-
深度学习笔记(5)——pytorch实现Att-BiLSTM
1 模型介绍
模型图:
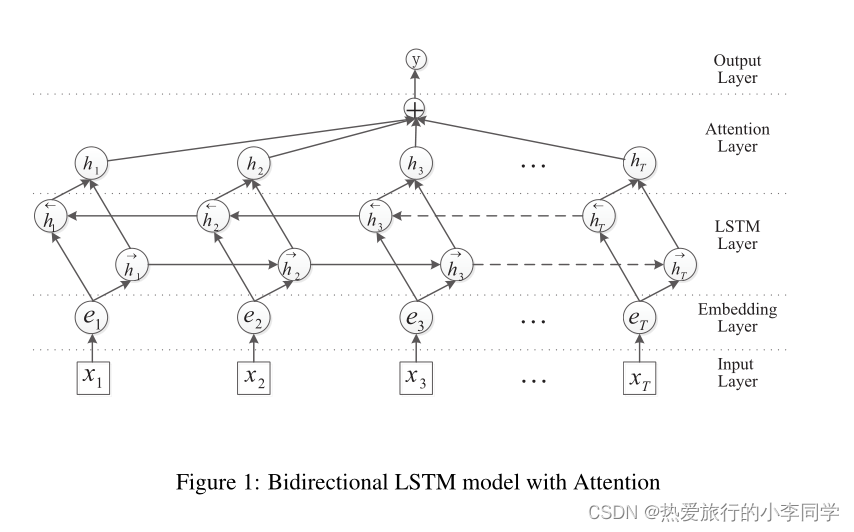
LSTM层:

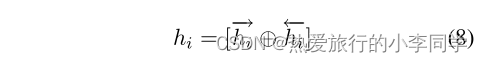
Attention层
M = t a n h ( H ) α = s o f t m a x ( ω T ∗ M ) r = H α T h ∗ = t a n h ( r ) \ M=tanh(H) \\ \alpha=softmax(\omega ^ T*M) \\ r=H\alpha^ T \\ h^*=tanh(r) M=tanh(H)α=softmax(ωT∗M)r=HαTh∗=tanh(r)
其中
H 为 L S T M 输出的结果,对应于 n n . l s t m ( ) 输出的第一个结果 \ H为LSTM输出的结果,对应于nn.lstm()输出的第一个结果 H为LSTM输出的结果,对应于nn.lstm()输出的第一个结果
w T 为训练参数向量, T 表示转置 \ w^T为训练参数向量,T表示转置 wT为训练参数向量,T表示转置
α 即为注意力打分函数 \ \alpha即为注意力打分函数 α即为注意力打分函数
h ∗ 为注意力层输出的结果,传递给全连接层 \ h^*为注意力层输出的结果,传递给全连接层 h∗为注意力层输出的结果,传递给全连接层2 代码实现
import torch import torch.nn.functional as F from torch import nn, Tensor class BiLSTM_Attention(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_size, num_layers, num_classes, device): super(BiLSTM_Attention, self).__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.device = device # 词嵌入层 self.embed = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim) # LSTM self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True, bidirectional=True) # Dropout层 self.dropout = nn.Dropout(p=0.5) # 全连接层 self.fc = nn.Linear(in_features=hidden_size * 2, out_features=num_classes) def attention(self, lstm_out, h_n): hidden = h_n.view(-1, self.hidden_size * 2, 1) # [64, 600, 1] [batch, num_directions * hidden_size, 1] weights = torch.transpose(hidden, 1, 2) # [64, 1, 600] [batch, 1, num_directions * hidden_size] H = torch.transpose(lstm_out, 1, 2) # [64, 600, 200] [batch, num_directions * hidden_size, seq_len] M = torch.tanh(H) """ [batch, 1, num_directions * hidden_size] bmm [batch, num_directions * hidden_size, seq_len] = [batch, 1, seq_len] torch.bmm([64, 1, 600], [64, 600, 200])->[64, 1, 200] """ att_weights = torch.bmm(weights, M) # [64, 1, 200] [batch, 1, seq_len] alpha = F.softmax(att_weights, dim=2) # [64, 1, 200] [batch, 1, seq_len] r = torch.bmm(H, torch.transpose(alpha, 1, 2)).squeeze(2) # [64, 600] [batch, num_directions * hidden_size] att_out = torch.tanh(r) # [batch, num_direction * hidden_size] return att_out, Tensor.cpu(alpha) def forward(self, x): # x:[64, 200] [batch_size, seq_len] x = self.embed(x) # [64, 200, 300] [batch, seq_len, hidden_size] h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(self.device) c0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(self.device) """ out: [64, 200, 600] [batch, seq_len, num_directions * hidden_size] h_n: [2, 64, 300] [num_layers * num_directions, batch, hidden_size] c_n: [2, 64, 300] [num_layers * num_directions, batch, hidden_size] """ out, (h_n, c_n) = self.lstm(x, (h0, c0)) """ att_out: [64, 600] [batch, num_directions * hidden_size] attention: [64, 1, 200] [batch, 1, seq_len] """ att_out, attention = self.attention(out, h_n) logits = self.fc(att_out) # [64, 10] [batch, num_classes] return logits- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
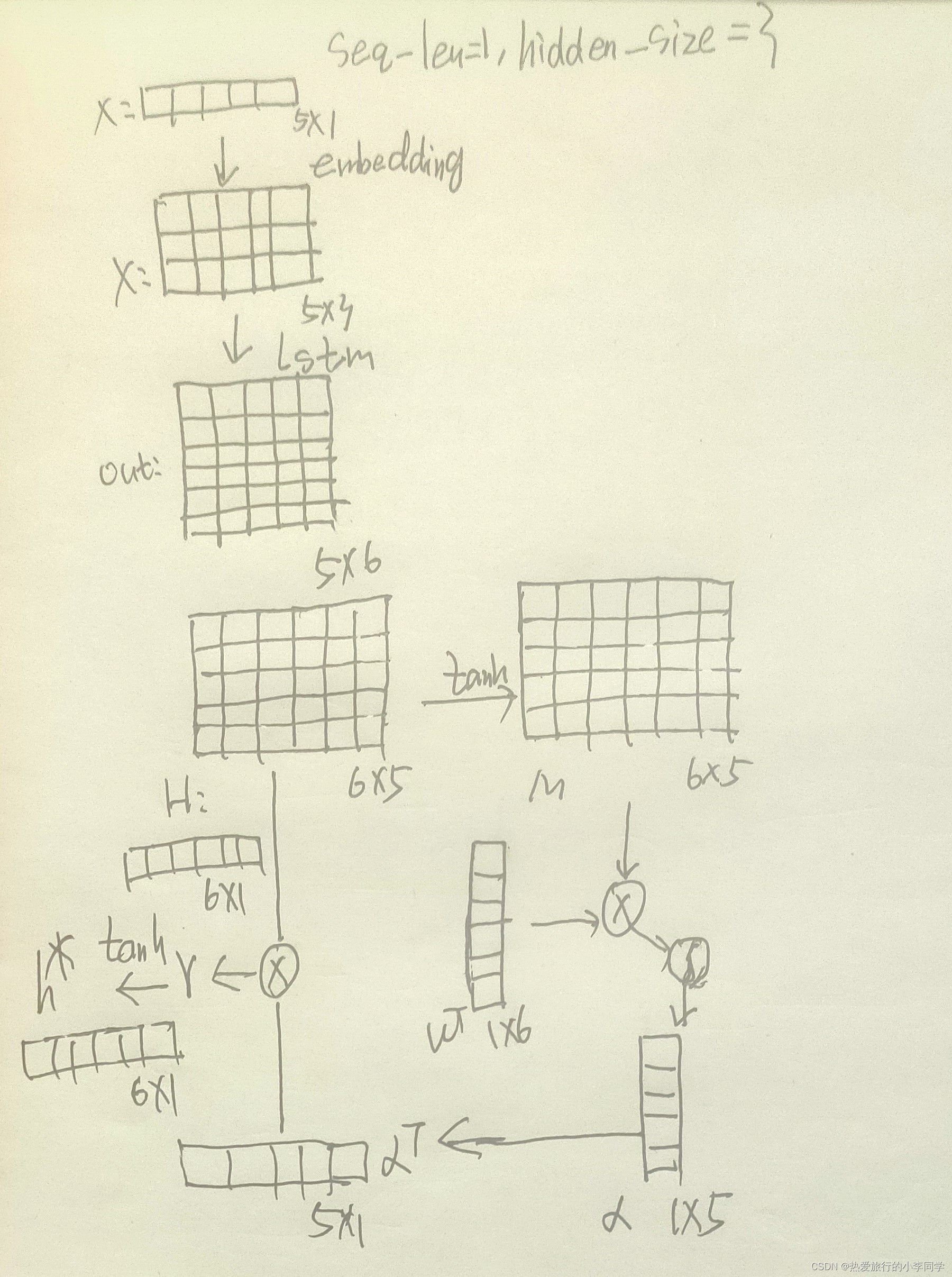
3 传播过程理解
传播过程中的维度变化
输入层:[batch, seq_len]
词嵌入层:[batch, seq_len, hidden_size]
LSTM层:
out: [batch, seq_len, num_directions * hidden_size]
h_n/c_n: [num_layers * num_directions, batch, hidden_size]
Attention层:
H: [batch, num_directions * hidden_size, seq_len]
M: [batch, num_directions * hidden_size, seq_len]
ω T \ \omega^T ωT: [batch, 1, seq_len]
α \ \alpha α: [batch, 1, seq_len]
r: [batch, num_directions * hidden_size]
att_out: [batch, num_directions * hidden_size]
logits: [batch, num_classed]
推导(一个batch为例)
4 实验
以微博情感分析为例
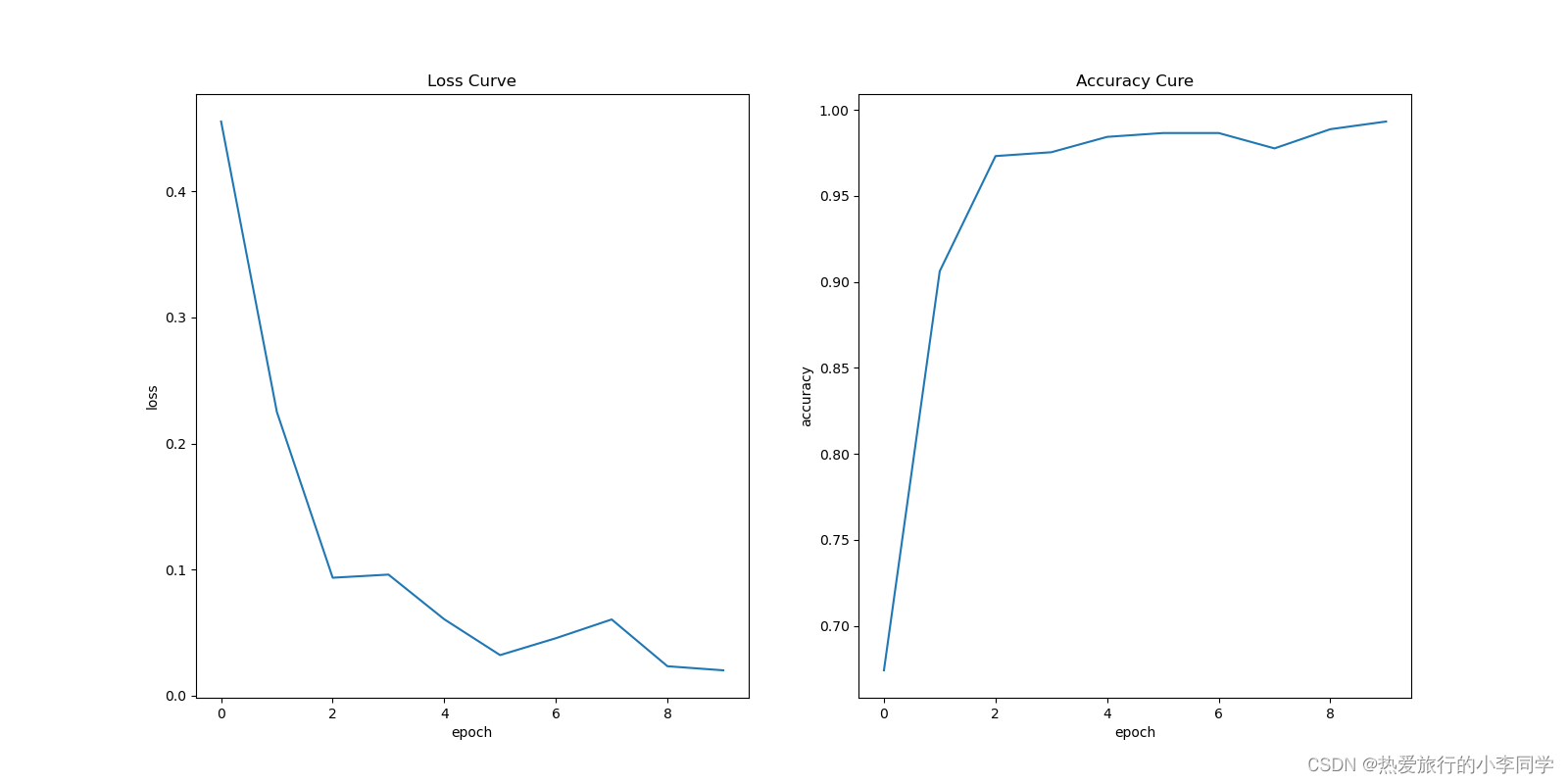
具体代码写在前篇4 参考文献
论文名称:Attention-Based Bidirectional Long Short-Term Memory Networks for
Relation Classification
论文链接:https://aclanthology.org/P16-2034.pdf
本文参考了:
CSDN:https://blog.csdn.net/qq_34523665/article/details/105654404
GITHUB:https://github.com/onehaitao/Att-BLSTM-relation-extraction -
相关阅读:
移动测试之语音识别功能如何测试?
微服务框架 SpringCloud微服务架构 22 DSL 查询语法 22.2 全文检索查询
分享刚出炉的基于Blazor技术的Web应用开发框架
用户忠诚度衡量指标丨利用净推荐值减少流失
SpringMVC框架
JavaScript 2.0
Apache Tomcat 漏洞复现
数据仓库性能测试方法论与工具集
《Hello Algo》:动画图解引领的数据结构与算法学习之旅
缓存的力量:提升API性能和可扩展性
- 原文地址:https://blog.csdn.net/m0_46275020/article/details/126530708
