-
深度学习-通过Resnet18实现CIFAR10数据分类
1. CIFAR10数据集
CIFAR-10 是一个适用于图像分类任务的小型数据集。图片的尺寸为 32×32,一共包含10 个类别:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck),共有50000张训练集图片和10000张测试集图片,其中,每个类别分别有6000张图片(5000训练集+1000测试集)。CIFAR10

2. Resnet18
残差神经网络(Resnet)是一种卷积神经网络,巧妙地利用了shortcut连接,解决了深度网络中模型退化的问题。极大的消除了深度过大的神经网络训练困难问题。神经网络的“深度”首次突破了100层、最大的神经网络甚至超过了1000层。
详细的Resnet的介绍可以参考:
Resnet18便是Resnet的一种结构,其中由17层卷积和1层全连接层组成。

3. 迁移学习
迁移学习是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中。迁移学习与多任务学习以及概念飘移这些问题相关,它不是一个专门的机器学习领域。然而,迁移学习在某些深度学习问题中是非常受欢迎的,例如在具有大量训练深度模型所需的资源或者具有大量的用来预训练模型的数据集的情况。仅在第一个任务中的深度模型特征是泛化特征的时候,迁移学习才会起作用。深度学习中的这种迁移被称作归纳迁移。就是通过使用一个适用于不同但是相关的任务的模型,以一种有利的方式缩小可能模型的搜索范围。
[https://baike.baidu.com/item/%E8%BF%81%E7%A7%BB%E5%AD%A6%E4%B9%A0/22768151]:
通过迁移学习,即使我们手上的数据量比较少,也可以建立一个效果还不错的深度学习模型。
4. 代码实现
4.1 导入程序所需的包
import glob import os.path as osp import random import numpy as np import json from datetime import datetime from PIL import Image from tqdm import tqdm import matplotlib.pyplot as plt %matplotlib inline- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
import torch from torch import nn from torch import optim from torch.utils import data from torch.utils.tensorboard import SummaryWriter import torchvision from torchvision import models, transforms- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 设置CPU生成随机数的种子,方便下次复现实验结果 torch.manual_seed(2022) # 每次生成的随机数都相同 np.random.seed(2022) random.seed(2022)- 1
- 2
- 3
- 4
- 5
4.2 使用GPU进行训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"running on {device}")- 1
- 2
4.3 图像预处理
# transforms.Resize(size):将图片的短边缩放成size的比例,然后长边也跟着缩放,使得缩放后的图片相对于原图的长宽比不变 # transforms.CenterCrop(size):从图像的中心位置裁剪指定大小的图像 # ToTensor():将图像由PIL转换为Tensor # transform.Normalize():把0-1变换到(-1,1) # image = (image - mean) / std # 其中mean和std分别通过(0.5, 0.5, 0.5)和(0.2, 0.2, 0.2)进行指定。原来的0-1最小值0则变成(0-0.5)/0.5=-1,而最大值1则变成(1-0.5)/0.5=1 trans = transforms.Compose([ transforms.Resize(224), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5),(0.2, 0.2, 0.2)) ])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4.4 创建数据集
train_dataset = torchvision.datasets.CIFAR10("./data", train=True, transform=trans, download=True) test_dataset = torchvision.datasets.CIFAR10("./data", train=False, transform=trans, download=True) classes = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]- 1
- 2
- 3
batch_size = 128 train_dataloader = data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_dataloader = data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)- 1
- 2
- 3
data_loaders = { "train": train_dataloader, "test": test_dataloader }- 1
- 2
- 3
- 4
4.5 下载预训练模型
net = torchvision.models.resnet18(pretrained=True) net- 1
- 2
4.6 修改网络模型的最后一层输出为10
net.fc = nn.Linear(512, 10)- 1
4.7 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters())- 1
- 2
4.8 使用Tensorboard可视化工具
TIMESTAMP = f"{datetime.now():%Y-%m-%dT%H-%M-%S/}" writer = SummaryWriter(f"/root/tf-logs/{TIMESTAMP}/")- 1
- 2
4.9 训练模型
def train_model(net, dataloaders, criterion, optimizer, num_epochs): net.to(device) # 网络加速 torch.backends.cudnn.benchmark = True for epoch in range(num_epochs): for phase in ["train", "test"]: if phase == "train": net.train() else: net.eval() # 损失 epoch_loss = 0.0 # 正确答案的数量 epoch_corrects = 0 for inputs, labels in tqdm(data_loaders[phase]): inputs = inputs.to(device) labels = labels.to(device) optimizer.zero_grad() # 设置梯度计算开启或关闭 # 只在训练时开启梯度计算 with torch.set_grad_enabled(phase == "train"): outputs = net(inputs) # 计算损失 loss = criterion(outputs, labels) # 预测标签 # 返回每一行的最大值,也就是所属的类别 _, preds = torch.max(outputs, 1) # 反向传播 if phase == "train": loss.backward() optimizer.step() # loss的总和 # loss计算的是平均值,所以要乘上batchsize,计算损失的总和 epoch_loss += loss.item() * inputs.size(0) # 预测正确的答案的数量 epoch_corrects += torch.sum(preds == labels.data) # 每个epoch的loss和正确率 epoch_loss = epoch_loss / len(data_loaders[phase].dataset) epoch_acc = epoch_corrects.double() / len(data_loaders[phase].dataset) epoch_loss = torch.tensor(epoch_loss) epoch_acc = torch.tensor(epoch_acc) # print(f"epoch: {epoch + 1}/{num_epochs}; {phase} loss:{np.round(epoch_loss.item(), 5)}; acc:{np.round(epoch_acc.item() * 100, 2)}%") writer.add_scalar(f"{phase} loss", epoch_loss, epoch) writer.add_scalar(f"{phase} accuracy", epoch_acc, epoch) # 保存模型 if (epoch % 20 == 0 and phase == 'train'): save_path = f"./models/resnet_{epoch}_{epoch_acc}.pth" torch.save(net.state_dict(), save_path)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
num_epochs = 200 train_model(net, data_loaders, criterion, optimizer, num_epochs)- 1
- 2
4.10 查看训练结果
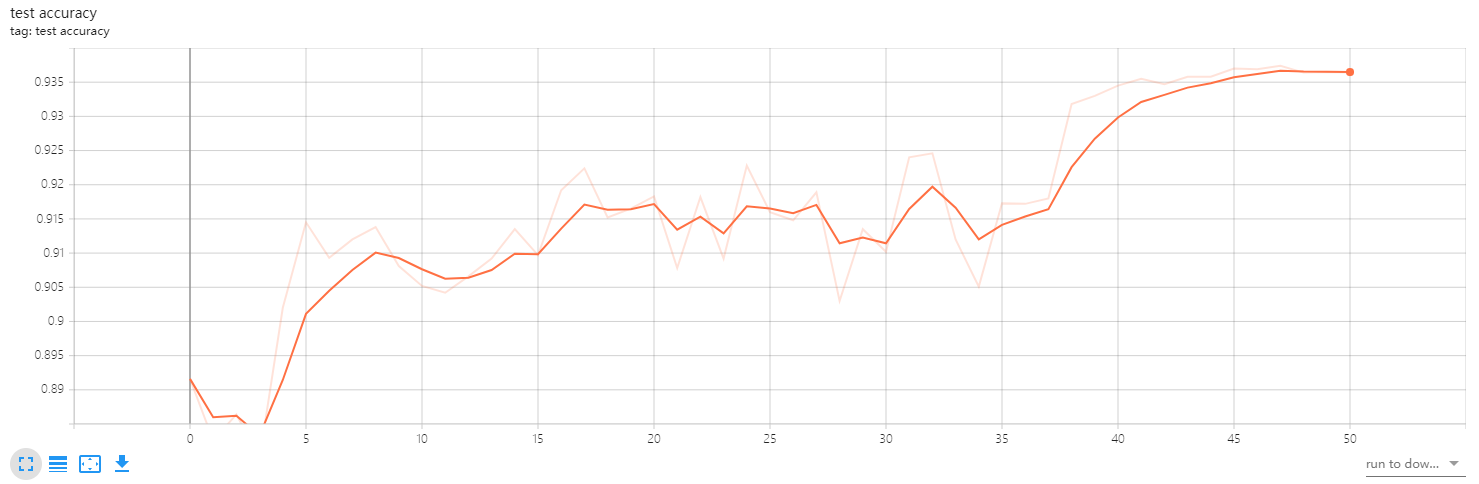
5. 测试模型
5.1 加载模型
net = torchvision.models.resnet18(pretrained=True) net.fc = nn.Linear(512, 10) load_path = "./models/vgg16_40_1.0.pth" load_weights = torch.load(load_path) net.load_state_dict(load_weights)- 1
- 2
- 3
- 4
- 5
- 6
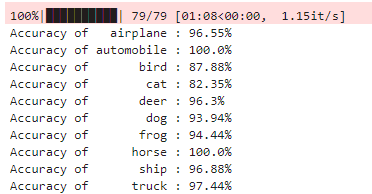
5.2 在测试集上测试模型的分类准确度
net.to(device) net.eval() class_correct = list(0. for i in range(10)) class_total = list(0. for i in range(10)) for data in tqdm(data_loaders['test']): imgs, labels = data imgs = imgs.to(device) labels = labels.to(device) outputs = net(imgs) _, preds = torch.max(outputs, 1) c = (preds == labels) c = c.squeeze() for i in range(4): label = labels[i] class_correct[label] += c[i] class_total[label] += 1 for i in range(10): print(f"Accuracy of {classes[i]:>10} : {np.round(100 * class_correct[i].detach().cpu().numpy() / class_total[i], 2)}%")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
-
相关阅读:
6-3漏洞利用-SSH环境搭建
1536. 排布二进制网格的最少交换次数;754. 到达终点数字;1106. 解析布尔表达式
单片机汇编代码如何执行
源码编译risc-v虚拟机和编译器 riscv-gnu-toolchain 和 riscv-tools 在ubuntu 22.04
【Python】自定义pip安装路径
Halcon一维码识别实例
Linux--网络编程
<一>Qt斗地主游戏开发:开发环境搭建--VS2019+Qt5.15.2
MySQL中对于事务的理解
【Java快速入门】Java语言的抽象类和接口(十)
- 原文地址:https://blog.csdn.net/weixin_40330033/article/details/126545207
