端删除,而查询的项目矩阵保留在前侧。同样,从全局到局部的交叉注意力计算为:
表示h元素的连接。请注意,键和值的投影矩阵从Mobile端删除,而查询的项目矩阵保留在前侧。同样,从全局到局部的交叉注意力计算为: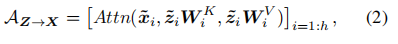
其中,
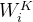 和
和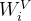 是前一个边的键和值的投影矩阵。从Mobile端删除查询的投影矩阵。
是前一个边的键和值的投影矩阵。从Mobile端删除查询的投影矩阵。 4. Mobile-Former Block
Mobile-Former 块由堆叠的Mobile-Former blocks组成(见图1)。每个块有四个支柱:a Mobile sub-block, a Former sub-block, and two-way cross attention Mobile←Former and Mobile→Former
Input and output: Mobile-Former block有两个输入:(a)局部特征图
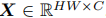 ,它在高度H和宽度W上有C通道,和(b)全局令牌Z∈
,它在高度H和宽度W上有C通道,和(b)全局令牌Z∈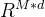 ,其中M和d分别是tokens的数量和维度。请注意,M和d在所有块中都是相同的。Mobile-Former block 一个块输出更新后的局部特征图X‘和全局令牌Z’,它们被用作下一个块的输入。
,其中M和d分别是tokens的数量和维度。请注意,M和d在所有块中都是相同的。Mobile-Former block 一个块输出更新后的局部特征图X‘和全局令牌Z’,它们被用作下一个块的输入。Mobile sub-block: 如图3所示,Mobile sub-block以特征图X为输入,并将其输出作为Mobile←Former的输入。它与[28]中的倒置瓶颈块略有不同,用动态ReLU[5]替换ReLU[5]作为激活函数。与原始的dynamic ReLU不同,其中参数是通过对平均池特征应用两个MLP层生成的,我们通过对前者的第一个全局标记输出z1‘应用两个MLP层(图3中的θ)来保存平均池。注意,对于所有块,深度卷积的核大小是3×3。
Former sub-block:Former sub-block是一个标准的transformer块,包括多点注意(MHA)和前馈网络(FFN)。在FFN中使用了膨胀比2(而不是4)。我们遵循[38]来使用后层的标准化。前者由Mobile→Former和Mobile←Former进行处理(见图3)。
Mobile→Former:利用提出的轻量级交叉注意(方程1)将局部特征X融合到全局令牌z中。与标准注意相比,去掉了关键
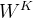 和值
和值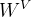 (在局部特征X上)的投影矩阵,以节省计算(见图3)。
(在局部特征X上)的投影矩阵,以节省计算(见图3)。Mobile←Former: 交叉注意(方程2)与Mobile→Former:相反,将全局tokens(作为键和值)融合到局部特征(作为查询)。我们保留了关键WK和值WV的投影矩阵,但删除了查询
 的投影矩阵以保存计算,如图3所示
的投影矩阵以保存计算,如图3所示计算复杂度:
给定一个大小为HW×C的输入特征映射和M个具有d维的全局标记,Mobile消耗最多的计算O(HWC^2)。其余部分消耗不到总计算成本的20%。具体来说,Former的自我注意和FFN的复杂度为O(
 )。Mobile→Former和Mobile←Former共享复杂性O(MHW C+M dC)的交叉关注。
)。Mobile→Former和Mobile←Former共享复杂性O(MHW C+M dC)的交叉关注。
5.网络架构
下表显示了一个具有224×224的Mobile-Former架构,它在不同的输入分辨率下堆叠了11个Mobile-Former。所有的块都有6个维度为192的全局tokens。它以3×3卷积开始,以及接下来的bottleneck block[19],它通过分层叠加3×3和点态卷积来扩展和压缩通道的数量。阶段2-5包括Mobile-Former blocks。每个阶段处理降采样,称为Mobile-Former↓的下采样变体(详见补充材料)。分类头对局部特征应用平均池,与第一个全局标记连接,然后通过两个中间具有h-swish[16]的完全连接层

6.Efficient End-to-End Object Detection
Backbone–Head architecture
我们在主干和头部中都使用mobile-前体块(见图4),它们有单独的令牌。主干有6个全局令牌,而头部有100个类似于DETR[1]生成的对象查询。与DETR
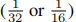 不同,Mobile-Former头部由于其计算效率,在低流量中采用多尺度
不同,Mobile-Former头部由于其计算效率,在低流量中采用多尺度 。上采样是通过双线性插值来实现的,然后添加来自主干的特征输出(具有相同的分辨率 所有对象查询都从粗到细逐步细化其表示,在FPN[20]中保存手动过程,以按大小分配对象。网络遵循DETR,在训练期间使用预测ffn和头部的辅助损失。头部从头开始训练,骨干在ImageNet上进行预先训练。
。上采样是通过双线性插值来实现的,然后添加来自主干的特征输出(具有相同的分辨率 所有对象查询都从粗到细逐步细化其表示,在FPN[20]中保存手动过程,以按大小分配对象。网络遵循DETR,在训练期间使用预测ffn和头部的辅助损失。头部从头开始训练,骨干在ImageNet上进行预先训练。
Spatial-aware dynamic ReLU in backbone
我们通过涉及所有全局标记来生成参数,从空间共享扩展到空间感知,而不是仅仅使用第一个标记,因为这些标记有不同的空间焦点。让我们将空间共享动态ReLU的参数生成表示为θ=f(z1),其中z1是第一个全局标记,f(·)由两个MLP层建模,中间是ReLU。相比之下,空间感知dynamic ReLU通过使用所有全局标记生成每个空间位置i生成参数θi,{zj}如下:

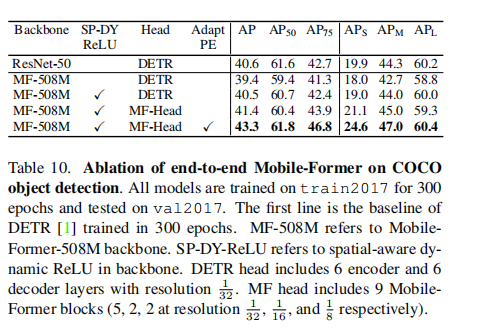
其中,αi,j为位置i处的特征与标记zj之间的注意点。通过对Mobile→Former中获得的交叉注意力进行归一化,它的计算是廉价的。Spatial-aware dynamicReLU在图像分类上与空间共享对应的图像分类相同,但在COCO目标检测上获得了1.1AP(见表10)。
Adapting position embedding in head与DETR[1]不同,我们在所有解码器层中共享对象查询的位置embeding,随着每个块的特征映射的变化,我们细化了头部中每个块之后的位置嵌入。让我们将一个查询在第k个块上的特征和位置emdeding分别表示为
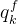 和
和 。它们的和(+)用于计算对象查询和特征映射之间的交叉注意以及对象查询之间的自注意,然后将特征embeding更新为下一个块
。它们的和(+)用于计算对象查询和特征映射之间的交叉注意以及对象查询之间的自注意,然后将特征embeding更新为下一个块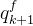 的输入。在这里,我们基于特征embeding将位置embeding调整为:
的输入。在这里,我们基于特征embeding将位置embeding调整为: 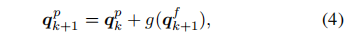
其中,自适应函数g(·)由两个MLP层实现,中间有ReLU。因此,对象查询可以根据内容跨块调整它们的位置。
7.实验
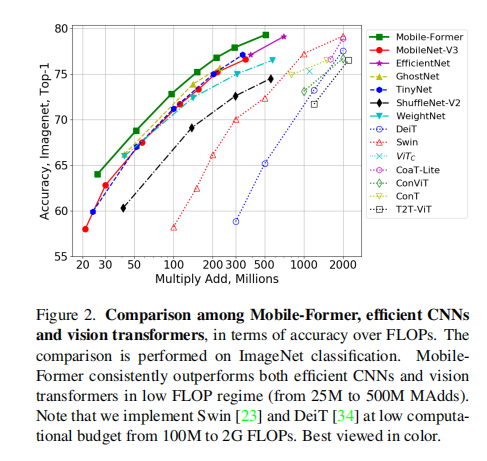
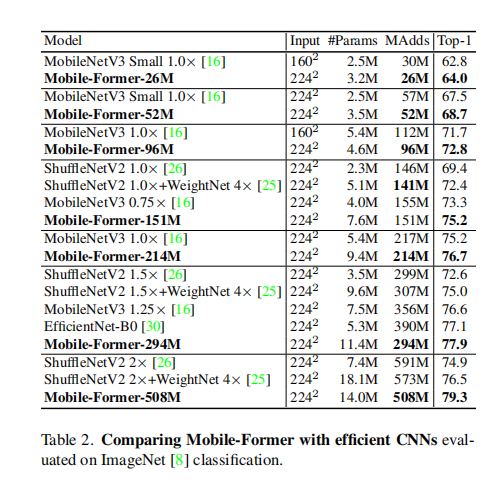
图像分类:
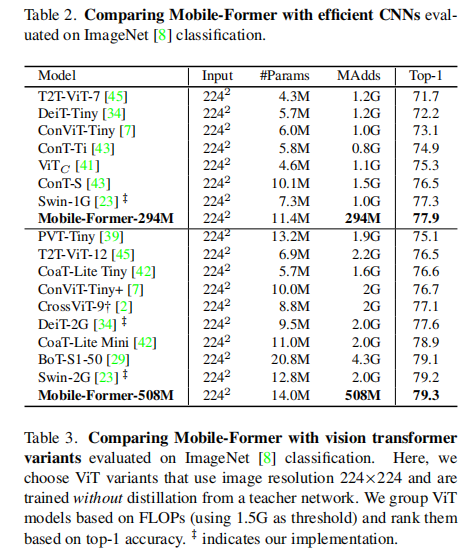
目标检测:
消融实验:
Mobile-Former is effective:Mobile-Former比Mobilenet更有效,因为它通过前者对全球交互进行编码,从而产生更准确的预测。同时,增加Mobilenet的深度卷积的内核大小(3×3→5×5)只会引入可忽略的增益,因为移动的接收领域通过融合前者的全局特征而扩大。

Mobile-Former不仅在编码本地处理和全局交互方面都很有效,而且还有效地实现了这一目标。下面的消融显示,前者只需要几个低维的全局tokens。此外,在去除前者的FFN或用位置混合MLP[33]替换多头注意时,移动原的高效并行设计是稳定的。
Number of tokens in Former
即使是一个全局tokens也能获得良好的性能(77.1%的前1精度)。当使用3和6标记时,还实现了额外的改进(0.5%和0.7%的top-1精度)。当使用了超过6个tokens时,改进就会停止。全球tokens的这种紧凑性是提高Mobile-Former效率的一个关键因素。

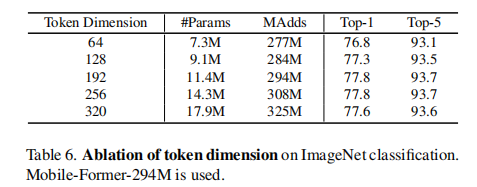
Token dimension
在former中使用了6个全局tokens。当tokens维数从64增加到192时,准确率从76.8%提高到77.8%,但在使用更高维数时收敛。这进一步支持了前者的效率。有6个维度为192的标记,former和该桥的总计算成本只消耗了总预算的12%(35M/294M)。
FFN in Former:
去除FFN会导致top-1的精度略有下降(−0.3%)。与FFN在原始VIT中的重要作用相比,FFN在Mobile-Former中的贡献有限。论文认为这是因为FFN并不是Mobile-Former中唯一的用来进行通道融合的模块。Mobile特征中的1×1卷积有助于局部特征的信道融合,而Mobile-Former中的投影矩阵
 有助于局部特征和全局特征的融合。
有助于局部特征和全局特征的融合。 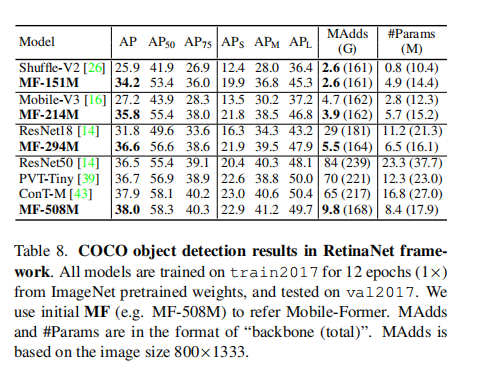
Multi-head attention (MHA) vs. position-mixing MLP
表7显示了在Former 和brige(Mobile→Former and Mobile←Former)中,用tokens/位置混合MLP[33]替换多头注意(MHA)的结果。top-1名的准确率从77.8%下降到77.3%。MLP通过单个矩阵乘法具有更有效的实现,但不适应不同的输入图像。
Object dection
Ablations of key components
缺陷:
参数利用率低
-
相关阅读:
基于ssm的医药进出口交易系统设计与实现-计算机毕业设计源码+LW文档
没人带宝宝,所以才要送去托育园?
java通过拦截器实现项目每次执行sql耗时统计,可配置是否打印
【Linux】基本指令(四)
HOOK Native API
PAT 乙级 1101 B是A的多少倍
为什么Java中你写的swap()函数无法实现两数交换?你真的深入了解Java中的栈和堆了吗?
聊聊asp.net core 授权流程
Vuex数据持久化存储
cnn感受野计算方法
- 原文地址:https://blog.csdn.net/qq_52053775/article/details/126545319