-
计算机视觉与图形学-神经渲染专题-基于单目 RGB 视频的动画神经辐射场
(说明:如果您认为下面的文章对您有帮助,请您花费一秒时间点击一下最底部的广告以此来激励本人创作,谢谢!!!)
摘要
这篇论文提出一个用于从单目视频中来创建详细人体的动画神经辐射场方法(动画NeRF)。这篇论文方法通过在学习场景表示网络的中引入显式姿势引导变形,将神经辐射场 (NeRF) 扩展到具有人体运动的动态场景。特别是,这篇论文估计了每一帧的人体姿态,并为人体模板学习一个恒定的规范空间,这使得在姿态参数的显式控制下,从观察空间到规范空间的自然形状变形成为可能。为了弥补不准确的姿态估计,作者在学习过程中引入更新初始姿态的姿态细化策略,这不仅有助于学习更准确的人体重建,而且还加速了收敛。在实验中,作者表明所提出的方法实现 1) 具有高质量细节的隐式人体几何和外观重建,2) 从新颖的视图中对人体进行逼真的渲染,以及 3) 具有新颖姿势的人体动画。
论文方法简要描述
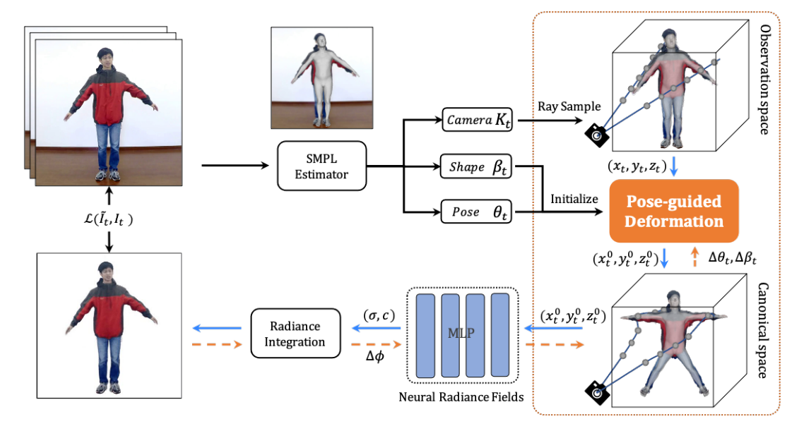
所提出的动画神经辐射场概述如下如所示。给定一个视频序列,作者估计用于初始化的人体主体的相机参数和SMPL参数。 然后,作者使用体绘制在观察空间中沿相机射线进行采样,并根据姿态引导变形将这些点转换到规范空间。紧接着,作者将这些点输入到神经辐射场中,得到体密度和颜色。与此同时,作者使用积分方程渲染图像,通过最小化渲染图像和真实图像之间的误差L,联合优化神经辐射场参数𝜙和SMPL参数K。
实验结果
在 People-snapshot(1-2 行)和iPER(3-4 行)上对新颖视图合成的不同方法进行视觉比较。NeRF很难处理动态场景,因为主体的移动违反了多视图一致性要求。 在作者提出的姿势引导变形的帮助下,如果估计的 SMPL 姿势准确,NeRF+U (NeRF + Unpose) 会取得更好的结果(第 1 行和第2 行),但如果不准确,仍然会产生模糊的结果(第 3 行和第 4 行)。只要估计的 SMPL 姿势相当好,进一步添加姿势细化就可以大大提高鲁棒性。与NeuralBody 和 SMPLpix 相比,作者的方法可以生成具有良好身份和布料细节的逼真图像。

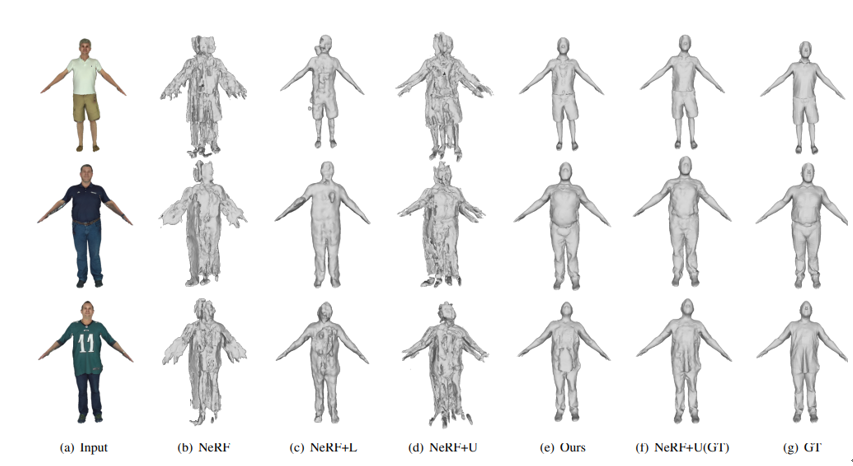
Multi-Garment上3D 重建的可视化。NeRF 和 NeRF+U (NeRF + Unpose) 由于主体的移动和不准确的 SMPL 无法重建 3D 几何。与产生过平滑或欠平滑结果的NeRF+L (NeRF + Latent) 相比,作者所提出的方法结果更合理。作为参考,NeRF+U(GT) 使用 GT SMPL 并以非常高的精度学习几何,证明了作者所提出的姿势引导变形的有效性,并展示了获得准确 SMPL 对 3D 重建任务的重要性。
结论
作者所提出的方法重建了详细的 3D 人体模型,并从单目视频中渲染出逼真的图像。通常情况下,训练视频会捕捉拍摄对象在相机前转身并保持 A 姿势或 T 姿势。在对包含复杂姿势的视频进行训练时,作者所提出的方法仍然可以获得合理的结果。但与之前的简单训练视频相比,观察到了明显的细节损失。主要原因是对于包含以下内容的视频,获得足够准确的SMPL 估计更具挑战性复杂的姿势。另一个限制是我们的方法很难处理极其宽松的衣服或完成服装的非刚性变形,因为作者提出的显式姿势引导变形将空间点与 SMPL 网格相关联,而没有显式的服装建模。因此,新颖的视图合成结果不可避免地丢失了衣服上的一些细节。因此,为了获得最佳效果,表演者应该慢慢转身并保持一个简单的姿势,以便他们的衣服相对于他们的身体几乎保持静止,以获得高质量的渲染。与所有仅针对一个场景训练的基于 NeRF 的方法一样,作者的方法无法重建不可见的部分,例如腋下和大腿内侧,因此输入视频需要尽可能覆盖人体的整个身体。
更多内容请关注公众号:元宇宙MetaAI
欢迎朋友们投稿,投稿可添加微信:NewYear-2016
-
相关阅读:
yolov5s V6.1版本训练PASCAL VOC2012数据集&yolov5官网教程Train Custom Data
我怀疑这是IDEA的BUG,但是我翻遍全网没找到证据!
opiodr aborting process unknown ospid (50593852) as a result of ORA-609
在word文档里面插入漂亮的伪代码
dubbo 自定义异常
【云原生之Docker实战】使用Docker部署mBlog微博系统
2023常州大学计算机考研信息汇总
docker(2)部署前后端分离springboot+vue项目
[一篇读懂]C语言九讲:线性表应用
Nacos win10 安装配置教程
- 原文地址:https://blog.csdn.net/CSS360/article/details/126496099