-
8.25 学习
import numpy as np import torch from torch.utils.data import Dataset from torch.utils.data import DataLoader class DiabetesDataset(Dataset): def __init__(self,filepath): xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32) self.len = xy.shape[0] self.x_data = torch.from_numpy(xy[:,:-1]) self.y_data = torch.from_numpy(xy[:,[-1]]) def __getitem__(self, index): return self.x_data[index],self.y_data[index] def __len__(self): return self.len dataset = DiabetesDataset('diabetes.csv.gz') train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2) # 模型构造 class Model(torch.nn.Module): def __init__(self): super(Model, self).__init__()#必要步骤,调用弗雷构造 self.linear1 = torch.nn.Linear(8,6) self.linear2 = torch.nn.Linear(6,4) self.linear3 = torch.nn.Linear(4,1) self.sigmoid = torch.nn.Sigmoid() def forward(self,x): #这一步的输出作为下一步的输入 x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() #实例化 # 损失函数与优化器 criterion = torch.nn.BCELoss(size_average=True) optimizer = torch.optim.SGD(model.parameters(),lr=0.01) # Using DataLoader for epoch in range(100): for i, data in enumerate(train_loader,0): # 1.Prepare data # 从data中提取数据和标签 inputs, labels = data # 2.forward,计算预测值和损失值 y_pred = model(inputs) loss = criterion(y_pred,labels) print(epoch,i,loss.item()) # 3. Backward optimizer.zero_grad() loss.backward() #4.update optimizer.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
真的出现了,runtimeerror
import numpy as np import torch from torch.utils.data import Dataset from torch.utils.data import DataLoader class DiabetesDataset(Dataset): def __init__(self,filepath): xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32) self.len = xy.shape[0] self.x_data = torch.from_numpy(xy[:,:-1]) self.y_data = torch.from_numpy(xy[:,[-1]]) def __getitem__(self, index): return self.x_data[index],self.y_data[index] def __len__(self): return self.len dataset = DiabetesDataset('diabetes.csv.gz') train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2) # 模型构造 class Model(torch.nn.Module): def __init__(self): super(Model, self).__init__()#必要步骤,调用弗雷构造 self.linear1 = torch.nn.Linear(8,6) self.linear2 = torch.nn.Linear(6,4) self.linear3 = torch.nn.Linear(4,1) self.sigmoid = torch.nn.Sigmoid() def forward(self,x): #这一步的输出作为下一步的输入 x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() #实例化 # 损失函数与优化器 criterion = torch.nn.BCELoss(size_average=True) optimizer = torch.optim.SGD(model.parameters(),lr=0.01) if __name__ == '__main__': # Using DataLoader for epoch in range(100): for i, data in enumerate(train_loader,0): # 1.Prepare data # 从data中提取数据和标签 inputs, labels = data # 2.forward,计算预测值和损失值 y_pred = model(inputs) loss = criterion(y_pred,labels) print(epoch,i,loss.item()) # 3. Backward optimizer.zero_grad() loss.backward() #4.update optimizer.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65

import torch criterion = torch.nn.CrossEntropyLoss() Y = torch.LongTensor([2,0,1]) Y_pred1 = torch.Tensor([[0.1,0.2,0.9], [1.1,0.1,0.2], [0.2,2.1,0.1]]) Y_pred2 = torch.Tensor([[0.8,0.2,0.3], [0.2,0.3,0.5], [0.2,0.2,0.5]]) l1 = criterion(Y_pred1,Y) l2 = criterion(Y_pred2,Y) print("Batch Loss1 = ",l1.data,"\nBatch Loss2=",l2.data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
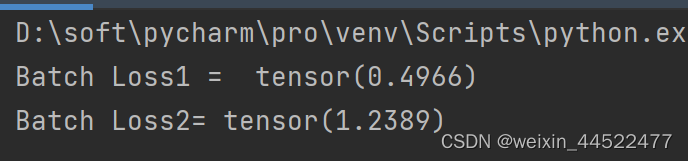
和预测的结果一样,LOSS1是比较小的,因为算出来的比较吻合,损失较小
Y是预测值,Y_PRE是初始值
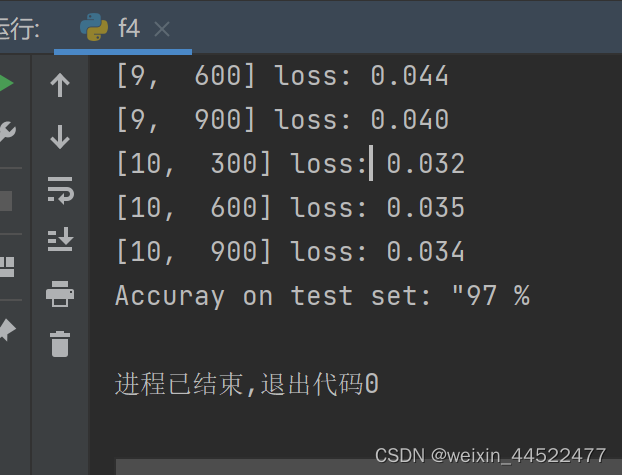
import torch from torchvision import transforms from torchvision import datasets from torch.utils.data import DataLoader import torch.nn.functional as F import torch.optim as optim batch_size = 64 # Convert the PIL Image to Tensor # totensor,把输入的图像转换为张量 # normalize: mean 均值 std标准差,就是0.1307,0.3081 transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]) train_dataset = datasets.MNIST(root='../dataset/mnist/',train=True,download=True,transform=transform) train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size) test_dataset = datasets.MNIST(root='../dataset/mnist/',train=False,download=True,transform=transform) test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size) class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.l1 = torch.nn.Linear(784,512) self.l2 = torch.nn.Linear(512,256) self.l3 = torch.nn.Linear(256,128) self.l4 = torch.nn.Linear(128, 64) self.l5 = torch.nn.Linear(64, 10) def forward(self,x): x = x.view(-1,784) x = F.relu(self.l1(x)) x = F.relu(self.l2(x)) x = F.relu(self.l3(x)) x = F.relu(self.l4(x)) return self.l5(x) model = Net() criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5) def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader,0): inputs,target = data optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs,target) loss.backward() optimizer.step() # 累计的loss拿出来,取loss的时候要用item running_loss += loss.item() # 如果300次迭代就拿出来 if batch_idx %300 == 299: print('[%d,%5d] loss: %.3f' % (epoch+1,batch_idx+1,running_loss/300)) running_loss = 0.0 # test def test(): correct = 0 total = 0 # torch.no_grad这里面不会计算梯度 with torch.no_grad(): for data in test_loader: images, labels = data # 拿完数据做预测,拿下标 outputs = model(images) # 沿着横去找最大值的下标 _, predicted = torch.max(outputs.data,dim=1) # 加上总数,total就是batch_size total += labels.size(0) # 求和拿出来,我们猜对了多少个 correct += (predicted == labels).sum().item() print('Accuray on test set: "%d %%' % (100*correct/total)) if __name__ == '__main__': for epoch in range(10): train(epoch) if epoch%10 == 9: test()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
import torch in_channels,out_channels = 5,10 width ,height = 100,100 kernel_size = 3 #卷积核的大小 batch_size = 1 # 在pytorch里面,所以输入的数据必须是小批量的数据 input = torch.randn(batch_size,in_channels,width,height) # 大小,尺寸 3*3 或者5*3 都可以,一般来说是正方形 conv_layer = torch.nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size) #创建的卷积对象 conv_layer 把input送给他 output = conv_layer(input) print(input.shape) print(output.shape) print(conv_layer.weight.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
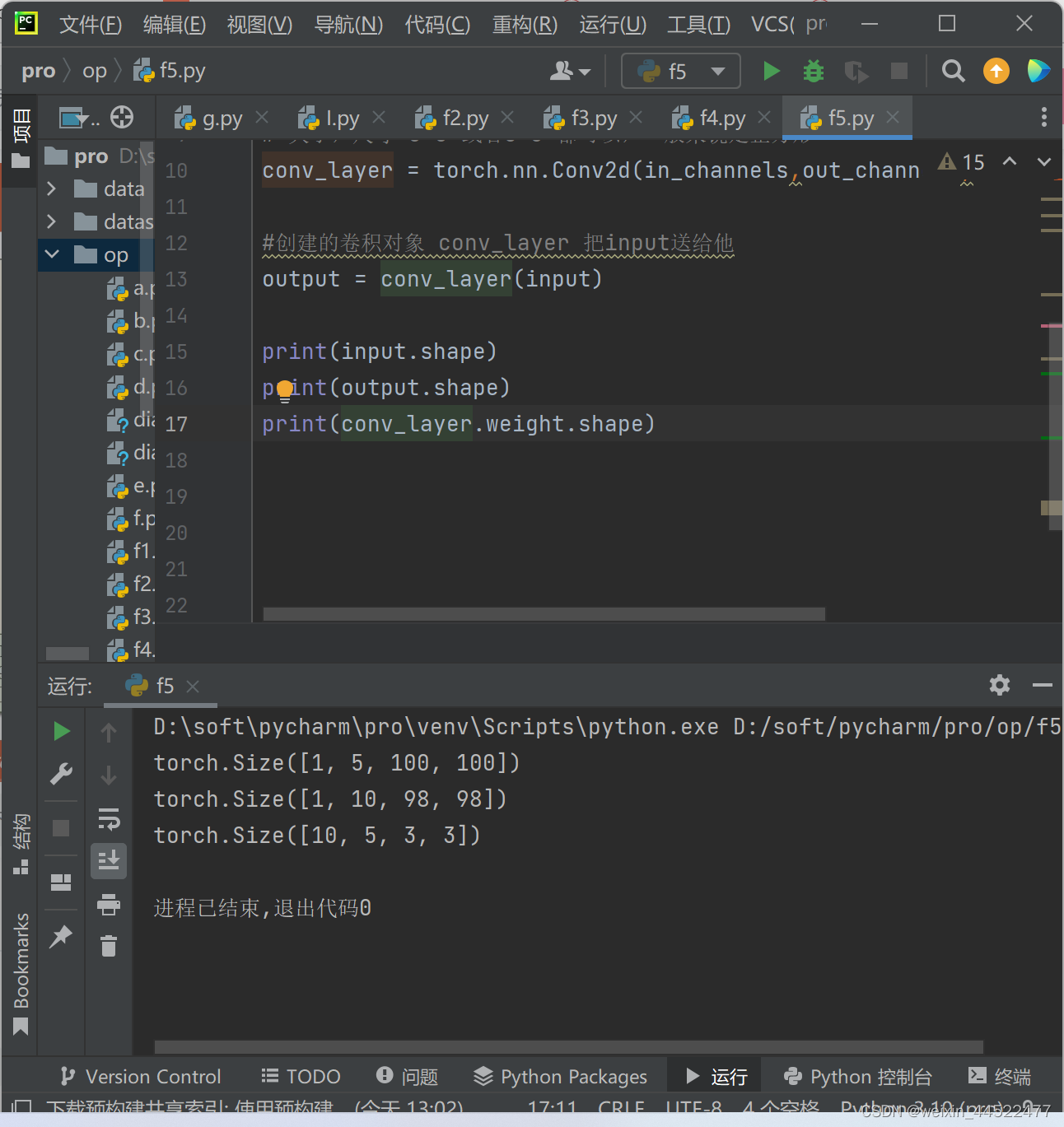
输入的图像5个通道,100*100
输出10个通道,98,98
10 输出的通道import torch # 输入的矩阵 input = [3,4,6,5,7, 2,4,6,8,2, 1,6,7,8,4, 9,7,4,6,2, 3,7,5,4,1] # 输入=这个输入转化为1维的5,5 input = torch.Tensor(input).view(1,1,5,5) conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,padding=1,bias=False) kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3) conv_layer.weight.data = kernel.data output = conv_layer(input) print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

D:\soft\pycharm\pro\venv\Scripts\python.exe D:/soft/pycharm/pro/op/f6.py tensor([[[[ 91., 168., 224., 215., 127.], [114., 211., 295., 262., 149.], [192., 259., 282., 214., 122.], [194., 251., 253., 169., 86.], [ 96., 112., 110., 68., 31.]]]], grad_fn=<ConvolutionBackward0>) 进程已结束,退出代码0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
stride
import torch # 输入的矩阵 input = [3,4,6,5,7, 2,4,6,8,2, 1,6,7,8,4, 9,7,4,6,2, 3,7,5,4,1] # 输入=这个输入转化为1维的5,5 input = torch.Tensor(input).view(1,1,5,5) conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,stride=2,bias=False) kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3) conv_layer.weight.data = kernel.data output = conv_layer(input) print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

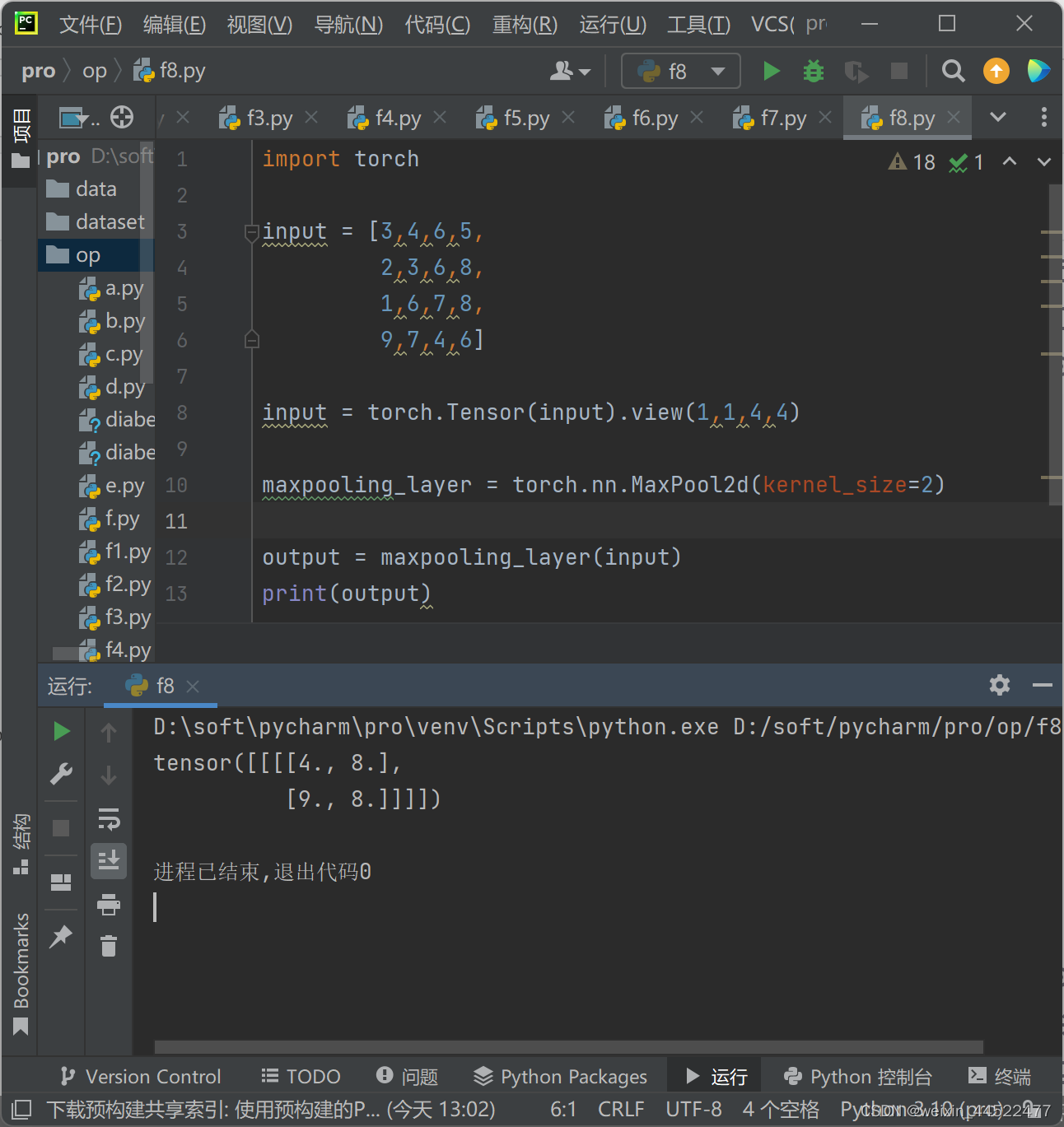
MaxPooling
import torch input = [3,4,6,5, 2,3,6,8, 1,6,7,8, 9,7,4,6] input = torch.Tensor(input).view(1,1,4,4) maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2) output = maxpooling_layer(input) print(output)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
D:\soft\pycharm\pro\venv\Scripts\python.exe D:/soft/pycharm/pro/op/f8.py tensor([[[[4., 8.], [9., 8.]]]]) 进程已结束,退出代码0- 1
- 2
- 3
- 4
- 5
- 6
-
相关阅读:
线性筛的简单证明
SecureCRT取消Session记录的密码
简单介绍一下迁移学习
2023常用的原型设计软件推荐
IP属地如何高效率识别
人傻了,在学校也没人跟我说微服务这么重要啊!惨遭工作毒打的我只能说这份微服务笔记真是我的救星!
【前端】判断是否为对象
node前端常用
SpringCloud Netflix-Hystix使用
python进阶练习
- 原文地址:https://blog.csdn.net/weixin_44522477/article/details/126522522
