-
深度学习中模块设计汇总(一)
深度学习模块最小构成部分
1.PixelShufflenn.PixelShuffle(upscale_factor=scailingFactor)- 1
2.Convolution
3.Strided Convolution深度学习经典模块
Beyond Joint Demosaicking and Denoising: An Image Processing Pipeline for a Pixel-bin Image Sensor
1.Group Depth Attention Bottleneck Block
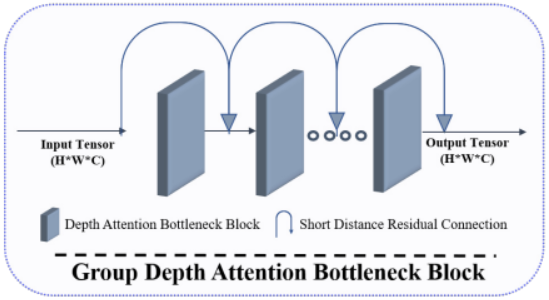
2.Depth A ttention Bottleneck Block

3.Spatial Attention Block

class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) x = self.conv1(x) return self.sigmoid(x) class SpatialAttentionBlock(nn.Module): def __init__(self, spatial_filter=32): super(SpatialAttentionBlock, self).__init__() self.spatialAttenton = SpatialAttention() self.conv = nn.Conv2d(spatial_filter, spatial_filter, 3, padding=1) def forward(self, x): x1 = self.spatialAttenton(x) #print(" spatial attention",x1.shape) xC = self.conv(x) #print("conv",xC.shape) y = x1 * xC #print("output",y.shape) return y- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
AWNet: Attentive Wavelet Network for Image ISP AWNet
1.全局上下文 res-dense 模块
全局上下文 res-dense 模块包含一个残差密集块 (RDB) 和一个全局上下文块 (GCB)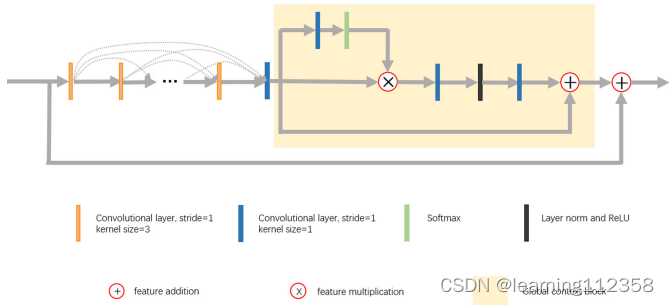
1.1 残差密集块 (RDB)class MakeDense(nn.Module): '''单个残差块''' def __init__(self, in_channels, growth_rate, kernel_size=3): super(MakeDense, self).__init__() self.conv = nn.Conv2d(in_channels, growth_rate, kernel_size=kernel_size, padding=(kernel_size - 1) // 2) self.norm_layer = nn.BatchNorm2d(growth_rate) def forward(self, x): out = F.relu(self.conv(x)) out = self.norm_layer(out) out = torch.cat((x, out), 1) return out for i in range(num_dense_layer): '''循环连接单个残差块形成一个残差密集块 (RDB) ''' modules.append(MakeDense(_in_channels, growth_rate)) _in_channels += growth_rate self.residual_dense_layers = nn.Sequential(*modules)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1.2 全局上下文块 (GCB)
class ContextBlock2d(nn.Module): def __init__(self, inplanes=9, planes=32, pool='att', fusions=['channel_add'], ratio=4): super(ContextBlock2d, self).__init__() assert pool in ['avg', 'att'] assert all([f in ['channel_add', 'channel_mul'] for f in fusions]) assert len(fusions) > 0, 'at least one fusion should be used' self.inplanes = inplanes self.planes = planes self.pool = pool self.fusions = fusions if 'att' in pool: self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1) # context Modeling self.softmax = nn.Softmax(dim=2) else: self.avg_pool = nn.AdaptiveAvgPool2d(1) if 'channel_add' in fusions: self.channel_add_conv = nn.Sequential( nn.Conv2d(self.inplanes, self.planes // ratio, kernel_size=1), nn.LayerNorm([self.planes // ratio, 1, 1]), nn.PReLU(), nn.Conv2d(self.planes // ratio, self.inplanes, kernel_size=1) ) else: self.channel_add_conv = None if 'channel_mul' in fusions: self.channel_mul_conv = nn.Sequential( nn.Conv2d(self.inplanes, self.planes // ratio, kernel_size=1), nn.LayerNorm([self.planes // ratio, 1, 1]), nn.PReLU(), nn.Conv2d(self.planes // ratio, self.inplanes, kernel_size=1) ) else: self.channel_mul_conv = None def spatial_pool(self, x): batch, channel, height, width = x.size() if self.pool == 'att': input_x = x # [N, C, H * W] input_x = input_x.view(batch, channel, height * width) # [N, 1, C, H * W] input_x = input_x.unsqueeze(1) # [N, 1, H, W] context_mask = self.conv_mask(x) # [N, 1, H * W] context_mask = context_mask.view(batch, 1, height * width) # [N, 1, H * W] context_mask = self.softmax(context_mask) # [N, 1, H * W, 1] context_mask = context_mask.unsqueeze(3) # [N, 1, C, 1] context = torch.matmul(input_x, context_mask) # [N, C, 1, 1] context = context.view(batch, channel, 1, 1) else: # [N, C, 1, 1] context = self.avg_pool(x) return context def forward(self, x): # [N, C, 1, 1] context = self.spatial_pool(x) if self.channel_mul_conv is not None: # [N, C, 1, 1] channel_mul_term = torch.sigmoid(self.channel_mul_conv(context)) out = x * channel_mul_term else: out = x if self.channel_add_conv is not None: # [N, C, 1, 1] channel_add_term = self.channel_add_conv(context) out = out + channel_add_term return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
2.离散小波变换(DWT)
2.1离散小波变换
DWT 的本质是将输入特征图分解为高频和低频分量,离散小波变换(DWT)上采样和下采样def dwt_init(x): x01 = x[:, :, 0::2, :] / 2 x02 = x[:, :, 1::2, :] / 2 x1 = x01[:, :, :, 0::2] x2 = x02[:, :, :, 0::2] x3 = x01[:, :, :, 1::2] x4 = x02[:, :, :, 1::2] x_LL = x1 + x2 + x3 + x4 x_HL = -x1 - x2 + x3 + x4 x_LH = -x1 + x2 - x3 + x4 x_HH = x1 - x2 - x3 + x4 return x_LL, torch.cat((x_LL, x_HL, x_LH, x_HH), 1) class DWT(nn.Module): def __init__(self): super(DWT, self).__init__() self.requires_grad = False def forward(self, x): return dwt_init(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.1离散小波逆变换 Inverse discrete wavelet transform (IDWT)
def iwt_init(x): r = 2 in_batch, in_channel, in_height, in_width = x.size() out_batch, out_channel, out_height, out_width = in_batch, int( in_channel / (r**2)), r * in_height, r * in_width x1 = x[:, 0:out_channel, :, :] / 2 x2 = x[:, out_channel:out_channel * 2, :, :] / 2 x3 = x[:, out_channel * 2:out_channel * 3, :, :] / 2 x4 = x[:, out_channel * 3:out_channel * 4, :, :] / 2 h = torch.zeros([out_batch, out_channel, out_height, out_width]).float().to(x.device) h[:, :, 0::2, 0::2] = x1 - x2 - x3 + x4 h[:, :, 1::2, 0::2] = x1 - x2 + x3 - x4 h[:, :, 0::2, 1::2] = x1 + x2 - x3 - x4 h[:, :, 1::2, 1::2] = x1 + x2 + x3 + x4 return h class IWT(nn.Module): def __init__(self): super(IWT, self).__init__() self.requires_grad = False def forward(self, x): return iwt_init(x)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
2.2Residual Wavelet Down-sampling Block

class GCWTResDown(nn.Module): def __init__(self, in_channels, att_block, norm_layer=nn.BatchNorm2d): super().__init__() self.dwt = DWT() if norm_layer: self.stem = nn.Sequential(nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=1), norm_layer(in_channels), nn.PReLU(), nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1), norm_layer(in_channels), nn.PReLU()) else: self.stem = nn.Sequential(nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=1), nn.PReLU(), nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1), nn.PReLU()) self.conv1x1 = nn.Conv2d(in_channels, in_channels, kernel_size=1, padding=0) self.conv_down = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, stride=2) #self.att = att_block(in_channels * 2, in_channels * 2) def forward(self, x): stem = self.stem(x) xLL, dwt = self.dwt(x) res = self.conv1x1(xLL) out = torch.cat([stem, res], dim=1) #out = self.att(out) return out, dwt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.3 Residual Wavelet Up sampling Block

class GCIWTResUp(nn.Module): def __init__(self, in_channels, att_block, norm_layer=None): super().__init__() if norm_layer: self.stem = nn.Sequential( nn.PixelShuffle(2), nn.Conv2d(in_channels // 4, in_channels // 4, kernel_size=3, padding=1), norm_layer(in_channels // 4), nn.PReLU(), nn.Conv2d(in_channels // 4, in_channels // 4, kernel_size=3, padding=1), norm_layer(in_channels // 4), nn.PReLU(), ) else: self.stem = nn.Sequential( nn.PixelShuffle(2), nn.Conv2d(in_channels // 4, in_channels // 4, kernel_size=3, padding=1), nn.PReLU(), nn.Conv2d(in_channels // 4, in_channels // 4, kernel_size=3, padding=1), nn.PReLU(), ) self.pre_conv_stem = nn.Conv2d(in_channels // 2, in_channels, kernel_size=1, padding=0) self.pre_conv = nn.Conv2d(in_channels, in_channels, kernel_size=1, padding=0) # self.prelu = nn.PReLU() self.post_conv = nn.Conv2d(in_channels // 4, in_channels // 4, kernel_size=1, padding=0) self.iwt = IWT() self.last_conv = nn.Conv2d(in_channels // 2, in_channels // 4, kernel_size=1, padding=0) # self.se = SE_net(in_channels // 2, in_channels // 4) def forward(self, x, x_dwt): x = self.pre_conv_stem(x) stem = self.stem(x) x_dwt = self.pre_conv(x_dwt) x_iwt = self.iwt(x_dwt) x_iwt = self.post_conv(x_iwt) out = torch.cat((stem, x_iwt), dim=1) out = self.last_conv(out) return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
CycleISP: Real Image Restoration via Improved Data Synthesis
3.RRG: Recursive Residual Group
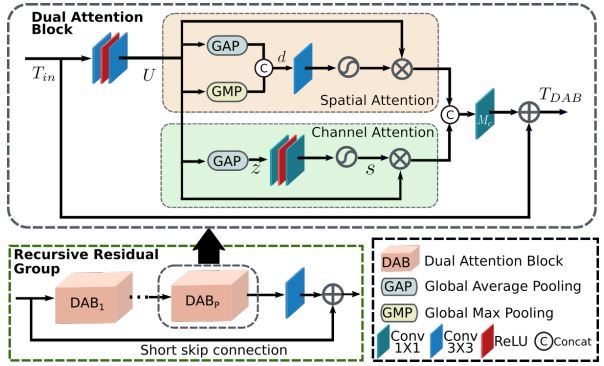
递归残差组 (RRG) 包含多个双重注意块 (DAB)。每个 DAB 包含空间注意和通道注意模块.
3.1Channel attentionclass CALayer(nn.Module): def __init__(self, channel, reduction=16): super(CALayer, self).__init__() # global average pooling: feature --> point self.avg_pool = nn.AdaptiveAvgPool2d(1) # feature channel downscale and upscale --> channel weight self.conv_du = nn.Sequential( nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True), nn.ReLU(inplace=True), nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True), nn.Sigmoid() ) def forward(self, x): y = self.avg_pool(x) y = self.conv_du(y) return x * y- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.2Spatial attention
class BasicConv(nn.Module): def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=False, bias=False): super(BasicConv, self).__init__() self.out_channels = out_planes self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias) self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None self.relu = nn.ReLU() if relu else None def forward(self, x): x = self.conv(x) if self.bn is not None: x = self.bn(x) if self.relu is not None: x = self.relu(x) return x class ChannelPool(nn.Module): def forward(self, x): return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 ) class spatial_attn_layer(nn.Module): def __init__(self, kernel_size=3): super(spatial_attn_layer, self).__init__() self.compress = ChannelPool() self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False) def forward(self, x): # import pdb;pdb.set_trace() x_compress = self.compress(x) x_out = self.spatial(x_compress) scale = torch.sigmoid(x_out) # broadcasting return x * scale- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
3.3双重注意块(DAB)
class DAB(nn.Module): def __init__( self, conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=nn.ReLU(True)): super(DAB, self).__init__() modules_body = [] for i in range(2): modules_body.append(conv(n_feat, n_feat, kernel_size, bias=bias)) if bn: modules_body.append(nn.BatchNorm2d(n_feat)) if i == 0: modules_body.append(act) self.SA = spatial_attn_layer() ## Spatial Attention self.CA = CALayer(n_feat, reduction) ## Channel Attention self.body = nn.Sequential(*modules_body) self.conv1x1 = nn.Conv2d(n_feat*2, n_feat, kernel_size=1) def forward(self, x): res = self.body(x) sa_branch = self.SA(res) ca_branch = self.CA(res) res = torch.cat([sa_branch, ca_branch], dim=1) res = self.conv1x1(res) res += x return res- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
3.4 Recursive Residual Group
class RRG(nn.Module): def __init__(self, conv, n_feat, kernel_size, reduction, act, num_dab): super(RRG, self).__init__() modules_body = [] modules_body = [ DAB( conv, n_feat, kernel_size, reduction, bias=True, bn=False, act=act) \ for _ in range(num_dab)] modules_body.append(conv(n_feat, n_feat, kernel_size)) self.body = nn.Sequential(*modules_body) def forward(self, x): res = self.body(x) res += x return res- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.5 Color Correction
class CCM(nn.Module): def __init__(self, conv=conv): super(CCM, self).__init__() input_nc = 3 output_nc = 96 num_rrg = 2 num_dab = 2 n_feats = 96 kernel_size = 3 reduction = 8 sigma = 12 ## GAUSSIAN_SIGMA act =nn.PReLU(n_feats) modules_head = [conv(input_nc, n_feats, kernel_size = kernel_size, stride = 1)] modules_downsample = [nn.MaxPool2d(kernel_size=2)] self.downsample = nn.Sequential(*modules_downsample) modules_body = [ RRG( conv, n_feats, kernel_size, reduction, act=act, num_dab=num_dab) \ for _ in range(num_rrg)] modules_body.append(conv(n_feats, n_feats, kernel_size)) modules_body.append(act) modules_tail = [conv(n_feats, output_nc, kernel_size),nn.Sigmoid()] self.head = nn.Sequential(*modules_head) self.body = nn.Sequential(*modules_body) self.tail = nn.Sequential(*modules_tail) self.blur, self.pad = get_gaussian_kernel(sigma=sigma) def forward(self, x): x = F.pad(x, (self.pad, self.pad, self.pad, self.pad), mode='reflect') x = self.blur(x) x = self.head(x) x = self.downsample(x) x = self.body(x) x = self.tail(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
-
相关阅读:
古早软件 vim的使用
Shopee与Turkish Cargo正式达成战略合作伙伴关系
React redux、react-redux的基本使用(笔记)
CentOS拓展磁盘分区
spring中注解来创建bean
论文阅读:Offboard 3D Object Detection from Point Cloud Sequences
Attack Lab
Codeforces Round 954 (Div. 3)
Vue2 第一次学习
致远OA(A8) REST接口 python版
- 原文地址:https://blog.csdn.net/learning5201/article/details/126519901
