-
【密码学】DES 介绍
一、DES 简介
DES:Data Encryption Standard(数据加密标准)
DES 是一种 对称密钥 的 块加密 算法。
谓之 “对称密钥”,是因为加密、解密用的密钥是一样的。
谓之 “块加密”,是因为这种算法把明文划分为很多个等长的块(block),对每个块进行加密,最后以某种手段拼在一起。“块加密” 亦称 “分组加密”。DES 的功能是:给定一个 64 位的明文和一个 64 位的密钥,输出一个 64 位的密文。这个密文可以用相同的密钥解密。所谓“64位的密钥”,其实里面只有54位在起作用。剩余的位可以直接丢弃,或者当作奇偶校验位。
虽然 DES 一次只能加密 8 个字节,但我们只需要把明文划分成每 8 个字节一组的块,就可以实现任意长度明文的加密。如果明文长度不是 8 个字节的倍数,还得进行填充。现在流行的填充方式是 PKCS7 / PKCS5,都是很简单的思路,用于把任意长度的文本填充成 8 字节的倍数长,也能方便地恢复原文,这里不再赘述。此外,独立地对每个块加密,最后直接拼起来是不行的(这种方式称为“电子密码本”,ECB 模式。它会导致明文中重复的块,加密结果也重复,这对于图片之类的数据来说几乎是致命的)。这个问题我们将在以后的博文中探讨。
DES 有一个非常不平凡的性质——加密与解密算法几乎一模一样。这大大简化了软件和硬件的设计。写完了加密算法,给它加上一行(倒转子密钥的顺序),就是一个解密算法了。这将给我们的编程带来帮助。
二、DES 算法入口参数
DES 算法的入口参数有三个:Key、Data、Mode。
其中,Key 为 7 个字节共 56 位,是 DES 算法的工作 密钥;
Data 为 8 个字节 64 位,是要被加密或被解密的 数据;
Mode 为 DES 的 工作方式,有两种:加密或解密。
三、DES 算法框架
DES 算法是在 Feistel network (费斯妥网络)的基础上执行的。以下是 DES 算法的流程图:
其中涉及的一些英语单词:permutation(置换)、cipher(密码)、rotation(旋转,转动,轮流,交替)

可以看到整个算法分为两大部分——迭代加密(左边的 16 轮迭代操作),以及 子密钥生成(右边生成子密钥的算法)。
1. 子密钥生成
所谓“子密钥生成”,就是从一把 64-bit 的主钥匙,得到 16 把 48-bit 的子钥匙,然后把这些子钥匙用于迭代加密。那么,如何从一把主钥匙得到 16 把子钥匙呢?
- 从 64-bit 的主钥匙里面选取特定的 56 位,其余的位就没用了。于是我们现在手上有了一个 56 位的布尔数组。把它分成左、右两个半密钥,它们都是 28-bit 的布尔数组。
- 左、右两个半密钥都左旋(也就是 循环左移 。整个数组往左移,左边弹出去了的东西补到最右边去)一定位数,这个左移的位数也是指定的。有些轮次是 1 位,有些轮次是 2 位。
- 把左、右半密钥拼起来,再做一个 置换 ,就得到了这一轮生成的子密钥。这个置换是从 56-bit 的数组里面选取指定的 48 位。所以现在每一轮都可以生成一个 48 位的子密钥。(注意,步骤 3 并不改变左右半密钥)。
- 重复 步骤 2、步骤 3 一共 16 次,于是得到了 16 个 48-bit 的子密钥。
2. 迭代加密
现在我们手上有了 16 把子密钥。遂开始加密:
-
输入的明文(长度为 64 的布尔数组)做一个置换(IP置换)。仍然得到 64-bit 的数组(不然就丢失信息了!)
-
把得到的数组拆成左、右两半边。每边是 32 位长度。
-
每一轮迭代,都是接收一组
L, R,返回L', R',作为下一轮迭代的L, R。迭代过程如下:L' = R R' = L ⊕ F(R,subkey)- 1
- 2
其中 F 函数(称为轮函数)是整个算法的核心,功能是:以一个子密钥,加密 32-bit 的信息。
-
利用之前得到的 16 个子密钥,执行步骤 3 一共 16 次。
-
将最终的 R 与 L 拼接,再做一次置换(FP置换),这是IP的逆置换,即得到密文。注意到 FP 就是 IP 的逆函数。这是为了保证“加密、解密算法几乎完全相同”。

加密迭代的过程:先把信息进行一次初始置换(IP置换);再进行 16 轮迭代;最后再给 (R+L) 这个数组来一次最终置换(FP置换),即可输出作为密文。
以上就是整个 DES 算法的加密过程。而解密过程与加密过程几乎一致,唯一的不同之处是:解密过程中子密钥的使用顺序,是与加密过程使用子密钥的顺序相反的。
好了,DES的整个过程我们都知道了,其中唯一还不知道的是轮函数F的细节,接下来讲。
3. 轮函数 F
IP 和 FP 都是简单置换,对于密码安全没有任何意义,这是一个历史遗留原因。
DES 的安全性在很大程度上取决于 F 函数,也就是轮函数。那么 Feistel 函数是干了什么事呢?来看下面一张流程图:
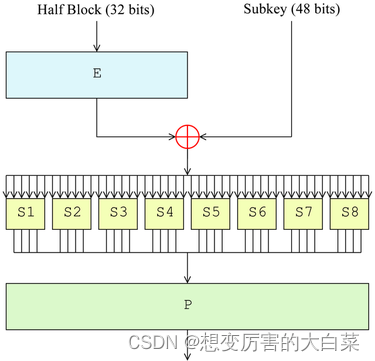
一个 32-bit 的块,经过一个扩张(Expand函数),变成 48 位,然后与子密钥异或。得到的 48-bit 的结果分为 8 组,每一组是 6-bit 的数据,丢进对应的 S 盒,输出 4-bit 的信息。把这些输出收集起来,一共是 4*8 = 32 位,做一次置换 (P 置换),得到 32-bit 的结果。这与输进来的 32-bit 信息是等长度的。
Expand 算法是指定的,P 置换是一个简单置换,因此都是 encode 过程。而这个 32-bit 的半块与 subkey 的混合过程,以及 S 盒提供的强有力的混淆能力,提供了 DES 体系的核心安全性。
需要注意一点:这个 P 置换是精心设计的,使得这一轮同一个 S 盒 输出的四个 bit,在下一回合的扩张之后,交由四个不同的 S 盒去处理。
接下来唯一要处理的就是 S 盒了。它一共有 8 张表,表长成下面这个样子:

什么意思呢?扩张之后的半块与子密钥异或之后,得到了 48 位结果;这些结果分成 8 个组,然后第一组使用 S1 这张表进行变换,第二组使用 S2 进行变换……依次类推。
例:
现在我们假设第二组是 101100 ,来看它在 S盒变换之后会得到什么结果:
- 由于这是第二组,故查询 S2 表。
- 它的首位、末尾是 10 ,故查询第三行(1yyyy0行)。
- 它的中间 4 位是 0110 ,查表知结果是13
- 把 13 转为二进制,得到 1101 ,于是这就是输出。
到此为止,我们完整实现了 F 函数。有一个很有趣的事实——利用同一个子密钥,连续做两次 goRound ,等于什么也没做。
同样的迭代循环,以特定方式连续做两次,等于什么也没做!这就是 DES 加密、解密算法几乎一致的原因所在。把加密、解密的流程图上下拼在一起,中间就会像消消乐一样不停地抵消(解密与加密使用 subkey 的顺序恰好是反的,所以最中间的两个操作会相互抵消),直到最后变得什么改变也没有——因此,这个解密做法是正确的。
四、DES 设计的基本原则:混淆和扩散
DES 设计中使用了 分组密码 设计的两个原则:混淆(confusion)和 扩散 (diffusion),其目的是抗击敌手对密码系统的统计分析。
1945年,Shannon 提出了设计密码体制的两种基本方法——混淆(confusion)、扩散(diffusion)。
混淆: 使密文与密钥之间的关系变得复杂。
本博客之前讨论过“维吉尼亚密码”的分析密钥长度攻击。它是利用了密文的一些统计学特征,来推测出密钥的长度。一个优秀的密码系统,应该很难通过几组密文推断出密钥的特征。扩散:使明文与密文的关系变得复杂。 常常体现为:明文的任何一个bit的变动,都会对密文产生翻天覆地的变化。
我们之前讨论过针对Many-Time-Pad的攻击。这种攻击就是利用了“明文的异或等于密文的异或”这种特征,使得攻击者轻易地得到了明文的大量统计信息,帮助攻击者攻破密码体系。
扩散的作用就是将每一位明文的影响尽可能迅速地作用到较多的输出密文位中,以便在大量的密文中消除明文的统计结构,并且使每一位密钥的影响尽可能迅速地扩展到较多的密文位中,以防对密钥进行逐段破译。在实践上,一些非线性的操作可以实现“混淆”。例如乘法(乘法对二进制位有很复杂的改变。回顾一下学《数字逻辑》的时候,一个乘法器需要大量的逻辑门才能实现)、S盒(Substitution-box,替换盒。就是一个特定的函数,其映射关系是精心设计以对抗攻击的)。DES 体系在轮函数中采用了 S-box。
至于对“扩散”的实现,一般采用线性变换、置换、循环移位等手段。多次迭代可以大大增强混淆和扩散的强度,使密文、明文、密钥之间的关系异常复杂,以至于攻击者极其难以分析。
五、安全性
算法的安全性依赖于密钥的保密程度。(Kerckhoffs’s principle,柯克霍夫原则)
柯克霍夫原则要求,一个加密方案的安全性,仅取决于密钥的安全性,而不取决于算法的秘密。接受 Kerckhoffs 原则会带来很多好处:
- 首先,由于加密算法是公开的,通讯各方只需要保密密钥(这显然比加密算法要短,按常理来讲,越短的东西越容易保密)。
- 另外,如果密钥泄露了,双方只需要改个新的密钥就能继续安全通信(若不遵循 Kerckhoffs 原则,一旦泄露算法就需要重新设计加密方案)。
- 最后,遵循 Kerckhoffs 原则可以带来标准化的好处:多人通讯时,可以采用相同的算法而选择不同的密钥,这样程序可以复用。
参考链接
-
相关阅读:
儿童护眼灯什么光源好?LED光源的儿童护眼灯品牌推荐
在Pyppeteer中实现反爬虫策略和数据保护
Linux文件权限
【C语言练习——打印空心下三角及其变形】
http模块学习
DVWA靶场通关实战
分布式项目搭建
SSRF漏洞
C语言第十一课(上):编写扫雷游戏(综合练习2)
latex subsection 第一段 首行取消缩进
- 原文地址:https://blog.csdn.net/weixin_44211968/article/details/126543433